

Bảng điều khiển giám sát EL-CL: Một nghiên cứu với Nimbus
StereumLabs , phối hợp với MigaLabs , đã dẫn đầu việc phát triển một bộ công cụ toàn diện gồm các bảng điều khiển Grafana được thiết kế để giám sát các chỉ số trên nhiều máy khách Consensus và Thực thi. Hơn 70 tổ hợp máy khách (bao gồm cả các siêu nút) được vận hành và quan sát liên tục, cung cấp cái nhìn tổng quan và đại diện về hành vi của máy khách trong điều kiện mạng thực tế.
Việc hiểu ý nghĩa và tác động vận hành của các chỉ số khách hàng thường rất khó khăn, đặc biệt là khi phân biệt giữa sự biến động bình thường và sự cố thực sự. Trong bài viết này, chúng tôi xem xét cách một lỗi ảnh hưởng đến máy khách Consensus Nimbus được xác định rõ ràng và nhanh chóng thông qua các bảng điều khiển này, minh họa giá trị thực tiễn của chúng trong các tình huống giám sát thực tế.
Mục đích của phân tích này không phải là chỉ trích một khách hàng cụ thể, mà là để chứng minh công cụ quan sát hiệu quả giúp phát hiện ngay lập tức các hành vi bất thường. Tình hình đã trở lại bình thường trong vòng vài giờ và sự cố này có tác động tổng thể hạn chế. Đồng thời, nó cũng nhắc nhở về tầm quan trọng của việc duy trì sự đa dạng khách hàng trong hệ sinh thái Ethereum.
Một phát hiện thứ yếu — việc mất hỗ trợ số liệu mà không được chú ý trong bản phát hành Nimbus tiếp theo — đã được đưa ra trong một cuộc họp đánh giá hợp tác với nhóm Nimbus, càng làm nổi bật giá trị của việc quan sát liên tục và giao tiếp giữa các nhóm.
Ngoài ra, tài liệu này trình bày một phân tích so sánh giữa một nút Nimbus thông thường và một siêu nút, tận dụng khả năng hiển thị song song của bảng điều khiển để minh họa sự khác biệt về hoạt động do đặc tả PeerDAS mang lại.
Nimbus Consensus Client Disruption — Ngày 8 tháng 2 năm 2026
Vào ngày 8 tháng 2 năm 2026, trong khoảng thời gian từ 01:00 đến 02:00 UTC, máy khách Consensus Nimbus đã gặp phải một lỗi nghiêm trọng, tạm thời làm gián đoạn hoạt động của nó trên mạng chính Ethereum.
Theo kết luận khám nghiệm tử thi chính thức:
“Các máy khách Nimbus đã từ chối sai một Block trên mạng chính là không hợp lệ và tạo ra một nhánh riêng. Lỗi hỏng bộ nhớ cache trong thuật toán băm cây Merkle của Nimbus gây ra điều này xuất phát từ một số thay đổi về kích thước của các đối tượng trong Danh sách SSZ xuất hiện trên mạng chính, dẫn đến việc bỏ qua quá trình vô hiệu hóa bộ nhớ cache chính xác… Bởi vì các hậu duệ của Block bị xác định sai là không hợp lệ có thể
Nếu không thể xử lý mà không vi phạm giao thức, Nimbus không thể tiếp tục theo dõi chuỗi chính tắc của mạng chính cho đến khi nút được khởi động lại.”
Tác động có thể quan sát được ở cấp độ nút
Mặc dù hoạt động mạng đã trở lại bình thường vài giờ sau đó, nhưng tác động về mặt vận hành đã ngay lập tức được thể hiện trên các hệ thống giám sát xuất ra các chỉ số Nimbus. Mặc dù chỉ riêng việc trực quan hóa các chỉ số là không đủ để xác định nguyên nhân gốc rễ, nhưng nó cung cấp một dấu hiệu nhanh chóng và rõ ràng rằng hành vi bất thường đang xảy ra — ngay cả đối với những người vận hành không có chuyên môn sâu về giao thức.
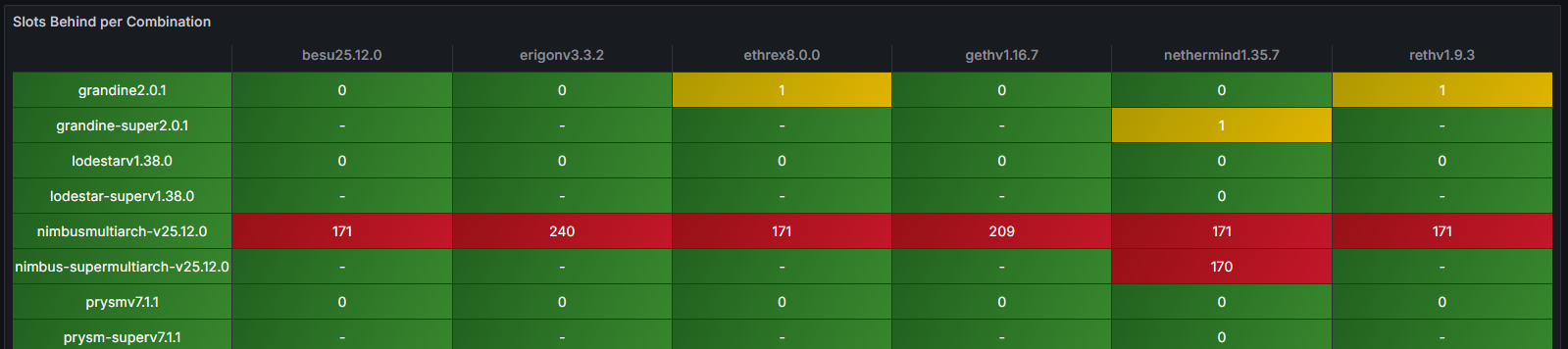
Một trong những chỉ báo nổi bật nhất là chỉ số “Slots Behind” (Số vị trí bị chậm). Vào khoảng 02:00 UTC, nút bị ảnh hưởng trong ví dụ này (Nimbus/Nethermind) được quan sát thấy chậm hơn 171 vị trí so với vị trí đồng hồ, cho thấy rõ ràng sự mất đồng bộ với chuỗi chính tắc.

Mặc dù nhiều người chơi staking chuyên nghiệp sử dụng bộ bảng điều khiển riêng của họ, nhưng họ không thể thấy những gì họ không chạy. Nói cách khác, họ chỉ thấy dữ liệu về các node mà họ đang chạy, nhưng họ không thể so sánh nó với các client khác mà họ không chạy. Đây là một điểm khác biệt quan trọng .
Vì StereumLabs vận hành một số lượng lớn các tổ hợp node, nên việc nhanh chóng xác minh xem các node khác có bị ảnh hưởng hay không và đó là những node nào rất dễ dàng. Thật vậy, bảng điều khiển trạng thái đồng bộ tổng quan đã ngay lập tức cho thấy một mô hình rõ ràng: tất cả các phiên bản chạy máy khách Consensus Nimbus đều bị chậm so với khe thời gian, trong khi các tổ hợp máy khách Consensus- Thực thi khác vẫn hoạt động bình thường. Việc so sánh song song này giúp phát hiện và xác định nguyên nhân gây ra sự bất thường ngay lập tức, mà không cần kiểm tra nhật ký chuyên sâu hoặc đối chiếu thủ công giữa các node.
Quan sát này càng được củng cố thêm bởi các bảng điều khiển chuyên dụng của các máy khách Consensus khác, với các chỉ số về đồng bộ hóa, xử lý Block và mạng lưới vẫn ổn định trong cùng khoảng thời gian đó.
Đồng thời, quá trình xử lý Block thực tế đã bị dừng lại. Việc thiếu các khối dữ liệu mới được xử lý đã được phản ánh trực tiếp trong các chỉ số nhập Block , khiến vấn đề trở nên rõ ràng từ góc độ vận hành.

Suy giảm khả năng kết nối mạng và kết nối ngang hàng
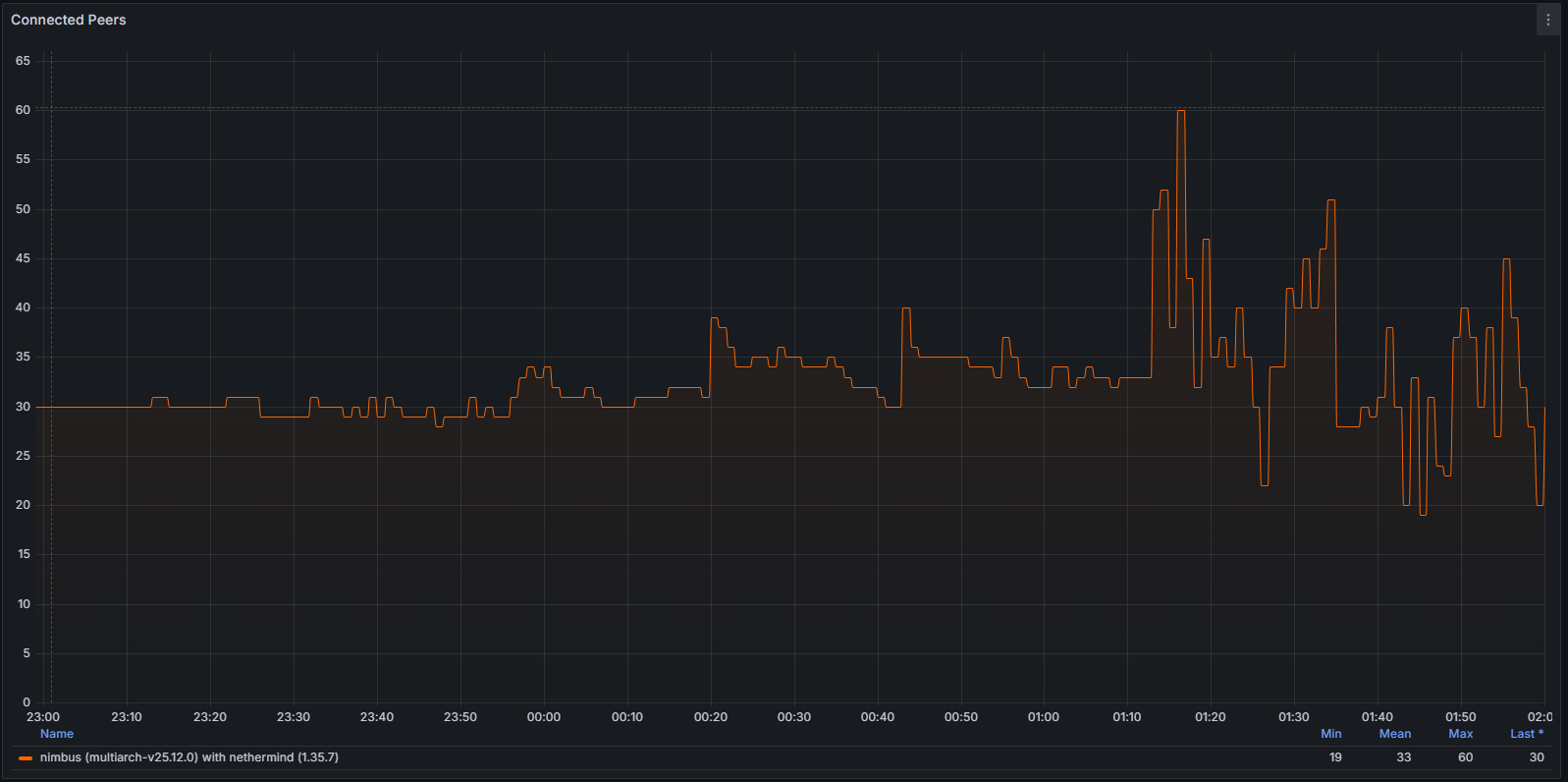
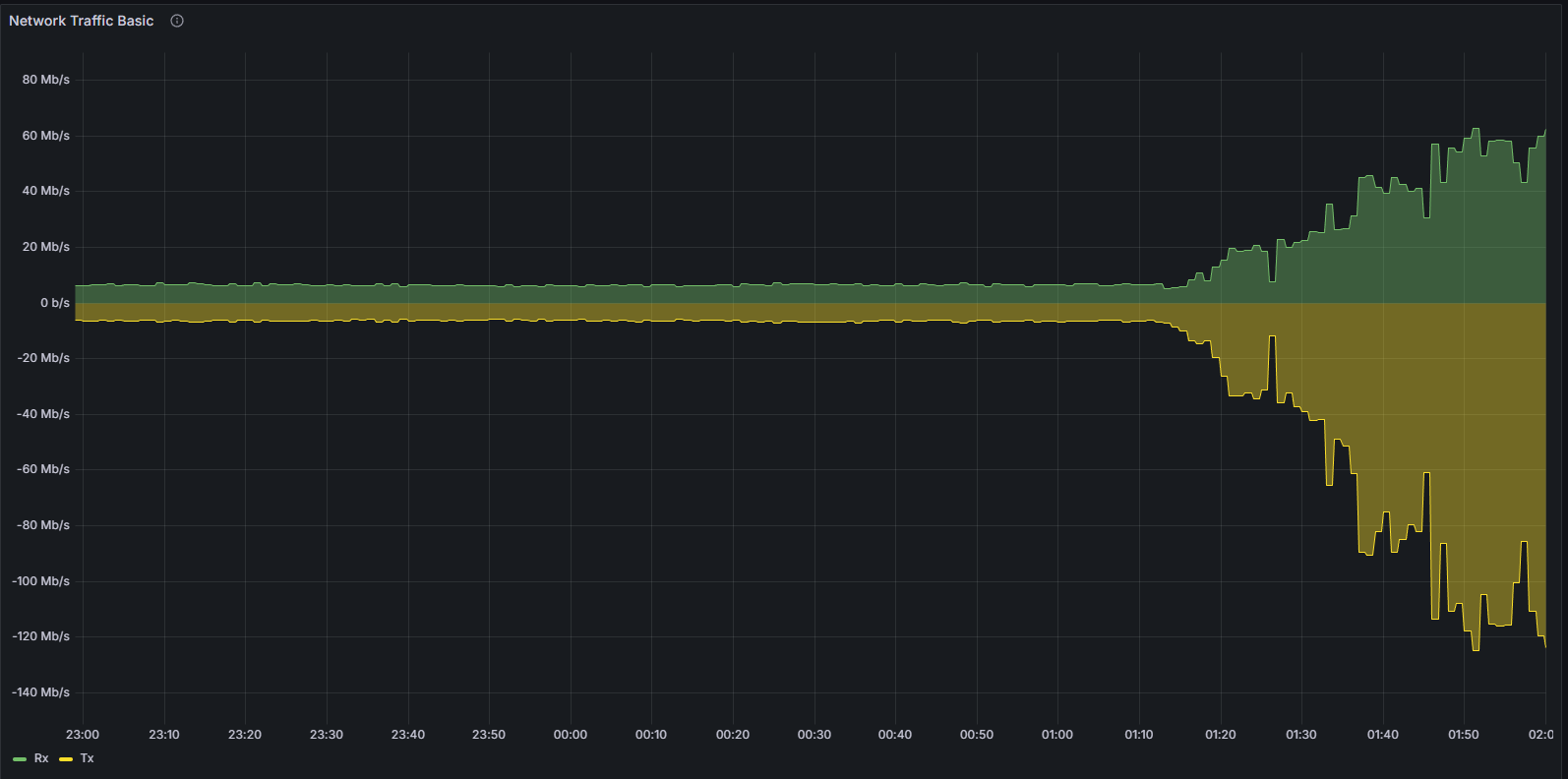
Sự bất ổn cũng thể hiện ở lớp mạng. Khi máy khách lệch khỏi chuỗi chuẩn, nó liên tục cố gắng thiết lập các kết nối ngang hàng hiệu quả. Hành vi này có thể quan sát rõ ràng thông qua:
Các đồng nghiệp được kết nối
Sử dụng băng thông
Số liệu thống kê libp2p
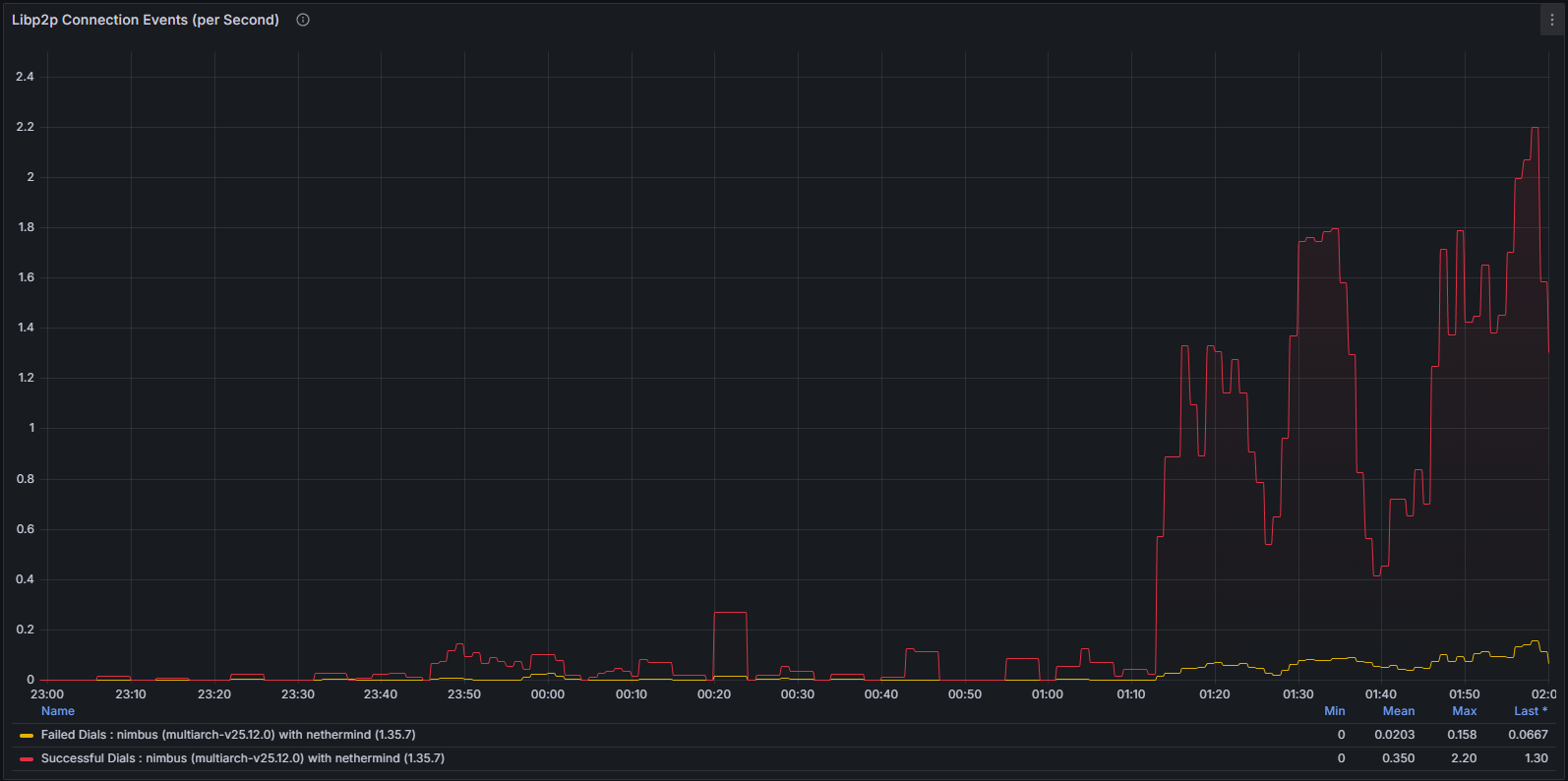
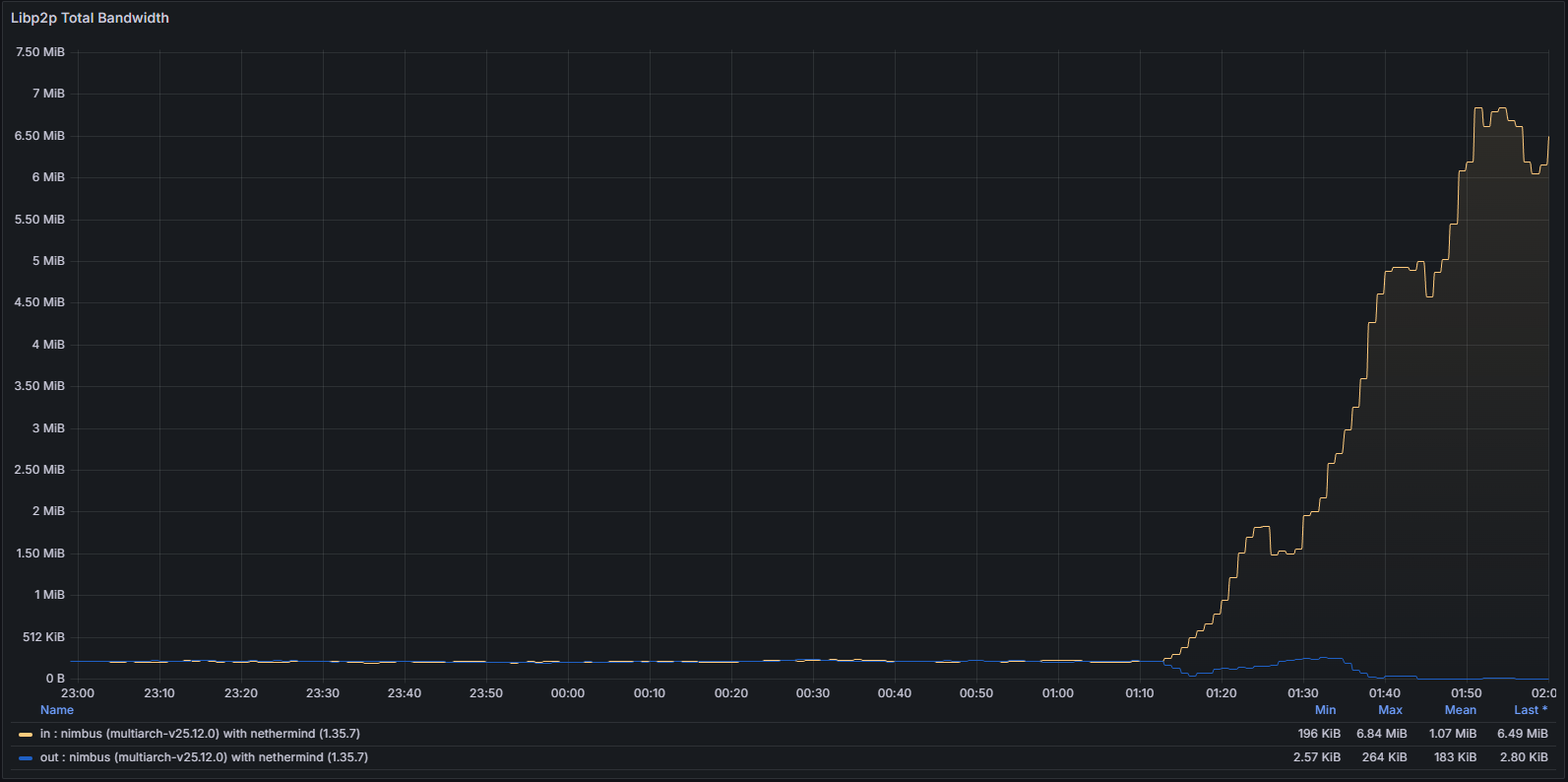
Cả mức sử dụng mạng hệ thống và các chỉ số cụ thể của giao thức đều cho thấy các mô hình bất thường, phù hợp với việc một nút không thể xác thực và truyền tải thành công các khối chuẩn.
Sự trì trệ hoạt động của cơ sở dữ liệu
Các chỉ số liên quan đến cơ sở dữ liệu càng làm nổi bật vấn đề. Các thao tác ghi và cập nhật trạng thái giảm đáng kể, phản ánh thực tế là máy khách không còn xử lý thành công dữ liệu chuẩn mới. Điều này cung cấp thêm bằng chứng xác nhận rằng nút thực sự bị kẹt chứ không chỉ đơn thuần là gặp phải độ trễ mạng tạm thời.
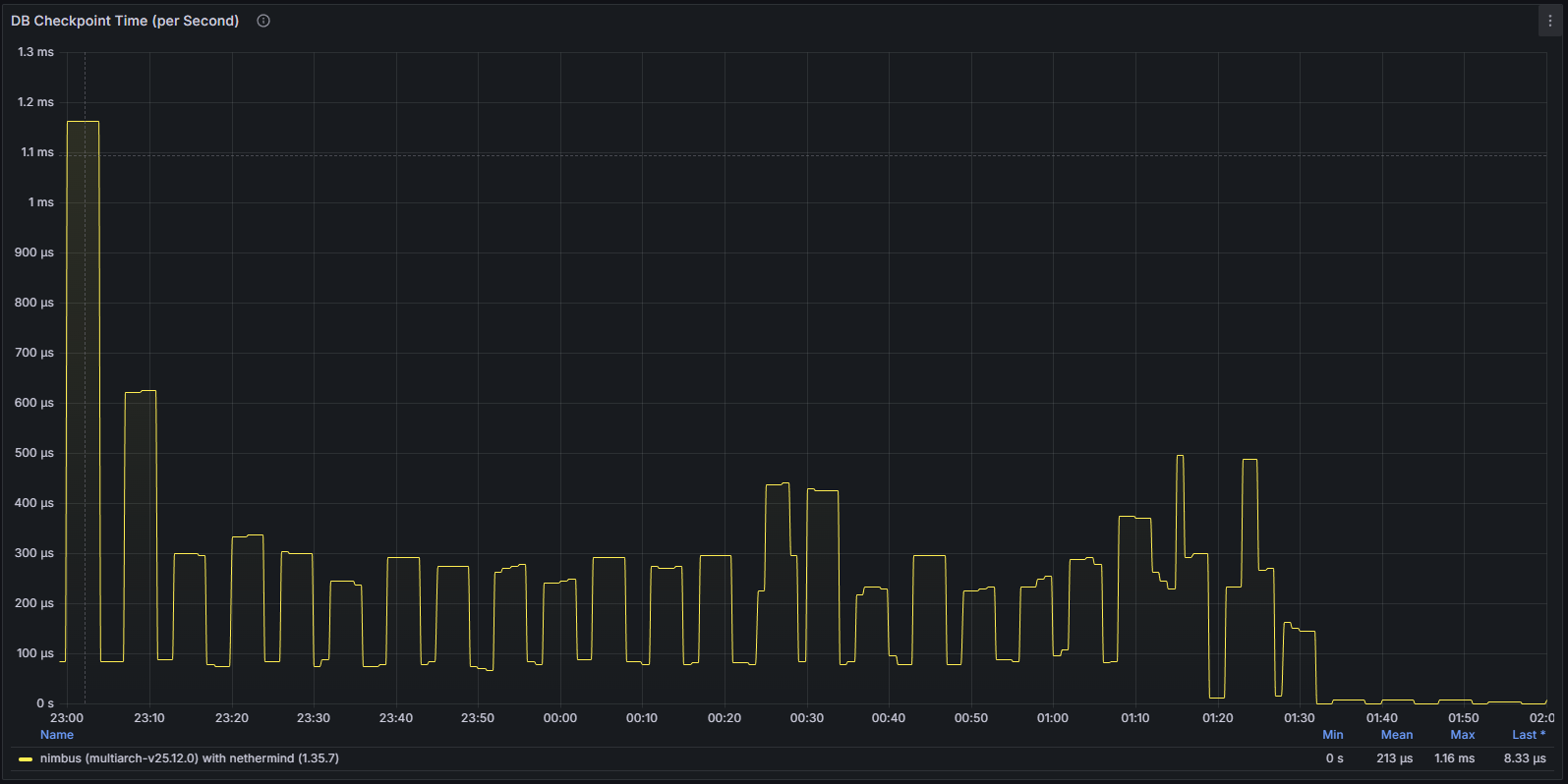
Nhìn chung, sự gián đoạn do lỗi này gây ra rất hạn chế và đã được giải quyết bằng cách khởi động lại node. Nimbus vẫn là một trong những client CL mạnh mẽ nhất trong lĩnh vực này, không có sự cố lớn nào kể từ khi Beacon Chain ra đời. Bản vá lỗi đã được phát hành chỉ vài ngày sau đó và không có vấn đề nào được ghi nhận kể từ đó.
Sự mất mát không được chú ý của sự hỗ trợ từ chỉ số đo lường
Phát hiện bất thường là một trong những trường hợp sử dụng quan trọng của việc biên soạn các bảng điều khiển này, nhưng không phải là trường hợp duy nhất. Trong một cuộc trao đổi kỹ thuật ngắn với nhóm Nimbus về phạm vi bao phủ bảng điều khiển và khả năng hiển thị số liệu, chúng tôi đã xác định được một lỗi hồi quy ảnh hưởng đến một số liệu cụ thể.
Thông tin về phân bố số lượng người dùng kết nối trên mỗi máy khách — một chỉ số có sẵn trong các phiên bản trước — không còn được xuất ra một cách chính xác nữa. Thông qua việc so sánh phiên bản và dữ liệu bảng điều khiển lịch sử, sự thay đổi này có thể liên quan đến bản phát hành được triển khai vào cuối năm 2025, cho thấy một lỗi hồi quy ngẫu nhiên có thể xảy ra trong chu kỳ cập nhật đó. Mặc dù tất cả các máy khách Ethereum đều chạy một loạt các bài kiểm tra trước khi phát hành, nhưng các bài kiểm tra đó thường bao gồm các vấn đề phức tạp, chẳng hạn như Consensus, Tính chất cuối cùng, xác thực, hiệu suất, v.v., nhưng chúng không phải lúc nào cũng bao gồm các chỉ số vì chúng không quan trọng đối với hoạt động.
Phát hiện này càng minh họa thêm giá trị của việc quan sát liên tục, xuyên suốt các phiên bản: ngoài việc phát hiện các sự cố trong quá trình thực thi, các bảng điều khiển toàn diện còn giúp làm nổi bật những sự không nhất quán nhỏ ở cấp độ số liệu mà nếu không sẽ khó nhận ra.


So sánh một nút Nimbus thông thường với một siêu nút.
Bảng điều khiển của Stereumlabs cung cấp khả năng so sánh song song giữa các nút thông thường và siêu nút, cho phép người vận hành quan sát và định lượng sự khác biệt về hoạt động giữa hai cấu hình này.
Sự khác biệt giữa một nút thông thường và một siêu nút trong Nimbus bắt nguồn từ đặc tả PeerDAS, được giới thiệu như một phần của bản nâng cấp Fusaka (Đề xuất cải tiến Ethereum (EIP)-7594). Sự khác biệt cốt lõi về kiến trúc nằm ở số lượng cột dữ liệu blob mà mỗi nút lưu giữ và truyền tải trên mạng ngang hàng: một nút thông thường đăng ký một tập hợp con được chỉ định ngẫu nhiên gồm 8 mạng con cột, trong khi một siêu nút đăng ký tất cả 128 mạng con cột, lưu giữ toàn bộ tập dữ liệu.
Do khối lượng giao dịch dữ liệu được quản lý bởi một siêu nút lớn hơn đáng kể, sự khác biệt rõ rệt và dễ nhận thấy nhất thể hiện ở mức tiêu thụ băng thông mạng nói chung. Điều này được hiển thị trong các bảng I/O mạng cấp cao nhất của bảng điều khiển.

Điều này được chứng thực thêm bởi các chỉ số băng thông libp2p, phản ánh sự tham gia của nút vào lớp truyền tin.

Cả Xuất lượng vào và ra đều tăng đáng kể trên siêu nút, với các đỉnh cao nhất xuất hiện xung quanh ranh giới khe khi dữ liệu cột được nhận và truyền lại. Mặc dù người ta có thể trực quan cho rằng băng thông của siêu nút sẽ lớn hơn khoảng 16 lần so với nút thông thường — do nó đăng ký tất cả 128 mạng con cột so với 8 — nhưng hệ số nhân quan sát được trên thực tế thấp hơn đáng kể. Điều này là do một phần đáng kể băng thông bị tiêu thụ bởi chi phí mạng cố định (quản lý ngang hàng, xác thực, truyền Block ) không đổi bất kể số lượng đăng ký mạng con, kết hợp với cấu trúc liên kết mạng lưới GossipSub giới hạn số lượng ngang hàng mà một nút nhận được bất kỳ cột nào. Tỷ lệ lý thuyết ×16 chỉ đúng nếu băng thông hoàn toàn là hàm của khối lượng giao dịch dữ liệu cột mà không có chi phí cố định, điều này không xảy ra trong mạng p2p thực tế.
Trong khoảng thời gian quan sát 7 ngày tính đến thời điểm viết bài này, băng thông trung bình đến và đi cho thấy sự khác biệt khoảng 40% giữa một siêu nút và một nút thông thường.

| Mb/s | Tối thiểu thông thường | Tối đa thông thường | Trung bình thường | Siêu nút tối thiểu | Siêu nút tối đa | Trung bình siêu nút | Delta Min | Delta Max | Giá trị trung bình Delta |
|---|---|---|---|---|---|---|---|---|---|
| Đã nhận | 5.7 | 10.1 | 7,65 | 10.8 | 81,4 | 18,9 | 52,78% | 12,41% | 40,48% |
| Đã truyền | 5,52 | 9,33 | 7.21 | 11.1 | 48,2 | 16.7 | 49,73% | 19,36% | 43,17% |
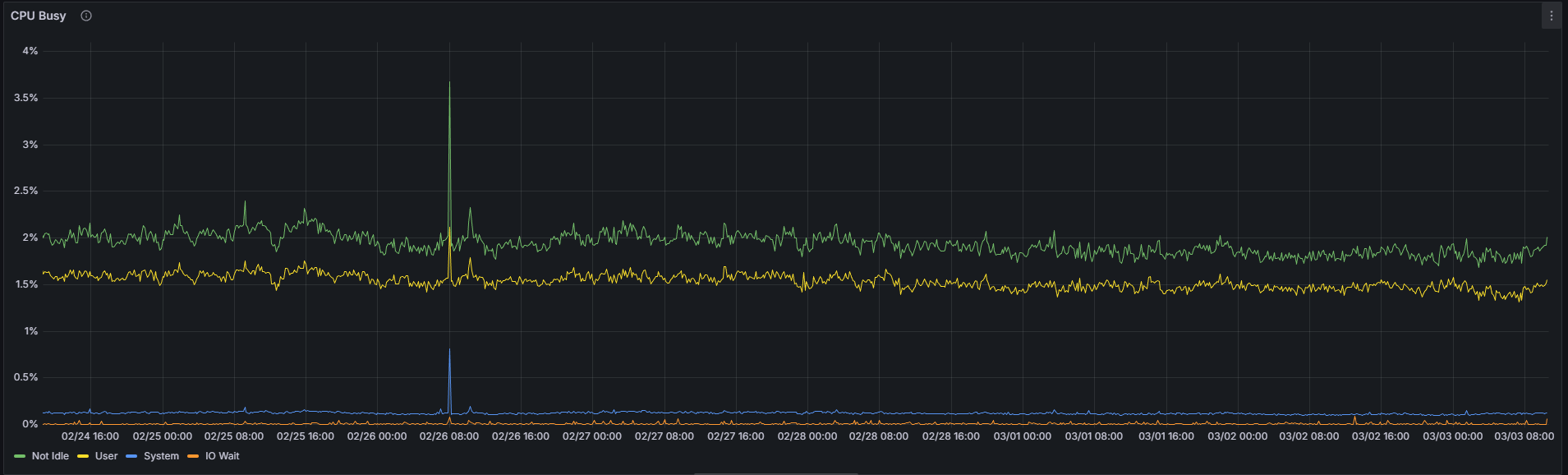
Do số lượng lớn các thao tác xác minh ô KZG và xử lý thông tin lan truyền được thực hiện trên tất cả 128 mạng con cột, một siêu nút dự kiến sẽ có mức sử dụng CPU cao hơn so với một nút thông thường. Tuy nhiên, chỉ số này không phải là yếu tố duy nhất đáng tin cậy để phân biệt giữa hai cấu hình.
Thường xuyên:
Siêu nút:
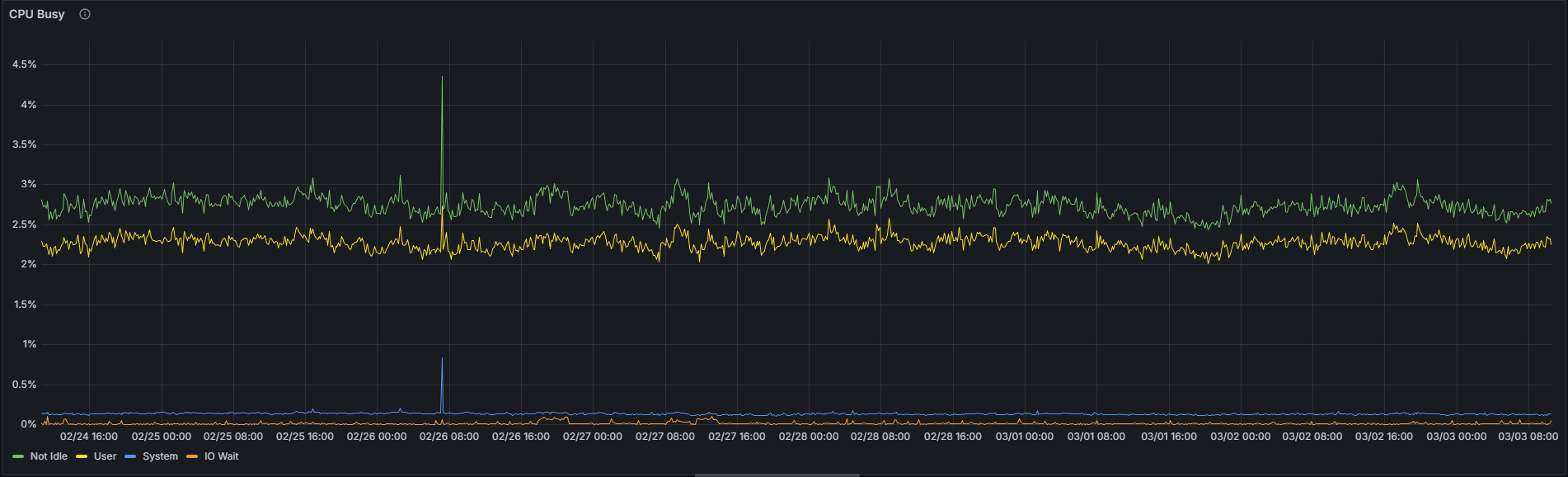
Trong khoảng thời gian quan sát 7 ngày tính đến thời điểm viết bài này, sự khác biệt tuyệt đối về mức sử dụng CPU trung bình giữa một siêu node và một node thông thường là dưới 1 điểm phần trăm (1,92% so với 2,74%) đối với sự kết hợp Nimbus/Nethermind cụ thể này. Mặc dù sự chênh lệch tương đối khoảng 70% có vẻ đáng kể, nhưng cần phải xem xét đến giá trị tuyệt đối rất thấp của nó — mức tăng từ 1,92% lên 2,74% vẫn không đáng kể về mặt vận hành. Mức sử dụng CPU cao hơn một chút trên siêu node là có thật, nhưng không nên là nguyên nhân gây lo ngại trong thực tế.
| Thường xuyên | Siêu nút | Đồng bằng | |
|---|---|---|---|
| CPU không ở trạng thái rảnh rỗi | 1,92% | 2,74% | 70,07% |
Việc tăng cường quyền quản lý cột trực tiếp dẫn đến Xuất lượng ghi đĩa cao hơn và mức tiêu thụ dung lượng lưu trữ tổng thể lớn hơn ở lớp Consensus . Một siêu nút giữ lại dữ liệu cho tất cả các cột trong suốt thời gian quản lý, trong khi dung lượng lưu trữ trên đĩa của một nút thông thường nhỏ hơn một cách tương ứng, phản ánh việc chỉ quản lý một tập hợp con được chỉ định.
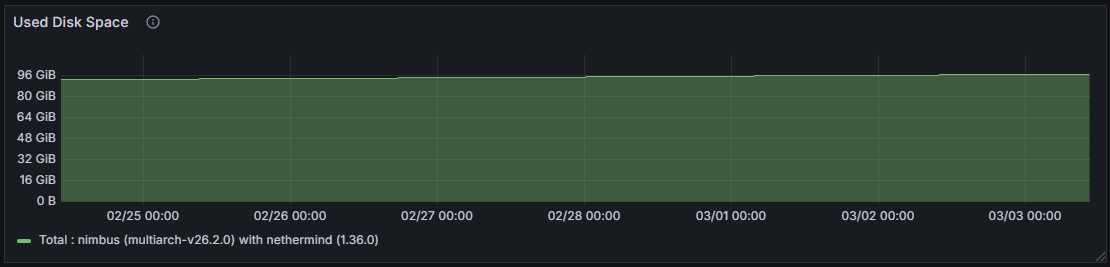
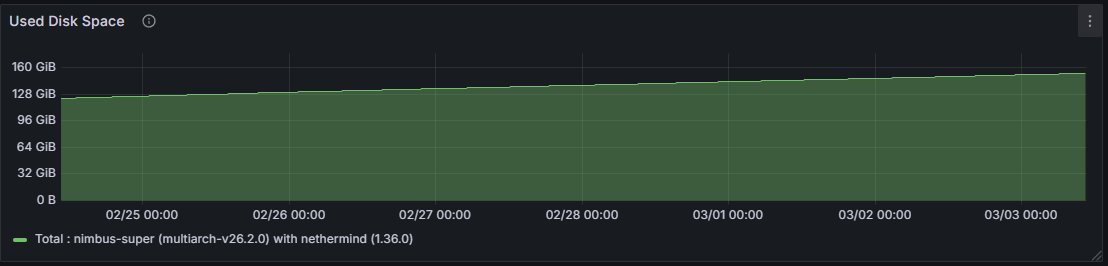
Việc tham gia rộng rãi hơn vào mạng con trên một siêu nút đòi hỏi sự tương tác với một tập hợp các nút ngang hàng lớn hơn và đa dạng hơn, dẫn đến số lượng nút ngang hàng được kết nối cao hơn so với một nút thông thường. Trong khoảng thời gian quan sát 7 ngày, số lượng nút ngang hàng được kết nối trên một nút thông thường dao động từ 23 đến 90, với giá trị trung bình là 35, trong khi trên siêu nút dao động từ 50 đến 161, với giá trị trung bình là 112 nút ngang hàng được kết nối.

Các siêu nút đăng ký vào tất cả 128 mạng con cột, dẫn đến số lượng đăng ký chủ đề gossip hoạt động cao hơn đáng kể. Các nút thông thường, chỉ tham gia vào 8 mạng con được chỉ định, sẽ có giá trị thấp hơn đáng kể trong các chỉ số đăng ký gossip.

Phần kết luận
Sự cố này chứng minh giá trị vận hành của việc giám sát toàn diện đối với các máy khách Consensus . Mặc dù bảng điều khiển không thể thay thế việc gỡ lỗi chính thức hoặc phân tích sau sự cố, nhưng chúng cung cấp khả năng hiển thị tức thời và hữu ích về tình trạng của máy khách và sự tham gia của mạng lưới.
Sự cố được trình bày có thể dễ dàng phát hiện thông qua nhiều khía cạnh đo lường độc lập — độ trễ đồng bộ hóa, xử lý Block , kết nối ngang hàng, mức độ sử dụng mạng và hoạt động cơ sở dữ liệu. Khả năng hiển thị đa lớp như vậy cho phép người vận hành nhanh chóng xác định các bất thường, đánh giá mức độ nghiêm trọng và thực hiện hành động khắc phục trong vòng vài phút thay vì hàng giờ.
Ngoài ra, việc xác định thiếu chỉ số phân phối các máy chủ kết nối sau bản phát hành cuối năm 2025 càng minh họa thêm một lợi ích quan trọng khác của việc theo dõi chỉ số dài hạn. Giám sát liên tục trên các phiên bản không chỉ giúp phát hiện lỗi trong quá trình hoạt động mà còn giúp phát hiện các lỗi hồi quy, sự không nhất quán của chỉ số và những thay đổi ngoài ý muốn trong chính khả năng quan sát. Nếu không có bảng điều khiển được cấu trúc và so sánh lịch sử, những vấn đề như vậy rất dễ bị bỏ qua.
Tóm Short, các bảng điều khiển được thiết kế tốt và duy trì liên tục không chỉ đơn thuần là các lớp trực quan hóa. Chúng tạo thành một giao diện vận hành thiết yếu cho hệ sinh thái Ethereum — cho phép các nhóm xác thực, nhà điều hành cơ sở hạ tầng và các nhà nghiên cứu phát hiện sự cố, xác nhận các bản vá lỗi, so sánh hành vi của máy khách và liên tục cải thiện độ tin cậy.




