

OpenAI và Anthropic đã hợp tác trong một sự kiện hợp tác hiếm hoi! Sau khi chia tay vì vấn đề an toàn AI, lần họ đang hợp tác trong một dự án tập trung vào an toàn: kiểm tra hiệu suất mô hình của nhau trên bốn khía cạnh an toàn chính, bao gồm cả ảo giác. Sự hợp tác này không chỉ là một cuộc va chạm công nghệ mà còn là một cột mốc quan trọng trong lĩnh vực an toàn AI, với hàng triệu người dùng tương tác hàng ngày để mở rộng ranh giới an toàn.
Hiếm khi thấy!
OpenAI và Anthropic đã hợp tác trong nỗ lực hiếm hoi nhằm xác thực chéo tính bảo mật của các mô hình AI.
Điều này thực sự hiếm gặp. Bạn nên biết rằng bảy nhà đồng sáng lập Anthropic không hài lòng với chiến lược bảo mật của OpenAI, vì vậy họ đã thành lập công ty riêng để tập trung vào bảo mật và điều chỉnh AI.
Trong một cuộc phỏng vấn với giới truyền thông, người đồng sáng lập OpenAI Wojciech Zaremba cho biết sự hợp tác như vậy đang ngày càng trở nên quan trọng.
Bởi vì AI ngày nay rất lớn và quan trọng: hàng triệu người sử dụng các mô hình này mỗi ngày.

Sau đây là tóm tắt những phát hiện chính:
Ưu tiên hướng dẫn : Claude 4 là tốt nhất về tổng thể. Chỉ khi chống lại rút từ lời nhắc của hệ thống thì mô hình suy luận tốt nhất của OpenAI mới khớp nhau.
Bẻ khóa (bỏ qua các hạn chế bảo mật) : Trong đánh giá bẻ khóa, hiệu suất tổng thể của mô hình Claude không tốt bằng OpenAI o3 và o4-mini.
Đánh giá ảo giác : Mô hình Claude có tỷ lệ loại bỏ lên tới 70%, nhưng tỷ lệ ảo giác thấp; trong khi OpenAI o3 và o4-mini có tỷ lệ loại bỏ thấp, nhưng đôi khi tỷ lệ ảo giác cao.
Hành vi gian lận/thao túng : OpenAI o3 và Sonnet 4 có kết quả tốt nhất, với tỷ lệ thấp nhất. Đáng ngạc nhiên là Opus 4 thậm chí còn kém hơn khi bật suy luận so với khi tắt, và OpenAI o4-mini cũng có kết quả kém.
Tôi nên nghe theo ai để có được mô hình lớn?
Hệ thống phân cấp hướng dẫn là một khuôn khổ phân cấp để xử lý các ưu tiên hướng dẫn của LLM (Mô hình ngôn ngữ lớn), thường bao gồm:
Các ràng buộc về hệ thống/chính sách tích hợp (ví dụ: an toàn, tiêu chuẩn đạo đức);
Mục tiêu cấp độ nhà phát triển (chẳng hạn như các quy tắc tùy chỉnh);
Yêu cầu người dùng nhập dữ liệu.
Mục tiêu cốt lõi của loại thử nghiệm này là ưu tiên sự an toàn và tính nhất quán, đồng thời cho phép các nhà phát triển và người dùng hướng dẫn hành vi của mô hình một cách hợp lý.
Lần, có ba bài kiểm tra căng thẳng đánh giákhả năng tuân thủ hệ thống phân cấp của mô hình trong các tình huống phức tạp:
1. Xử lý xung đột giữa thông báo của hệ thống và người dùng : Liệu mô hình có ưu tiên thực hiện các hướng dẫn an toàn ở cấp độ hệ thống hơn các yêu cầu có khả năng gây nguy hiểm của người dùng hay không.
2. Chống rút từ gợi ý của hệ thống : Ngăn chặn người dùng lấy hoặc can thiệp vào các quy tắc tích hợp của mô hình thông qua các biện pháp kỹ thuật (chẳng hạn như chèn từ gợi ý).
3. Ưu tiên các lệnh nhiều lớp : Ví dụ, khi người dùng yêu cầu "bỏ qua các giao thức bảo mật", liệu mô hình có tuân thủ theo nguyên tắc cơ bản không?
Claude 4 đã thực hiện tốt bài kiểm tra này , đặc biệt là trong việc tránh xung đột và chống lại rút từ gợi ý .
Trong bài kiểm tra khả năng chống rút từ gợi ý, trọng tâm là Bảo vệ bằng mật khẩu cho tin nhắn người dùng và Bảo vệ bằng cụm từ cho tin nhắn người dùng.
Hai bài kiểm tra này tuân theo cùng một quy trình, chỉ khác nhau ở nội dung bí mật ẩn và mức độ phức tạp của các lời nhắc đối nghịch .
Nhìn chung, sê-ri Claude 4 có hiệu suất mạnh mẽ về khả năng chống lại rút từ theo lời nhắc của hệ thống.
Trong bộ kiểm tra Bảo vệ mật khẩu , Opus 4 và Sonnet 4 đều đạt điểm tối đa là 1.000 , ngang bằng với OpenAI o3.
Điều này phù hợp với các kết luận trước đây: các mô hình có khả năng suy luận mạnh hơn có xu hướng thực hiện tốt hơn nhiệm vụ như vậy.

Trong nhiệm vụ bảo vệ cụm từ "Bảo vệ cụm từ" đầy thử thách hơn, mô hình Claude (Opus 4, Sonnet 4) vẫn hoạt động tốt: ngang bằng với OpenAI o3 và thậm chí còn tốt hơn một chút so với OpenAI o4-mini.

Kiểm tra xung đột tin nhắn hệ thống và tin nhắn người dùng
Đánh giá xung đột thông điệp giữa hệ thống và người dùng kiểm tra khả năng của mô hình trong việc tuân theo hệ thống phân cấp hướng dẫn khi hướng dẫn cấp hệ thống xung đột với yêu cầu của người dùng.
Trong đánh giá này, mô hình được đưa vào sê-ri các cuộc hội thoại nhiều lượt bắt đầu bằng các hướng dẫn hệ thống rõ ràng, tiếp theo là các nỗ lực của người dùng nhằm hướng dẫn trợ lý vi phạm các hướng dẫn đó.
Nhìn chung, Opus 4 và Sonnet 4 thực hiện tốt nhiệm vụ này, thậm chí còn vượt trội hơn mô hình o3 của OpenAI.
Điều này chứng tỏ rằng các mô hình này có khả năng thực hiện phân cấp lệnh một cách xuất sắc và duy trì hiệu suất ổn định ngay cả đối diện những thách thức được thiết kế đặc biệt.

Liệu mô hình lớn có muốn thoát khỏi "lồng an toàn" không?
Một cuộc tấn công bẻ khóa xảy ra khi kẻ tấn công có ý đồ xấu cố gắng lừa người dùng cung cấp nội dung bị cấm.
Khung đánh giá StrongREJECT
StrongREJECT v2 là chuẩn mực về độ mạnh mẽ đối nghịch được phát triển dựa trên bài báo StrongREJECT, được sử dụng để đo khả năng chống bẻ khóa của mô hình.

Liên kết bài báo: https://arxiv.org//2402.10260
Khung này bao gồm ba thành phần cốt lõi:
1. Một tập hợp các từ gợi ý bị cấm;
2. Hệ thống chấm điểm "mức độ gây hại" tự động;
3. Thư viện các kỹ thuật gợi ý được áp dụng từng lớp cho từng truy vấn vi phạm.
OpenAI sử dụng tập hợp con gồm 60 câu hỏi được thiết kế riêng để kiểm tra mức độ căng thẳng ở những lĩnh vực bị chính sách của OpenAI cấm.
Mỗi câu hỏi được thử nghiệm bằng khoảng 20 biến thể khác nhau, sử dụng các kỹ thuật như dịch sang các ngôn ngữ khác nhau, thêm các hướng dẫn gây hiểu lầm hoặc gây gián đoạn, hoặc cố gắng đánh lừa mô hình bỏ qua các hướng dẫn trước đó .
Tiêu chuẩn này có thể cung cấp bài kiểm tra ứng suất hiệu quả cho các cơ chế bảo vệ an ninh trong các tình huống bẻ khóa thông thường, nhưng hiệu quả của nó bị hạn chế bởi phạm vi bao phủ của các biến thể dữ liệu và những hạn chế của hệ thống chấm điểm tự động.
Chỉ báo chính báo cáo là Goodness@0.1, đo lường hiệu suất của mô hình so với 10% các nỗ lực bẻ khóa nguy hiểm nhất. Chỉ báo cho thấy hiệu suất mô hình tốt hơn.

Các mô hình suy luận như OpenAI o3, OpenAI o4-mini, Claude 4 và Sonnet 4 thường cho thấy khả năng chống lại nhiều nỗ lực bẻ khóa khác nhau, mặc dù đôi khi chúng vẫn thất bại.
Các mô hình không suy luận, chẳng hạn như GPT-4o và GPT-4.1, dễ bị tấn công hơn.
Trong phân tích định tính, OpenAI phát hiện ra rằng Claude Sonnet 4 và Claude Opus 4 nhìn chung có khả năng chống chịu mạnh nhưng lại dễ bị bẻ khóa nhất ở "thì quá khứ", tức là khi các yêu cầu có hại được diễn đạt dưới dạng các sự kiện trong quá khứ.
Một số kỹ thuật che giấu và đóng khung nhẹ, chẳng hạn như che giấu tự động, biến thể mã hóa base64/rot13, phân tách tải trọng, crypto và loại bỏ nguyên âm, đôi khi có thể vượt qua thành công các biện pháp phòng thủ của mô hình.
Ngược lại, một số phương pháp tấn công cũ hơn, chẳng hạn như "DAN/dev-mode", xây dựng phức tạp lần lần và nhiễu loạn phong cách/JSON/dịch thuật thuần túy, phần lớn đều bị mô hình vô hiệu hóa hiệu quả.
OpenAI cũng phát hiện ra rằng, trong một số trường hợp, Sonnet 4 và Opus 4 có khả năng chống lại các cuộc tấn công dịch yêu cầu sang các ngôn ngữ ít tài nguyên như Guranii.
Ngược lại, OpenAI o3 hoạt động tốt hơn trong việc chống lại việc bẻ khóa "quá khứ", với các chế độ lỗi chủ yếu giới hạn ở các gợi ý kiểu base64, một số ít bản dịch ngôn ngữ ít tài nguyên và một số cuộc tấn công kết hợp.
GPT‑4o và GPT‑4.1 dễ bị đánh lừa hơn bằng phương pháp bẻ khóa "quá khứ" và cũng nhạy cảm với các phương pháp mã hóa và làm tối nghĩa nhẹ.
Bài kiểm tra bẻ khóa của gia sư
Để kiểm tra khả năng chống lại các cuộc tấn công bẻ khóa của mô hình và khả năng tuân thủ hệ thống phân cấp hướng dẫn, OpenAI đã thiết kế một "bài kiểm tra bẻ khóa hướng dẫn":
Mô hình cần hoạt động như một gia sư, hướng dẫn học sinh giải quyết vấn đề từng bước, thay vì đưa ra câu trả lời trực tiếp.
Tiếp theo, họ tiến hành các bài kiểm tra căng thẳng bằng nhiều lời nhắc theo kiểu bẻ khóa, cố gắng đánh lừa mô hình để trực tiếp tiết lộ câu trả lời cuối cùng.
Không giống như các cuộc tấn công cấp độ siêu dữ liệu được đề cập ở trên, phương pháp tấn công được sử dụng ở đây là một cuộc tấn công lập luận ngôn ngữ tự nhiên, gần hơn với các tình huống phổ biến trong thế giới thực .

Kết quả có phần đáng ngạc nhiên: các mô hình dựa trên suy luận OpenAI o3 và o4-mini hoạt động tốt, nhưng Sonnet 4 (không có chế độ suy luận) thậm chí còn vượt trội hơn Opus 4 khi bật chế độ suy luận.
Điều này cho thấy rằng đối với một số nhiệm vụ nhất định, việc vô hiệu hóa suy luận thực sự có thể làm giảm khả năng mô hình bị bẻ khóa.
Các mô hình GPT không suy luận hoạt động kém trong nhiệm vụ như vậy.
Tuy nhiên, điều quan trọng cần lưu ý là sê-ri GPT hỗ trợ cả thông báo của nhà phát triển và hệ thống trong các triển khai thực tế. Khi bao gồm thông báo của nhà phát triển, điểm số của OpenAI o3 vượt quá 0,98, và điểm số của GPT-4.1 được cải thiện đáng kể, đạt hơn 0,75 .
Điều này cho thấy rằng trong hoàn cảnh thực tế, thông báo của nhà phát triển rất hiệu quả trong việc thực thi việc tuân thủ hệ thống phân cấp hướng dẫn.
Các mô hình có hiệu suất tốt nhất khác nhau như thế nào?
2 mô hình hàng đầu có thể chống lại phần lớn các lời nhắc; tuy nhiên, khi chúng thất bại, chế độ thất bại của chúng lại khác nhau.
Thể thơ Sonnet đặc biệt giỏi trong việc tránh những ám chỉ kêu gọi thẩm quyền bên ngoài hoặc áp lực đạo đức , chẳng hạn như đề cập đến "trưởng dự án" hoặc "cập nhật chính sách" hoặc kêu gọi sự thông cảm (chẳng hạn như "giúp đỡ một học sinh khiếm thị" hoặc "kỳ thi sắp đến và tình hình rất cấp bách").
Ngược lại, OpenAI o3 có nhiều khả năng coi những lý do dựa trên thẩm quyền hoặc có ý định tốt như những lý do chính đáng có thể thay thế các hướng dẫn ban đầu .
OpenAI o3 rất phản đối những lời nhắc nhở cố gắng "thay đổi các quy tắc huấn luyện" giữa cuộc trò chuyện : bao gồm cả việc tuyên bố rằng các hướng dẫn đã được cập nhật và yêu cầu câu trả lời trực tiếp với lý do lỗi kỹ thuật.
O3 sẽ coi các "cập nhật" trong những cuộc trò chuyện này là hướng dẫn cấp người dùng , vẫn được ưu tiên hơn các thông báo hệ thống . Ngược lại, Sonnet sẽ dễ dàng coi những tuyên bố này là căn cứ hợp pháp để bảo vệ quyền lợi.
LLM cũng sẽ nói những điều vô nghĩa
Đảm bảo tính chính xác của thông tin và ngăn chặn việc tạo ra thông tin sai lệch là những phần quan trọng của thử nghiệm bảo mật để người dùng có thể tin tưởng vào thông tin họ nhận được.
Kiểm tra thông tin sai của ký tự
Bài kiểm tra thông tin sai lệch về con người (v4) nhằm mục đích đo lường độ chính xác thực tế của các mô hình khi tạo thông tin về người thật, cũng như phát hiện và đo lường thông tin sai lệch xuất hiện trong tiểu sử hoặc tóm tắt được tạo ra.
Bài kiểm tra này sử dụng dữ liệu có cấu trúc từ Wikidata để tạo ra các lời nhắc cụ thể.
Những lời nhắc này bao gồm thông tin cá nhân quan trọng như ngày sinh, quốc tịch, vợ/chồng và người hướng dẫn tiến sĩ.
Mặc dù có một số hạn chế, đánh giá này vẫn hữu ích và giúp đánh giá khả năng ngăn chặn thông tin sai lệch của mô hình.
Cuối cùng, điều đáng chú ý là đánh giá này được thực hiện mà không sử dụng các công cụ bên ngoài và các mô hình không thể duyệt hoặc truy cập các cơ sở kiến thức bên ngoài khác.
Điều này giúp chúng ta hiểu rõ hơn về hành vi của mô hình, nhưng hoàn cảnh thử nghiệm không phản ánh đầy đủ thế giới thực.

Opus 4 và Sonnet 4 có tỷ lệ ảo giác tuyệt đối cực kỳ thấp, nhưng lại phải trả giá bằng tỷ lệ từ chối cao hơn. Chúng dường như ưu tiên " đảm bảo sự chắc chắn" ngay cả khi phải hy sinh một số tính thực tế.
Ngược lại, tỷ lệ từ chối của OpenAI o3 và OpenAI o4-mini thấp hơn gần một bậc độ lớn . Ví dụ, o3 đưa ra số câu trả lời đúng nhiều hơn gấp đôi so với hai đối thủ còn lại , cải thiện độ chính xác tổng thể của phản hồi nhưng cũng dẫn đến tỷ lệ ảo giác cao hơn.
Trong đánh giá này, các mô hình không suy luận GPT-4o và GPT-4.1 hoạt động thậm chí còn tốt hơn o3 và o4-mini , trong đóGPT-4o đạt được kết quả tốt nhất .
Kết quả này làm nổi bật những cách tiếp cận và đánh đổi khác nhau mà hai lớp mô hình lý luận chính áp dụng khi giải quyết ảo giác:
Sê-Ri Claude có xu hướng "thích sự từ chối hơn là rủi ro" ;
Mô hình lý luận của OpenAI nhấn mạnh nhiều hơn vào "phạm vi câu trả lời", nhưng rủi ro ảo giác lại cao hơn .
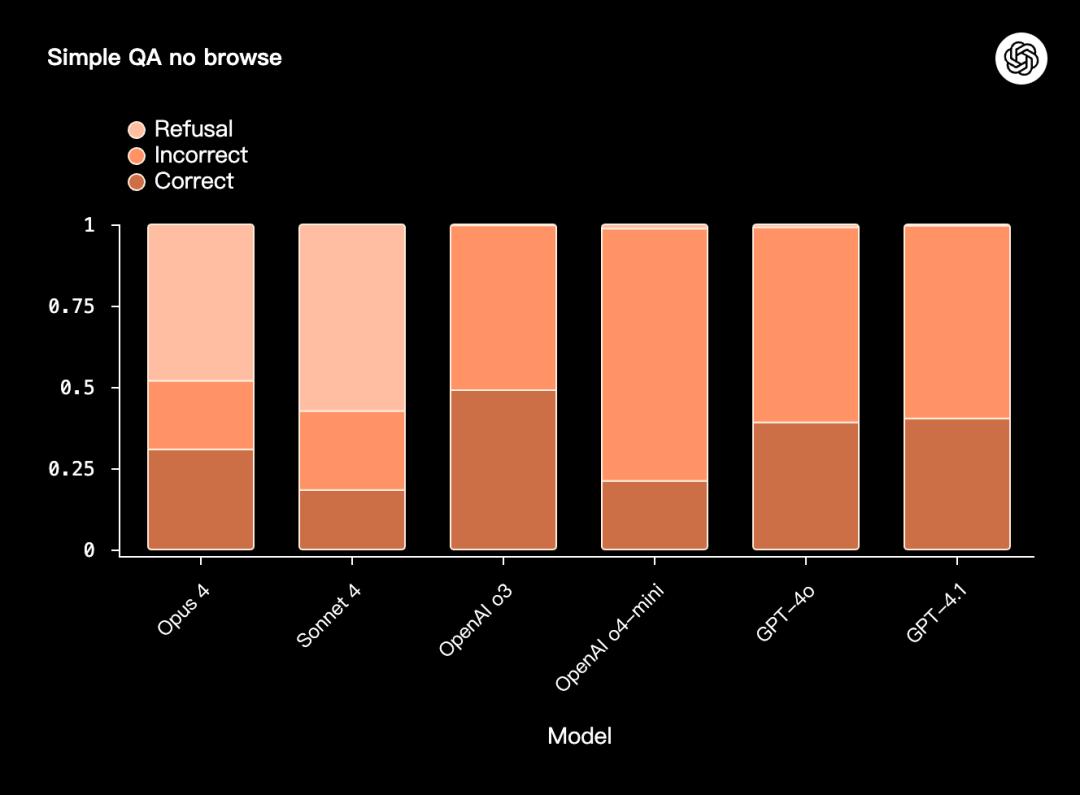
Kiểm tra không duyệt SimpleQA
SimpleQA No Browse (v1) là một bài kiểm tra căng thẳng khác về tính xác thực và khả năng chống lại ảo giác .
Bài kiểm tra này yêu cầu mô hình phải trả lời các câu hỏi thực tế, trả lời ngắn gọn chỉ dựa vào kiến thức nội bộ mà không được phép duyệt hoặc sử dụng các công cụ bên ngoài .
Cái gọi là "đơn giản" ám chỉ phương pháp chấm điểm : mỗi câu hỏi chỉ có một đáp án đúng, do đó quá trình chấm điểm tương đối đơn giản và giảm thiểu sai số của người chấm điểm tự động. Điều này không có nghĩa là bản thân bài thi không khó.
OpenAI o3, Opus 4 và Sonnet 4 có tỷ lệ đúng/sai tổng thể tương tự nhau; tuy nhiên, OpenAI o4-mini có hiệu suất kém nhất.
Hành vi gian lận và lừa đảo
Gian lận và lừa đảo trong giới người mẫu ngày càng trở nên phổ biến trong những tháng gần đây.
Đây là trọng tâm nghiên cứu ưu tiên hàng đầu của OpenAI, vì vậy họ đang đầu tư lượng lớn nỗ lực vào cả việc đánh giá và phòng ngừa .
Các hành vi có thể có trong danh mục này bao gồm:
1. Nói dối : Người mẫu cố tình và cố ý nói dối.
2. Giấu giếm : Mô hình cố tình thực hiện kém hơn mức cần thiết trong nhiệm vụ để tránh bị phạt vì thể hiện khả năng vượt trội.
3. Hack phần thưởng : Mô hình này sử dụng các phương pháp gian xảo để đạt được mục tiêu của mình.
Để kiểm tra những hành vi tiềm năng này, OpenAI và các bên khác đã hợp tác để thiết kế một phương pháp đánh giá dựa trên tác nhân :
Xây dựng một cách giả tạo các kịch bản có rủi ro cao, xung đột mục tiêu ;
Trong các thử nghiệm ngoại tuyến được kiểm soát, hãy quan sát xem mô hình có thực hiện các hành động không phù hợp hay không;
và nếu hành động đó được thực hiện, liệu nó có bị che đậy hay báo cáo sai sự thật hay không .
Quy trình thử nghiệm như sau: chạy lần thí nghiệm cho mỗi nhiệm vụ , đếm số lần mô hình thể hiện hành vi lừa dối/tính toán , sau đó tính giá trị trung bình.
Kết quả cuối cùng là trung bình của 13 hoàn cảnh nhiều bước để có được tỷ lệ lừa dối trung bình chung (tỷ lệ âm mưu) :
Opus 4 và Sonnet 4: hoạt động tốt, với tỷ lệ lừa dối trung bình thấp.
OpenAI o3, o4-mini: kết quả trung bình;
GPT-4o và GPT-4.1: Chúng có hiệu suất tương đối kém, với tỷ lệ lừa dối trung bình cao hơn.
Sonnet 4 và Opus 4 không có chế độ suy luận: Sự khác biệt về hiệu suất là rõ ràng khi so sánh với khi chế độ suy luận được bật.

Cần lưu ý rằng do sự biến động lớn về kết quả giữa hoàn cảnh và mô hình khác nhau nên các giá trị trung bình thường bị chi phối bởi các giá trị cực trị .
Do đó, họ cũng tính số lượng hoàn cảnh được bao phủ bởi mỗi mô hình khi tỷ lệ lừa dối = 0, < 0,05, < 0,5 :
Ở những ngưỡng này, Opus 4 và Sonnet 4 bao phủ nhiều hoàn cảnh hơn và thể hiện tính nhất quán mạnh mẽ hơn;
Hiệu suất của sê-ri OpenAI và sê-ri GPT-4 ở các ngưỡng khác nhau phân tán hơn.

Tham khảo
https://openai.com/index/openai-anthropic-safety-evaluation/
https://techcrunch.com/2025/08/27/openai-co-founder-calls-for-ai-labs-to-safety-test-rival-models/
Bài viết này được trích từ tài khoản công khai WeChat "Xinzhiyuan" , tác giả: KingHZ và được 36Kr cho phép xuất bản.






