Được rồi, mọi người có vẻ đang thích thú với nội dung về AI dạo gần đây nên chúng ta sẽ tiếp tục. Tuy nhiên, thị trường đang tăng trưởng mạnh mẽ nên chúng ta cần xem xét lại thị trường tiền điện tử trong thời gian tới và xem có gì đáng chú ý.
Nhưng hôm nay, chúng ta sẽ tìm hiểu những kiến thức cơ bản về LLM (Learning Level Modules). Tôi nhận thấy hầu hết những người sử dụng ChatGPT hoặc Claude hàng ngày đều không biết chúng hoạt động như thế nào.
Điều đó dĩ nhiên là ổn. Bạn không cần phải biết động cơ hoạt động như thế nào để lái xe. Nhưng tôi nghĩ việc có hiểu biết cơ bản về những gì đang diễn ra bên trong sẽ giúp bạn trở thành người dùng tốt hơn. Nó giúp bạn hiểu tại sao AI lại giỏi ở một số việc và kém ở những việc khác, giúp bạn đặt ra những câu hỏi tốt hơn, và khiến bạn ít có khả năng quá tin tưởng hoặc thiếu tin tưởng vào kết quả đầu ra.
Bài viết này khá dài, dưới đây là những nội dung chúng ta sẽ đề cập:
LLM là gì?
Một người học chương trình LLM “học” như thế nào?
Khoan đã, vậy ra đó là tính năng tự động hoàn thành à?
Token là gì?
Còn về các thông số thì sao?
Các mô hình LLM thực sự tạo ra phản hồi của chúng như thế nào?
Vậy những mô hình này thực sự "biết" những gì?
Huấn luyện khác với tinh chỉnh như thế nào?
Tại sao một số mô hình lại tốt hơn những mô hình khác?
Kích thước mô hình: tại sao một số có thể chạy trên máy tính xách tay của bạn, trong khi những mô hình khác cần trung tâm dữ liệu.
Việc biết tất cả những điều này giúp ích gì cho bạn?
Nếu bạn muốn nâng cao hơn nữa hành trình học tập về AI của mình, hãy xem công ty mới mà tôi vừa thành lập cùng với một vài người bạn: The Stoa of AI .
Chúng tôi tạo ra các khóa học video và tổ chức các buổi hội thảo và cuộc gọi trực tiếp hàng tuần để hướng dẫn bạn cách thực hiện AI một cách thiết thực vào quy trình làm việc hàng ngày.
Hiện tại chúng tôi đang trong giai đoạn truy cập sớm với giá ưu đãi, hãy xem chi tiết tại đây: https://www.skool.com/thestoaofai
LLM là gì?
LLM là viết tắt của Large Language Model (Mô hình Ngôn ngữ Lớn). Đó là nền tảng mà ChatGPT, Claude, Gemini và tất cả các chatbot AI khác được xây dựng dựa trên đó.
Ngôn ngữ. Các mô hình này hoạt động với ngôn ngữ. Văn bản đầu vào, văn bản đầu ra. Bạn gõ từ, chúng tạo ra từ. (Đúng vậy, giờ đây chúng cũng xử lý hình ảnh, âm thanh và mã lập trình, nhưng về bản chất, chúng là những cỗ máy ngôn ngữ, và từ "ngôn ngữ" có thể được sử dụng cho bất kỳ đầu vào/đầu ra nào được tạo ra bởi các mô hình ngôn ngữ tự nhiên này).
Mô hình. Trong trí tuệ nhân tạo, mô hình là một chương trình được huấn luyện trên dữ liệu để nhận dạng các mẫu. Nếu bạn cho một người chưa từng nhìn thấy mèo xem hàng triệu bức ảnh về các giống mèo khác nhau, cuối cùng họ sẽ trở nên giỏi trong việc phân biệt chúng. Mô hình tuyến tính (LLM) cũng dựa trên khái niệm tương tự.
Rất lớn. Các mô hình này RẤT LỚN. Chúng được huấn luyện trên lượng dữ liệu khổng lồ . Chúng ta đang nói đến một phần đáng kể của toàn bộ internet. Sách, bài báo, Wikipedia, diễn đàn, kho mã nguồn, bài báo học thuật. Hàng tỷ, thậm chí hàng nghìn tỷ từ.
Tóm lại, ta có: một chương trình đã đọc một lượng lớn văn bản của con người và học được các quy luật ngôn ngữ từ đó.
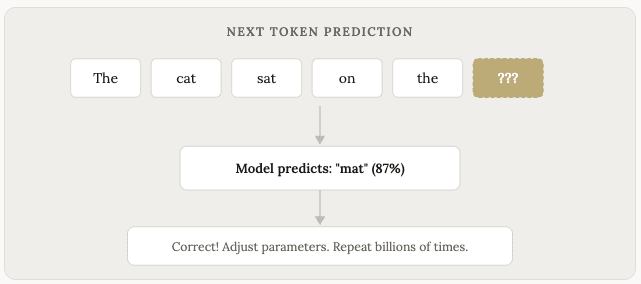
Khái niệm cốt lõi của quá trình "huấn luyện" khá đơn giản. Bạn lấy một câu, che đi từ cuối cùng, và yêu cầu mô hình dự đoán từ tiếp theo.
“Con mèo ngồi trên ___”
Mô hình đưa ra dự đoán. Nếu dự đoán sai, bạn điều chỉnh mô hình một chút để lần sau nó hoạt động tốt hơn. Sau đó, bạn thực hiện điều này hàng tỷ tỷ lần, với hàng tỷ tỷ câu.
Theo thời gian, mô hình trở nên giỏi hơn trong việc dự đoán từ tiếp theo. Rồi từ tiếp theo nữa. Và cứ thế tiếp tục. Cho đến khi nó tạo ra toàn bộ đoạn văn và trang sách nghe giống như do con người viết.
Đây là phiên bản đơn giản hóa của quy trình (thuật ngữ kỹ thuật là “dự đoán mã thông báo tiếp theo”), nhưng nó nắm bắt được ý tưởng cốt lõi. Về cơ bản, LLM là những cỗ máy dự đoán. Chúng dự đoán văn bản nào sẽ xuất hiện tiếp theo dựa trên tất cả những gì chúng đã thấy trước đó.
Đúng vậy. Đây là một sự so sánh được sử dụng rất nhiều, và nó phần nào chính xác.
Tính năng tự động hoàn thành trên điện thoại của bạn dự đoán từ tiếp theo dựa trên các mẫu đơn giản. Mô hình ngôn ngữ ký hiệu (LLM) cũng làm điều tương tự, nhưng với lượng dữ liệu khổng lồ, sức mạnh tính toán vượt trội và khả năng hiểu ngữ cảnh sâu sắc hơn nhiều.
Sự khác biệt về quy mô tạo ra sự khác biệt về bản chất. Chức năng tự động hoàn thành trên điện thoại của bạn có thể gợi ý dùng từ “the” sau từ “in”. Một người có bằng Thạc sĩ Luật (LLM) sẽ viết cho bạn một bài luận mạch lạc về vật lý lượng tử, duy trì lập luận nhất quán xuyên suốt 2.000 từ và định dạng đúng cách. Cả hai đều dự đoán từ tiếp theo. Một bên làm điều đó với chiều sâu và sự tinh tế đến mức tạo ra thứ trông và cảm giác như sự hiểu biết.
Liệu đó có phải là sự hiểu biết hay không là một trong những cuộc tranh luận lớn trong lĩnh vực trí tuệ nhân tạo hiện nay. Tôi nghĩ chúng ta không cần phải giải quyết vấn đề này ở đây. Điều quan trọng đối với mục đích thực tiễn là kết quả đầu ra phải hữu ích, và thường là rất ấn tượng.
Token là đơn vị mà các mô hình LLM sử dụng, và chúng cũng được coi như là đơn vị tiền tệ của các mô hình LLM. Khi bạn sử dụng mô hình biên giới từ Anthropic hoặc OpenAI, bạn thường sẽ trả tiền theo số token đã sử dụng.
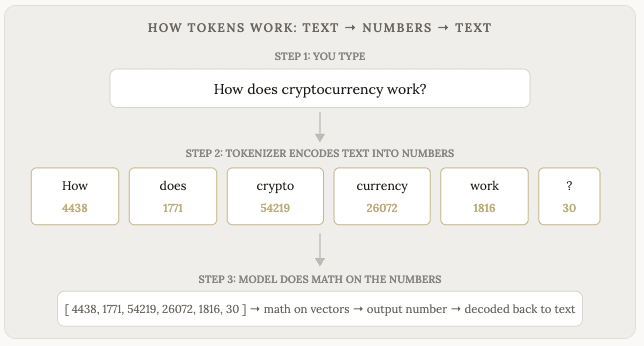
Đây là điều mà hầu hết mọi người không nhận ra: mô hình thực chất không bao giờ nhìn thấy từ ngữ của bạn . Nó chỉ nhìn thấy các con số.
Khi bạn gõ một tin nhắn, điều đầu tiên xảy ra là văn bản của bạn được mã hóa thành các token, trong đó mỗi token được gán một số. Từ “hello” có thể trở thành token 15339. Từ “the” có thể là token 1820. Từ “cryptocurrency” có thể được tách thành hai token: “crypto” (54219) và “currency” (26072).
Những con số này là dữ liệu mà mô hình sử dụng. Mọi phép tính diễn ra bên trong mô hình, tất cả các bước khớp mẫu, tất cả các dự đoán, đều được thực hiện bằng toán học trên các con số. Mô hình xử lý các con số này thông qua mạng nơ-ron của nó và cho ra... thêm nhiều con số nữa. Những con số đầu ra đó sau đó được giải mã trở lại thành các từ mà bạn đọc trên màn hình.
Mã hóa → Tính toán → Giải mã. Đó là toàn bộ vòng lặp.
Quá trình chuyển đổi văn bản thành số được gọi là mã hóa. Quá trình chuyển đổi các số đầu ra trở lại thành văn bản được gọi là giải mã. Bạn không bao giờ nhìn thấy các số, và mô hình cũng không bao giờ nhìn thấy các từ. Có một lớp chuyển đổi (gọi là bộ phân tách từ) nằm giữa bạn và mô hình, thực hiện mã hóa và giải mã qua lại.
Vậy điều gì xảy ra trong phần "toán học"? Mỗi số của từ được chuyển đổi thành một vectơ, là một danh sách dài các số (hàng trăm hoặc hàng nghìn số) đại diện cho ý nghĩa và ngữ cảnh của từ đó. Từ "bank" trong "river bank" sẽ có vectơ khác với từ "bank" trong "bank account" vì các từ xung quanh ảnh hưởng đến cách biểu diễn.
Mô hình sau đó chạy các vectơ này qua nhiều lớp tính toán, điều chỉnh và kết hợp chúng, so sánh từng token với mọi token khác để tìm ra mối quan hệ và ngữ cảnh (đây là cơ chế “chú ý” mà bạn có thể đã nghe đến). Sau hàng chục lớp như vậy, kết quả cuối cùng là một phân phối xác suất trên mọi token tiếp theo có thể có. Mô hình chọn một token, giải mã nó trở lại thành văn bản, và thế là xong! bạn thấy một từ xuất hiện trên màn hình.
Đây cũng là lý do tại sao các mô hình ngôn ngữ ký hiệu (LLM) đôi khi hoạt động kỳ lạ với những việc như đếm số chữ cái trong một từ hoặc thực hiện các phép toán. Mô hình không coi từ “strawberry” là dâu tây. Nó coi đó là một hoặc hai số hiệu. Nó không có khái niệm về các chữ cái riêng lẻ bởi vì những chữ cái đó đã được mã hóa đi trước khi mô hình xử lý chúng.
Một token xấp xỉ 3/4 của một từ, hoặc khoảng 4 ký tự. Những từ ngắn thông dụng như “the” hoặc “and” được tính là một token. Những từ dài hơn hoặc ít phổ biến hơn sẽ được chia thành nhiều token.
Điều này quan trọng với bạn vì các mô hình LLM có giới hạn về số lượng token mà chúng xử lý cùng một lúc. Giới hạn này được gọi là cửa sổ ngữ cảnh. Hãy coi nó như bộ nhớ làm việc của mô hình.
Nếu một mô hình có cửa sổ ngữ cảnh 200.000 token, điều đó có nghĩa là nó có thể ghi nhớ khoảng 150.000 từ cùng một lúc. Một số mô hình hiện nay còn hỗ trợ nhiều hơn thế. Claude Opus 4.6, Claude Sonnet 4.6 và Gemini đều hỗ trợ cửa sổ ngữ cảnh 1 triệu token. Con số này tương đương khoảng 750.000 từ, hoặc khoảng 10 đến 15 cuốn tiểu thuyết hoàn chỉnh. Llama 4 Scout của Meta hỗ trợ tới 10 triệu token trong cửa sổ ngữ cảnh. Đây là những con số đáng kinh ngạc so với vài năm trước.
Nhưng cần lưu ý rằng cửa sổ ngữ cảnh lớn hơn không nhất thiết là tốt hơn về bản chất.
Khi bạn nhồi nhét ngày càng nhiều token vào cửa sổ ngữ cảnh, chất lượng phản hồi của mô hình có xu hướng giảm sút. Các nhà nghiên cứu gọi đây là “sự suy giảm ngữ cảnh”. Mô hình không chú ý đồng đều đến mọi thứ trong ngữ cảnh của nó. Nó có xu hướng chú ý nhiều nhất đến những thứ ở gần đầu và cuối, và ít chú ý hơn đến những thứ ở giữa. Một bài nghiên cứu năm 2023 đã phát hiện ra rằng khi thông tin liên quan bị chôn vùi ở giữa một ngữ cảnh dài, các mô hình hoạt động kém hơn đáng kể trong việc tìm kiếm và sử dụng nó.
Điều này có nghĩa là việc cung cấp thêm ngữ cảnh cho mô hình không phải lúc nào cũng tốt hơn. Nếu bạn đưa 500.000 từ khóa của các tài liệu có liên quan lỏng lẻo vào cửa sổ ngữ cảnh và câu hỏi thực tế của bạn liên quan đến một chi tiết nào đó ở giữa, bạn có thể nhận được câu trả lời kém hơn so với việc chỉ cung cấp 10.000 từ khóa liên quan nhất. Ngữ cảnh chất lượng quan trọng hơn ngữ cảnh số lượng. Điều này nghe có vẻ hơi ngược với trực giác, nhưng đó là cách nó hoạt động.
Cũng giống như mọi thứ liên quan đến trí tuệ nhân tạo, các mô hình cũng đang ngày càng tốt hơn trong lĩnh vực này. Claude đạt điểm cao nhất trong các bài kiểm tra ngữ cảnh dài, và khoảng cách về hiệu năng giữa ngữ cảnh ngắn và ngữ cảnh dài đang thu hẹp dần qua mỗi thế hệ.
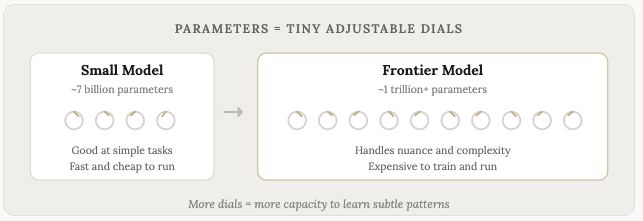
Đây là một con số khổng lồ khác mà bạn thường nghe đến. Nhiều mô hình quảng cáo có hàng tỷ hoặc hàng trăm tỷ tham số; một số thậm chí có hàng nghìn tỷ. Nhưng tham số thực chất là gì?
Các tham số là các thiết lập nội bộ của mô hình. Hãy tưởng tượng chúng như những núm xoay nhỏ, và trong quá trình huấn luyện, mỗi núm xoay này sẽ được điều chỉnh một chút mỗi khi mô hình đưa ra dự đoán và nhận phản hồi về việc dự đoán đó đúng hay sai.
Nói một cách cụ thể hơn, tham số là những con số xác định cách các vectơ được đề cập ở phần trước được biến đổi khi chúng đi qua mô hình. Chúng kiểm soát những thứ như: từ này nên chú ý đến từ kia bao nhiêu? Khái niệm này nên liên quan đến khái niệm kia như thế nào? Những mẫu nào là quan trọng và những mẫu nào là nhiễu?
Mỗi kết nối giữa các nơ-ron trong mạng nơ-ron đều có một tham số (trọng số) kiểm soát độ mạnh của kết nối đó. Một mô hình 7 tỷ tham số có 7 tỷ kết nối như vậy. Một mô hình nghìn tỷ tham số có một nghìn tỷ kết nối. Mỗi mô hình đều được tinh chỉnh từng chút một, qua hàng nghìn tỷ ví dụ huấn luyện.
Một mô hình có nhiều tham số hơn sẽ có nhiều "nút điều chỉnh" hơn, điều đó có nghĩa là nó có khả năng học được nhiều mẫu phức tạp và tinh tế hơn. Một mô hình nhỏ có thể học được rằng "con mèo ngồi trên tấm thảm" là một mẫu phổ biến. Một mô hình lớn cũng học được điều đó, nhưng nó còn học được rằng ý nghĩa của một đoạn văn sẽ thay đổi khi bạn sử dụng từ "tuy nhiên", hoặc một câu hỏi được đặt ra một cách lịch sự thường mong đợi một câu trả lời khác so với một câu hỏi thẳng thừng. Mô hình càng lớn, nó càng nắm bắt được nhiều mối quan hệ tinh tế hơn.
Nhiều tham số hơn thường đồng nghĩa với mô hình thông minh hơn, mặc dù đó không phải là yếu tố duy nhất. Chất lượng dữ liệu huấn luyện, các quyết định về kiến trúc và việc tinh chỉnh cũng rất quan trọng, và chúng ta sẽ thảo luận về điều đó sau. Nhưng nếu các yếu tố khác đều như nhau, nhiều tham số hơn đồng nghĩa với khả năng học hỏi độ phức tạp cao hơn.
Sự đánh đổi nằm ở tài nguyên. Mỗi tham số đều chiếm bộ nhớ. Việc chạy một mô hình có nghĩa là phải tải tất cả các tham số đó vào RAM (hoặc bộ nhớ GPU) và thực hiện các phép toán trên chúng cho mỗi token được tạo ra. Đó là lý do tại sao các mô hình lớn hơn cần phần cứng đắt tiền hơn, tốn nhiều chi phí hơn để chạy và tạo ra token chậm hơn.
Bạn không cần phải nhớ chính xác các con số hoặc hiểu rõ cách mọi thứ hoạt động như thế nào đối với những việc này.
Tóm lại: tham số = khả năng học hỏi độ phức tạp của mô hình.
Khi bạn nhắn tin cho Claude hoặc ChatGPT, về cơ bản quá trình sẽ diễn ra như sau:
Tin nhắn của bạn sẽ được chuyển đổi thành các mã thông báo (số).
Mô hình xử lý những con số đó thông qua mạng nơ-ron của nó (hàng tỷ tham số).
Nó dự đoán mã thông báo (số) tiếp theo có khả năng xuất hiện cao nhất.
Con số đó được thêm vào chuỗi và mô hình dự đoán con số tiếp theo.
Lặp lại, từng từ một, cho đến khi nhận được phản hồi hoàn chỉnh.
Đây là lý do tại sao bạn thấy văn bản xuất hiện từng từ một khi AI đang phản hồi. Nó đang tạo ra phản hồi theo thời gian thực, từng phần một. Nó không viết toàn bộ câu trả lời rồi mới tiết lộ. Nó đang tìm ra câu trả lời trong quá trình xử lý.
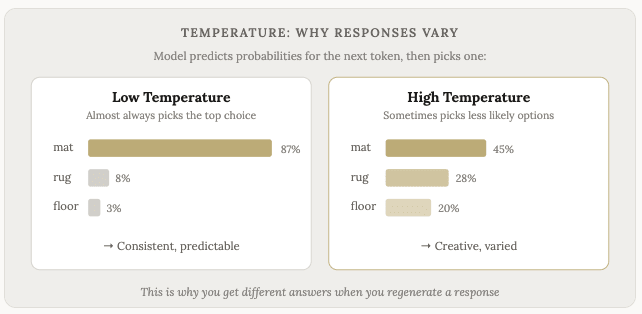
Đây cũng là lý do tại sao cùng một câu hỏi đôi khi lại cho ra những câu trả lời khác nhau. Có một mức độ ngẫu nhiên (gọi là “nhiệt độ”) được tích hợp vào quá trình lựa chọn. Mô hình không phải lúc nào cũng chọn từ khóa tiếp theo có khả năng xảy ra cao nhất. Đôi khi nó chọn tùy chọn có khả năng xảy ra cao thứ hai hoặc thứ ba, điều này dẫn đến câu trả lời hơi khác một chút.
Trên hầu hết các mẫu máy, bạn cũng có thể điều chỉnh cài đặt này và yêu cầu máy sử dụng nhiều phản hồi ít chuẩn mực hơn. Điều này hữu ích nếu bạn đang làm những việc như viết sáng tạo hoặc bất cứ điều gì cần tư duy đột phá. Đối với bất cứ điều gì yêu cầu sự chính xác và dữ liệu thực tế, các mẫu máy ở nhiệt độ thấp thường hoạt động tốt hơn.
Mô hình LLM không có cơ sở dữ liệu các sự kiện để tra cứu. Chúng không tìm kiếm trong tủ hồ sơ khi bạn hỏi chúng một câu hỏi. Thay vào đó, kiến thức được nhúng trong các mẫu tham số của chúng. Mô hình đã học được rằng một số sự kiện nhất định có xu hướng xuất hiện trong những ngữ cảnh nhất định, và nó tái tạo lại chúng khi ngữ cảnh yêu cầu.
Đây là lý do tại sao các mô hình ngôn ngữ ký hiệu đôi khi bịa đặt ra mọi thứ. Cộng đồng AI gọi đây là "ảo giác". Mô hình không nói dối. Nó đang tạo ra văn bản nghe có vẻ như là sự tiếp nối có khả năng xảy ra nhất của cuộc hội thoại, và đôi khi điều nghe có vẻ có khả năng xảy ra nhất lại không đúng. Nó đang dự đoán, chứ không phải ghi nhớ.
Đây là một trong những điều quan trọng nhất cần hiểu về các phần mềm soạn thảo văn bản (LLM). Chúng được tối ưu hóa để tạo ra văn bản nghe hay , chứ không phải văn bản đúng . Hai điều này thường trùng lặp, nhưng không phải lúc nào cũng vậy.
Nguyên tắc chung: thông tin càng mơ hồ hoặc càng cụ thể, mô hình càng dễ đưa ra kết quả sai hoặc bịa đặt. Nếu bạn hỏi về các chủ đề đã được ghi chép đầy đủ và xuất hiện thường xuyên trong dữ liệu huấn luyện, mô hình khá đáng tin cậy. Nếu bạn hỏi về các chủ đề chuyên biệt, sự kiện gần đây hoặc các con số cụ thể, thì hãy kiểm tra lại kết quả đầu ra.
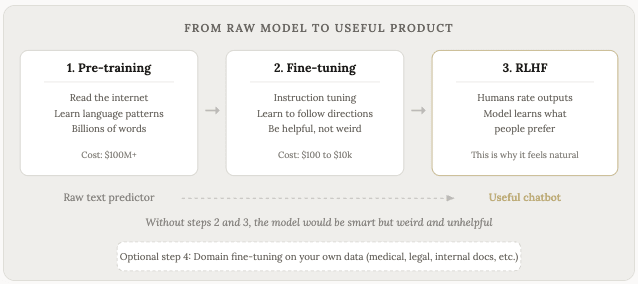
Huấn luyện là quá trình ban đầu, trong đó mô hình đọc toàn bộ văn bản và học các mẫu. Quá trình này tốn kém và mất nhiều thời gian. Chỉ riêng chi phí tính toán đã tiêu tốn hàng trăm triệu đô la để huấn luyện một mô hình tiên tiến (giai đoạn này đôi khi được gọi là tiền huấn luyện vì nó diễn ra trước bất kỳ sự tinh chỉnh nào nữa).
Kết quả của quá trình huấn luyện trước được gọi là mô hình cơ sở. Mô hình cơ sở rất thông minh và hiểu biết nhiều về ngôn ngữ, nhưng cách giao tiếp với chúng lại khá kỳ lạ. Nếu bạn hỏi một mô hình cơ sở một câu hỏi, nó có thể tiếp tục đoạn văn của bạn như thể đang viết một bài báo trên Wikipedia, hoặc tạo ra các bài đăng ngẫu nhiên trên diễn đàn, hoặc hoàn thành câu của bạn theo một hướng mà bạn không ngờ tới. Nó không biết rằng mình phải giúp đỡ. Nó là một cỗ máy dự đoán văn bản, nhưng không phải là một trợ lý đàm thoại như chúng ta thường dùng, ví dụ như ChatGPT, v.v.
Tinh chỉnh là bước biến một mô hình cơ bản thành một thứ hữu ích. Đó là vòng huấn luyện thứ hai, được thực hiện trên một tập dữ liệu nhỏ hơn nhiều và được chọn lọc kỹ lưỡng hơn. Đây là nơi mô hình học cách làm theo hướng dẫn, trả lời câu hỏi, trò chuyện và nói chung là hành xử theo cách bạn mong đợi ở một chatbot.
Có một vài loại tinh chỉnh khác nhau đáng để bạn biết đến:
Sự khác biệt về chi phí giữa huấn luyện trước và tinh chỉnh là rất lớn . Việc huấn luyện trước GPT-5 hoặc Claude từ đầu có giá hàng trăm triệu đô la. Trong khi đó, việc tinh chỉnh một mô hình mã nguồn mở trên dữ liệu của riêng bạn có giá từ vài đô la đến vài nghìn đô la, tùy thuộc vào kích thước của mô hình và lượng dữ liệu bạn sử dụng.
Đây là một trong những lý do tại sao các mô hình mã nguồn mở lại quan trọng đến vậy. Bạn có thể sử dụng một mô hình cơ bản miễn phí như Llama hoặc Mistral, tinh chỉnh nó cho phù hợp với dữ liệu cụ thể của mình, và cuối cùng bạn sẽ có một mô hình tùy chỉnh hiểu rõ lĩnh vực của bạn, chạy trên phần cứng của riêng bạn và không tốn phí cho mỗi truy vấn. Điều này rất quan trọng đối với các doanh nghiệp xử lý lượng lớn dữ liệu và không muốn gửi dữ liệu đó đến API của bên thứ ba.
Chúng ta đã đề cập đến vấn đề này một chút rồi, nhưng để làm rõ và mở rộng thêm một vài yếu tố chi tiết hơn:
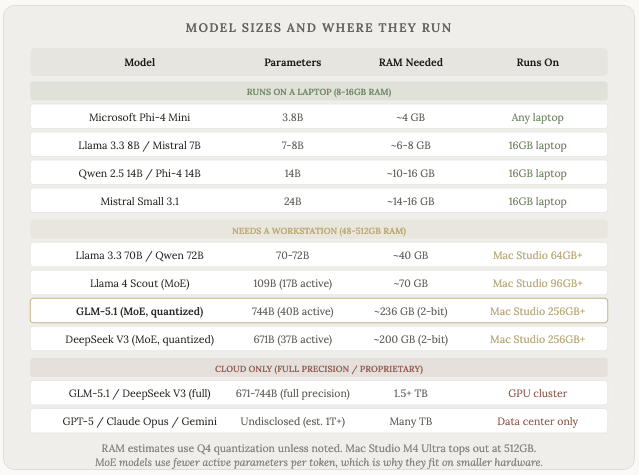
Như chúng ta đã biết, không phải tất cả các mô hình đều có cùng kích thước. Số lượng tham số rất khác nhau, và điều đó trực tiếp quyết định phần cứng bạn cần để vận hành chúng.
Một quy tắc chung: mỗi tỷ tham số cần khoảng 0,5 đến 1 GB RAM (tùy thuộc vào độ chính xác/lượng tử hóa). Một mô hình 7 tỷ tham số cần khoảng 4-8 GB RAM. Một mô hình 70 tỷ tham số cần khoảng 40 GB. Các mô hình tiên tiến từ OpenAI, Anthropic và Google có hàng trăm tỷ đến hơn một nghìn tỷ tham số, và chúng yêu cầu các cụm GPU chuyên dụng khổng lồ có giá hàng triệu đô la.
Đây là lý do tại sao một số mô hình có thể chạy cục bộ trên máy tính của bạn, trong khi những mô hình khác chỉ có thể truy cập thông qua API đám mây. Bạn phải trả phí theo từng token để sử dụng GPT-5 hoặc Claude vì cơ sở hạ tầng cần thiết để vận hành chúng rất lớn. Nhưng bạn có thể tải xuống và chạy Llama 8B hoặc Mistral 7B trên một chiếc máy tính xách tay tốt mà không mất phí.
Ngoài ra còn có một kỹ thuật gọi là Hỗn hợp các Chuyên gia (Mixture of Experts - MoE), trong đó một mô hình có tổng số tham số rất lớn nhưng chỉ kích hoạt một phần nhỏ trong số đó cho mỗi token. DeepSeek V3 có tổng cộng 671 tỷ tham số nhưng chỉ sử dụng 37 tỷ tham số cho mỗi token. GLM-5.1 có tổng cộng 744 tỷ tham số nhưng chỉ có 40 tỷ tham số được kích hoạt. Điều này cho phép các mô hình lớn chạy trên phần cứng nhỏ hơn so với dự kiến.
Khoảng cách về chất lượng giữa các mẫu máy nhỏ nhất và lớn nhất là có thật, nhưng nó cũng đang thu hẹp lại. Một mẫu máy 14B với cấu hình phù hợp chạy trên máy tính xách tay của bạn ngày nay có thể thực hiện tốt các tác vụ đơn giản và hàng ngày, ngay cả khi so sánh với các mẫu máy tiên tiến nhất (mặc dù có thể chậm hơn).
Khoảng cách này dễ nhận thấy nhất ở những bài toán suy luận phức tạp nhiều bước, viết văn sáng tạo dài và những nhiệm vụ đòi hỏi nhiều kiến thức về thế giới. Đối với những công việc thường ngày như soạn thảo email, tóm tắt tài liệu hoặc trả lời câu hỏi, các mô hình cục bộ lại hoạt động tốt một cách đáng ngạc nhiên.
Và tất nhiên không phải tất cả các mô hình cục bộ đều giống nhau. GLM5.1 là một mô hình tốt đáng ngạc nhiên có thể chạy trên máy Mac Studio, mặc dù vẫn rất đắt tiền (5-10 nghìn đô la trở lên), nhưng không đáng kể so với hàng triệu đô la mà các trung tâm dữ liệu khổng lồ tốn kém để xây dựng.
Ý tôi là, hy vọng bạn cũng thấy những điều này thú vị như tôi! Kiến thức rất có giá trị, và việc hiểu cách mọi thứ hoạt động cũng quan trọng, ngay cả khi bạn không thực sự cần biết điều đó để sử dụng chúng.
Một phần giá trị đó đến từ những thay đổi mà bạn có thể thực hiện khi sử dụng các công cụ này.
Khi bạn biết rằng mô hình đang dự đoán từ tiếp theo dựa trên các mẫu, bạn sẽ hiểu tại sao việc cung cấp thêm ngữ cảnh lại dẫn đến kết quả tốt hơn. Bạn hiểu tại sao việc cụ thể trong các lời nhắc lại quan trọng. Bạn hiểu tại sao đôi khi nó lại tự tin nói những điều sai.
Khi bạn hiểu về "cửa sổ ngữ cảnh", bạn sẽ hiểu tại sao những cuộc trò chuyện dài đôi khi lại đi chệch hướng.
Khi bạn hiểu về nhiệt độ và tính ngẫu nhiên, bạn sẽ hiểu tại sao việc tạo lại phản hồi đôi khi lại mang đến kết quả tốt hơn (hoặc tệ hơn). Đó là một con đường khác trong không gian xác suất. Và việc biết rằng bạn có thể điều chỉnh cài đặt nhiệt độ tùy thuộc vào nhiệm vụ sẽ cho phép bạn tận dụng những công cụ này theo cách phù hợp với nhu cầu cụ thể của mình.
Bạn cũng bắt đầu hiểu rõ những công cụ này là gì và không phải là gì. Chúng không phải là công cụ tìm kiếm (mặc dù hiện nay chúng đã tích hợp chức năng tìm kiếm). Chúng không phải là cơ sở dữ liệu. Chúng không phải là những nhà tiên tri. Chúng là những cỗ máy đối sánh mẫu với độ tinh vi phi thường, được huấn luyện trên một phần lớn kiến thức viết của nhân loại (và sau đó được huấn luyện/tinh chỉnh thêm bằng phản hồi bổ sung và được chọn lọc từ con người).
Điều đó khiến chúng trở nên hữu ích.
Điều đó cũng khiến họ dễ mắc sai lầm theo những cách cụ thể và có thể dự đoán được.
Nắm vững tất cả những điều này sẽ giúp bạn trở thành người dùng tốt hơn và tự tin hơn trong việc sử dụng tính năng nhắc nhở trong tương lai.
Tuyên bố miễn trừ trách nhiệm: Nội dung trong bản tin này không được coi là lời khuyên đầu tư. Tôi không phải là cố vấn tài chính. Đây chỉ là ý kiến và quan điểm cá nhân của tôi. Bạn nên luôn tham khảo ý kiến của cố vấn tài chính chuyên nghiệp/có giấy phép trước khi giao dịch hoặc đầu tư vào bất kỳ sản phẩm liên quan đến tiền điện tử nào. Một số liên kết được chia sẻ có thể là liên kết giới thiệu.