

PANDAS:以太坊下一代数据可用性采样的实用方法
作者:Onur Ascigil1、Michał Król2、Matthieu Pigaglio3、Sergi Reñé4、Etienne Rivière3、Ramin Sadre3
总结
- PANDAS 是一种网络层协议,支持 32 MB 及以上的Danksharding 。
- PANDAS 的目标是实现随机采样的 4 秒截止时间(在紧密分叉选择模型下)。
- 在提议者-构建者分离(PBS)之后,资源丰富的构建者对节点执行样本的初始分发(即播种)。
- PANDAS 在每个时隙期间分两个阶段进行:1)播种阶段,其中时隙的选定构建器将二维编码 blob的行和列的子集分发给验证器节点,2)行/列合并和采样阶段,其中节点对随机单元进行采样,同时检索和重建指定的行/列以提高单元的数据可用性。
- PANDAS 使用直接通信方式,这意味着 1 跳,即点对点通信,用于播种和采样阶段,而不是基于八卦的多跳方法或 DHT。
在设计 PANDAS 时,我们做出以下假设:
假设 1)资源丰富的构建者:按照提议者-构建者分离(PBS)方案,在 PANDAS 中,一组资源丰富的构建者(例如,具有足够高上传带宽(如 500 Mbps 或更高)的云实例)负责将种子样本分发到网络。[1]
假设 2)建造者激励:建造者有动机确保 blob 数据可用,因为只有 DAS 成功,The Block才会被接受。然而,不同的建造者可以拥有不同数量的资源。理性建造者的兴趣在于确保在花费最少资源的同时,数据将被视为可用。
假设 3)验证节点(VN)是 DAS 协议的主要实体:单个验证节点(VN)仅执行单个采样操作(作为一个实体),与其托管的验证器数量无关。
假设 4)不诚实的大多数:大多数(甚至绝大多数)的 VN 和建设者可能是恶意的,因此可能无法正确遵守协议。
假设 5)抗 Sybil 攻击的VN :诚实的 VN 可以使用验证器证明方案来证明其至少拥有一名验证器。如果多个节点尝试重复使用相同的证明,则其他诚实节点和构建者可能会将其列入黑名单。
以下是 PANDAS 的目标:
目标 1)紧密分叉选择:诚实的验证者节点(VN)在对区块进行投票之前完成随机抽样,即使大多数 VN 都是恶意的*。*因此,我们以紧密分叉选择模型为目标,这意味着某个时隙委员会中的诚实 VN 必须在该时隙的四秒内完成投票前的随机抽样。
目标 2)灵活的构建者播种策略:鉴于不同的构建者可以拥有不同的资源,我们的设计允许The Block构建者灵活地实施不同的 blob 分发策略,每种策略在安全性和资源使用之间都有不同的权衡。为了获得更高的安全性,构建者可以向验证者节点发送更多 blob 单元的副本,从而确保更高的可用性。相反,为了最大限度地减少资源使用,构建者最多可以分发每个单元的单个副本,以降低安全性为代价减少带宽使用。这种灵活的方法允许构建者在确保数据可用性和优化带宽之间进行权衡,同时激励验证者节点认为The Block可用并接受该区块。
目标 3) 允许不一致的节点视图:我们的目标是确保 VN 和构建者无需就 VN 列表达成共识。虽然我们的目标是让 VN 和构建者大致同意系统中的 VN 集,但 VN 不必保持严格一致的视图,也不必让构建者和 VN 的视图完全同步。
PANDAS 设计
持续对等发现:为了实现目标 3,系统中的节点与下面的协议阶段并行执行持续对等发现,以维护包含其他对等点的最新“视图”。构建者和 VN 旨在发现具有有效验证器证明的所有 VN。我们希望构建者和 VN 都能对系统中的所有 VN 有一个接近但不完美的视图。
运行对等发现协议的成员服务将新的(已验证的)VN 插入视图,并最终收敛为完整的 VN 集。对等发现消息被搭载到示例请求消息中,以减少发现开销。
PANDAS 协议有两个(不协调的)阶段,在每个时隙期间重复:
阶段 1 )播种,
第 2 阶段)行/列合并和抽样
在播种阶段,构建器将行/列的子集直接推送到 VN,其中行/列分配基于确定性函数。一旦 VN 从构建器收到样本,它就会合并分配给它的整个行/列(通过从分配给相应行/列的其他 VN 请求缺失的单元格)并同时执行随机采样。
VN 无需协调即可开始合并和采样。因此,完成第 1 阶段的节点可以立即开始第 2 阶段,而无需与其他节点协调。作为时隙委员会成员的 VN 必须在时隙开始后的 4 秒内完成播种和随机采样。
下面,我们详细解释我们的协议的两个阶段。
阶段 1 - 播种:构建器使用确定性函数将 VN 分配给各个行/列,该函数使用哈希空间,如下所述。VN 到各个行/列的映射是动态的,并且在每个槽中都会发生变化。映射允许节点在本地和确定性地将节点映射到行/列,而无需知道节点的数量或完整列表。
Builder 准备并向 VN 分发种子样本,如下所示:
1.a)将行/列映射到哈希空间中的静态区域:如图 1 上部所示,将各个行和列分配到哈希空间中的静态区域。
1.b)将 VN 映射到哈希空间:构建器使用抽签函数 FNODE(NodeID, epoch, slot, R) 将每个 VN 分配给哈希空间中的键。该函数采用的参数包括 NodeID(即节点的标识符,即对等 ID)、epoch 和 slot 编号,以及从上一个 slot 的The Block的头部派生的随机值 R。
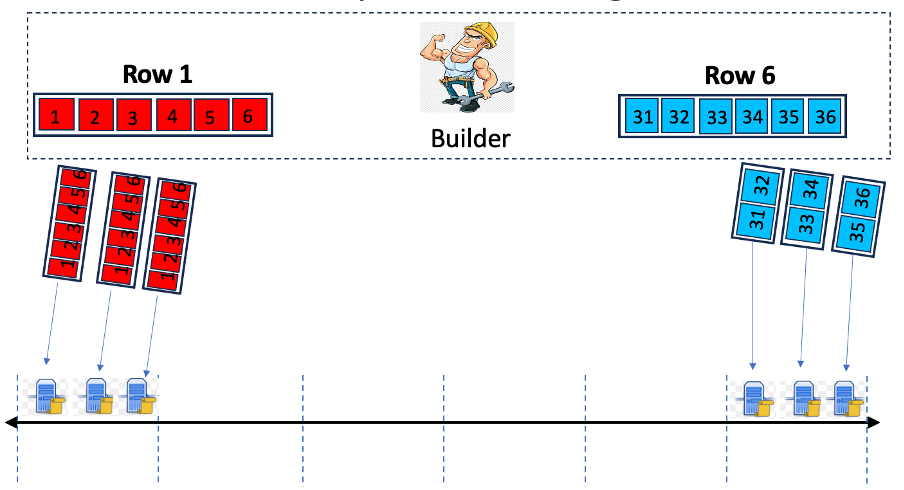
图 1:行样本到 VN 的分配。列样本的映射方式类似。
分配给行区域的 VN 将从构建器接收属于该行的单元格子集。由于 VN 在每个槽位期间使用 FNODE 重新映射到哈希空间,因此它们的行/列分配也会发生变化。
注意:在基于八卦的播种方法中,不可能按时隙动态地分配行和列给 VN,因为每行和每列的八卦通道必须随时间保持相对稳定。
1.c)行/列样本分布:对于每一行和每一列,构建器采用尽力而为的分布策略,将每一行/列的子集推送到映射到相应行/列区域的 VN。构建器使用直接通信方法,特别是基于 UDP 的协议,将每行/列的单元格直接分发到 VN。
直接沟通的理由*:*我们的目标是尽快完成播种阶段,以便委员会成员有时间在投票前完成随机抽样(目标 1)。
行/列分布策略:我们允许构建器根据目标 2 的资源可用性选择分布策略。不同的分布策略在资源使用和数据可用性之间存在权衡。考虑图 2 中分布两行的示例。在一个极端情况下(左侧),构建器将整个第 1 行分布到该行区域中的每个 VN,以提高数据可用性,但代价是更高的资源使用率。在另一个极端情况下,构建器将第 6 行的非重叠行片段发送到该行区域中的每个 VN,这需要更少的资源,但导致单个单元的可用性降低。
我们目前正在评估不同的分布策略,包括可以确定性地将行/列的各个单元映射到行/列区域中的各个 VN 的策略。
注意:建造者仅参与播种阶段。
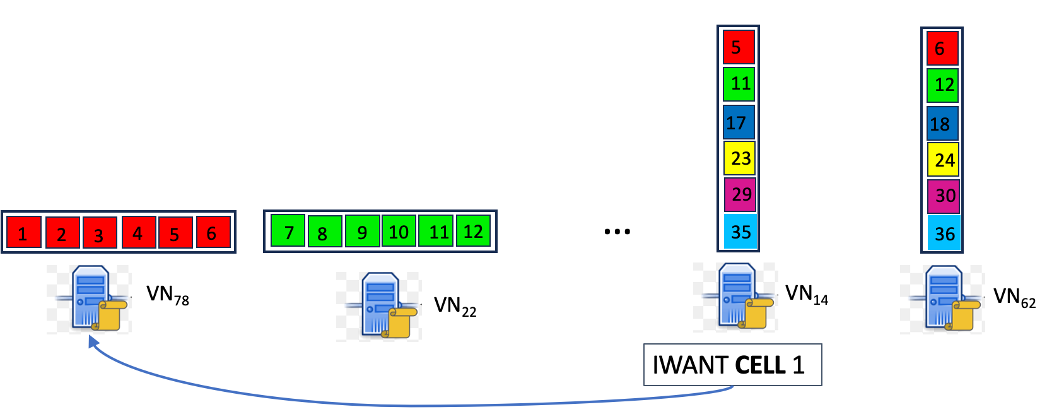
图 2:将行样本分发到相应行区域中的 VN 的两种(极端)策略。
第 2 阶段 - 行/列合并和采样:当前时段委员会的 VN 旨在在时段的前四秒内(即投票截止时间)完成随机采样。为了提高单元的可用性,特别是对于必须在四秒内执行(随机)采样的时段委员会成员,VN 还会进行合并,即根据 FNODE 映射检索分配给它们的整行和整列,作为行/列采样的一部分。
2.a) VN 随机抽样:当前时段委员会中的 VN 在从建造者处收到种子样本后,立即尝试检索73 个随机选择的单元。
使用确定性分配 FNODE,VN 可以在本地确定预计最终保管给定行或列的节点。
采样算法:其中一些节点可能处于离线状态或无响应。按顺序发送单元请求可能会错过委员会成员的 4 秒截止时间。
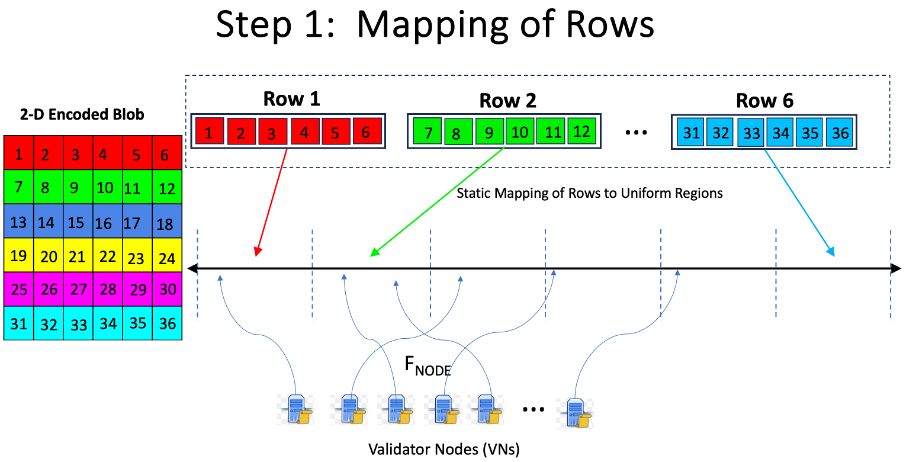
图 3:样本获取示例:分配给每个 VN 的行和列显示在相应 VN 的顶部。根据映射 FNODE 的知识,VN14 知道向 VN78 发送请求以检索单元格一。
同时,向所有持有副本的对等点发送请求会导致网络中消息激增,并承担拥塞风险。因此,获取必须在并行和冗余请求的使用与延迟约束之间寻求平衡。我们的方法采用自适应单元获取策略,通过基于 UDP(无连接)的协议在节点之间进行直接通信。获取算法可以容忍丢失和离线节点。
2.b) VN 行/列合并:如果 VN 从构建器收到的其指定行或列的单元格少于一半(这是构建器选择的分配策略的结果),它会向其他 VN 请求缺失的单元格。在行/列合并期间,VN 仅向分配给同一行/列区域的 VN 请求单元格。当 VN 拥有某一行或某一列的一半单元格时,它可以在本地重建整行或整列。
合并行/列的理由:
- 重建缺失细胞:在执行行/列采样时,VN 重建缺失细胞。
- 提高单元格的可用性:给定确定性映射(FNODE),构建器可以选择任何分发策略将行和列的子集发送到 VN。行/列合并旨在提高样本的可用性,以便能够按时完成随机抽样。
理想情况下,构建器应选择一种种子样本分布策略,使 VN 能够有效地合并行和列。为了实现这一点,构建器可以向每个 VN 推送一个地图(连同种子样本),该地图详细说明了行/列中的各个单元格如何分配给该行/列区域内的 VN,这是构建器分布策略的一部分。借助此地图,VN 可以快速识别和检索缺失的单元格以重建完整的行,从而提高数据的可用性。
注意:在某些 DAS 方法中,术语“行/列采样”是指节点在对 blob 的可用性进行投票之前检索多行和多列。在我们的方法中,节点检索行和列以增强数据可用性,支持必须在投票前进行随机采样的验证者。
我们将其称为“行/列合并”而不是“行/列抽样”,因为在 PANDAS 中,委员会成员基于随机抽样进行投票,并且他们不会直接对整行或整列进行抽样。
那么常规节点(RN)怎么样?
与 VN 不同,RN 不会从构建器获取种子行/列样本。构建器将初始种子样本发送到使用验证器证明方案的抗 Sybil 的 VN 组。目前没有机制让 RN 证明它们不是 Sybil;因此,来自构建器的样本的初始分布仅使用 VN。
使用公共确定性函数 FNODE,RN 可以类似地映射到单个行/列区域。映射到某个区域后,RN 可以(可选)执行行/列合并以检索整个行和列,并响应对其指定区域内单元格的查询。
与其他节点一样,RN 必须执行对等发现。一般来说,RN 的目标是发现所有 VN,也可以尝试发现其他 RN。通过对等发现了解其他对等点后,RN 可以通过直接通信执行随机采样。与 VN 不同,RN 完成采样的时间不受严格限制 — 它们可以在 VN 之后开始采样,例如,在收到当前时隙的The Block块头后。
讨论和正在进行的工作
我们假设理性的建造者有动机削减成本(并减少供应),但同时,他们的目标是提供区块(以获得奖励)。这意味着建造者将努力使行/列合并尽可能高效,即通过高效合并(提高单元的可用性),建造者可以在播种阶段发送更少的每个单元副本以降低成本。
我们目前正在试验不同的分发策略,其中恶意 VN 会保留样本并试图破坏对等发现。我们的 DAS 模拟代码可在DataHop GitHub 存储库中找到。
[1] 英国兰卡斯特大学
2 英国伦敦城市大学
3 天主教鲁汶大学 (UCLouvain)
4 DataHop 实验室






