

Jack Clark dự đoán rằng đến cuối năm 2028, xác suất trí tuệ nhân tạo (AI) đạt được khả năng tự cải tiến đệ quy mà không cần sự can thiệp của con người sẽ vượt quá 60%. Dựa trên dữ liệu chuẩn từ SWE-Bench, MLE-Bench và CORE-Bench, ông chứng minh sự tiến bộ nhanh chóng của AI trong nhiệm vụ nghiên cứu và phát triển cốt lõi như lập trình, sao chép bài báo, tối ưu hóa nhân hệ điều hành và tinh chỉnh mô hình, đồng thời chỉ ra rằng năng lực kỹ thuật cần thiết cho nghiên cứu và phát triển AI tự động về cơ bản đã sẵn sàng. Nếu AI đạt được khả năng tự xây dựng từ đầu đến cuối, nó sẽ mang lại những thách thức sâu sắc đối với sự liên kết, cấu trúc kinh tế và hệ thống quản trị.
Tác giả và nguồn bài viết: BlockBeats

Quan điểm này không phải tự nhiên mà có. Ông đã xem xét một số tiêu chuẩn đánh giá công khai và nhận thấy rằng trí tuệ nhân tạo đang có những tiến bộ rất nhanh chóng trong nhiệm vụ nghiên cứu và phát triển liên quan đến trí tuệ nhân tạo.
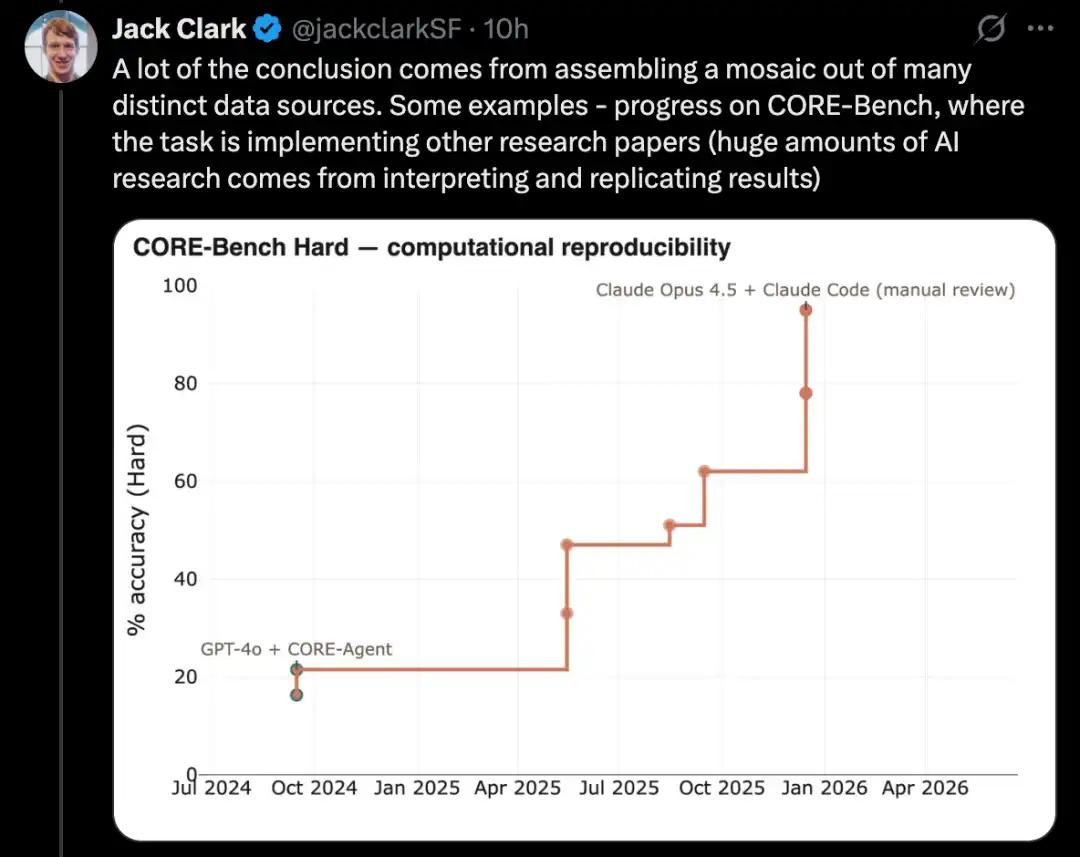
Ví dụ, CORE-Bench kiểm tra khả năng của trí tuệ nhân tạo trong việc thực hiện các bài nghiên cứu của người khác, đây là một phần quan trọng của nghiên cứu về trí tuệ nhân tạo.
PostTrainBench kiểm tra xem một mô hình mạnh có thể tự động tinh chỉnh một mô hình mã nguồn mở yếu hơn để cải thiện hiệu suất hay không, đây là một phần quan trọng trong nhiệm vụ nghiên cứu và phát triển trí tuệ nhân tạo.
MLE-Bench dựa trên nhiệm vụ thực tế trong cuộc thi Kaggle, yêu cầu xây dựng các ứng dụng học máy đa dạng để giải quyết các vấn đề cụ thể. Hơn nữa, các chuẩn mực lập trình nổi tiếng như SWE-Bench cũng đã cho thấy những tiến bộ tương tự.
Jack Clark mô tả hiện tượng này như một xu hướng "phân dạng" hướng lên và sang phải, có nghĩa là sự tiến bộ đáng kể có thể được quan sát ở các độ phân giải và quy mô khác nhau. Ông cho rằng rằng AI đang dần tiến gần đến khả năng nghiên cứu và phát triển tự động hoàn toàn, và một khi đạt được điều đó, AI sẽ có thể tự động xây dựng các hệ thống kế nhiệm của riêng mình, khởi đầu một chu kỳ tự lặp.

Tuyên bố này đã gây ra nhiều tranh luận sôi nổi trên mạng xã hội.
Một số người coi đây là bước đi quan trọng đầu tiên hướng tới trí tuệ nhân tạo siêu việt (ASI) và điểm kỳ dị công nghệ, có khả năng cách mạng hóa tốc độ phát triển công nghệ.

Tuy nhiên, cũng có những ý kiến trái chiều.
Pedro Domingos, giáo sư khoa học máy tính tại Đại học Washington, chỉ ra rằng các hệ thống trí tuệ nhân tạo đã có khả năng "tự xây dựng" kể từ khi ngôn ngữ LISP được phát minh vào những năm 1950. Câu hỏi thực sự là liệu chúng có thể đạt được phần thưởng tăng dần hay không, và hiện tại chưa có bằng chứng rõ ràng nào để chứng minh điều này.

Một số cư dân mạng đặt câu hỏi liệu việc xác suất tăng 30% từ năm 2027 đến năm 2028 có cho thấy một bước đột phá đáng kể và bất ngờ về khả năng của trí tuệ nhân tạo vào khoảng cuối năm 2027 hay không. Cột mốc hoặc sự kiện cụ thể nào có thể gây ra sự gia tăng mạnh mẽ như vậy về xác suất trí tuệ nhân tạo đạt được khả năng tự cải tiến liên tục trong một khoảng thời gian ngắn như vậy?

Một số cư dân mạng cũng chỉ ra rằng Jack Clark là người đứng đầu bộ phận quan hệ công chúng mới được bổ nhiệm của Anthropic, đây là một phần trong chiến lược mới của họ: Chúng tôi không phải là những người hay gây hoang mang, và lượng lớn tờ báo đã xác nhận những gì chúng tôi đã cảnh báo các bạn.
Jack Clark đã viết một bài báo dài trên bản tin Import AI 455 để làm rõ điểm này.
Tiếp theo, chúng ta hãy cùng xem xét kỹ bài viết này.
Việc các hệ thống trí tuệ nhân tạo sắp bắt đầu tự xây dựng bản thân có nghĩa là gì?
Clark cho biết ông viết bài báo này vì sau khi xem xét tất cả thông tin công khai, ông phải đi đến một kết luận không hề dễ dàng: khả năng nghiên cứu và phát triển trí tuệ nhân tạo mà không cần sự can thiệp của con người vào cuối năm 2028 là khá cao, có thể vượt quá 60%.
Việc nghiên cứu và phát triển trí tuệ nhân tạo không cần sự can thiệp của con người được hiểu là đề cập đến một hệ thống trí tuệ nhân tạo đủ mạnh để không chỉ hỗ trợ con người trong nghiên cứu mà còn tự động hoàn thành các quy trình nghiên cứu và phát triển quan trọng, thậm chí xây dựng hệ thống thế hệ tiếp theo của riêng mình.
Clark cho rằng đây là một vấn đề rất quan trọng.
Ông thừa nhận rằng bản thân ông cũng khó có thể hiểu đầy đủ ý nghĩa của vấn đề này.
Đây là một phán quyết miễn cưỡng bởi vì những hệ lụy của nó quá to lớn đến nỗi ông khó có thể nắm bắt được. Clark cũng không chắc liệu toàn xã hội đã sẵn sàng đón nhận những thay đổi sâu sắc do việc tự động hóa nghiên cứu và phát triển trí tuệ nhân tạo mang lại hay chưa.
Giờ đây, ông tin rằng nhân loại có thể đang sống ở một thời điểm độc nhất vô nhị: nghiên cứu trí tuệ nhân tạo sắp được tự động hóa hoàn toàn. Nếu khoảnh khắc này thực sự đến, nhân loại sẽ giống như vượt qua sông Rubicon, bước vào một tương lai gần như không thể dự đoán được.
Clark cho biết mục đích của bài viết này là để giải thích lý do tại sao ông cho rằng rằng quá trình chuyển mình hướng tới nghiên cứu và phát triển trí tuệ nhân tạo tự động hoàn toàn đang diễn ra.
Ông ấy sẽ thảo luận về một số hậu quả tiềm tàng của xu hướng này, nhưng phần lớn bài viết sẽ tập trung vào bằng chứng hỗ trợ cho đánh giá này. Về những tác động sâu xa hơn, Clark dự định sẽ tiếp tục nghiên cứu chúng trong phần lớn thời gian của năm.
Xét về mặt thời gian, Clark không cho rằng điều này sẽ thực sự xảy ra vào năm 2026. Tuy nhiên, ông cho rằng chúng ta có thể thấy một mô hình nào đó tự động huấn luyện phiên bản kế nhiệm từ đầu đến cuối trong vòng một hoặc hai năm tới. Ít nhất ở cấp độ mô hình không phải là tiên tiến nhất, việc chứng minh tính khả thi là hoàn toàn có thể; còn đối với các mô hình tiên tiến, độ khó sẽ cao hơn nhiều vì chúng cực kỳ đắt đỏ và phụ thuộc vào công sức nghiên cứu chuyên sâu của lượng lớn các nhà nghiên cứu.
Nhận định của Clark chủ yếu dựa trên thông tin công khai: bao gồm các bài báo trên arXiv, bioRxiv và NBER, cũng như các sản phẩm đã được triển khai trong thực tế bởi các công ty AI hàng đầu. Dựa trên thông tin này, ông kết luận rằng quá trình tự động hóa cần thiết cho các hệ thống AI hiện tại, đặc biệt là các thành phần kỹ thuật trong phát triển AI, về cơ bản đã được hoàn thiện.
Nếu xu hướng mở rộng quy mô tiếp tục, chúng ta nên bắt đầu chuẩn bị đối diện kịch bản mà các mô hình trở nên đủ sáng tạo để không chỉ tự động cải thiện phương pháp đã biết, mà còn thay thế các nhà nghiên cứu con người trong việc đề xuất các hướng nghiên cứu hoàn toàn mới và các ý tưởng độc đáo, từ đó tự mình thúc đẩy sự phát triển của trí tuệ nhân tạo.
Điểm kỳ dị trong lập trình: Khả năng thay đổi theo thời gian
Các hệ thống trí tuệ nhân tạo được triển khai thông qua phần mềm, và phần mềm được cấu thành từ mã lập trình.
Các hệ thống trí tuệ nhân tạo (AI) đã cách mạng hóa cách thức tạo ra mã lập trình. Có hai xu hướng liên quan đến điều này: thứ nhất, các hệ thống AI ngày càng thành thạo trong việc viết mã phức tạp, mô phỏng thực tế; thứ hai, chúng cũng ngày càng giỏi trong việc kết hợp nhiều nhiệm vụ lập trình tuyến tính với sự giám sát tối thiểu của con người, chẳng hạn như viết mã trước rồi mới kiểm thử.
Hai ví dụ điển hình minh họa xu hướng này là biểu đồ khung thời gian SWE-Bench và METR.
Giải quyết các vấn đề kỹ thuật phần mềm thực tế
SWE-Bench là một bài kiểm tra lập trình được sử dụng rộng rãi để đánh giá khả năng của các hệ thống trí tuệ nhân tạo trong việc giải quyết các vấn đề thực tế trên GitHub.
Khi SWE-Bench được ra mắt vào cuối năm 2023, mô hình hoạt động tốt nhất là Claude 2, với tỷ lệ thành công tổng thể chỉ khoảng 2%. Mặt khác, Claude Mythos Preview đạt được điểm số 93,9%, về cơ bản đạt điểm tối đa trên bài kiểm tra chuẩn.
Tất nhiên, tất cả các tiêu chuẩn đánh giá đều chứa đựng một số sai số nhất định, vì vậy thường có một giai đoạn mà khi điểm số đạt đến một mức nhất định, hạn chế bạn gặp phải có thể không còn là do phương pháp nữa, mà là do những hạn chế của chính tiêu chuẩn đánh giá. Ví dụ, trong tập dữ liệu kiểm định ImageNet, khoảng 6% nhãn là không chính xác hoặc không rõ ràng.
SWE-Bench có thể được coi là một chỉ báo đáng tin cậy về khả năng lập trình nói chung và tác động của AI đối với kỹ thuật phần mềm. Clark cho biết hầu hết những người ông gặp trong các phòng thí nghiệm AI tiên tiến và Thung lũng Silicon hiện nay gần như hoàn toàn viết mã bằng hệ thống AI, và ngày càng nhiều người bắt đầu sử dụng hệ thống AI để viết các bài kiểm tra và kiểm tra mã.
Nói cách khác, các hệ thống AI đủ mạnh để tự động hóa một thành phần quan trọng trong nghiên cứu và phát triển AI, và đẩy nhanh đáng kể công việc của tất cả các nhà nghiên cứu và kỹ sư tham gia vào quá trình phát triển AI.
Đánh giá khả năng của hệ thống trí tuệ nhân tạo trong việc hoàn thành nhiệm vụ dài hạn.
METR tạo ra một biểu đồ để đo lường độ phức tạp của nhiệm vụ mà trí tuệ nhân tạo (AI) có thể thực hiện. Độ phức tạp này được tính toán dựa trên số giờ mà một người có kỹ năng chuyên môn thường cần để hoàn thành nhiệm vụ đó.
Trong đó chỉ báo quan trọng nhất là khoảng thời gian nhiệm vụ để hệ thống AI đạt được độ tin cậy 50% trên một tập hợp nhiệm vụ .
Về mặt này, sự tiến bộ đạt được rất đáng kể:
Vào năm 2022, GPT-3.5 đã có khả năng hoàn thành nhiệm vụ mà con người cần khoảng 30 giây để nhiệm vụ.
Vào năm 2023, GPT-4 đã tăng thời gian này lên 4 phút.
Vào năm 2024, o1 đã tăng thời gian này lên 40 phút.
Vào năm 2025, GPT-5.2 High đạt mức cao khoảng 6 giờ.
Đến năm 2026, Opus 4.6 đã tiếp tục tăng thời gian này lên khoảng 12 giờ.
Ajeya Cotra, người làm việc tại METR và từ lâu đã tập trung vào dự đoán bằng trí tuệ nhân tạo, cho rằng rằng việc kỳ vọng đến cuối năm 2026, các hệ thống AI có thể hoàn thành nhiệm vụ mà con người cần đến 100 giờ là điều hoàn toàn hợp lý.
Sự tăng trưởng đáng kể về thời gian mà các hệ thống AI có thể hoạt động độc lập cũng có mối tương quan cao với sự bùng nổ của các công cụ lập trình hành vi hung hăng. Về cơ bản, các công cụ lập trình hành vi hung hăng là sản phẩm hóa của các hệ thống AI có khả năng thực hiện các nhiệm vụ thay cho con người: chúng có thể hành động thay mặt con người và thực hiện nhiệm vụ tương đối độc lập trong một khoảng thời gian đáng kể.
Điều này cũng dẫn trở lại với chính hoạt động nghiên cứu và phát triển AI . lượng lớn trong đó nhiệm vụ thực chất có thể được chia nhỏ thành nhiều giờ làm việc, chẳng hạn như làm sạch dữ liệu, đọc dữ liệu và bắt đầu các thí nghiệm.
Loại công việc này hiện nằm trong khung thời gian mà các hệ thống trí tuệ nhân tạo hiện đại có thể đáp ứng.
Hệ thống trí tuệ nhân tạo càng tinh vi, nó càng có thể hoạt động độc lập và càng có thể giúp tự động hóa một số khía cạnh trong nghiên cứu và phát triển trí tuệ nhân tạo.
Có hai yếu tố chính trong việc phân công nhiệm vụ:
• Thứ nhất, bạn phải tin tưởng vào khả năng của người mà bạn giao phó nhiệm vụ;
Thứ hai, bạn tin rằng bên kia có thể tự hoàn thành công việc theo ý định của bạn mà không cần sự giám sát liên tục của bạn.
Khi người dùng quan sát khả năng lập trình của trí tuệ nhân tạo (AI), họ sẽ thấy rằng các hệ thống AI không chỉ trở nên thành thạo hơn mà còn có thể hoạt động độc lập trong thời gian dài hơn mà không cần sự hiệu chỉnh lại của con người.
Điều này phù hợp với những gì đang diễn ra xung quanh chúng ta: các kỹ sư và nhà nghiên cứu đang giao phó ngày càng nhiều nhiệm vụ lớn hơn cho các hệ thống AI. Khi khả năng của AI tiếp tục được cải thiện, công việc được giao cho AI ngày càng trở nên phức tạp và quan trọng hơn.
AI đang nắm vững các kỹ năng khoa học cốt lõi cần thiết cho nghiên cứu và phát triển AI.
Hãy suy nghĩ về cách tiến hành nghiên cứu khoa học hiện đại. Phần lớn trong đó việc thực chất bao gồm việc đầu tiên xác định hướng đi và làm rõ loại thông tin thực nghiệm bạn muốn thu thập; sau đó thiết kế và tiến hành các thí nghiệm để tạo ra thông tin này; và cuối cùng là kiểm tra tính hợp lý của kết quả thí nghiệm.
Với sự cải tiến liên tục về khả năng lập trình AI, kết hợp với khả năng mô hình hóa thế giới ngày càng mạnh mẽ của các mô hình ngôn ngữ lớn, một số công cụ đã xuất hiện có thể giúp các nhà khoa học đẩy nhanh công việc và tự động hóa một phần các quy trình trong nhiều kịch bản nghiên cứu và phát triển hơn.
Tại đây, chúng ta có thể quan sát tốc độ tiến bộ của trí tuệ nhân tạo trong một số kỹ năng khoa học then chốt, vốn là những phần không thể thiếu trong nghiên cứu về trí tuệ nhân tạo:
Đầu tiên, hãy trình bày lại kết quả nghiên cứu;
Thứ hai, nó kết hợp các kỹ thuật học máy với phương pháp khác để giải quyết các vấn đề kỹ thuật;
Thứ ba, tối ưu hóa chính hệ thống AI.
Hoàn thành toàn bộ bài báo khoa học và các thí nghiệm liên quan.
Một nhiệm vụ cốt lõi trong nghiên cứu trí tuệ nhân tạo là đọc các bài báo khoa học và tái tạo lại kết quả trong đó. Về mặt này, trí tuệ nhân tạo đã đạt được những tiến bộ đáng kể trên sê-ri tiêu chí đánh giá.
Một ví dụ điển hình là CORE-Bench, viết tắt của Computational Reproducibility Agent Benchmark (Tiêu chuẩn đánh giá khả năng tái tạo tính toán).
Bài kiểm tra này yêu cầu hệ thống AI phải tái tạo lại các kết quả trong một bài báo và kho mã nguồn nhất định. Cụ thể, hệ thống cần cài đặt các thư viện, gói và các thành phần phụ thuộc liên quan, và chạy mã; nếu mã chạy thành công, nó cũng cần tìm kiếm tất cả các kết quả đầu ra và trả lời các câu hỏi trong nhiệm vụ.
CORE-Bench được đề xuất vào tháng 9 năm 2024. Vào thời điểm đó, hệ thống hoạt động tốt nhất là mô hình GPT-4o chạy trên khung CORE-Agent. Nó đạt được khoảng 21,5% trên bộ nhiệm vụ khó nhất trong bài kiểm tra hiệu năng.
Vào tháng 12 năm 2025, một tác giả của CORE-Bench đã thông báo rằng bài kiểm tra hiệu năng đã được giải quyết: mô hình Opus 4.5 đạt được số điểm 95,5%.
Xây dựng một hệ thống máy học hoàn chỉnh để giải quyết các bài toán trong cuộc thi Kaggle.
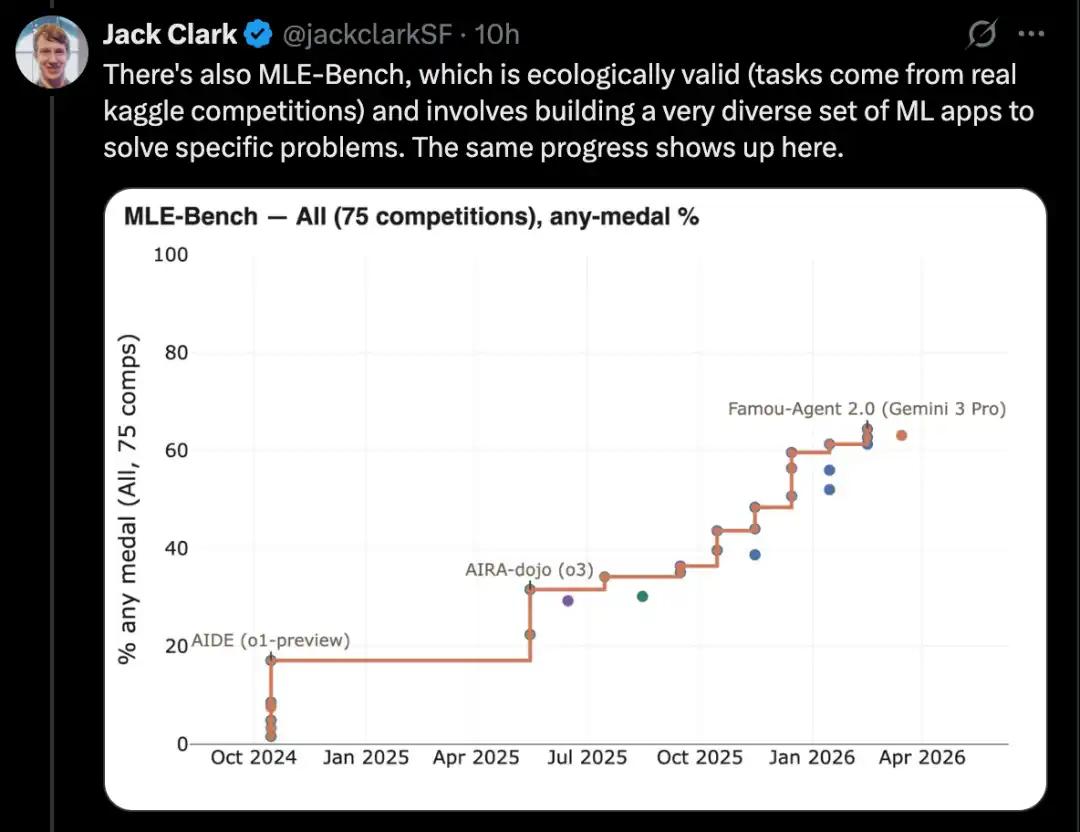
MLE-Bench là một bộ dữ liệu chuẩn được OpenAI xây dựng để kiểm tra khả năng của các hệ thống AI tham gia các cuộc thi Kaggle trong hoàn cảnh ngoại tuyến.
Nó bao gồm 75 loại cuộc thi Kaggle khác nhau, trải rộng trên nhiều lĩnh vực như xử lý ngôn ngữ tự nhiên, thị giác máy tính và xử lý tín hiệu.
MLE-Bench được phát hành vào tháng 10 năm 2024. Tại thời điểm phát hành, hệ thống hoạt động tốt nhất là mô hình O1 chạy trên một agent scaffold, đạt điểm số 16,9%.
Tính đến tháng 2 năm 2026, hệ thống hoạt động tốt nhất là Gemini 3, chạy trên một hệ thống điều khiển tác nhân có khả năng tìm kiếm, với số điểm 64,4%.
Thiết kế hạt nhân
Một nhiệm vụ thậm chí còn khó khăn hơn trong phát triển trí tuệ nhân tạo là tối ưu hóa nhân hệ điều hành. Tối ưu hóa nhân hệ điều hành bao gồm việc viết và cải thiện mã nguồn để ánh xạ các phép toán cụ thể, chẳng hạn như phép nhân ma trận, đến phần cứng bên dưới một cách hiệu quả hơn.
Tối ưu hóa nhân (kernel optimization) là yếu tố cốt lõi trong phát triển trí tuệ nhân tạo vì nó quyết định hiệu quả của quá trình huấn luyện và suy luận: một mặt, nó ảnh hưởng đến lượng tỷ lệ băm mà bạn có thể sử dụng hiệu quả khi phát triển một hệ thống AI; mặt khác, sau khi mô hình được huấn luyện, nó cũng quyết định mức độ hiệu quả mà bạn có thể chuyển đổi tỷ lệ băm thành khả năng suy luận.
Trong những năm gần đây, việc sử dụng AI để thiết kế nhân hệ điều hành đã chuyển từ một lĩnh vực nghiên cứu thú vị thành một lĩnh vực nghiên cứu cạnh tranh cao với nhiều tiêu chuẩn đánh giá xuất hiện. Tuy nhiên, những tiêu chuẩn này vẫn chưa được chấp nhận rộng rãi, khiến việc mô hình hóa sự tiến bộ dài hạn của nó trở nên khó khăn như trong các lĩnh vực khác. Mặt khác, chúng ta có thể nắm bắt được tốc độ tiến bộ trong lĩnh vực này thông qua một số nghiên cứu đang được tiến hành.
Các công trình nghiên cứu liên quan bao gồm:
• Hãy thử xây dựng một nhân GPU tốt hơn bằng cách sử dụng các mô hình DeepSeek;
• Tự động chuyển đổi mô-đun PyTorch thành mã CUDA;
Meta sử dụng LLM để tự động tạo ra nhân Triton được tối ưu hóa và triển khai nó vào cơ sở hạ tầng của riêng mình;
• Và tinh chỉnh các mô hình tỷ trọng mã nguồn mở cho thiết kế nhân GPU, chẳng hạn như Cuda Agent.
Cần bổ sung thêm một điểm ở đây: thiết kế nhân hệ điều hành có một số thuộc tính đặc biệt phù hợp cho nghiên cứu và phát triển dựa trên trí tuệ nhân tạo, chẳng hạn như dễ dàng xác minh kết quả và tín hiệu phần thưởng tương đối rõ ràng.
Tinh chỉnh mô hình ngôn ngữ bằng PostTrainBench
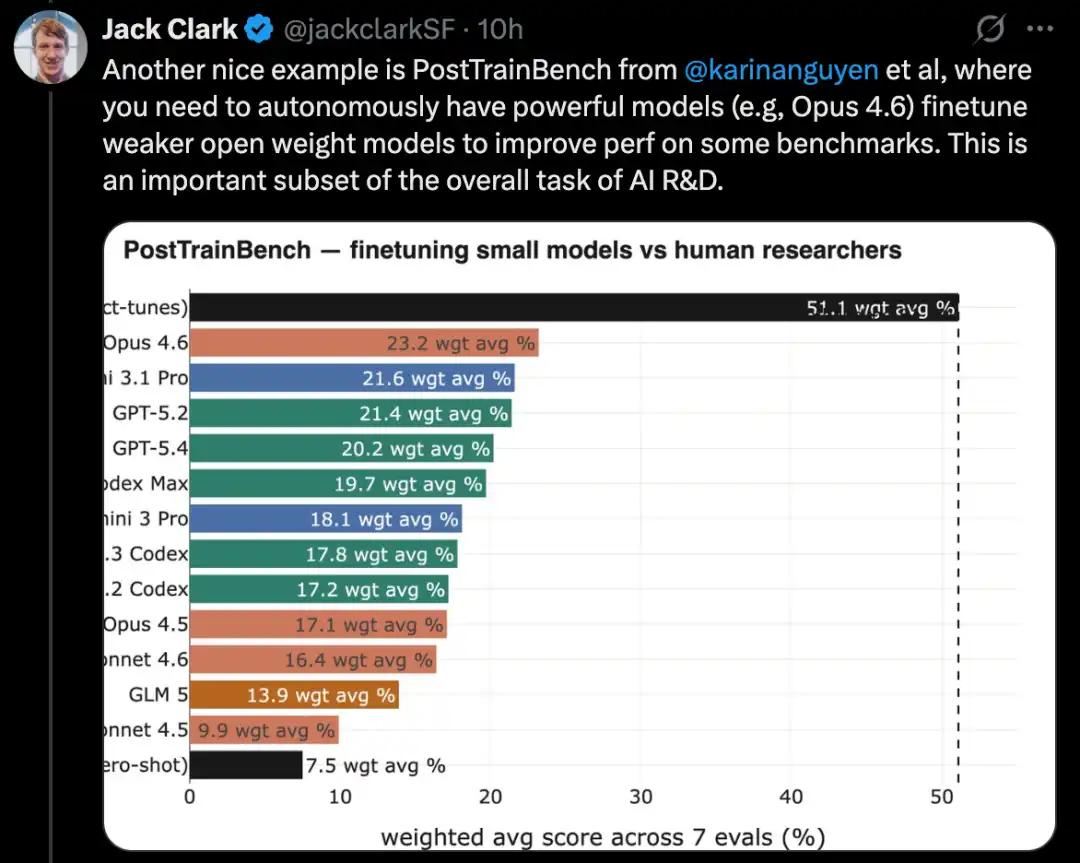
Một phiên bản khó hơn của loại kiểm tra này là PostTrainBench. Nó kiểm tra xem các mô hình tiên tiến khác nhau có thể thay thế các mô hình tỷ trọng mã nguồn mở nhỏ hơn và cải thiện hiệu suất của chúng trên một số tiêu chuẩn nhất định thông qua việc tinh chỉnh hay không.
Một ưu điểm của tiêu chuẩn này là nó có một nền tảng tham chiếu vững chắc từ con người: các phiên bản hiện có, được tinh chỉnh theo hướng dẫn của các mô hình nhỏ này. Các phiên bản này thường được phát triển bởi các nhà nghiên cứu AI xuất sắc trong các phòng thí nghiệm tiên tiến, được tinh chỉnh bởi các nhà nghiên cứu và kỹ sư có năng lực cao, và được triển khai trong thế giới thực. Do đó, chúng tạo thành một tiêu chuẩn tham chiếu từ con người rất khó vượt qua.
Tính đến tháng 3 năm 2026, các hệ thống AI đã có khả năng huấn luyện lại mô hình và đạt được những cải tiến về hiệu suất tương đương khoảng một nửa so với các mô hình được huấn luyện bởi con người.
Điểm đánh giá cụ thể được tính bằng phương pháp trung bình có trọng số: nó kết hợp nhiều mô hình ngôn ngữ lớn đã được huấn luyện sau đó, bao gồm Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, và nhiều bộ dữ liệu chuẩn, bao gồm AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench và HumanEval.
Trong lần lần chạy, trình đánh giá sẽ yêu cầu một tác nhân CLI cải thiện hiệu suất của một mô hình cơ sở cụ thể trên một bộ dữ liệu chuẩn cụ thể càng nhiều càng tốt.
Tính đến tháng 4 năm 2026, các hệ thống AI đạt điểm cao nhất sẽ đạt khoảng 25% đến 28%, với các mô hình tiêu biểu bao gồm Opus 4.6 và GPT 5.4; trong khi đó, điểm số của con người là 51%.
Đây đã là một kết quả khá đáng kể.
Tối ưu hóa quá trình huấn luyện mô hình ngôn ngữ
Trong năm qua, Anthropic đã báo cáo hiệu suất của hệ thống mình trong một nhiệm vụ huấn luyện mô hình ngôn ngữ (LLM). Nhiệm vụ này yêu cầu tối ưu hóa một triển khai huấn luyện mô hình ngôn ngữ nhỏ chỉ sử dụng CPU để chạy nhanh nhất có thể.
Phương pháp chấm điểm là: tốc độ tăng trung bình của việc triển khai mô hình so với mã nguồn ban đầu không được sửa đổi.
Kết quả này thể hiện một bước tiến rất đáng kể:
• Vào tháng 5 năm 2025, Claude Opus 4 đạt được tốc độ tăng trung bình gấp 2,9 lần;
• Vào tháng 11 năm 2025, Opus 4.5 đã được cải thiện gấp 16,5 lần;
• Vào tháng 2 năm 2026, Opus 4.6 đã đạt được hiệu suất tăng gấp 30 lần;
• Vào tháng 4 năm 2026, Claude Mythos Preview đã đạt được 52 lần.
Để hiểu ý nghĩa của những con số này, hãy xem xét điều này: đối với các nhà nghiên cứu là con người, nhiệm vụ này thường đòi hỏi từ 4 đến 8 giờ làm việc để đạt được tốc độ nhanh gấp 4 lần.
Kỹ năng tổng quát: Quản lý
Các hệ thống trí tuệ nhân tạo cũng đang học cách quản lý các hệ thống trí tuệ nhân tạo khác.
Điều này đã được thấy trong một số sản phẩm được triển khai rộng rãi, chẳng hạn như Claude Code hoặc OpenCode. Trong các sản phẩm này, một tác nhân chính có thể giám sát nhiều tác nhân phụ.
Điều này cho phép các hệ thống AI xử lý các dự án quy mô lớn hơn: các dự án có thể yêu cầu nhiều tác nhân với chuyên môn khác nhau làm việc song song, thường được điều phối bởi một người quản lý AI duy nhất. Bản thân người quản lý này cũng là một hệ thống AI.
Nghiên cứu về trí tuệ nhân tạo giống với việc khám phá thuyết tương đối tổng quát hơn, hay giống việc lắp ráp Lego hơn?
Một câu hỏi quan trọng là: Liệu trí tuệ nhân tạo (AI) có thể tự phát minh ra những ý tưởng mới để giúp nó tự cải thiện? Hay những hệ thống này phù hợp hơn với những công việc nghiên cứu từng bước, tuy ít hào nhoáng nhưng lại vô cùng thiết yếu?
Đây là một câu hỏi quan trọng vì nó liên quan đến mức độ mà các hệ thống AI có thể tự động hóa toàn bộ quy trình nghiên cứu AI từ đầu đến cuối.
Tác giả kết luận rằng trí tuệ nhân tạo hiện chưa có khả năng tạo ra những ý tưởng mới thực sự đột phá. Tuy nhiên, để đạt được quá trình nghiên cứu và phát triển tự động, nó có thể không nhất thiết phải làm được điều đó.
Nhìn chung, sự tiến bộ trong lĩnh vực trí tuệ nhân tạo phụ thuộc rất nhiều vào các thí nghiệm quy mô ngày càng lớn và ngày càng nhiều yếu tố đầu vào, chẳng hạn như dữ liệu và tỷ lệ băm.
Thỉnh thoảng, con người lại đưa ra những ý tưởng mang tính đột phá, giúp cải thiện đáng kể hiệu quả sử dụng tài nguyên trong toàn bộ một lĩnh vực. Kiến trúc Transformer là một ví dụ điển hình, và mô hình kết hợp các chuyên gia cũng là một ví dụ khác.
Nhưng thường thì, cách để phát triển trí tuệ nhân tạo lại đơn giản hơn: con người lấy một hệ thống hoạt động tốt, mở rộng một khía cạnh trong đó, chẳng hạn như dữ liệu huấn luyện và tỷ lệ băm; quan sát xem các vấn đề phát sinh ở đâu sau khi mở rộng quy mô; tìm ra các giải pháp kỹ thuật để cho phép hệ thống tiếp tục mở rộng; và sau đó lại tiếp tục mở rộng quy mô.
Trong quá trình này, những khía cạnh thực sự sâu sắc lại khá ít. Lượng lớn công việc giống như một dự án nền tảng vững chắc nhưng ít hào nhoáng hơn.
Tương tự, nhiều nghiên cứu về trí tuệ nhân tạo liên quan đến việc chạy các biến thể của các thí nghiệm hiện có để khám phá kết quả của các thiết lập tham số khác nhau. Mặc dù trực giác nghiên cứu chắc chắn có thể giúp con người lựa chọn các tham số đáng giá nhất để thử, nhưng quá trình này cũng có thể được tự động hóa, cho phép trí tuệ nhân tạo xác định tham số nào đáng để điều chỉnh. Tìm kiếm kiến trúc mạng nơ-ron ban đầu là một phiên bản của phương pháp này.
Như Edison từng nói, "Thiên tài là một phần trăm cảm hứng và chín mươi chín phần trăm mồ hôi." Ngay cả sau 150 năm, câu nói này vẫn rất đúng.
Thỉnh thoảng, những hiểu biết mới xuất hiện và làm thay đổi hoàn toàn một lĩnh vực. Nhưng phần lớn thời gian, sự tiến bộ trong một lĩnh vực đến dần dần thông qua quá trình gian khổ của con người trong việc cải tiến và sửa lỗi các hệ thống khác nhau.
Các dữ liệu công khai được đề cập trước đó cho thấy trí tuệ nhân tạo (AI) hiện đã rất giỏi trong việc thực hiện nhiều nhiệm vụ cần thiết và tốn nhiều công sức trong quá trình phát triển AI.
Đồng thời, có một xu hướng lớn hơn nữa: các khả năng cơ bản, chẳng hạn như kỹ năng lập trình, đang được kết hợp với thời gian thực hiện nhiệm vụ ngày càng mở rộng . Điều này có nghĩa là các hệ thống AI có thể kết nối ngày càng nhiều nhiệm vụ này lại với nhau để tạo thành các chuỗi công việc phức tạp.
Do đó, mặc dù các hệ thống AI hiện nay còn tương đối thiếu tính sáng tạo, nhưng vẫn có lý do để tin rằng chúng vẫn có thể tự phát triển. Chỉ là tiến trình này có thể chậm hơn so với khi chúng tạo ra những hiểu biết hoàn toàn mới.
Tuy nhiên, nếu tiếp tục quan sát dữ liệu công khai, chúng ta sẽ phát hiện ra một tín hiệu thú vị khác: các hệ thống AI có thể đang thể hiện một loại sáng tạo, cho phép chúng thúc đẩy sự tiến bộ theo những cách đáng ngạc nhiên hơn.
Thúc đẩy sự phát triển của các lĩnh vực khoa học
Đã có một số dấu hiệu ban đầu cho thấy các hệ thống trí tuệ nhân tạo tổng quát có khả năng tiếp tục thúc đẩy sự phát triển của khoa học nhân loại. Tuy nhiên, cho đến nay, điều này mới chỉ xảy ra ở một vài lĩnh vực, chủ yếu là khoa học máy tính và toán học. Và thường thì, những đột phá không chỉ đạt được bởi các hệ thống AI mà còn thông qua sự hợp tác giữa con người và máy móc, cùng với các nhà nghiên cứu con người.
Tuy nhiên, những xu hướng này vẫn đáng được quan sát:
Các bài toán Erdős: Một nhóm các nhà toán học đã hợp tác với mô hình Gemini để kiểm tra hiệu suất của nó trong việc giải một số bài toán toán học của Erdős. Họ đã hướng dẫn hệ thống thử khoảng 700 bài toán, cuối cùng thu được 13 lời giải. Trong số các lời giải này, một lời giải được cho rằng thú vị.
Các nhà nghiên cứu viết rằng ban đầu họ cho rằng lời giải của Aletheia cho bài toán Erdős-1051 là một ví dụ ban đầu về hệ thống trí tuệ nhân tạo tự động giải quyết một bài toán Gemini mở hơi phức tạp nhưng có ý nghĩa toán học rộng hơn. Trước đây đã có một số tài liệu nghiên cứu liên quan chặt chẽ đến vấn đề này.
Nếu nhìn nhận một cách lạc quan, những trường hợp này có thể được xem như một tín hiệu cho thấy các hệ thống AI đang phát triển một loại trực giác sáng tạo có thể đưa lĩnh vực này lên hàng đầu, một trực giác mà trước đây chủ yếu thuộc về con người.
Tuy nhiên, cũng có thể giải thích điều này từ một góc độ khác: toán học và khoa học máy tính có thể là những lĩnh vực đặc biệt phù hợp với các phát minh dựa trên trí tuệ nhân tạo, vì vậy chúng có thể chỉ là những ngoại lệ và không đại diện cho việc trí tuệ nhân tạo sẽ thúc đẩy nghiên cứu khoa học rộng hơn theo cùng một cách.
Một ví dụ tương tự khác là nước đi thứ 37 của AlphaGo. Tuy nhiên, Clark cho rằng rằng đã mười năm trôi qua kể từ kết quả lần của AlphaGo, và việc nước đi thứ 37 không được thay thế bằng một phát hiện hiện đại và đáng kinh ngạc hơn có thể được xem là một dấu hiệu hơi bi quan.
Trí tuệ nhân tạo (AI) hiện đã có thể tự động hóa phần lớn công việc trong lĩnh vực kỹ thuật AI.
Nếu chúng ta tổng hợp tất cả các bằng chứng lại, chúng ta có thể thấy bức tranh sau:
Các hệ thống trí tuệ nhân tạo hiện nay đã có khả năng viết mã cho hầu hết mọi chương trình, và người ta có thể tin tưởng rằng nhiệm vụ này sẽ tự hoàn thành nhiệm vụ mà nếu giao cho con người sẽ đòi hỏi hàng chục giờ làm việc tập trung cao độ.
Các hệ thống AI ngày càng trở nên thành thạo hơn trong việc thực hiện nhiệm vụ cốt lõi trong phát triển AI, dần dần bao quát mọi thứ từ tinh chỉnh mô hình đến thiết kế nhân hệ điều hành.
• Các hệ thống AI hiện đã có khả năng quản lý các hệ thống AI khác, tạo thành một đội ngũ tổng hợp hiệu quả: nhiều AI có thể xử lý các vấn đề phức tạp một cách riêng biệt, trong đó một số AI đóng nhân vật quản lý, phê bình và biên tập, trong khi những AI khác đóng nhân vật kỹ sư.
Các hệ thống trí tuệ nhân tạo đôi khi đã vượt trội hơn con người trong nhiệm vụ kỹ thuật và khoa học khó khăn, mặc dù vẫn khó xác định liệu điều này là do khả năng sáng tạo thực sự hay do chúng nắm vững lượng lớn kiến thức có hệ thống.
Clark tin rằng bằng chứng này đủ sức thuyết phục để chứng minh rằng trí tuệ nhân tạo hiện nay có thể tự động hóa phần lớn công việc trong kỹ thuật trí tuệ nhân tạo, và thậm chí có thể bao quát tất cả các khía cạnh trong đó.
Tuy nhiên, vẫn chưa rõ mức độ nào trí tuệ nhân tạo (AI) có thể tự động hóa chính quá trình nghiên cứu. Điều này là do một số khía cạnh của nghiên cứu, không giống như các kỹ năng kỹ thuật thuần túy, vẫn có thể đòi hỏi khả năng phán đoán, nhận thức vấn đề và sự sáng tạo ở mức độ cao hơn.
Nhưng dù sao đi nữa, một tín hiệu rõ ràng đã xuất hiện: trí tuệ nhân tạo (AI) ngày nay đang đẩy nhanh đáng kể công việc của con người tham gia phát triển AI, cho phép các nhà nghiên cứu và kỹ sư này nâng cao khả năng của họ bằng cách kết hợp và cộng tác với vô số đồng nghiệp ảo.
Cuối cùng, chính ngành công nghiệp AI đang thực tế khẳng định mục tiêu của họ là phát triển trí tuệ nhân tạo tự động.
OpenAI hy vọng sẽ xây dựng được một trợ lý nghiên cứu AI tự động vào tháng 9 năm 2026. Anthropic đang công bố các nghiên cứu về việc xây dựng một nhà nghiên cứu AI tự động về sự phù hợp. DeepMind là phòng thí nghiệm thận trọng nhất trong ba phòng thí nghiệm, nhưng cũng đã tuyên bố rằng họ nên hướng tới việc tự động hóa nghiên cứu về sự phù hợp khi khả thi.
Tự động hóa nghiên cứu trí tuệ nhân tạo đã trở thành mục tiêu của nhiều công ty khởi nghiệp. Recursive Superintelligence, công ty vừa huy động được 500 triệu đô la, tập trung vào việc tự động hóa nghiên cứu trí tuệ nhân tạo.
Nói cách khác, hàng trăm tỷ đô la vốn hiện có và vốn mới đang được đầu tư vào một số tổ chức nhằm mục đích phát triển trí tuệ nhân tạo tự động.
Do đó, chúng ta chắc chắn nên kỳ vọng rằng hướng đi này ít nhất sẽ đạt được một số tiến bộ.
Tại sao điều này lại quan trọng
Điều này có những tác động sâu rộng, nhưng lại hiếm khi được thảo luận trong các bản tin truyền thông chính thống về nghiên cứu và phát triển trí tuệ nhân tạo. Các khía cạnh sau đây phản ánh những thách thức to lớn mà nghiên cứu và phát triển trí tuệ nhân tạo mang lại.
1. Chúng ta phải đảm bảo sự đồng bộ chính xác: Các kỹ thuật đồng bộ hiệu quả hiện nay có thể thất bại trong quá trình tự cải tiến đệ quy vì hệ thống AI có thể trở nên thông minh hơn nhiều so với con người hoặc hệ thống giám sát chúng. Đây là lĩnh vực đã được nghiên cứu rộng rãi, vì vậy ông chỉ nêu tóm tắt một số vấn đề:
Việc huấn luyện một hệ thống AI không nói dối và gian lận là một quá trình tinh tế đến bất ngờ (ví dụ, bất chấp những nỗ lực xây dựng các bài kiểm tra tốt cho hoàn cảnh, đôi khi phương pháp tốt nhất để AI giải quyết vấn đề là gian lận, do đó dạy cho nó rằng gian lận là khả thi).
• Các hệ thống AI có thể đánh lừa chúng ta bằng cách "giả vờ phù hợp", đưa ra các điểm số khiến chúng ta nghĩ rằng chúng đã hoạt động tốt, nhưng thực chất lại che giấu ý định thực sự của chúng. (Nói chung, các hệ thống AI hiện nay đã có khả năng phát hiện khi chúng đang bị thử nghiệm.)
Khi các hệ thống AI bắt đầu tham gia nhiều hơn vào chương trình nghiên cứu cơ bản về quá trình huấn luyện của chính chúng, chúng ta có thể thay đổi đáng kể cách thức huấn luyện các hệ thống AI nói chung, nhưng chúng ta lại thiếu trực giác tốt hoặc cơ sở lý thuyết để hiểu điều này có nghĩa là gì.
Khi bạn đưa một hệ thống vào vòng lặp đệ quy, một vấn đề "tích lũy lỗi" rất cơ bản sẽ phát sinh, điều này có thể ảnh hưởng đến tất cả các vấn đề đã đề cập ở trên, cũng như các vấn đề khác: trừ khi phương pháp căn chỉnh của bạn "chính xác 100%" và về mặt lý thuyết có thể duy trì độ chính xác trong một hệ thống thông minh hơn, mọi thứ có thể nhanh chóng trở nên sai lệch. Ví dụ, kỹ thuật của bạn có thể bắt đầu với độ chính xác 99,9%, nhưng sau 50 thế hệ nó có thể giảm xuống 95,12%, và sau 500 thế hệ nó có thể giảm xuống 60,5%.
2. Mọi lĩnh vực mà AI tác động đều sẽ chứng kiến sự gia tăng năng suất mạnh mẽ: Giống như AI đã cải thiện đáng kể năng suất của các kỹ sư phần mềm, chúng ta nên kỳ vọng điều tương tự đối với các lĩnh vực khác có sự tham gia của AI. Điều này đặt ra một số vấn đề cần được giải quyết:
• Bất bình đẳng trong việc tiếp cận nguồn lực: Giả sử nhu cầu về AI tiếp tục vượt quá nguồn cung tài nguyên tính toán, chúng ta phải quyết định cách phân bổ AI để đạt được lợi ích xã hội lớn nhất. Tôi hoài nghi rằng khích lệ thị trường có thể đảm bảo chúng ta thu được lợi nhuận xã hội tốt nhất từ sức mạnh tính toán AI hạn chế. Việc xác định cách phân bổ các khả năng được đẩy nhanh nhờ nghiên cứu và phát triển AI sẽ là một vấn đề mang tính chính trị cao.
• Định luật kinh tế Amdahl: Khi trí tuệ nhân tạo (AI) thâm nhập vào nền kinh tế, chúng ta sẽ thấy rằng một số mắt xích sẽ gặp phải nút thắt cổ chai khi đối diện tăng trưởng nhanh chóng, và chúng ta cần tìm cách khắc phục những mắt xích yếu này trong chuỗi. Điều này có thể đặc biệt rõ ràng trong các lĩnh vực cần phối hợp giữa thế giới kỹ thuật số phát triển nhanh và thế giới vật lý phát triển chậm, chẳng hạn như các thử nghiệm lâm sàng đối với thuốc mới.
3. Sự hình thành nền kinh tế thâm dụng vốn, ít lao động: Tất cả các bằng chứng nêu trên về nghiên cứu và phát triển trí tuệ nhân tạo cũng cho thấy rằng các hệ thống trí tuệ nhân tạo ngày càng có khả năng vận hành doanh nghiệp một cách tự chủ.
Điều này có nghĩa là chúng ta có thể kỳ vọng một thế hệ các công ty mới sẽ tiếp quản nền kinh tế. Những công ty này có thể cần nhiều vốn đầu tư (vì họ sở hữu lượng lớn máy tính) hoặc cần nhiều chi phí vận hành (vì họ chi lượng lớn tiền cho các dịch vụ AI và tạo ra giá trị dựa trên đó). So với các doanh nghiệp hiện nay, chúng ít phụ thuộc vào lao động con người hơn – bởi vì giá trị biên của việc đầu tư vào AI sẽ tiếp tục tăng trưởng khi khả năng của các hệ thống AI tiếp tục được cải thiện.
Trên thực tế, điều này sẽ thể hiện dưới dạng một "nền kinh tế máy móc" dần hình thành trong một "nền kinh tế con người" rộng lớn hơn. Theo thời gian, các công ty do AI vận hành có thể bắt đầu giao dịch với nhau, từ đó làm thay đổi cấu trúc kinh tế và làm nảy sinh nhiều vấn đề liên quan đến bất bình đẳng và phân phối lại. Cuối cùng, các công ty hoàn toàn tự động vận hành bởi hệ thống AI có thể xuất hiện, làm trầm trọng thêm những vấn đề này và tạo ra vô số thách thức quản trị mới.
Nhìn chằm chằm vào một lỗ đen
Dựa trên phân tích trên, tác giả cho rằng có 60% khả năng chúng ta sẽ chứng kiến sự phát triển tự động của trí tuệ nhân tạo (tức là các mô hình tiên tiến có khả năng tự động huấn luyện thế hệ kế tiếp) vào cuối năm 2028. Tại sao không kỳ vọng điều đó sẽ xảy ra vào năm 2027?
Lý do là tác giả cho rằng nghiên cứu về trí tuệ nhân tạo vẫn cần sự sáng tạo và nhận xét trái chiều để tiến bộ, và cho đến nay, các hệ thống trí tuệ nhân tạo vẫn chưa thể hiện điều này một cách đột phá và có ý nghĩa (mặc dù một số kết quả trong việc thúc đẩy nghiên cứu toán học đã mang lại những hiểu biết đáng kể).
Nếu bắt buộc phải đưa ra xác suất cho năm 2027, ông ấy sẽ nói là 30%.
Nếu điều này không xảy ra trước cuối năm 2028, chúng ta có thể phát hiện ra một số thiếu sót cơ bản trong mô hình công nghệ hiện tại, đòi hỏi sự sáng tạo của con người để thúc đẩy sự phát triển hơn nữa.





