Tang Jie (@jietang) là giáo sư tại Đại học Thanh Hoa và là nhà khoa học AI trưởng tại Zhipu (công ty đứng sau sê-ri mô hình GLM). Ông cũng là một trong những người am hiểu nhất về các mô hình quy mô lớn ở Trung Quốc. Gần đây, ông đã đăng một bài viết dài trên Weibo (xem bình luận) thảo luận về những hiểu biết của mình về các mô hình quy mô lớn vào năm 2025.
Điều thú vị là Tang Jie và Andrej Karpathy có nhiều nhận xét chung, nhưng cũng có một số điểm nhấn khác biệt. Việc xem xét quan điểm của hai chuyên gia hàng đầu này song song sẽ cho thấy một bức tranh toàn diện hơn.
Nội dung khá dài, nhưng có một câu tôi muốn nhấn mạnh ở đầu bài:
Nguyên tắc đầu tiên của việc ứng dụng mô hình AI không phải là tạo ra các ứng dụng mới; bản chất của nó là để trí tuệ nhân tạo tổng quát (AGI) thay thế công việc của con người. Do đó, phát triển AI có khả năng thay thế các công việc khác nhau là chìa khóa cho việc ứng dụng nó. Nếu bạn đang phát triển các ứng dụng AI, bạn nên liên tục xem xét tuyên bố này: Nguyên tắc đầu tiên của việc ứng dụng AI không phải là tạo ra sản phẩm mới, mà là thay thế công việc của con người. Một khi bạn hiểu điều này, thứ tự ưu tiên của nhiều việc sẽ trở nên rõ ràng.
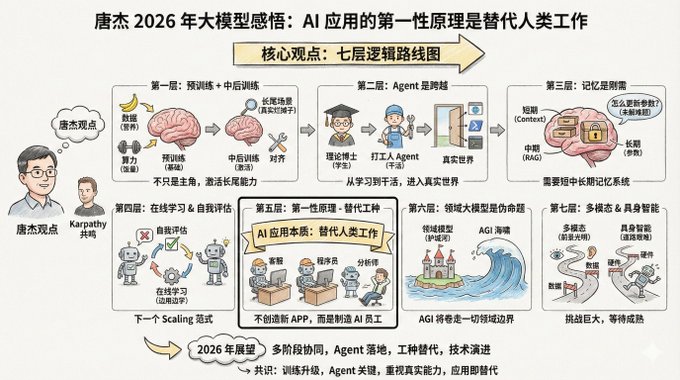
Quan điểm cốt lõi của Tang Jie có bảy lớp logic.
---
Lớp đầu tiên: Huấn luyện trước không hề lỗi thời, chỉ là nó không còn là yếu tố chính duy nhất nữa. Huấn luyện trước vẫn là nền tảng để mô hình nắm vững kiến thức thế giới và khả năng suy luận cơ bản.
Nhiều dữ liệu hơn, tham số lớn hơn và tính toán chuyên sâu hơn vẫn là những cách hiệu quả nhất để nâng cao trí thông minh của mô hình. Điều này giống như một đứa trẻ đang lớn; lượng thức ăn (tỷ lệ băm) và chất dinh dưỡng (dữ liệu) phải đủ. Đây là một định luật vật lý không thể tránh khỏi.
Nhưng chỉ trí thông minh thôi là chưa đủ. Các mô hình hiện tại có một vấn đề: chúng thường "mất cân bằng". Để cải thiện điểm số chuẩn, nhiều mô hình tập trung vào các vấn đề cụ thể, khiến chúng kém hiệu quả hơn trong các tình huống thực tế phức tạp. Điều này giống như việc ném một đứa trẻ vào môi trường làm việc thực tế sau chín năm giáo dục bắt buộc (đào tạo trước khi vào nghề) để xử lý những vấn đề không có trong sách giáo khoa - đó mới là nơi các kỹ năng thực sự được phát triển.
Do đó, trọng tâm tiếp theo là "huấn luyện giữa và sau huấn luyện". Hai giai đoạn này chịu trách nhiệm "kích hoạt" khả năng của mô hình, đặc biệt là khả năng căn chỉnh trong các cảnh có đuôi dài.
Các kịch bản "đuôi dài" là gì? Đó là những nhu cầu không phổ biến nhưng có thật. Ví dụ, giúp luật sư sắp xếp các hợp đồng đặc biệt hoặc giúp bác sĩ phân tích hình ảnh các bệnh hiếm gặp. Những kịch bản này chiếm tỷ lệ một tỷ lệ nhỏ trong tập dữ liệu kiểm thử thông thường, nhưng lại rất quan trọng trong các ứng dụng thực tế.
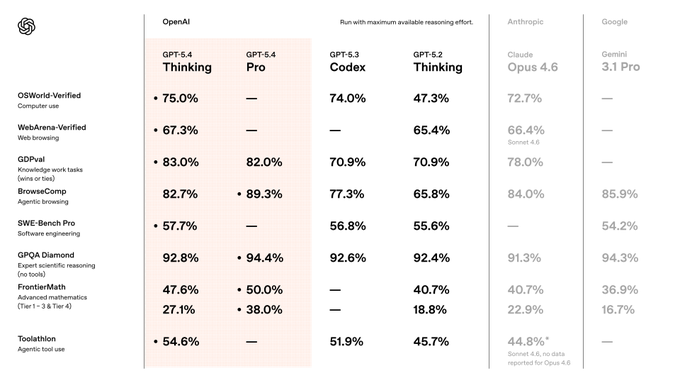
Mặc dù các tiêu chuẩn đánh giá chung giúp đánh giá hiệu suất của mô hình, chúng cũng có thể dẫn đến hiện tượng quá khớp (overfitting) ở nhiều mô hình. Điều này phù hợp với quan điểm của Karpathy rằng "huấn luyện trên tập dữ liệu kiểm thử là một nghệ thuật mới". Mọi người đều đang cố gắng nâng cao thứ hạng của mình, nhưng đạt điểm cao trên bảng xếp hạng không đồng nghĩa với việc giải quyết được các vấn đề thực tế.
---
Lớp thứ hai: Tác nhân đại diện cho sự chuyển đổi từ "sinh viên" sang "người đi làm". Tang Jie đã sử dụng một phép so sánh sinh động:
Nếu thiếu khả năng hoạt động như một tác nhân, một mô hình lớn chỉ là một "luận án tiến sĩ lý thuyết". Cho dù một người đọc bao nhiêu sách, thậm chí đạt đến trình độ sau tiến sĩ, nếu họ không thể giải quyết vấn đề, họ chỉ là một kho chứa kiến thức, không thể tạo ra năng suất.
Sự so sánh này rất chính xác. Giai đoạn tiền huấn luyện giống như tham gia các lớp học, và học tăng cường giống như thực hành giải bài tập, nhưng cả hai đều đang trong "giai đoạn học tập". Tác nhân (agent) là chìa khóa để mô hình thực sự "hoạt động", và nó là ngưỡng để bước vào thế giới thực và tạo ra giá trị thực tiễn.
Khái quát hóa và chuyển giao kiến thức giữa hoàn cảnh tác nhân khác nhau không hề dễ dàng. Các kỹ năng bạn phát triển trong hoàn cảnh lập trình có thể không hoạt động tốt trong hoàn cảnh trình duyệt. Cách tiếp cận đơn giản nhất hiện nay là liên tục thu thập dữ liệu từ nhiều hoàn cảnh hơn và thực hiện học tăng cường được điều chỉnh phù hợp với hoàn cảnh đó.
Trước đây, khi phát triển các tác nhân, chúng ta thường gắn thêm nhiều công cụ khác nhau vào mô hình. Xu hướng hiện nay là trực tiếp tích hợp dữ liệu từ việc sử dụng các công cụ này vào "ADN" của mô hình để huấn luyện.
Điều này nghe có vẻ hơi ngớ ngẩn, nhưng thực tế đây là con đường hiệu quả nhất hiện nay.
Karpathy cũng liệt kê Agent là một trong những thay đổi quan trọng nhất năm nay. Ông dẫn chứng Claude Code làm ví dụ, nhấn mạnh rằng Agent cần có khả năng "sống trong máy tính của bạn", gọi các công cụ, thực thi các vòng lặp và giải quyết các vấn đề phức tạp.
---
Lớp thứ ba: Bộ nhớ là một yêu cầu cơ bản, nhưng cách thức đạt được nó vẫn chưa rõ ràng. Tang Jie đã dành một lượng thời gian đáng kể để thảo luận về bộ nhớ. Ông cho rằng rằng khả năng ghi nhớ là yếu tố thiết yếu để các mô hình được triển khai trong hoàn cảnh thực tế.
Ông chia trí nhớ con người thành bốn lớp:
- Trí nhớ ngắn hạn, tương ứng với vỏ não trước trán
- Trí nhớ trung hạn, tương ứng với vùng hồi hải mã.
Những ký ức dài hạn nằm ở vỏ não.
- Trí nhớ lịch sử của con người, tương ứng với Wikipedia và các ghi chép lịch sử.
Trí tuệ nhân tạo cũng cần mô phỏng cơ chế này; mô hình lớn có thể tương ứng với:
- Cửa sổ ngữ cảnh → Bộ nhớ ngắn hạn
- Tìm kiếm RAG → Bộ nhớ trung gian
- Tham số mô hình → Một cách tiếp cận đối với trí nhớ dài hạn là "trí nhớ nén", phương pháp này cô đọng thông tin quan trọng và lưu trữ nó trong ngữ cảnh. Các "ngữ cảnh siêu dài" hiện tại chỉ giải quyết trí nhớ ngắn hạn, về cơ bản là kéo dài "giấy ghi chú" có thể sử dụng được. Nếu cửa sổ ngữ cảnh trở nên đủ dài trong tương lai, thì trí nhớ ngắn hạn, trung hạn và dài hạn đều có thể đạt được.
Nhưng còn một vấn đề khó khăn hơn nữa: làm thế nào để cập nhật kiến thức của chính mô hình? Làm thế nào để thay đổi các tham số? Đây vẫn là một vấn đề chưa được giải quyết.
---
Lớp thứ tư: học trực tuyến và tự đánh giá có thể là mô hình mở rộng quy mô tiếp theo. Phần này là phần có tầm nhìn xa nhất trong quan điểm của Tang Jie.
Mô hình hiện tại đang ở trạng thái "ngoại tuyến", nghĩa là nó được huấn luyện nhưng không thay đổi. Điều này gây ra một số vấn đề: mô hình không thể tự lặp lại một cách thực sự, việc huấn luyện lại lãng phí tài nguyên và nhiều dữ liệu tương tác bị mất.
Lý tưởng nhất là mô hình nên có khả năng học hỏi trực tuyến, trở nên thông minh hơn sau mỗi lần sử dụng.
Tuy nhiên, để đạt được điều này, có một điều kiện tiên quyết: mô hình phải biết liệu nó có đúng hay không. Điều này được gọi là "tự đánh giá". Nếu mô hình có thể đánh giá chất lượng đầu ra của chính nó, ngay cả khi đó là một đánh giá xác suất, nó sẽ biết mục tiêu tối ưu hóa và có thể tự cải thiện.
Tang Jie cho rằng rằng việc xây dựng cơ chế tự đánh giá cho một mô hình là một vấn đề khó khăn, nhưng nó cũng có thể là hướng đi của mô hình mở rộng quy mô tiếp theo. Ông đã sử dụng một số thuật ngữ: học tập liên tục, học tập thời gian thực và học tập trực tuyến.
Điều này củng cố quan điểm của Karpathy về RLVR. RLVR hiệu quả chính xác bởi vì nó cung cấp "phần thưởng có thể kiểm chứng", cho phép mô hình tự xác định độ chính xác của mình. Nếu cơ chế này có thể được khái quát hóa cho nhiều kịch bản hơn, học trực tuyến có thể trở thành hiện thực.
---
Lớp thứ năm: Nguyên tắc đầu tiên của các ứng dụng trí tuệ nhân tạo là "thay thế việc làm".
Đây là câu nói đã truyền cảm hứng cho tôi nhiều nhất:
Nguyên tắc đầu tiên của việc ứng dụng mô hình AI không phải là tạo ra các ứng dụng mới; bản chất của nó là để trí tuệ nhân tạo tổng quát (AGI) thay thế công việc của con người. Do đó, phát triển AI có thể thay thế các công việc khác nhau là chìa khóa cho việc ứng dụng nó.
Bản chất của trí tuệ nhân tạo không phải là tạo ra các ứng dụng mới, mà là thay thế công việc của con người.
Hai con đường:
1. Chuyển đổi phần mềm trước đây cần sự can thiệp của con người thành phần mềm được hỗ trợ bởi trí tuệ nhân tạo (AI).
2. Tạo ra phần mềm trí tuệ nhân tạo phù hợp với một công việc cụ thể của con người, trực tiếp thay thế người lao động.
Chat đã phần nào thay thế tìm kiếm và cũng đã tích hợp cả tương tác cảm xúc. Bước tiếp theo là thay thế dịch vụ khách hàng, lập trình viên cấp dưới và chuyên viên phân dữ liệu.
Do đó, bước đột phá vào năm 2026 nằm ở việc "Trí tuệ nhân tạo thay thế các công việc khác nhau".
Các doanh nhân không nên nghĩ về "mình muốn phát triển phần mềm gì cho người dùng", mà nên nghĩ về "mình muốn tạo ra loại nhân viên AI nào để giúp sếp cắt giảm chi phí nhân công cho một vị trí nhất định".
Nói cách khác, thay vì lúc nào cũng nghĩ đến việc tạo ra một sản phẩm "AI+X" mới, hãy nghĩ trước xem những công việc nào của con người có thể được thay thế, rồi sau đó sụp đổ để xác định hình thức sản phẩm.
Điều này lặp lại nhận xét của Karpathy về "Con trỏ cho X". Nếu Con trỏ về cơ bản là "phiên bản dựa trên trí tuệ nhân tạo của công việc lập trình viên", thì những thứ tương tự sẽ xuất hiện trong nhiều ngành công nghiệp khác nhau.
---
Lớp thứ sáu: Mô hình toàn miền là một "mệnh đề giả".
Quan điểm này có thể khiến một số người cảm thấy khó chịu, nhưng Tang Jie đã nói thẳng thừng: mô hình chuyên biệt theo lĩnh vực là một luận điểm sai lầm. Nếu chúng ta đang nói về Trí tuệ Nhân tạo Tổng quát (AGI), thì việc có "AGI chuyên biệt theo lĩnh vực" có ý nghĩa gì?
Lý do tồn tại các mô hình lớn chuyên biệt theo từng lĩnh vực là vì các công ty ứng dụng không muốn thừa nhận thất bại trước các công ty mô hình AI, và hy vọng xây dựng hệ thống bảo vệ bằng kiến thức chuyên môn và chế ngự AI thành một công cụ.
Nhưng bản chất của AI là một "cơn sóng thần" - nó sẽ cuốn trôi mọi thứ ở bất cứ nơi nào nó đến. Một số công ty trong một số lĩnh vực nhất định chắc chắn sẽ bước ra khỏi hệ thống bảo vệ và bị cuốn vào thế giới của AGI. Dữ liệu miền, quy trình và dữ liệu tác nhân của họ sẽ dần được tích hợp vào mô hình chính.
Dĩ nhiên, các mô hình miền sẽ tồn tại trong một thời gian dài trước khi Trí tuệ Nhân tạo Tổng quát (AGI) được hiện thực hóa. Nhưng khoảng thời gian đó sẽ kéo dài bao lâu? Rất khó để nói, bởi vì AI đang phát triển quá nhanh.
---
Lớp 7: Trí tuệ đa phương thức và thể hiện – Một tương lai tươi sáng nhưng con đường đầy khó khăn. Trí tuệ đa phương thức chắc chắn là tương lai. Tuy nhiên, vấn đề hiện tại là nó chỉ hỗ trợ hạn chế trong việc nâng cao giới hạn trên của AGI (Trí tuệ chuyên biệt theo khía cạnh).
Việc phát triển văn bản, đa phương thức và tạo nội dung đa phương thức có thể hiệu quả hơn nếu được thực hiện riêng biệt. Tất nhiên, việc kết hợp cả ba yếu tố này đòi hỏi sự can đảm và kinh phí.
Trí tuệ thể hiện (robot) thậm chí còn khó hơn. Thách thức cũng giống như với các tác nhân: tính linh hoạt. Bạn dạy một robot hoạt động trong kịch bản A, nhưng nó lại không hoạt động trong kịch bản khác. Bạn sẽ làm gì? Thu thập và dữ liệu dữ liệu khó khăn vừa tốn kém.
Phải làm sao? Thu thập dữ liệu, hay tổng hợp dữ liệu? Cả hai đều không dễ dàng và đều tốn kém. Nhưng ngược lại, một khi quy mô dữ liệu tăng lên và các khả năng đa năng xuất hiện, rào cản gia nhập thị trường sẽ tự nhiên hình thành.
Một vấn đề khác thường bị bỏ qua là chính bản thân robot cũng là một vấn đề. Sự không ổn định và các trục trặc thường xuyên là những vấn đề về phần cứng đang hạn chế sự phát triển của trí tuệ thể hiện.
Tang Jie dự đoán rằng sẽ có những tiến bộ đáng kể trong các lĩnh vực này vào năm 2026.
---
Khi liên kết bài viết của Tang Jie với toàn bộ bức tranh, ta thấy một lộ trình khá rõ ràng:
Hiện tại, việc điều chỉnh tỷ lệ bằng dữ liệu được huấn luyện trước vẫn hiệu quả, nhưng cần chú trọng hơn vào khả năng căn chỉnh và xử lý dữ liệu ở các phân bố đuôi dài.
Gần đây, các tác nhân (agents) đã tạo ra bước đột phá quan trọng, giúp các mô hình chuyển từ "nói" sang "hành động".
Trong trung hạn, hệ thống bộ nhớ và học trực tuyến là những khóa học thiết yếu, và các mô hình cần phải học cách tự đánh giá và cải tiến liên tục.
Về lâu dài, việc thay thế công việc là bản chất của các ứng dụng, và hệ thống bảo vệ nghề nghiệp sẽ bị phá vỡ bởi trí tuệ nhân tạo tổng quát (AGI).
Về lâu dài, các phương pháp đa phương thức và dựa trên trải nghiệm thực tế sẽ phát triển độc lập, chờ đợi sự hoàn thiện của công nghệ và dữ liệu.
---
Khi so sánh quan điểm của Tang Jie và Karpathy, có thể nhận thấy một số điểm đồng thuận:
Thứ nhất, thay đổi cốt lõi trong năm 2025 là nâng cấp mô hình đào tạo, từ "đào tạo trước là phương pháp chính" sang "hợp tác đa giai đoạn".
Thứ hai, Agent là một cột mốc, một bước tiến quan trọng giúp các mô hình chuyển từ giai đoạn học hỏi sang giai đoạn hành động.
Thứ ba, có sự chênh lệch giữa điểm chuẩn và khả năng thực tế, và vấn đề này đang nhận được sự quan tâm ngày càng tăng.
Thứ tư, bản chất của các ứng dụng AI là thay thế hoặc nâng cao công việc của con người, chứ không phải tạo ra ứng dụng chỉ vì mục đích tạo ra ứng dụng.
Sự khác biệt về trọng tâm nghiên cứu cũng rất thú vị. Karpathy quan tâm nhiều hơn đến câu hỏi triết học "trí tuệ nhân tạo có hình dạng như thế nào?", trong khi Tang Jie quan tâm hơn đến vấn đề kỹ thuật "làm thế nào để triển khai mô hình trong các tình huống thực tế". Một người thiên về "hiểu biết", người kia thiên về "triển khai".
Cả hai góc nhìn đều cần thiết. Chỉ khi có sự hiểu biết rõ ràng, chúng ta mới biết mình có đang đi đúng hướng hay không; chỉ khi có kỹ thuật vững chắc, chúng ta mới có thể biến ý tưởng thành hiện thực.
Năm 2026 sẽ là một năm tuyệt vời.
twitter.com/dotey/status/20035...