Mặc dù không hoàn toàn liên quan đến tiền điện tử, nhưng bài viết này có liên quan đến thị trường dự đoán mà tôi đã từng viết trước đây và tôi tin rằng nó sẽ thu hút sự quan tâm của độc giả. Thêm vào đó, một vài độc giả đã yêu cầu tôi viết một bài đăng như thế này, vì vậy, đây là bài viết đó!
Tôi đã dành vài tuần qua để xây dựng một mô hình dự đoán nhằm xác định ai sẽ thắng trong các trận đấu cạnh tranh của Dota 2 (một trò chơi điện tử thể thao điện tử). Tôi đã thực hiện tất cả bằng phương pháp lập trình cảm tính với Claude Code (với một chút trợ giúp từ Yoshi thông qua openclaw, nhưng hoàn toàn có thể thực hiện trực tiếp bằng CC). Tôi không có bằng cấp về máy học và không có kiến thức về khoa học dữ liệu.
Mặc dù còn sớm, nhưng kết quả trông rất khả quan. Tôi đã kiểm tra lại mô hình và kết quả thực sự rất tuyệt vời . Thành thật mà nói, chúng trông quá tốt đến mức khó tin, vì vậy hãy đón nhận điều này với một thái độ hoài nghi:
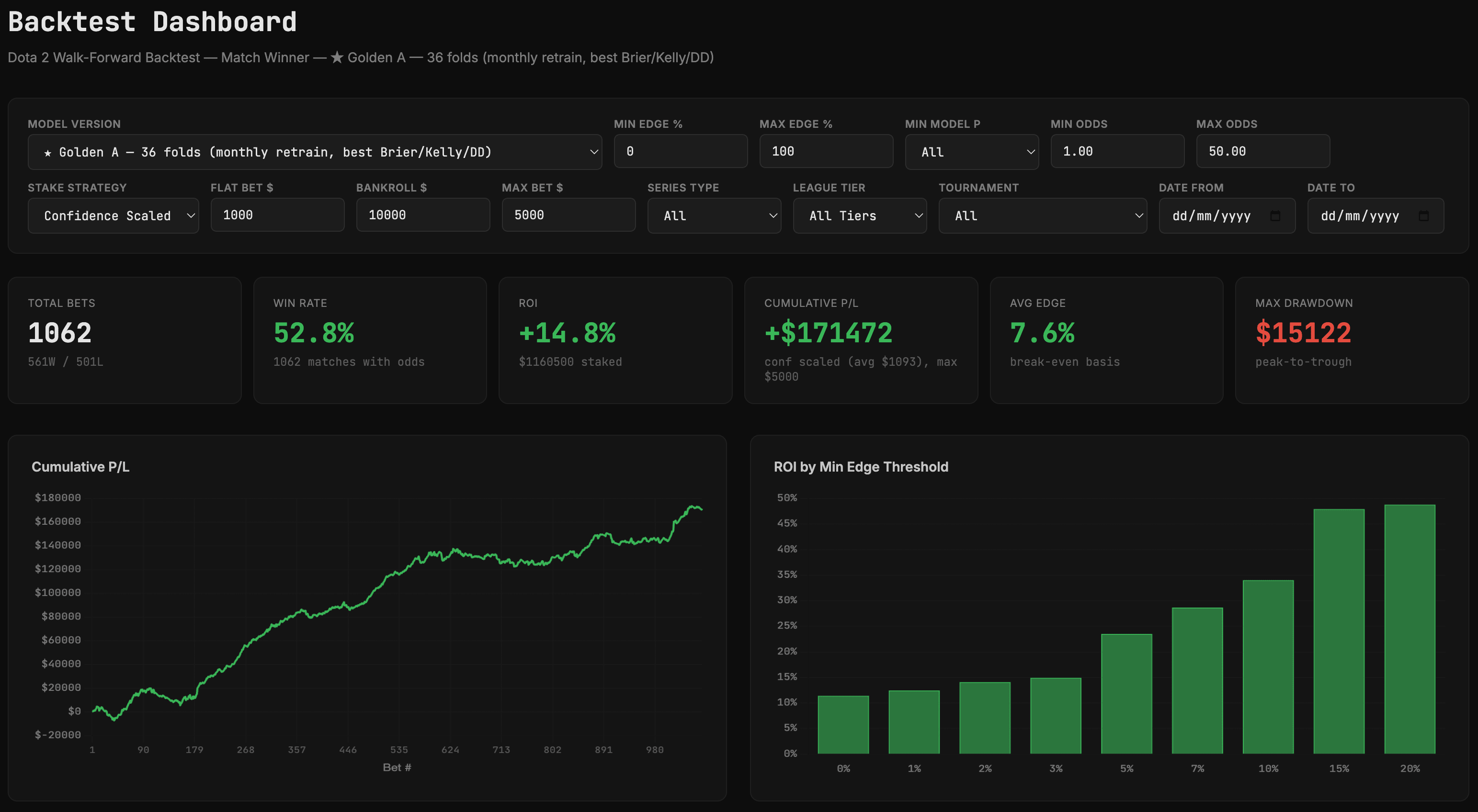
1. Bắt đầu với một câu hỏi rõ ràng và cụ thể.
Chất lượng câu hỏi của bạn quyết định chất lượng của tất cả những gì tiếp theo.
Một điểm khởi đầu tốt là tự hỏi bản thân:
2. Hãy nhờ AI hỗ trợ bạn trong từng bước.
Vậy nên, sau khi đã chọn được câu hỏi muốn trả lời, đã đến lúc bạn tải nền tảng mã hóa cảm xúc mà mình lựa chọn lên và bắt đầu yêu cầu AI hỗ trợ thêm. Tôi đã viết về Claude Code vài tuần trước và đó là nơi tôi xây dựng mô hình của mình. Tôi khuyên bạn nên sử dụng Claude Code với Opus 4.6 hoặc Codex với GPT 5.4 vì hiện tại chúng là hai mô hình tiên tiến nhất trong lĩnh vực mã hóa.
Dĩ nhiên bạn có thể thử với những mẫu máy kém hơn và thử nghiệm (và đó là một cách tuyệt vời để học hỏi), nhưng nếu bạn đang cố gắng kiếm tiền, tôi thực sự nghĩ bạn sẽ muốn sử dụng những mẫu máy cao cấp nhất.
Sau khi vào Claude Code/Codex, hãy tạo một dự án mới và bắt đầu bằng cách cho nó biết những gì bạn muốn, dựa trên câu hỏi mà bạn đã đặt ra. Ví dụ như:
Tôi muốn xây dựng một mô hình dự đoán Dota 2 để giúp dự đoán đội nào sẽ thắng trong một trận đấu. Tôi muốn bạn giúp tôi việc này. Hãy bắt đầu bằng cách nghiên cứu kỹ lưỡng để tìm hiểu mọi thứ bạn có thể về việc xây dựng mô hình dự đoán; cụ thể là các mô hình Dota 2 và thể thao điện tử. Hãy xem xét các bài báo nghiên cứu và bất kỳ bằng chứng nào về các mô hình thành công khác mà chúng ta có thể học hỏi. Chia sẻ các nguồn và bằng chứng đó với tôi. Hãy tổng hợp tất cả thông tin đó và lập một kế hoạch từng bước cho chúng ta và cho tôi biết chúng ta cần gì để bắt đầu.
Trí tuệ nhân tạo (AI) sẽ làm rất tốt việc lập kế hoạch từ đây, nhưng một điều tôi thấy rất hữu ích và quan trọng là tự mình đọc các nguồn tài liệu và bài nghiên cứu ( hoặc ít nhất là một vài bài). Tôi biết tất cả chúng ta đều đang tự rèn luyện bản thân để dựa vào các bản tóm tắt và gạch đầu dòng của AI, nhưng bạn thực sự cần hiểu một Bit về cách mọi thứ hoạt động bên trong; điều đó sẽ cực kỳ hữu ích khi bạn tiến về phía trước.
Tôi hy vọng phần còn lại của bức thư này sẽ cung cấp cho bạn một số bối cảnh và giúp bạn hiểu rõ hơn về những vấn đề này.
3. Bạn cần dữ liệu đáng tin cậy và sạch sẽ.
Mô hình của bạn học hỏi từ dữ liệu. Nếu dữ liệu sai, không đầy đủ hoặc không nhất quán, mô hình sẽ học được những điều sai lệch.
Đối với mô hình Dota 2 của tôi, tôi lấy phần lớn dữ liệu từ các API chính thức. Tôi luôn khuyên nên tìm kiếm các API tốt để lấy dữ liệu thay vì thu thập dữ liệu từ web. Đối với Dota, API tôi sử dụng có dữ liệu trận đấu toàn diện kéo dài nhiều năm. Bao gồm đội hình, chỉ số người chơi, kết quả trận đấu, thông tin cập nhật và nhiều hơn nữa. Dữ liệu được cấu trúc tốt, được ghi chép đầy đủ và cập nhật thường xuyên.
Thật không may (hoặc có thể là may mắn, vì điều này có thể tạo ra cơ hội), không phải mọi lĩnh vực đều có API tiện lợi dành cho bạn. Đôi khi bạn phải tự thu thập dữ liệu từ các trang web, phân tích PDF hoặc làm việc với các bảng tính phức tạp.
Thông thường, bạn vẫn phải làm Bit hai việc (tôi cũng thu thập dữ liệu thủ công, mặc dù 95% đến từ API).
Tóm lại, định dạng không quan trọng bằng độ tin cậy. Bạn cần tin tưởng rằng dữ liệu phản ánh chính xác những gì đã xảy ra. Sử dụng API dễ hơn, nhưng không phải là cách duy nhất để đạt được điều này.
Bên cạnh dữ liệu đáng tin cậy, dữ liệu sạch cũng rất quan trọng. Điều này có nghĩa là: không có bản ghi trùng lặp, định dạng nhất quán, không có giá trị thiếu trong các trường quan trọng và tài liệu rõ ràng về ý nghĩa của từng trường.
Trí tuệ nhân tạo giúp ích như thế nào?
Hãy yêu cầu nó viết các bài kiểm tra chất lượng dữ liệu. Ví dụ: “Hãy viết một Script để tải dữ liệu trận đấu của tôi, kiểm tra các bản ghi trùng lặp, đánh dấu bất kỳ trận đấu nào thiếu ID đội và hiển thị cho tôi sự phân bố các trận đấu theo tháng.” Bạn thậm chí có thể yêu cầu đơn giản hơn, chẳng hạn như “Tôi muốn đảm bảo dữ liệu của chúng ta sạch sẽ và đáng tin cậy, chúng ta có thể làm điều đó như thế nào?” và nó sẽ đưa ra một số gợi ý và kế hoạch, và bạn có thể tiếp tục từ đó.
4. Đặc điểm của bạn là tất cả
Các đặc trưng là một trong những yếu tố quan trọng nhất cần hiểu khi xây dựng mô hình dự đoán. Nói một cách ngắn gọn, các đặc trưng là dữ liệu đầu vào mà mô hình sử dụng để đưa ra dự đoán. Dữ liệu thô hiếm khi hữu ích khi đứng riêng lẻ. Bạn cần dữ liệu thô vì đó là thứ được sử dụng để tạo ra các đặc trưng, nhưng chính các đặc trưng mới là thứ thực sự được sử dụng để dự đoán mọi thứ.
Đối với Dota 2, một thống kê thô như "đội A đã chơi 200 trận" hầu như không cho bạn biết gì về việc ai sẽ thắng trận tiếp theo. Nhưng "đội A đã thắng 65% trong 20 trận gần nhất ở bản cập nhật hiện tại" lại cho bạn biết điều gì đó hữu ích về phong độ gần đây trong meta hiện tại.
Đây là lúc kiến thức chuyên môn của bạn phát huy tác dụng. Bạn hiểu rõ lĩnh vực của mình. Bạn biết những yếu tố nào ảnh hưởng đến kết quả. Nếu bạn là một người hâm mộ golf thực thụ, bạn biết rằng thời tiết có tác động, loại cỏ tạo nên sự khác biệt, việc người chơi bắt đầu vào buổi sáng hay buổi chiều có thể thay đổi khả năng ghi điểm tốt của họ, bạn biết rằng những người đánh xa sẽ chơi tốt hơn trên một số sân, v.v.
Mô hình của bạn ban đầu không biết bất cứ điều gì trong số này. Nó chỉ biết những gì bạn cung cấp cho nó thông qua các đặc trưng.
Các đặc điểm tốt nắm bắt thông tin có sẵn trước khi dự đoán, có liên quan đến kết quả và không trùng lặp với các đặc điểm khác.
Trí tuệ nhân tạo giúp ích như thế nào?
Hãy yêu cầu hệ thống đề xuất các tính năng như một điểm khởi đầu, để bạn có cái nhìn tổng quan về các loại công cụ bạn có thể sử dụng. Sau đó, mô tả chuyên môn của bạn và các yếu tố mà bạn cho là quan trọng để cùng nhau lên ý tưởng và lập danh sách các tính năng bổ sung mà bạn nghĩ có thể ảnh hưởng đến kết quả.
Sau đó, hãy yêu cầu nó tạo ra các tính năng đó từ dữ liệu thô của bạn. Nó sẽ viết mã chuyển đổi. Bạn đánh giá xem các tính năng đó có hợp lý hay không. Quá trình trao đổi qua lại này chính là điểm mạnh của lập trình dựa trên cảm nhận. Bạn đóng góp tư duy (ít nhất là một phần) và kiến thức chuyên môn của mình. Trí tuệ nhân tạo sẽ làm mọi thứ còn lại.
5. Chọn mô hình phù hợp
Bạn có câu hỏi, dữ liệu và các đặc điểm. Bây giờ bạn cần một thứ gì đó để lấy những đặc điểm đó và biến chúng thành một dự đoán. Thứ đó chính là mô hình.
Hãy coi mô hình như một hàm số. Bạn cung cấp cho nó các đầu vào (các đặc trưng) và nó sẽ trả về cho bạn một đầu ra (một dự đoán). Các loại mô hình khác nhau học hàm số này theo những cách khác nhau. Một số thì đơn giản, một số thì phức tạp. Lựa chọn đúng đắn phụ thuộc vào vấn đề của bạn, nhưng đối với hầu hết các nhiệm vụ dự đoán với dữ liệu có cấu trúc, câu trả lời đơn giản hơn bạn nghĩ.