Tôi nghĩ đây là một trong những bài viết hữu ích nhất mà tôi đã viết trong thời gian gần đây. Mặc dù không hoàn toàn liên quan đến mật mã, nhưng nó rất phù hợp với những bài đăng gần đây của tôi về các tác nhân AI và Claude Code , những bài viết đã nhận được rất nhiều sự quan tâm.
Mỗi khi tôi đề cập đến AI trong bản tin này, thường là liên quan đến các công cụ AI đám mây lớn như Claude, ChatGPT, Gemini, ETC Cách thức hoạt động của các mô hình này là bạn nhập một câu lệnh, nó được gửi đến máy chủ ở đâu đó, được xử lý và phản hồi được trả về. Đơn giản vậy thôi. Điều này cũng tương tự cho dù bạn đang sử dụng giao diện trang web hay lập trình chuyên sâu trong Claude Code bằng gói đăng ký Claude Max của mình.
Nhưng ngoài kia còn cả một thế giới khác về trí tuệ nhân tạo mã nguồn mở hoạt động hoàn toàn trên máy tính của bạn. Đó là các hệ thống quản lý học tập cục bộ (LLM), và đến năm 2026, chúng đã trở nên thực sự tốt.
Không có gì ngạc nhiên khi lĩnh vực này đang phát triển rất nhanh. Chỉ trong hai tuần qua, GLM-5.1 đã trở thành mô hình mã nguồn mở đầu tiên vượt qua Claude Opus 4.6 trong một bài kiểm tra hiệu năng lập trình quan trọng. Sau đó, Kimi K2.6 ra mắt vào đầu ngày hôm nay và đã giành lấy vị trí dẫn đầu từ GLM. Các công cụ và mô hình ngày càng được cải thiện, và khoảng cách giữa điện toán đám mây và điện toán cục bộ ngày càng thu hẹp.
Tôi đã tìm hiểu và thử nghiệm các mô hình cục bộ trên máy Mac Studio của mình trong tuần qua và (rất vui mừng) khi thấy chúng có khả năng đến thế. Rõ ràng là chúng không tốt bằng Claude Opus 4.7 và các mô hình tiên tiến khác cho những tác vụ siêu phức tạp, nhưng đối với phần lớn công việc hàng ngày của tôi, các mô hình cục bộ thực sự hữu ích. Và miễn phí. Và riêng tư. Và luôn sẵn có.
Ngay cả khi bạn vẫn duy trì các gói dịch vụ đám mây (tôi cũng vậy), việc có một mô hình cục bộ để sao lưu hoặc thực hiện các tác vụ cụ thể là một trong những quyết định tốt nhất bạn có thể đưa ra.
Nó thực sự rất hấp dẫn và thú vị, và việc học cách sở hữu và vận hành mô hình của riêng mình là một kỹ năng rất tốt cần học trong thời đại ngày nay.
Dưới đây là những nội dung chúng ta sẽ đề cập trong bài viết hôm nay:
Tại sao cần sử dụng mô hình cục bộ?
Phần cứng: Bạn cần những gì?
Các công cụ phần mềm
Nên chọn mô hình nào cho nhiệm vụ nào?
Bắt đầu
Kết nối các mô hình địa phương với các tác nhân AI
Lời kết
Nếu bạn muốn nâng cao hơn nữa hành trình học tập về AI của mình, hãy xem công ty mới mà tôi vừa thành lập cùng với một vài người bạn: The Stoa of AI .
Chúng tôi tạo ra các khóa học video và tổ chức các buổi hội thảo và cuộc gọi trực tiếp hàng tuần để hướng dẫn bạn cách thực hiện trí tuệ nhân tạo (AI) một cách thiết thực vào quy trình làm việc hàng ngày.
Hiện tại chúng tôi đang trong giai đoạn truy cập sớm với giá ưu đãi, hãy xem chi tiết tại đây: https://www.skool.com/thestoaofai
Tại sao cần sử dụng mô hình cục bộ?
Năm lý do chính.
Bảo mật thông tin cá nhân. Các lời nhắc, tệp và cuộc trò chuyện của bạn đều được lưu trữ trên máy tính của bạn. Không có máy chủ bên thứ ba nào. Đối với bất kỳ ai làm việc với dữ liệu nhạy cảm, mã nguồn độc quyền hoặc tài liệu mật, đây là một vấn đề vô cùng quan trọng. Chưa kể đến những người chỉ đơn giản là quan tâm đến quyền riêng tư cá nhân của họ và không muốn Trí tuệ Nhân tạo (AI) theo dõi họ (hoặc tệ hơn, làm rò rỉ dữ liệu của họ cho các đối tượng xấu).
Chi phí. Khi đã có phần cứng, việc suy luận là miễn phí. Nếu bạn sử dụng AI nhiều, các mô hình cục bộ thường sẽ tự hoàn vốn nếu có đủ thời gian. Bạn cũng có thể tận dụng các thiết bị cũ ở nhà để chạy các mô hình cục bộ.
Không có giới hạn tốc độ. Các mô hình Frontier tiêu tốn tín dụng rất nhanh . Việc có một mô hình dự phòng cục bộ là một điều tuyệt vời, cũng như việc có các mô hình chạy các tác vụ sẽ không bao giờ đạt đến giới hạn tốc độ (và không tính vào giới hạn tốc độ hiện có của bạn). Hầu hết mọi người sử dụng phương pháp "một kích cỡ phù hợp cho tất cả" đối với AI và sử dụng các mô hình như Opus và Sonnet cho các tác vụ đơn giản mà chúng hoàn toàn không cần thiết, và một mô hình cục bộ đơn giản hơn nhiều có thể làm tốt tương tự.
Truy cập ngoại tuyến. Đây là một tính năng tuyệt vời. Sau khi bạn đã tải mô hình xuống máy tính cá nhân, nó sẽ hoạt động mà không cần internet. Bạn có thể tương tác với mô hình của mình trên các chuyến bay, ở những vùng hẻo lánh, và có một phương án dự phòng để truy cập toàn bộ kiến thức của nhân loại ngay trên máy tính của mình.
Kiểm soát. Bạn được quyền lựa chọn các mô hình và có thể tinh chỉnh cấu hình của chúng theo ý muốn. Bạn sẽ không bị bất ngờ bởi sự thay đổi trong Điều khoản dịch vụ và sẽ không bị chặn ngẫu nhiên vì vi phạm điều khoản (hoặc do lỗi từ phía họ). Bạn có thể kiểm soát hoàn toàn toàn bộ hệ thống AI của mình khi chạy mô hình cục bộ.
Điều đó đã trở thành hiện thực cách đây vài tuần khi Anthropic chặn OpenClaw và các khung phần mềm tác nhân bên thứ ba khác sử dụng gói đăng ký Claude Pro/Max. Những người đang sử dụng hệ thống đó đột nhiên phải chuyển sang nhà cung cấp khác hoặc trả phí API, mức phí này có thể dễ dàng lên tới 50 đô la mỗi ngày.
Các mô hình địa phương không gặp phải vấn đề này.
Như tôi đã nói ở trên, các mô hình cục bộ sẽ không thể sánh kịp các mô hình tiên tiến trong các bài toán suy luận đa bước phức tạp nhất. Nhưng đối với việc lập trình đơn giản và thường ngày, tóm tắt, soạn thảo, thu thập dữ liệu web, nghiên cứu và hỏi đáp, chúng xử lý được 70-80% những gì tôi giao cho chúng.
Cấu hình lý tưởng là sự kết hợp cả hai. Điện toán đám mây cho những tác vụ phức tạp, và máy cục bộ cho mọi thứ khác.
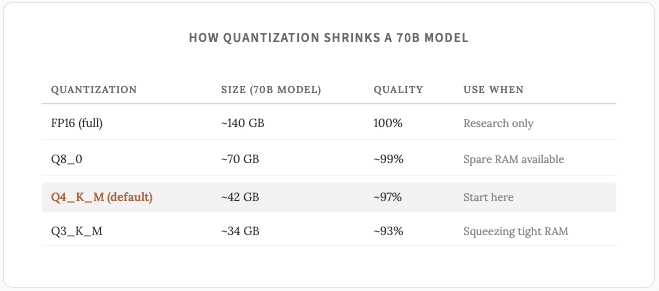
Trước khi đi sâu vào phần cứng, chúng ta hãy cùng tìm hiểu nhanh về lượng tử hóa . Bạn sẽ thấy thuật ngữ này ở khắp mọi nơi trong thế giới LLM và nó ảnh hưởng đến mọi quyết định về phần cứng mà bạn đưa ra, vì vậy rất đáng để hiểu rõ ngay từ đầu.
Các mô hình độ chính xác đầy đủ lưu trữ mỗi tham số dưới dạng số 16 Bit . Lượng tử hóa nén số đó xuống còn 8 Bit, 4 Bit hoặc thấp hơn. Mô hình trở nên nhỏ hơn và nhanh hơn, nhưng đổi lại là độ chính xác giảm đi một Bit . Một ví dụ về âm nhạc mà tôi thấy rất dễ hiểu: FLAC về mặt kỹ thuật tốt hơn tệp MP3 320kbps, nhưng hầu hết mọi người không thể nghe thấy sự khác biệt (chắc chắn tôi cũng không thể).
Lượng tử hóa 4 Bit tạo ra đầu ra gần như không thể phân biệt được với độ chính xác đầy đủ đối với hầu hết các tác vụ. Nếu bạn bắt gặp các mô hình có tên như Q4_K_M hoặc Q3_K_M, hãy hiểu rằng chúng đang đề cập đến cùng một mô hình nhưng với lượng tử hóa 4 Bit hoặc 3 Bit .
Nguyên tắc chung: một mô hình lượng tử hóa Q4 yêu cầu khoảng 0,6-0,7 GB bộ nhớ cho mỗi tỷ tham số (tôi đã giải thích về tham số trong bài đăng tuần trước) .
Tôi khuyên bạn nên tiếp tục sử dụng các mẫu Q4_K_M trừ khi bạn có lý do cụ thể khác.
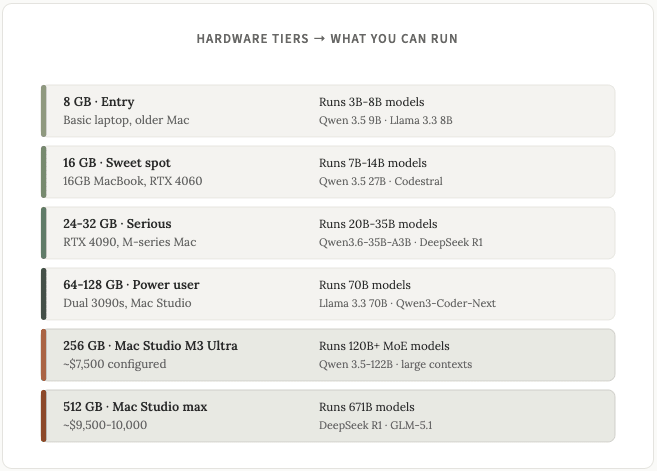
Được rồi, quay lại với phần cứng. Con số quan trọng nhất khi chạy LLM trên phần cứng là bộ nhớ khả dụng. Đó là VRAM trên PC hoặc bộ nhớ hợp nhất trên máy Mac. Mọi thứ khác liên quan đến phần cứng đều là thứ yếu.
Dưới đây là biểu đồ hữu ích để xem các loại mô hình bạn có thể chạy dựa trên các thông số kỹ thuật phần cứng khác nhau:
Máy Mac có một lợi thế độc đáo nhờ bộ nhớ hợp nhất. CPU, GPU và Neural Engine chia sẻ một vùng bộ nhớ duy nhất. Một chiếc Mac Studio với 512 GB bộ nhớ hợp nhất thực sự có thể chạy DeepSeek R1 với 671 tỷ tham số cục bộ.
Tôi đang tự mình chạy GLM5.1 với 744 tỷ tham số trên máy Mac Studio (phiên bản Q3, yêu cầu khoảng 308GB bộ nhớ).
Đây là một câu hỏi thường gặp và câu trả lời, cũng như hầu hết mọi thứ, là "tùy thuộc vào hoàn cảnh". Không có cái nào tốt hơn cái nào một cách tuyệt đối, chúng đều giỏi ở những khía cạnh khác nhau, tùy thuộc vào tình huống/yêu cầu của bạn.
Một số yếu tố khác cần xem xét:
Dựa trên hoàn cảnh của bạn, tôi xin đưa ra lời khuyên sau:
Nếu bạn có ngân sách eo hẹp và đã có sẵn PC: Hãy lắp thêm card đồ họa RTX 3090 đã qua sử dụng. Đây sẽ là lựa chọn tốt nhất về giá trị trên mỗi GB VRAM trong năm 2026.
Nếu bạn muốn một chiếc máy hoàn chỉnh dưới 1.500 đô la và chủ yếu chạy các dòng máy 7B-14B: Mac Mini M4 Pro với 24 GB (1.399 đô la). Hoạt động êm ái, hiệu quả, không cần lắp ráp.
Nếu bạn muốn có phản hồi nhanh nhất có thể trên các mẫu máy tính tầm trung: Hãy tự lắp ráp một chiếc PC với card đồ họa RTX 4090 hoặc 5090. Tổng chi phí khoảng 2.500-3.500 đô la.
Nếu bạn muốn chạy các mẫu máy 30B+ hoặc muốn một chiếc máy luôn hoạt động yên tĩnh: Mac Mini M4 Pro với 48-64 GB (1.999-2.199 USD) hoặc Mac Studio với 64-128 GB (2.400-4.500 USD).
Nếu bạn muốn chạy các mô hình mã nguồn mở mạnh nhất (GLM-5.1, Kimi K2.6, DeepSeek R1 ở chế độ 671B) mà không cần dàn GPU chuyên nghiệp: Mac Studio với 256 GB hoặc 512 GB là lựa chọn duy nhất hợp lý dành cho người tiêu dùng. Giá khoảng 6.000-10.000 đô la.
Còn chiếc laptop bạn đang sở hữu thì sao?
Một điều cần biết trước khi bạn bỏ tiền ra mua là bất kỳ MacBook M1 nào trở lên với ít nhất 8 GB bộ nhớ đều có thể chạy một số mô hình cục bộ nhỏ. Một chiếc MacBook Air M1 với 16 GB có thể chạy 7 mô hình với tốc độ 15-25 token mỗi giây, và nếu bạn có một chiếc MacBook với bộ nhớ lớn hơn nữa, bạn có thể chạy được nhiều mô hình hơn.
Những thiết bị này không quá cao cấp, nhưng vẫn có thể thực sự hữu ích cho các tác vụ đơn giản/cơ bản, và quan trọng hơn, bạn ít nhất có thể hiểu được cách các mô hình địa phương hoạt động trước khi bỏ thêm tiền.
Phần cứng là bước đầu tiên, nhưng một khi đã có phần cứng, bạn sẽ cần một số công cụ để quản lý và chạy các mô hình trên thiết bị của mình. Dưới đây là các lựa chọn chính.
LM Studio là lựa chọn phù hợp nếu bạn mới bắt đầu. Đây là một ứng dụng máy tính để bàn đầy đủ chức năng với giao diện sạch sẽ và dễ sử dụng. Bạn tải xuống trình cài đặt, duyệt qua thư viện mô hình HuggingFace tích hợp sẵn, nhấp vào mô hình bạn muốn và bắt đầu trò chuyện. Không cần sử dụng bất kỳ lệnh terminal nào.
Nó có trình giám sát RAM trực tiếp cho biết liệu máy tính của bạn có thể chạy được mô hình đó trước khi bạn tải xuống và sẽ đề xuất các mô hình tốt nhất để bạn tải xuống dựa trên phần cứng của mình.
Nó cũng cung cấp API tương thích với OpenAI để bạn có thể kết nối với các tập lệnh và tác nhân nếu muốn (ví dụ: bạn có thể chạy các tác nhân Openclaw hoặc Hermes trên các mô hình cục bộ của mình).
Ollama là lựa chọn tốt hơn nếu bạn muốn xây dựng mọi thứ bằng các mô hình cục bộ, nhưng nó yêu cầu bạn phải quen thuộc với giao diện dòng lệnh (CLI). Một vài ưu điểm của Ollama so với LM Studio:
Ollama có khả năng tương thích API tương tự như LM Studio.
Ollama có ứng dụng dành cho máy tính để bàn và nó hoạt động tốt, nhưng so với LM Studio thì nó khá tối giản. Không có trình giám sát RAM trực tiếp, không có điều khiển thông số trực quan, không có so sánh mô hình cạnh nhau, không có trình duyệt HuggingFace. Nó ổn cho các cuộc trò chuyện nhanh, nhưng không phải là điểm mạnh của Ollama. Nếu bạn muốn giao diện người dùng trau chuốt, hãy dùng LM Studio. Nếu bạn muốn chạy ứng dụng không giao diện/lập trình/agent, hãy dùng Ollama. Hoặc, một lựa chọn thậm chí còn tốt hơn…
Bạn có thể cài đặt cả hai! Chúng không xung đột với nhau, và đó là lời khuyên của tôi. Tôi dùng LM Studio để nhanh chóng kiểm tra các mô hình mới, và Ollama cho bất cứ thứ gì tôi muốn tích hợp vào quy trình làm việc. Nếu phải chọn một: LM Studio dành cho người không phải lập trình viên mới bắt đầu, Ollama dành cho bất kỳ ai có kế hoạch kết nối các mô hình cục bộ với OpenClaw, Hermes hoặc các tập lệnh của riêng họ.
Một số công cụ khác bạn cần biết:
Unsloth dùng để tinh chỉnh các mô hình trên dữ liệu của riêng bạn, điều này mở ra một khả năng rất tuyệt vời khác cho các mô hình cục bộ. Phiên bản Unsloth Studio mới được phát hành vào tháng 3 cho phép bạn huấn luyện một mô hình trên tài liệu hoặc phong cách viết của mình. Tôi muốn tinh chỉnh một mô hình trên tất cả các bản tin (hoặc X bài đăng) của mình và xem mô hình hoạt động như thế nào so với các mô hình tiên tiến khác khi viết theo giọng văn của riêng tôi.
HuggingFace là kho lưu trữ các mô hình. Hãy coi nó như GitHub dành cho AI, bạn không nhất thiết phải tương tác trực tiếp với nó, nhưng khi bạn đang sử dụng Local LM hoặc Ollama và "tải xuống một mô hình", hãy nhớ rằng bạn có thể đang tải xuống từ HuggingFace.
llama.cpp và MLX là hai công cụ nền tảng. Cả Ollama và LM Studio đều sử dụng một trong hai để suy luận. Hầu hết mọi người không cần phải để ý đến chúng.
Phần này đã lỗi thời đến hai lần trong khi tôi đang viết bức thư này. Sau đây là quan điểm của tôi tính đến ngày 21 tháng 4 năm 2026. Một nửa trong số này có thể sẽ bị thay thế trong vòng ba tháng, hoặc thậm chí sớm hơn. Kimi K2.6 vừa mới ra mắt vài giờ trước và tôi chưa có cơ hội tự mình dùng thử, nhưng tôi đã từng dùng GLM-5.1 và có lẽ đó là lựa chọn tốt nhất trước khi có Kimi K2.6.
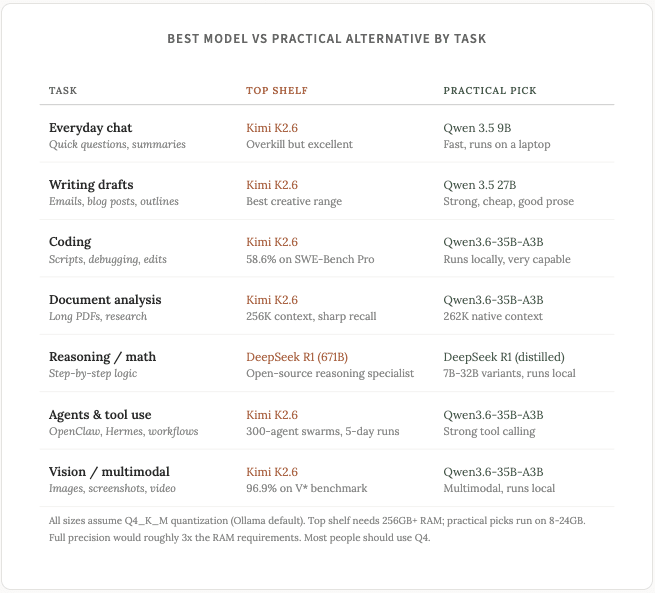
Có một vài điều cần lưu ý trước khi tôi chia sẻ bảng so sánh. Các mô hình trọng lượng mở tiên tiến (Kimi K2.6, GLM-5.1) tốt hơn các mô hình nhỏ hơn ở hầu hết mọi khía cạnh. Đó là bản chất của các mô hình lớn hơn với nhiều tham số hơn. Nhưng chúng cần phần cứng mạnh để chạy cục bộ, vì vậy đối với các tác vụ không cần suy luận sâu, một mô hình nhỏ hơn sẽ hoàn thành công việc với chi phí và độ trễ thấp hơn nhiều. Câu hỏi thực tế bạn nên tự hỏi không phải là "mô hình nào tốt nhất cho tác vụ này" mà là "mô hình nhỏ nhất nào xử lý tác vụ này đủ tốt".
Nói nhanh về các bài kiểm tra hiệu năng. Tôi sẽ nhắc đến SWE-Bench Pro vài lần trong bài viết này. Đây là bài kiểm tra hiệu năng quan trọng nhất đối với việc lập trình. Thay vì kiểm tra xem mô hình có thể viết một hàm độc lập hay không, SWE-Bench Pro đưa cho mô hình một vấn đề thực tế trên GitHub từ một dự án mã nguồn mở và yêu cầu nó sửa lỗi. Mô hình phải đọc mã nguồn, hiểu lỗi, viết mã sửa lỗi và gửi mã vượt qua các bài kiểm tra hiện có. Điểm số 50% có nghĩa là mô hình đã giải quyết được một nửa số lỗi được đưa ra.
Để dễ hình dung, Claude Opus 4.6 đạt điểm số 53,4%. Phiên bản mới ra mắt Opus 4.7 đạt điểm số ấn tượng 64,3%. Bất kỳ điểm số nào trong khoảng 55-60% thường được coi là thuộc hàng tiên tiến, nhưng con số này rõ ràng đang liên tục thay đổi khi các mẫu tiên tiến ngày càng tốt hơn.
Trên kệ cao cấp dành cho lập trình, hiện nay có hai mẫu máy tính bảng có trọng lượng mở nổi bật.
Kimi K2.6 của Moonshot AI là ông vua mới của thế giới lập trình mã nguồn mở. Nó vừa ra mắt hôm nay. Nó được thiết kế đặc biệt cho các tác vụ lập trình dài và phức tạp. Trong khi các mô hình khác bắt đầu mất đi sự mạch lạc sau một hoặc hai giờ, K2.6 đã chứng minh khả năng thực thi liên tục trong 5 ngày trên các tác vụ kỹ thuật thực tế.
Nó cũng có thể điều phối 300 tác nhân phụ song song (thật đáng kinh ngạc), điều đó có nghĩa là bạn có thể đưa cho nó một yêu cầu kiểu như "tái cấu trúc toàn bộ monorepo này" và nó sẽ phân chia công việc thành hàng trăm tác nhân chuyên biệt. Nó vượt trội hơn Claude Opus 4.6 trên SWE-Bench Pro (58,6% so với 53,4%). Nếu bạn đang xây dựng bất kỳ thứ gì liên quan đến tác nhân hoặc thực hiện nhiều công việc chỉnh sửa mã nguồn, thì đây là mô hình cục bộ tốt nhất hiện nay (nhưng một lần nữa... tất cả điều này có thể thay đổi ngay ngày mai đấy lol).
GLM-5.1 từ Z.ai là phiên bản cũ hơn (ngày 7 tháng 4, thật khó tin khi coi nó là "phiên bản cũ hơn"), nhưng chất lượng lập trình vẫn rất gần. Nó đạt 58,4% trên SWE-Bench Pro, chỉ kém hơn K2.6 một chút. Đây cũng là một lựa chọn tuyệt vời nếu bạn muốn lập trình tiên tiến nhưng không có phần cứng đủ mạnh để chạy mô hình Kimi.
Về mặt thực tiễn, Qwen3.6-35B-A3B (phát hành ngày 16 tháng 4) sẽ là lựa chọn tối ưu cho hầu hết người dùng. Kiến trúc MoE có nghĩa là chỉ có 3 tỷ tham số hoạt động trên mỗi Token mặc dù tổng số token trong mô hình là 35 tỷ, điều này có nghĩa là nó chạy nhanh trên máy tính có RAM 24 GB. Nó xử lý cả hình ảnh và video, không chỉ văn bản, và nó có cửa sổ ngữ cảnh hỗ trợ tới 1 triệu token, cho phép bạn cung cấp toàn bộ mã nguồn hoặc các tài liệu dài.
Nó rất tốt trong việc lập trình hàng ngày, viết bản nháp, tóm tắt và quy trình làm việc của các tác nhân.
Điều này khá ngẫu nhiên nhưng có người đã thử nghiệm trên máy tính xách tay của họ so với Claude Opus 4.7 vào ngày cả hai được phát hành, và mô hình cục bộ đã vẽ một con bồ nông cưỡi xe đạp đẹp hơn (một ví dụ rất ngẫu nhiên và ngớ ngẩn nhưng cuộc sống mà thiếu đi chút kỳ quặc thì còn gì thú vị nữa):
Đối với phần cứng nhỏ hơn, Qwen 3.5 9B là lựa chọn thiết thực và hoạt động tốt trên MacBook 8 GB. Nó không thể xử lý các tác vụ phức tạp với nhiều tập tin, nhưng đối với một số tác vụ hàng ngày (viết lại email, tóm tắt bài báo, hỏi đáp nhanh), nó hoạt động khá hiệu quả.
Bắt đầu
Nếu bạn muốn thử chạy các mô hình cục bộ của riêng mình, đây là một số hướng dẫn để bắt đầu cho cả LM Studioo và Ollama.
LM Studio:
Tải xuống LM Studio từ lmstudio.ai .
Cài đặt nó.
Mở ứng dụng.
Nhấp vào “Khám phá” và tìm kiếm kiểu máy. Trình giám sát RAM trực tiếp sẽ cho bạn biết liệu máy đó có tương thích với máy tính của bạn hay không.
Nhấp vào nút tải xuống.
Nhấp vào “Tải mô hình” khi hoàn tất, và bạn đã sẵn sàng sử dụng. Bạn có thể trò chuyện trực tiếp với mô hình trong LM Studio, hoặc kết nối nó với một agent như OpenClaw/Hermes (tôi sẽ giải thích cách làm ở phần tiếp theo).
Ollama:
Cài đặt Ollama từ ollama.com (trình cài đặt một dòng dành cho Mac và Linux).
Sau đó, hãy truy cập ollama.com/library hoặc huggingface.co để xem các mẫu.
Mỗi danh sách mô hình đều cung cấp cho bạn lệnh chính xác để chạy nó. HuggingFace có nhiều lựa chọn hơn và hiển thị kích thước tệp để bạn có thể kiểm tra xem nó có phù hợp với RAM của mình trước khi tải xuống.
Sau khi tìm được mô hình, hãy chạy nó trong cửa sổ dòng lệnh, kết quả sẽ trông như thế này:
Lần đầu tiên bạn chạy lệnh như thế này, nó sẽ tải xuống mô hình, sau đó nó sẽ tải mô hình từ ổ cứng của bạn. Sau khi tải xuống/tải xong, bạn có thể bắt đầu giao tiếp với nó ngay lập tức từ terminal.
Việc thiết lập và sử dụng các mô hình cục bộ khá đơn giản. Toàn bộ quá trình thiết lập từ đầu đến cuối không mất nhiều thời gian, thường thì phần lâu nhất là tải xuống mô hình (vài GB đến hàng chục/hàng trăm GB tùy thuộc vào mô hình).
Đây thực sự là tất cả những gì bạn cần làm để chạy các mô hình LLM cục bộ hoàn toàn trên thiết bị của mình, và tôi khuyên mọi người có phần cứng nên thử cách này với một số mẫu máy nhỏ nhất.
Kết nối các mô hình địa phương với các tác nhân AI
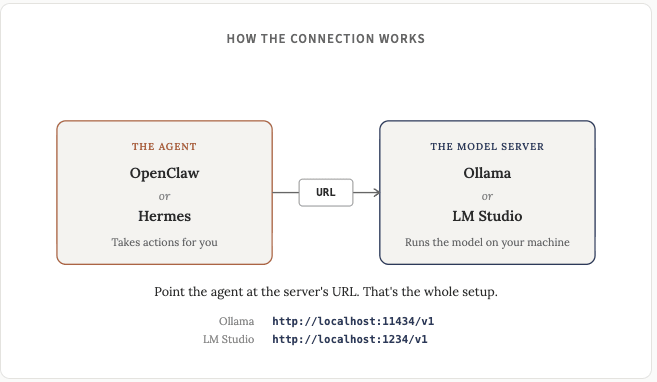
Đây là lúc mọi thứ trở nên thú vị. Việc chạy một chatbot cục bộ rất hữu ích và tuyệt vời, nhưng kết nối mô hình cục bộ với một framework tác nhân (Openclaw hoặc Hermes) mới là chìa khóa thực sự.
OpenClaw: Cài đặt OpenClaw, sau đó trong Cài đặt > Cấu hình (hoặc openclaw.json) thêm nhà cung cấp tùy chỉnh trỏ đến http://localhost:11434/v1 cho Ollama hoặc http://localhost:1234/v1 cho LM Studio. Đặt loại API là “openai-completions” và đặt tên cho mô hình của bạn trùng khớp với tên được tải.
Hướng dẫn cài đặt Hermes: Cài đặt Hermes, sau đó chạy lệnh `hermes model` để mở trình hướng dẫn thiết lập. Chọn “Custom endpoint”, nhập URL cục bộ của bạn (tương tự như trên: Ollama là http://localhost:11434/v1, LM Studio là http://localhost:1234/v1), và chọn mô hình bạn đã tải. Có thể chuyển đổi mô hình sau bằng lệnh `/model` trong khung chat.
Cả Ollama và LM Studio đều cung cấp API tương thích với OpenAI, và cả OpenClaw lẫn Hermes đều sử dụng định dạng đó, nên cuối cùng mọi thứ khá đơn giản. Một khi bạn đã hiểu rõ, bạn sẽ thấy việc thử nghiệm các mô hình mới rất dễ dàng.
Rất nhiều nội dung về các mô hình LLM cục bộ hiện nay thường thổi phồng mọi thứ. Mặc dù tôi không nghĩ mọi người đều cần sử dụng các mô hình cục bộ, và tôi rất hiểu những hạn chế của các mô hình này, nhưng tôi nghĩ rằng bất cứ ai đam mê AI đều sẽ thu được lợi ích rất lớn nếu dành một hoặc hai ngày để mày mò tìm hiểu về nó.
Một mô hình cục bộ sẽ không thể thay thế Claude Opus 4.7 cho các suy luận đa bước phức tạp. Nó sẽ không thể viết nội dung tốt như các mô hình đám mây tiên tiến. Nó cũng sẽ không thể gỡ lỗi một codebase đa tệp phức tạp một cách đáng tin cậy.
Ứng dụng này sẽ cung cấp cho bạn một trợ lý AI riêng tư, miễn phí, luôn sẵn sàng, xử lý hầu hết các tác vụ cơ bản mà bạn giao cho nó, và, dường như, đôi khi còn làm tốt hơn trong việc tạo ra hình ảnh một con bồ nông trên xe đạp?
Và đối với nhiều người, như vậy là quá đủ rồi.
Đường cong chất lượng rõ ràng là có thật, và không phải tất cả các mô hình cục bộ đều được tạo ra như nhau. Việc chuyển từ 8B sang 14B là một bước nhảy vọt đáng chú ý. Từ 14B lên 32B lại là một bước nhảy vọt khác. Nếu bạn có phần cứng đủ mạnh để chạy Kimi K2.6 hoặc GLM-5.1 trên máy Mac Studio 512 GB, bạn đang chạy một mô hình vượt trội hơn Claude Opus 4.6 trên SWE-Bench Pro. Đối với phần cứng thông thường, Qwen3.6-35B-A3B trên cấu hình 24-32 GB là lựa chọn tối ưu vào tháng 4 năm 2026. Bạn sẽ đạt được chất lượng gần như tối ưu trên một máy tính tiêu chuẩn.
Cách tiếp cận tổng thể tốt nhất mà tôi khuyên dùng cho mọi người là sử dụng điện toán đám mây cho những tác vụ phức tạp nhất, và máy cục bộ cho mọi thứ khác (hoặc những thứ cần phải bảo mật). Bạn không cần phải chọn một trong hai.
Hệ sinh thái LLM địa phương vào tháng 4 năm 2026 đã khá hoàn thiện. Vài tháng qua đã chứng kiến những bước tiến vượt bậc về chất lượng, và nếu xu hướng này tiếp tục, sức mạnh trí tuệ nhân tạo mà chúng ta, những người bình thường, có thể sử dụng tại nhà sẽ thực sự đáng kinh ngạc.
Thành thật mà nói, những mô hình này có lẽ đã tốt hơn bạn nghĩ rồi. Và việc sở hữu một trí tuệ nhân tạo chạy trên chính máy tính của bạn, trả lời các câu hỏi của bạn với chi phí vận hành (gần như) bằng không và không rò rỉ dữ liệu, là một trong những điều khiến tôi nhớ đến những lời hay ý đẹp của một trong những nhà văn khoa học viễn tưởng vĩ đại nhất hiện nay:
Tuyên bố miễn trừ trách nhiệm: Nội dung trong bản tin này không được coi là lời khuyên đầu tư. Tôi không phải là cố vấn tài chính. Đây chỉ là ý kiến và quan điểm cá nhân của tôi. Bạn nên luôn tham khảo ý kiến của cố vấn tài chính chuyên nghiệp/có giấy phép trước khi giao dịch hoặc đầu tư vào bất kỳ sản phẩm liên quan đến tiền điện tử nào. Một số liên kết được chia sẻ có thể là liên kết giới thiệu.