

来源:福布斯
编译:MetaverseHub
上周有消息称,OpenAI 在新一轮融资中获得 65 亿美元,其市场估值也来到了 1500 亿美元。
这笔融资再次肯定了 OpenAI 作为人工智能初创公司的巨大价值,也表明它愿意做出结构性改变,以吸引更多投资。
消息人士补充说,鉴于 OpenAI 收入的快速增长,这一轮大规模融资受到了投资者的强烈追捧,并可能在未来两周内敲定。
Thrive Capital、Khosla Ventures 和微软等现有投资者有望参与。包括英伟达和苹果在内的新投资者也计划参与投资,红杉资本也在洽谈回归投资事宜。

同时,OpenAI 推出了 o1 系列,这是其迄今为止最复杂的人工智能模型,旨在出色地完成复杂的推理和问题解决任务。o1 模型使用了强化学习和思维链推理,代表了人工智能能力的重大进步。
OpenAI 通过不同的访问层级向 ChatGPT 用户和开发者提供 o1 模型。对于 ChatGPT 用户,ChatGPT Plus 计划的用户可以访问 o1-preview 模型,该模型具有高级推理和解决问题的能力。
OpenAI 的应用程序接口(API)允许开发人员在更高级别的订阅计划中访问 o1-preview 和 o1-mini。
这些模型在第 5 级 API 中提供,允许开发人员将 o1 模型的高级功能集成到自己的应用程序中。第 5 级 API 是 OpenAI 为访问其高级模型而提供的更高级别的订阅计划。
以下是有关 OpenAI o1 模型的 10 个关键要点:
01.两个模型变体:o1-Preview 和 o1-Mini
OpenAI 发布了两个变体:o1-preview 和 o1-mini。o1-preview 模型在复杂任务中表现出色,而 o1-mini 则为 STEM 领域(尤其是编码和数学)提供了更快、更具成本效益的优化解决方案。
02.高级思维链推理
o1 模型利用思维链过程,在做出回答之前会逐步推理。这种深思熟虑的方法提高了准确性,有助于处理需要多步骤推理的复杂问题,使其优于 GPT-4 等以前的模型。

思维链提示通过将复杂问题分解为连续的步骤来增强人工智能的推理能力,从而提高模型的逻辑和计算能力。
OpenAI 的 GPT-o1 模型将这一过程嵌入其架构中,模拟人类解决问题的过程,从而推进了这一过程。
这使得 GPT-o1 在竞技编程、数学和科学领域表现出色,同时也提高了透明度,因为用户可以跟踪模型的推理过程,这标志着类人人工智能推理的飞跃。
这种先进的推理能力会导致模型在做出响应前需要一定的时间,与 GPT-4 系列模型相比可能会显得缓慢。
03.增强的安全功能
OpenAI 在 o1 模型中嵌入了先进的安全机制。这些模型在不被允许的内容评估中表现出卓越的性能,显示出对「越狱」的抵抗性,使其在敏感用例中的部署更加安全。
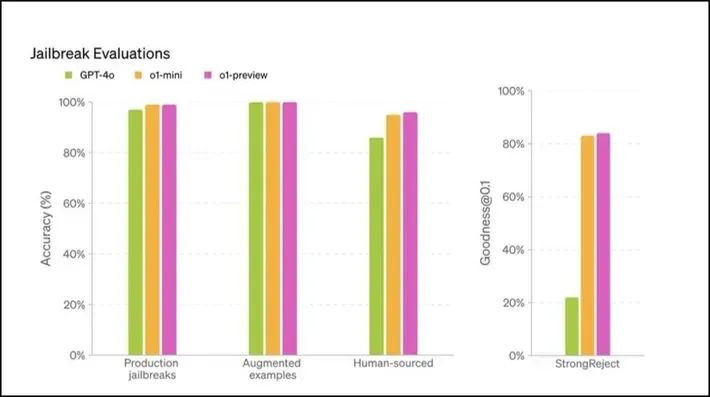
人工智能模型「越狱」涉及绕过安全措施,容易引发有害或不道德的输出。随着人工智能系统变得越来越复杂,与「越狱」相关的安全风险也随之增加。
OpenAI 的 o1 模型,尤其是 o1-preview 变体,在安全测试中得分更高,显示出更强的抵御此类攻击的能力。
这种增强的抵御能力得益于该模型的高级推理能力,这有助于它更好地遵守道德准则,使恶意用户更难操纵它。
04.在 STEM 基准测试中表现更佳
o1 模型在各种学术基准测试中名列前茅。例如,o1 在 Codeforces(编程竞赛)中排名第 89 位,在美国数学奥林匹克预选赛中名列前 500 名。
05.减少「高级幻觉」
大型语言模型中的「幻觉」是指生成错误或无据信息。OpenAI 的 o1 模型利用高级推理和思维链过程解决了这一问题,使其能够逐步思考问题。
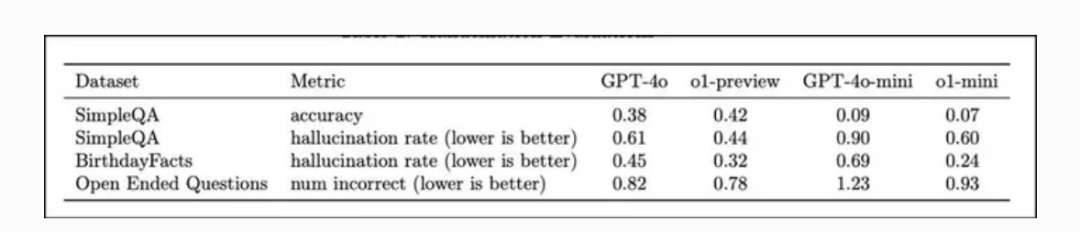
与以前的模型相比,o1 模型降低了「幻觉」发生率。
在 SimpleQA 和 BirthdayFacts 等数据集上进行的评估显示,o1-preview 在提供真实、准确的回答方面优于 GPT-4,从而降低了错误信息的风险。
06.基于多样化的数据集训练
o1 模型在公共、专有和定制数据集上进行了综合训练,使其既精通一般知识,又熟悉特定领域的主题。这种多样性使其具有强大的对话和推理能力。
07.价格友好且具成本效益
OpenAI 的 o1-mini 模型是 o1-preview 的高性价比替代品,价格便宜 80%,同时在数学和编码等 STEM 领域仍具有很强的性能。
o1-mini 模型专为需要高精度、低成本的开发人员量身定制,非常适合预算有限的应用。这种定价策略可确保更多的人,尤其是教育机构、初创企业和小型企业,能够接触到先进的人工智能。
08.安全工作和外部「红队测试」
在大语言模型(LLM)中,「红队测试」是指通过模拟其他人的攻击,或者用可能导致模型做出有害、有偏见或与初衷不符的行为的方式来严格测试人工智能系统。
这对于在大规模部署模型之前找出内容安全、错误信息和道德界限等方面的漏洞至关重要。

通过使用外部测试人员和不同的测试场景,红队测试有助于使 LLM 更加安全、稳健并符合道德标准。这样可以确保模型能够抵御「越狱」或其他方式的操纵。
在部署之前,o1 模型经过了严格的安全评估,包括红队测试和准备框架评估。这些努力有助于确保模型符合 OpenAI 的高安全性和一致性标准。
09.更公平,更少偏见
o1-preview 模型在减少刻板答案方面的表现优于 GPT-4。在公平性评估中,它能更多地选择正确答案,同时在处理模棱两可的问题方面也有改进。
10.思维链监控与欺骗检测
OpenAI 采用了实验技术来监控 o1 模型的思维链,以在模型故意提供错误信息时检测欺骗行为。初步结果表明,在降低模型生成的错误信息所带来的潜在风险方面,该技术具有良好的前景。
OpenAI 的 o1 模型代表了人工智能推理和解决问题方面的重大进步,尤其在数学、编码和科学推理等 STEM 领域表现出色。
随着高性能 o1-preview 和高性价比 o1-mini 的推出,这些模型针对一系列复杂任务进行了优化,同时通过广泛的红队测试确保了更高的安全性和道德合规性。





