

Nghiên cứu ban đầu của tôi cho thấy rằng có thể giảm thêm 30% dung lượng lưu trữ cho mã hợp đồng, ngoài việc loại bỏ mã trùng lặp và nén mã hợp đồng tại thời điểm lưu trữ.
Tất nhiên, trình biên dịch Solidity và mọi trình biên dịch khác đều sẽ tạo ra mã bytecode với các mẫu mã lệnh. Khi nén một hợp đồng riêng lẻ, thuật toán nén lý tưởng sẽ học các mẫu này sau khi chúng xuất hiện một lần trong hợp đồng đó, và sau đó có thể tham chiếu đến chúng theo cách rút gọn trong suốt phần còn lại của hợp đồng.
Tuy nhiên, điều này có nghĩa là thuật toán nén luôn bị bất ngờ bởi lần xuất hiện đầu tiên của một mẫu trong một hợp đồng riêng lẻ, bởi vì thuật toán không biết rằng mẫu này phổ biến trong nhiều hợp đồng thông minh, và do đó chỉ có thể học hỏi từ hợp đồng riêng lẻ mà nó đang xử lý.
Giải pháp cho vấn đề này đã được tích hợp sẵn trong hầu hết các thư viện thuật toán nén - bạn có thể cung cấp một "từ điển" nhỏ được huấn luyện trước, mã hóa các mẫu phổ biến đã từng xuất hiện trong dữ liệu lịch sử. Điều này cho phép nén ngay lập tức các mẫu phổ biến khi chúng xuất hiện lần đầu trong dữ liệu mới.
Lợi ích thứ hai là, khi sử dụng từ điển được huấn luyện trước, nó cũng ghi nhớ các mẫu lớn từ các hợp đồng spam/lỗi spam xuất hiện quá nhiều. Đối với những hợp đồng đã bị spam hàng chục nghìn lần với những biến thể nhỏ, từ điển có thể giảm số lượng lỗi này xuống chỉ còn vài phần trăm so với kích thước ban đầu.
Đây là kết quả:
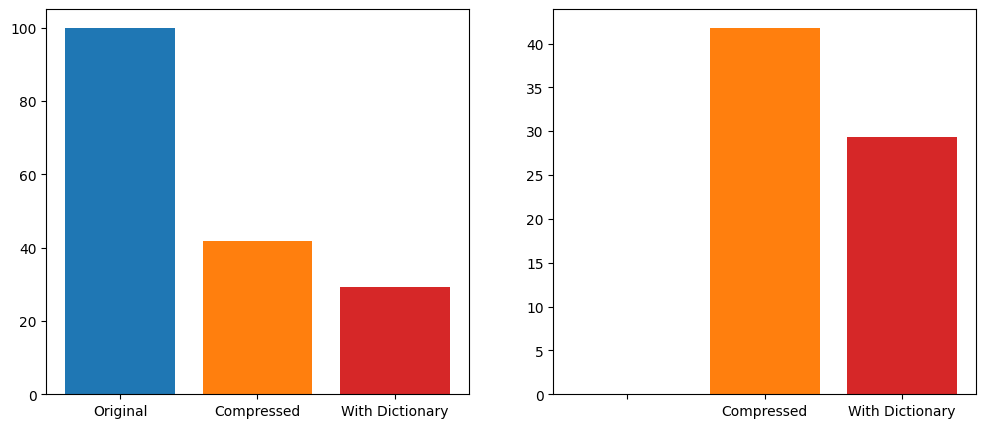
Sử dụng bộ dữ liệu zelliac về tất cả mã bytecode hợp đồng đã được triển khai cho đến đầu năm 2025, có 1,539,858 bộ mã bytecode đã được loại bỏ trùng lặp và đã được triển khai.
Sử dụng thư viện nén Zstandard ở mức nén nhanh mặc định là 3, và nén từng tập mã bytecode riêng lẻ, tổng kích thước giảm từ 100% xuống còn 41.8% so với kích thước ban đầu. Thêm vào đó là một từ điển 100KB, được huấn luyện ở cài đặt mặc định cho mức nén, dẫn đến mã bytecode chiếm 29.3% kích thước ban đầu, giảm 30% so với kích thước đã nén.
Việc tăng kích thước từ điển nén hoặc tăng mức độ nén hơn nữa sẽ làm giảm kích thước cuối cùng. Tôi đã tối ưu hóa điều này để đạt tốc độ cao nhất. Cũng rất có thể việc tinh chỉnh thêm các tham số huấn luyện từ điển có thể dẫn đến kích thước nhỏ hơn nữa.
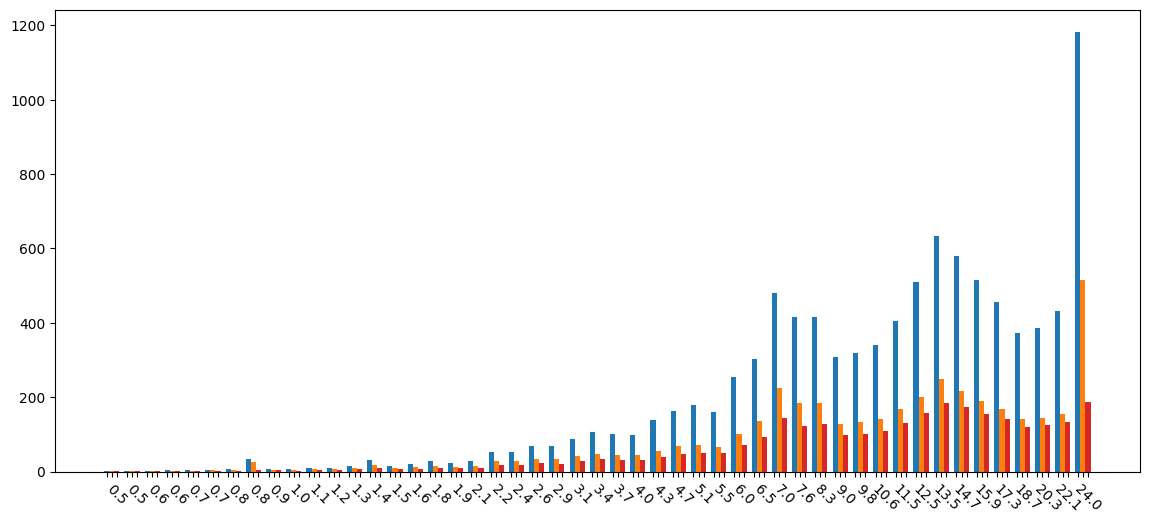
Tổng dung lượng lưu trữ cần thiết cho các mã byte hợp đồng có kích thước khác nhau:
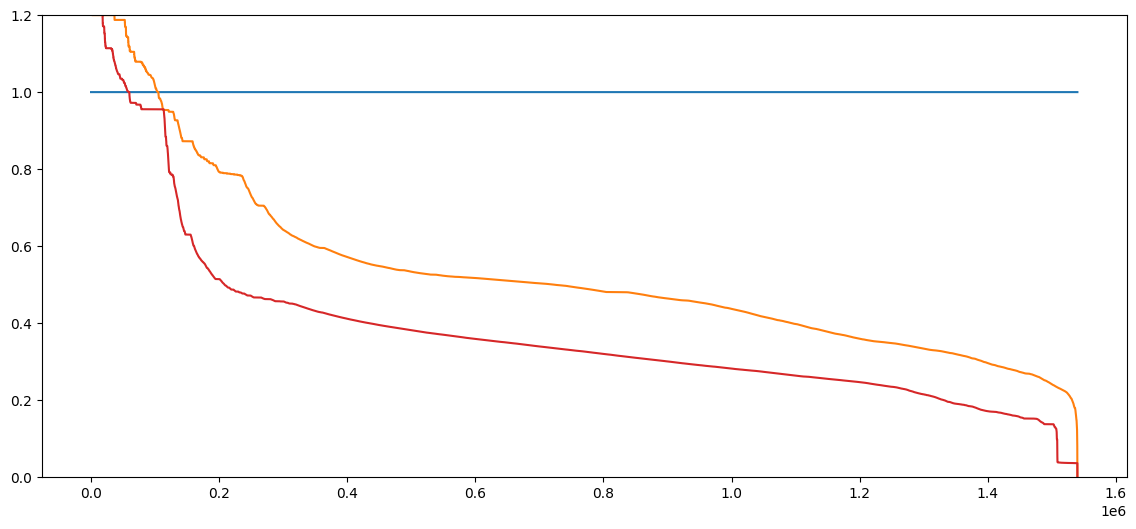
Xếp hạng từ hiệu suất kém nhất đến tốt nhất trên tất cả các hợp đồng.
Lời kết:
- Nếu sử dụng điều này ở phía máy khách, tôi cho rằng nên lưu trữ một byte duy nhất để biết liệu hợp đồng có được nén hay không, và nếu có thì từ điển/ ALGO nào đã được sử dụng. Điều này sẽ cho phép nâng cấp mượt mà lên các từ điển tốt hơn trong tương lai, cũng như tránh việc nén các tệp mà việc nén lại làm cho chúng trở nên tệ hơn.
- Tôi sử dụng thư viện nén zstandard đơn giản vì tôi đã có những trải nghiệm tốt với nó trong quá khứ. Tôi chưa so sánh các thư viện hoặc thuật toán nén khác nhau ở thời điểm này.





