

作者:brody
编译:深潮TechFlow
从表面上看,“加密货币与人工智能”似乎是一种强迫结合。
然而,在这些不对称中存在着潜在机会,风险与回报的比例似乎严重偏向于上行。这就是值得我们花时间深入思考的原因。
我经常被问到我对加密货币与人工智能融合的看法,这促使我开发了这个简单的框架:
区块链在哪些方面为人工智能应用引入了全新的优势?
AI 技术栈中的哪些组件通过去中心化协议得到了优化?
开源的去中心化 AI 应用在哪些方面达到了与其闭源竞争者相当的性能?
从整体来看,这里有几个我关注的关键领域,旨在回应这些问题:
区块链在哪些方面为人工智能开发解锁了全新的优势?
协调层:这些协议旨在协调 AI/ML 开发者,共同创建“智能”,通过提供他们的模型和资源换取奖励,这些奖励通常基于所产生智能的价值。
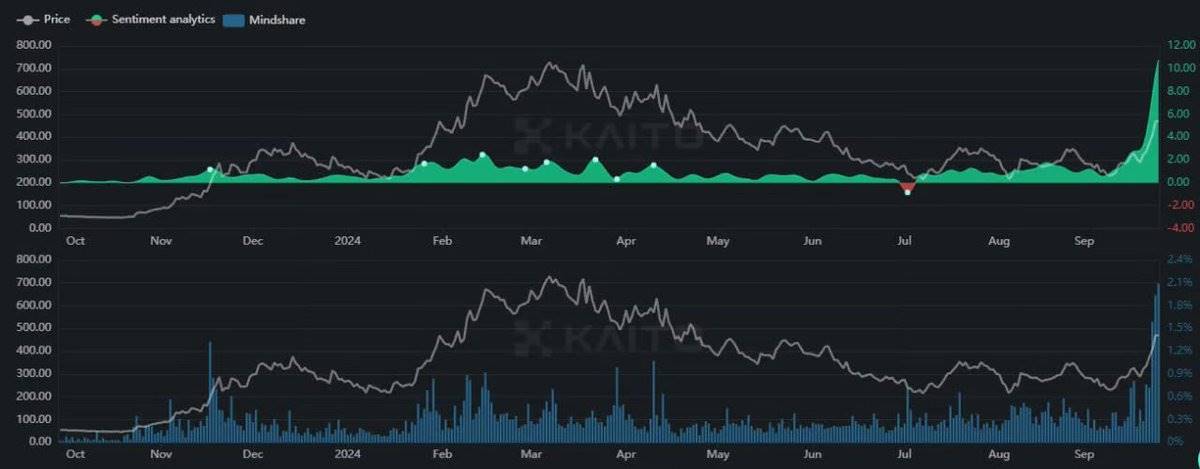
这就是我对 Bittensor 如此热情的原因。它正在大规模实现这一目标(目前有 48 个子网,并在不断扩展),拥有深厚的人才护城河,以及极少数生态系统能够效仿的热情代币持有者社区。
另一方面来看,Sentient、Allora 和 Nous Research 等团队也在进行类似的倡议,尽管它们的协议设计和方向有所不同。
激励对齐是区块链在最终阶段能够有效运作的核心原因之一,而这种应用对开源 AI 开发的支持是基本的。
人们正在逐渐意识到这一点。
AI 技术栈中的哪些组件通过去中心化协议得到了优化?
数据:获取高质量、经过验证和稳健的数据集对人工智能至关重要,但目前这仍然是一个巨大的瓶颈。数据收集过程中的优化将推动我们突破“数据壁垒”。
我们密切关注的几个团队是 Grass 和 Vana,它们都在通过激励和所有权创建新的高效和优化的数据收集机制。
简而言之,Vana 使数据 DAO(去中心化自治组织)得以实现,允许用户为独特的数据集做出贡献,并根据 AI 开发者对特定数据的需求来获得相应的奖励。
在这个领域中,正在测试几种方法论,所有这些方法论在客观上都优于它们的 Web 2 同类产品。
数据 DAO 示例

开源的去中心化 AI 应用程序在哪些方面的性能与其闭源同类产品达到了平衡?
分布式模型训练(Distributed Model Training):AI 模型训练是一个资源消耗极大的过程,涉及通过神经网络输入大型数据集,以训练模型完成特定任务。直到一个月前,人们曾认为以分布式方式进行这一过程极不可能。
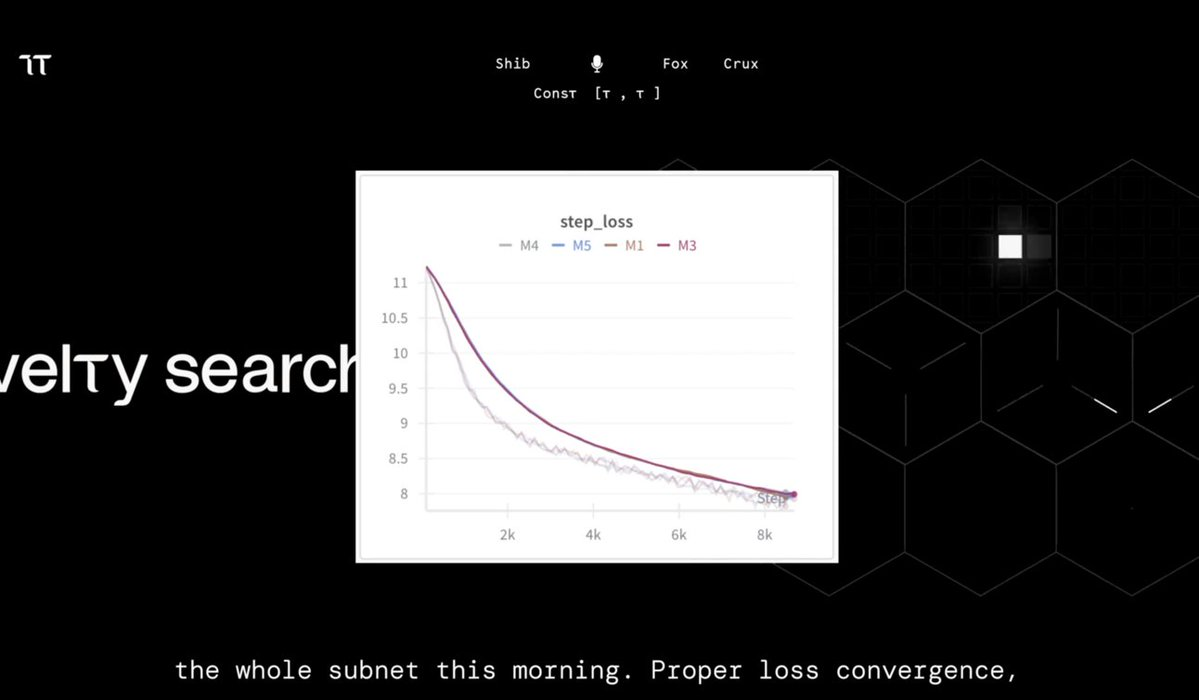
多亏了 Nous Research(DisTrO)和 Prime Intellect(DiLoCo)等先驱,在分布式模型训练方面,开源和去中心化 AI 的突破正在加速,与闭源替代品达到了性能平衡。
看到开源去中心化 AI 领域的这些基础性突破让人感到兴奋,因为这充分证明了将这一领域视为单纯依靠炒作的“包办婚姻”是错误的。
DisTrO 在上周的 Novelty Search 活动中部署于 Bittensor 子网。
有句话说得好:“如果他们没有对你进行 FUD(恐惧、不确定性和怀疑),那么你就没有在构建任何值得 FUD 的东西。”我们认为这一说法适用于这个领域。
毕竟,我们接受 FUD(恐惧、不确定性和怀疑)的存在。这使我们退一步,构建出更强大的框架和评估,以应对这些看似复杂、难以解读的领域。
感谢所有为这些工作付出努力的建设者们!你们的贡献得到了大家的认可。






