

Bài viết này được mang đến cho bạn bởi Illia Polosukhin, đồng sáng lập NEAR Protocol "Tại sao AI cần phải mở - Tại sao AI cần Web3"
Người dịch: IOSG Ventures
Bìa: NEAR Protocol

Bài viết này được dịch bởi IOSG Ventures và chỉ dành cho mục đích trao đổi, học hỏi trong ngành và không mang tính tham khảo đầu tư. Nếu cần trích dẫn, vui lòng ghi rõ nguồn. Để in lại, vui lòng liên hệ với đội ngũ IOSG để được cấp phép và hướng dẫn in lại. Tất cả các dự án được đề cập trong bài viết này không phải là khuyến nghị hoặc lời khuyên đầu tư.
Vào ngày 17 tháng 4, Cuộc hội ngộ những người bạn cũ lần thứ 12 IOSG Ventures đã được tổ chức theo lịch trình. Chủ đề của sự kiện lần là "Singularity: AI x Crypto Convergence". Mục đích của cuộc họp mặt lần là để những người tham gia thảo luận về nơi các lĩnh vực trí tuệ nhân tạo và crypto đang hội tụ và tác động của sự hội tụ này đối với tương lai. Tại những sự kiện như thế này, người tham dự có cơ hội chia sẻ nhận xét, kinh nghiệm và ý tưởng của mình, từ đó thúc đẩy sự hợp tác và đổi mới trong ngành.
Tiếp theo là một trong những bài phát biểu chính của sự kiện lần . Illia Polosukhin, đồng sáng lập Portfolio NEAR Protocol từ IOSG Ventures, mang đến cho các bạn "Tại sao AI cần phải mở - Tại sao AI cần Web3"

Tại sao AI cần phải mở
Hãy cùng khám phá “Tại sao AI cần phải mở”. Bối cảnh của tôi là về Học máy và tôi đã làm nhiều công việc học máy khác nhau trong khoảng mười năm sự nghiệp của mình. Nhưng trước khi tham gia vào lĩnh vực tiền điện tử, hiểu ngôn ngữ tự nhiên và thành lập NEAR, tôi đã làm việc tại Google. Bây giờ chúng tôi phát triển khuôn khổ thúc đẩy phần lớn trí tuệ nhân tạo hiện đại, được gọi là Transformer. Sau khi rời Google, tôi thành lập công ty Machine Learning để chúng tôi có thể dạy máy móc lập trình, từ đó thay đổi cách chúng ta tương tác với máy tính. Nhưng chúng tôi đã không làm điều đó vào năm 2017 hoặc 2018. Còn quá sớm và không có sức mạnh tính toán cũng như dữ liệu để làm điều đó.

Những gì chúng tôi đang làm là thu hút mọi người từ khắp nơi trên thế giới thực hiện công việc gắn nhãn dữ liệu cho chúng tôi, chủ yếu là sinh viên. Họ ở Trung Quốc, Châu Á và Đông Âu. Nhiều người trong đó họ không có tài khoản ngân hàng ở những quốc gia này. Hoa Kỳ không sẵn lòng gửi tiền một cách dễ dàng, vì vậy chúng tôi bắt đầu muốn sử dụng blockchain như một giải pháp cho vấn đề của mình. Chúng tôi muốn giúp mọi người trên khắp thế giới thanh toán theo cách có lập trình dễ dàng hơn, bất kể họ ở đâu. Nhân tiện, thách thức hiện tại với Tiền điện tử là mặc dù hiện tại NEAR đã giải quyết được rất nhiều vấn đề, nhưng thông thường bạn cần mua một số Tiền điện tử trước khi có thể giao dịch trên blockchain để kiếm được nó, điều này ngược lại với quy trình.
Giống như các doanh nghiệp, họ sẽ nói, này, trước hết, bạn cần mua một số cổ phần trong công ty để sử dụng nó. Đây là một trong nhiều vấn đề mà chúng tôi tại NEAR đang giải quyết. Bây giờ hãy thảo luận về khía cạnh AI sâu hơn một chút. Các mô hình ngôn ngữ không có gì mới, chúng đã xuất hiện từ những năm 1950. Nó là một công cụ thống kê được sử dụng rộng rãi trong các công cụ ngôn ngữ tự nhiên. Trong một thời gian dài, bắt đầu từ năm 2013, một cải tiến mới đã bắt đầu khi học độ sâu được hồi sinh. Điểm đổi mới là bạn có thể ghép các từ, thêm chúng vào các vectơ đa chiều và chuyển đổi chúng thành dạng toán học. Điều này hoạt động tốt với các mô hình học độ sâu, vốn chỉ có lượng lớn phép nhân ma trận và hàm kích hoạt.

Điều này cho phép chúng tôi bắt đầu thực hiện các mô hình học độ sâu nâng cao và đào tạo để thực hiện nhiều điều thú vị. Bây giờ nhìn lại, những gì chúng tôi đang làm là mạng lưới thần kinh nơ-ron, được mô phỏng rất giống con người và chúng tôi có thể đọc từng từ một. Vì vậy, làm điều này là rất chậm, phải không. Nếu bạn đang cố gắng hiển thị nội dung nào đó cho người dùng trên Google.com, không ai sẽ đợi để đọc Wikipedia trong khoảng 5 phút trước khi đưa ra câu trả lời nhưng bạn muốn có câu trả lời ngay lập tức. Vì vậy, mô hình Transformers, mô hình thúc đẩy ChatGPT, Midjourney và tất cả những tiến bộ gần đây, đều xuất phát từ cùng một ý tưởng là có một hệ thống có thể xử lý dữ liệu song song, có thể suy luận và có thể đưa ra câu trả lời ngay lập tức.
Vì vậy, một trong những đổi mới chính trong ý tưởng này ở đây là mọi từ, mọi mã thông báo, mọi bản vá hình ảnh đều được xử lý song song, tận dụng GPU của chúng tôi và accelerator khác, vốn có khả năng tính toán song song cao. Bằng cách này, chúng ta có thể suy luận về nó theo cách có thể mở rộng. Việc mở rộng quy mô này cho phép mở rộng quy mô đào tạo để xử lý dữ liệu đào tạo tự động. Vì vậy, sau đó, chúng ta có Dopamine, chất này thực hiện công việc tuyệt vời trong một khoảng thời gian ngắn, cho phép tập luyện bùng nổ. Nó có lượng lớn và bắt đầu đạt được những kết quả đáng kinh ngạc trong việc suy luận và hiểu các ngôn ngữ trên thế giới.
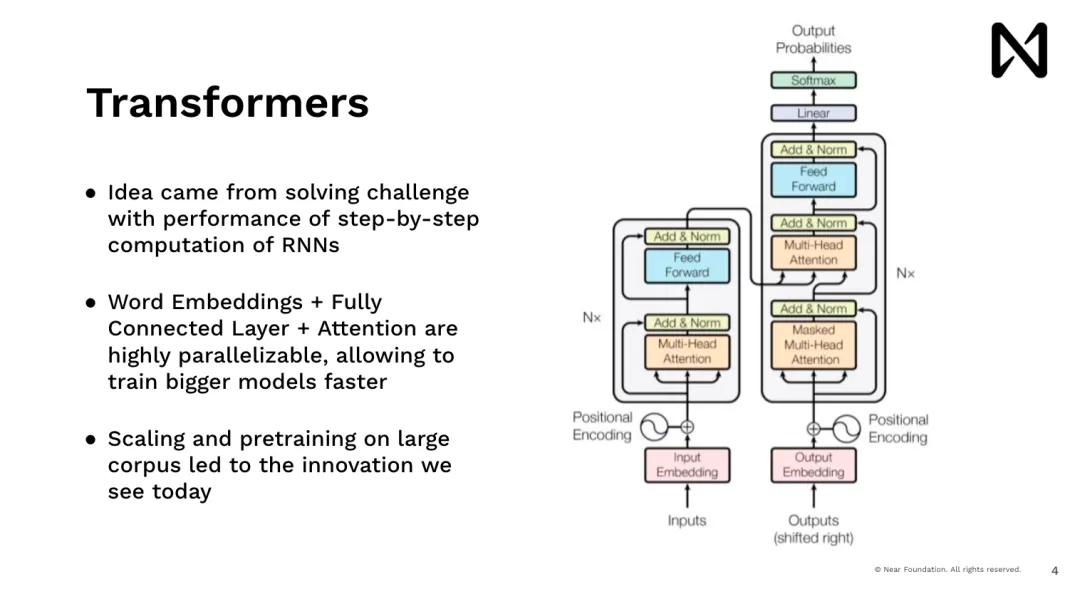
Hướng hiện tại là tăng tốc đổi mới trong trí tuệ nhân tạo. Trước đây, nó là một công cụ mà các nhà khoa học dữ liệu và kỹ sư máy học sẽ sử dụng và sau đó, theo cách nào đó, giải thích nội dung dữ liệu trong sản phẩm của họ hoặc có thể thảo luận về dữ liệu đó. người ra quyết định. Bây giờ chúng ta có mô hình AI giao tiếp trực tiếp với mọi người. Bạn thậm chí có thể không biết mình đang giao tiếp với người mẫu vì nó thực sự ẩn đằng sau sản phẩm. Vì vậy, chúng tôi đã trải qua quá trình chuyển đổi này từ những người hiểu cách AI hoạt động sang hiểu và có thể sử dụng nó.

Vì vậy, tôi sẽ cung cấp cho bạn một số bối cảnh ở đây, khi chúng tôi nói rằng chúng tôi đang sử dụng GPU để huấn luyện mô hình, đây không phải là loại GPU chơi game mà chúng tôi sử dụng trên máy tính để bàn để chơi trò chơi điện tử.

Mỗi máy thường có tám GPU, tất cả đều được kết nối với nhau thông qua một bo mạch chủ và sau đó được xếp thành các giá đỡ, mỗi máy có khoảng 16 máy. Tất cả các giá đỡ này hiện cũng được kết nối với nhau thông qua cáp mạng chuyên dụng để đảm bảo thông tin có thể được truyền trực tiếp giữa các GPU với tốc độ cực cao. Do đó, thông tin không vừa với CPU. Trên thực tế, bạn sẽ không xử lý nó trên CPU. Tất cả các tính toán xảy ra trên GPU. Vậy đây là một thiết lập siêu máy tính. Một lần nữa, đây không phải là kiểu "này, đây là GPU" truyền thống. Vì vậy, một mô hình có quy mô lớn như GPU4 đã sử dụng 10.000 chiếc H100 để huấn luyện trong khoảng ba tháng với chi phí 64 triệu USD. Bạn biết quy mô chi phí hiện nay là bao nhiêu và chi phí đào tạo một số mô hình hiện đại là bao nhiêu.
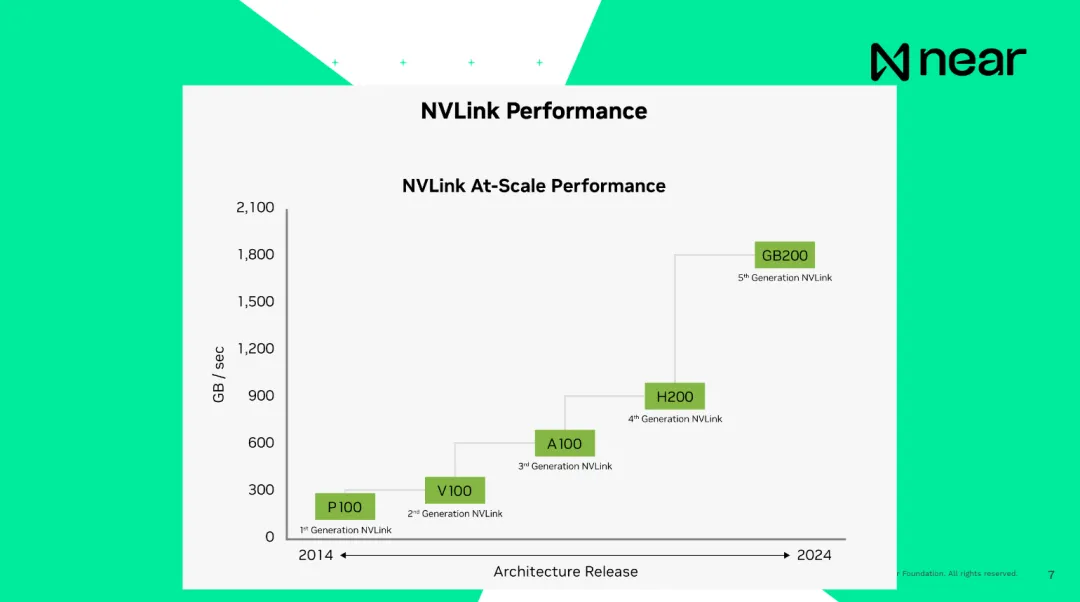
Điều quan trọng là khi tôi nói các hệ thống được kết nối với nhau, tốc độ kết nối hiện tại của H100, sản phẩm thế hệ trước, là 900GB mỗi giây và tốc độ kết nối giữa CPU bên trong của máy tính và RAM là 200GB mỗi giây, tất cả đều cục bộ với máy tính. Do đó, dữ liệu có thể được gửi từ GPU này sang GPU khác nhanh hơn máy tính của bạn có thể gửi trong cùng một trung tâm dữ liệu . Về cơ bản, máy tính của bạn có thể tự giao tiếp bên trong hộp. Tốc độ kết nối của thế hệ sản phẩm mới về cơ bản là 1,8TB/giây. Từ quan điểm của nhà phát triển, đây không phải là một đơn vị tính toán riêng lẻ. Đây là những siêu máy tính có bộ nhớ và sức mạnh tính toán khổng lồ, cung cấp cho bạn những phép tính có quy mô cực lớn.
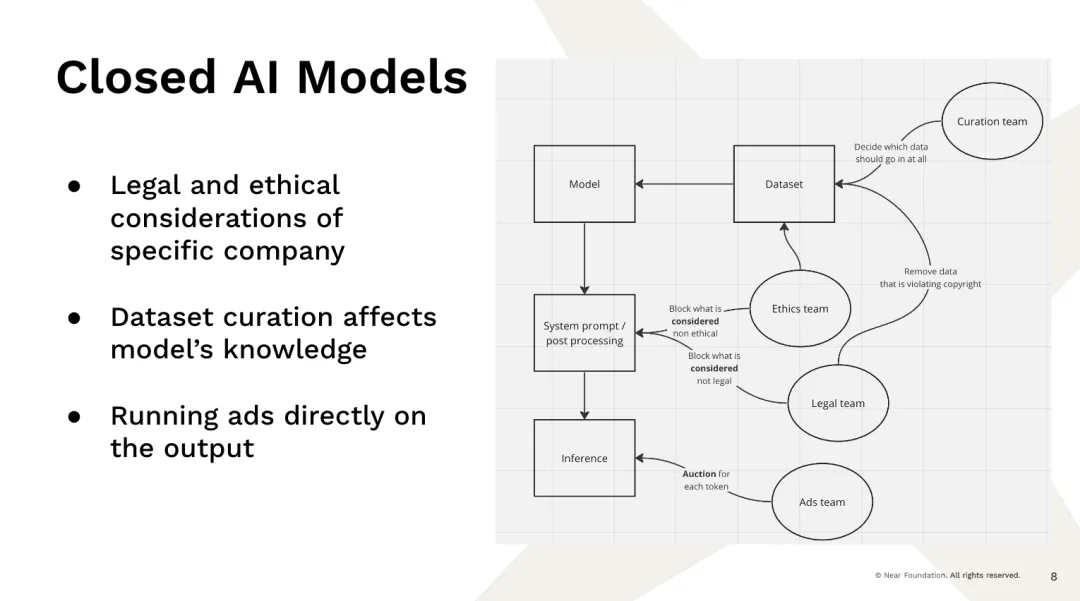
Bây giờ, điều này dẫn đến vấn đề mà chúng ta gặp phải, đó là những công ty lớn có nguồn lực và khả năng để xây dựng những mô hình này hiện đang cung cấp cho chúng ta khá nhiều dịch vụ này, tôi không biết thực sự có bao nhiêu công việc trong đó, Phải? Đó là một ví dụ, phải không? Bạn đến một nhà cung cấp công ty tập trung hoàn toàn và nhập một truy vấn. Hóa ra có một số đội ngũ không phải là đội ngũ kỹ thuật phần mềm mà là đội ngũ quyết định cách hiển thị kết quả, phải không? Bạn có một đội ngũ quyết định dữ liệu nào sẽ được đưa vào dữ liệu dữ liệu.
Ví dụ: nếu bạn chỉ lấy dữ liệu từ internet, số lần Barack Obama sinh ra ở Kenya và Barack Obama sinh ra ở Hawaii là hoàn toàn giống nhau, bởi vì mọi người thích suy đoán về các cuộc tranh cãi. Vì vậy, bạn phải quyết định những gì bạn muốn đào tạo. Bạn quyết định lọc ra một số thông tin vì bạn không tin đó là sự thật. Vì vậy, nếu một cá nhân như thế này đã quyết định dữ liệu nào sẽ được sử dụng và tồn tại, thì dữ liệu đó phần lớn bị ảnh hưởng bởi người đưa ra chúng. Bạn có đội ngũ pháp lý để quyết định nội dung nào chúng tôi không thể xem là có bản quyền và nội dung nào là bất hợp pháp. Chúng tôi có một "đội ngũ đạo đức" quyết định nội dung nào là phi đạo đức và nội dung nào chúng tôi không nên hiển thị.
Vì vậy, theo một cách nào đó, có rất nhiều hoạt động lọc và thao tác đang diễn ra. Những mô hình này là mô hình thống kê. Họ được chọn lọc từ dữ liệu. Nếu có gì đó không có trong dữ liệu, họ sẽ không biết câu trả lời. Nếu có điều gì đó trong dữ liệu, họ có thể coi đó là sự thật. Bây giờ, khi bạn nhận được câu trả lời từ AI, điều đó có thể đáng lo ngại. Phải. Bây giờ, lẽ ra bạn phải nhận được câu trả lời từ mô hình, nhưng không có gì đảm bảo cả. Bạn không biết kết quả được tạo ra như thế nào. Một công ty thực sự có thể thay đổi kết quả bằng cách bán phiên cụ thể của bạn cho người trả giá cao nhất. Hãy tưởng tượng rằng bạn hỏi bạn nên mua loại xe nào và Toyota quyết định rằng hãng sẽ ưu tiên Toyota sẽ trả cho công ty 10 xu để mua.

Vì vậy, ngay cả khi bạn sử dụng những mô hình này làm cơ sở kiến thức được cho là trung lập và đại diện cho dữ liệu, thì thực tế trước khi bạn nhận được kết quả, rất nhiều điều xảy ra làm sai lệch kết quả theo một cách rất cụ thể. Điều này đã đặt ra rất nhiều câu hỏi, phải không? Về cơ bản, đó là một tuần đầy những cuộc chiến pháp lý khác nhau giữa các công ty lớn và giới truyền thông. SEC, gần như mọi người hiện đang cố gắng khởi kiện nhau vì những mô hình này tạo ra quá nhiều sự không chắc chắn và quyền lực. Và, nếu bạn mong đợi, vấn đề là các công ty công nghệ lớn sẽ luôn có động cơ để tiếp tục tăng trưởng thu nhập, phải không? Ví dụ: nếu bạn là công ty đại chúng, bạn cần báo cáo thu nhập và bạn cần tiếp tục tăng trưởng.
Để đạt được mục tiêu này, nếu bạn đã chiếm được thị trường mục tiêu, giả sử bạn đã có 2 tỷ người dùng. Không còn nhiều người dùng mới trên Internet nữa. Bạn không có nhiều lựa chọn ngoại trừ việc tối đa hóa thu nhập trung bình , có nghĩa là bạn cần rút nhiều giá trị hơn từ những người dùng có thể có ít giá trị hoặc bạn cần thay đổi hành vi của họ. AI sáng tạo rất giỏi trong việc thao túng và thay đổi hành vi của người dùng, đặc biệt nếu người ta cho rằng nó xuất hiện dưới dạng trí thông minh toàn diện. Vì vậy, chúng ta gặp phải tình huống rất nguy hiểm khi có rất nhiều áp lực pháp lý và các cơ quan quản lý không hiểu đầy đủ về cách thức hoạt động của công nghệ này. Chúng tôi làm rất ít để bảo vệ người dùng khỏi bị thao túng.

Nội dung lôi cuốn, nội dung gây hiểu lầm, thậm chí không có quảng cáo, bạn chỉ cần chụp ảnh màn hình thứ gì đó, đổi tiêu đề, đăng lên Twitter và mọi người sẽ phát điên. Bạn có khích lệ tài chính giúp bạn liên tục tối đa hóa thu nhập. Và thực ra bạn không làm điều xấu trong nội bộ Google, phải không? Khi quyết định tung ra mô hình nào, bạn thực hiện thử nghiệm A hoặc B để xem mô hình nào mang lại nhiều thu nhập hơn . Do đó, bạn không ngừng tối đa hóa thu nhập bằng cách rút nhiều giá trị hơn từ người dùng của mình. Hơn nữa, người dùng và cộng đồng không có thông tin đầu vào về nội dung của mô hình, dữ liệu được sử dụng hoặc những gì nó thực sự đang cố gắng đạt được. Đây là trường hợp của người dùng ứng dụng. Đây là một sự điều chỉnh.
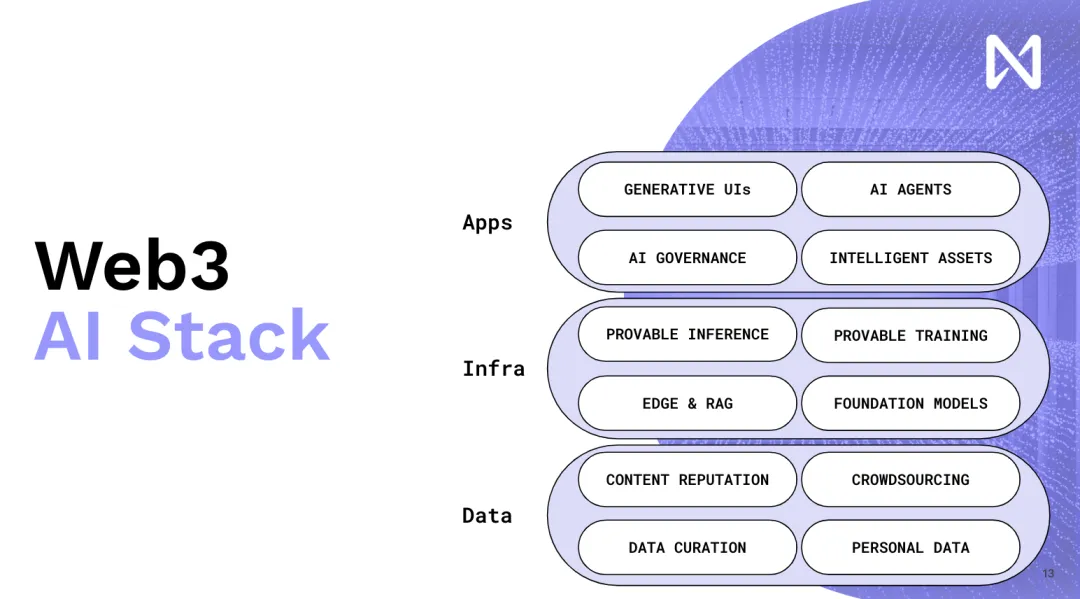
Đây là lý do tại sao chúng tôi tiếp tục thúc đẩy việc tích hợp WEB 3 và AI. Nó có thể là một công cụ quan trọng. Nó cho phép chúng tôi có khích lệ mới và khích lệ chúng tôi sản xuất phần mềm và sản phẩm tốt phi tập trung . Đây là định hướng chung cho toàn bộ quá trình phát triển web 3 AI. Bây giờ để giúp bạn hiểu chi tiết hơn, tôi sẽ nói ngắn gọn về các phần cụ thể. Trước hết, phần đầu tiên là Danh tiếng nội dung.

Một lần nữa, đây không phải là vấn đề thuần túy của AI, mặc dù các mô hình ngôn ngữ mang lại sức mạnh và quy mô to lớn cho cách con người thao tác và khai thác thông tin. Điều bạn muốn là danh tiếng crypto có thể theo dõi, có thể theo dõi được, danh tiếng này sẽ hiển thị khi bạn xem các nội dung khác nhau. Vì vậy, hãy tưởng tượng rằng bạn có một số nút cộng đồng thực sự crypto và có sẵn trên mọi trang của mọi trang web. Bây giờ, nếu bạn vượt qua điều đó, tất cả các nền tảng phân phối này sẽ bị gián đoạn vì những mô hình này hiện sẽ đọc gần như toàn bộ nội dung này và cung cấp cho bạn các bản tóm tắt được cá nhân hóa và đầu ra được cá nhân hóa.
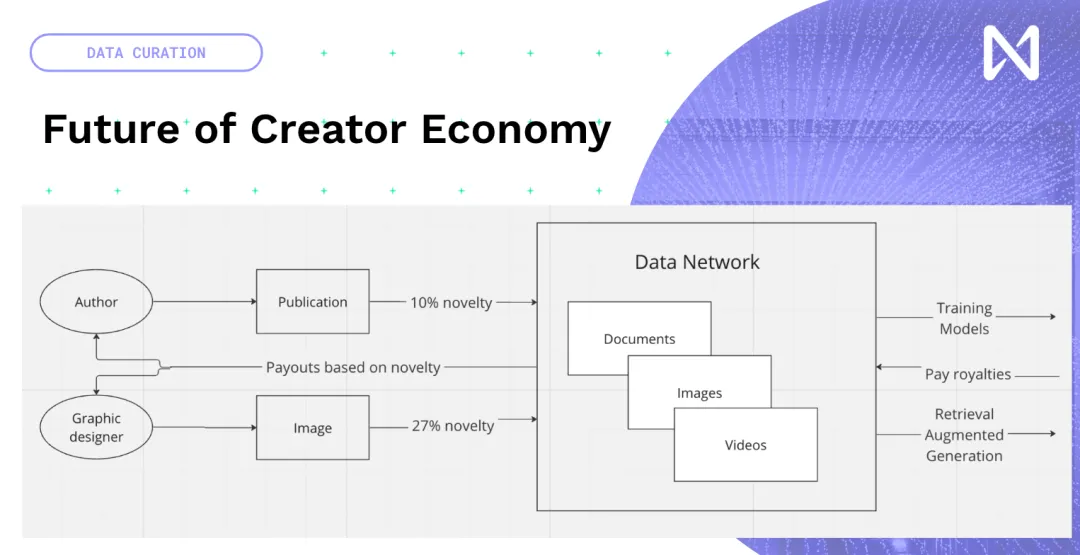
Vì vậy, chúng tôi thực sự có cơ hội tạo nội dung sáng tạo mới và thay vì cố gắng sáng tạo lại, hãy thêm blockchain và NFT vào nội dung hiện có. Một nền kinh tế sáng tạo mới xoay quanh thời gian suy luận và đào tạo mô hình, nơi dữ liệu mọi người tạo ra, cho dù đó là ấn phẩm mới, ảnh, YouTube hay âm nhạc bạn tạo, sẽ được đưa vào mạng dựa trên mức độ đóng góp của dữ liệu đó cho việc đào tạo mô hình. Vì vậy, dựa trên điều này, có một số khoản bồi thường có sẵn trên toàn cầu dựa trên nội dung. Vì vậy, chúng ta đang chuyển đổi từ một nền kinh tế thu hút sự chú ý hiện được thúc đẩy bởi các mạng quảng cáo sang một nền kinh tế thực sự cung cấp thông tin sáng tạo và thú vị.
Một điều quan trọng tôi muốn đề cập là lượng lớn điều không chắc chắn đến từ các phép toán dấu phẩy động. Tất cả các mô hình này liên quan đến lượng lớn nhiều phép tính dấu phẩy động và phép nhân. Đây là những hoạt động không chắc chắn.
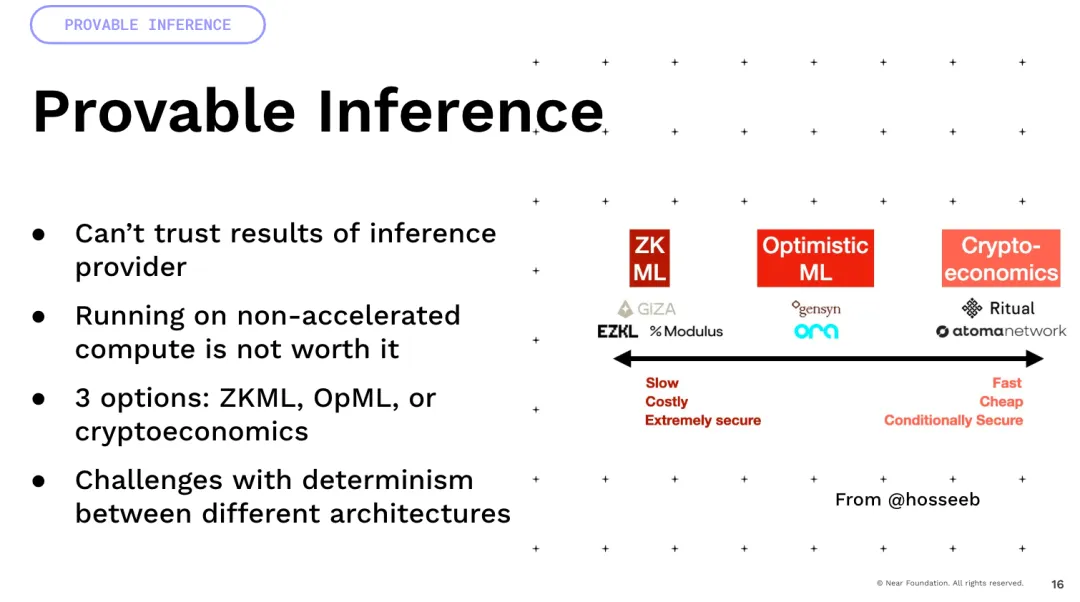
Bây giờ, nếu bạn nhân chúng trên các kiến trúc GPU khác nhau. Vì vậy nếu lấy A100 và H100 thì kết quả sẽ khác nhau. Do đó, nhiều phương pháp dựa vào thuyết tất định, chẳng hạn như crypto và sự lạc quan, sẽ thực sự gặp rất nhiều khó khăn và đòi hỏi nhiều sự đổi mới để đạt được điều này. Cuối cùng, có một ý tưởng thú vị, chúng tôi đang xây dựng các loại tiền tệ có thể lập trình và tài sản có thể lập trình, nhưng nếu bạn có thể tưởng tượng rằng bạn thêm thông tin này vào chúng, bạn có thể có tài sản thông minh hiện không được xác định bằng mã, mà được xác định bởi khả năng ngôn ngữ tự nhiên để tương tác với thế giới, phải không? Đó là nơi chúng tôi có thể có nhiều cách tối ưu hóa lợi nhuận thú vị, DeFi, chúng tôi có thể thực hiện các chiến lược giao dịch trên toàn thế giới.

Thách thức bây giờ là không có sự kiện nào hiện tại có hành vi Mạnh mẽ. Họ không được đào tạo để trở nên mạnh mẽ trước đối thủ vì mục đích đào tạo là dự đoán mã thông báo tiếp theo. Vì vậy, việc thuyết phục người mẫu đưa toàn bộ số tiền của bạn sẽ dễ dàng hơn. Trước khi tiếp tục, điều quan trọng là phải thực sự giải quyết vấn đề này. Vì vậy tôi sẽ để lại cho bạn ý tưởng này, chúng ta đang ở ngã tư đường, phải không? Có một hệ sinh thái AI khép kín có khích lệ và bánh đà cực kỳ hấp dẫn vì khi tung ra một sản phẩm, họ tạo ra lượng lớn thu nhập và sau đó đầu tư thu nhập đó vào việc xây dựng sản phẩm. Tuy nhiên, sản phẩm vốn được thiết kế để tối đa hóa thu nhập của công ty và do đó rút giá trị từ người dùng. Hoặc chúng tôi có phương pháp mở, do người dùng sở hữu này, trong đó người dùng có quyền kiểm soát.

Những mô hình này thực sự có lợi cho bạn, cố gắng tối đa hóa lợi nhuận của bạn. Chúng cung cấp cho bạn một cách để thực sự bảo vệ bạn khỏi nhiều mối nguy hiểm trên Internet. Vì vậy, đây là lý do tại sao chúng ta cần phát triển và ứng dụng nhiều hơn nữa về AI x Crypto. cảm ơn tất cả.
Tuyên bố miễn trừ trách nhiệm: Là một nền tảng thông tin blockchain, các bài viết được xuất bản trên trang này chỉ thể hiện quan điểm cá nhân của tác giả và khách và không liên quan gì đến quan điểm của Web3Caff. Thông tin trong bài viết chỉ tham khảo và không cấu thành bất kỳ lời khuyên hay đề nghị đầu tư nào. Vui lòng tuân thủ luật pháp và quy định có liên quan của quốc gia hoặc khu vực nơi bạn sinh sống.






