

在本文中,Vitalik 对上述众多涉及可扩展性相关技术路线的历史研究、最新研发进展进行了承上启下的总结与分析,并补充阐述新的技术条件下无信任(trustless)、L1 原生 rollups 等新可能性。
原文:Possible futures of the Ethereum protocol, part 2: The Surge(vitalik.eth)
作者:vitalik.eth
编译:183Aaros,Yewlne,LXDAO
译者的话
“打破可扩展性三难困境非常困难,但并非不可能,它需要以某种方式跳出论证所暗示的思维定式。” —— Vitalik Buterin。
为了可扩展性三难困境(scalability trilemma),以太坊在各历史时期有着众多技术设想与尝试,从状态通道(state channels)、分片(sharding),到 rollups、Plasma,再到现如今生态里共同聚焦的大规模 “数据可用性(data availability)”。直至 2023 年 The Surge 路线图,以太坊才选择了这条遵 “以 L1 的鲁棒性与去中心化为中心,多元化(pluralistic)L2s 多样发展”、或许能超越三难困境的技术哲学道路。作为前文《以太坊协议可能的未来(一):The Merge》的续篇,在本文中,Vitalik 对上述众多涉及可扩展性相关技术路线的历史研究、最新研发进展进行了承上启下的总结与分析,并补充阐述新的技术条件下无信任(trustless)、L1 原生 rollups 等新可能性。
本文概述
本文共约 11000 字,有 7 个部分,阅读完本文预计需要 60 分钟。
- 补充:可扩展性三难困境
- 数据可用性采样(data availability sampling)的进一步进展
- 数据压缩(data compression)
- 通用 Plasma
- 成熟的 L2 证明系统(proof systems)
- 跨 L2 互操作性和用户体验改进
- L1 上的扩展执行
正文内容
《以太坊协议可能的未来(二):The Surge》
特别感谢 Justin Drake、Francesco、Hsiao-wei Wang、@antonttc 和 Georgios Konstantopoulos
最初,以太坊在其路线图中有两种扩展策略。一种(参见 2015 年的这篇早期论文)是 “分片(sharding)”:每个节点只需验证和存储一小部分交易,而不是验证和存储链中的所有交易。其他点对点网络(例如 BitTorrent)也是这样运作的,所以我们当然可以让区块链以同样的方式工作。另一种是 Layer 2 协议:位于以太坊之上的网络,可以充分利用其安全性,同时将大多数数据和计算保留在主链之外。“Layer 2 协议” 在 2015 年意味着状态通道(state channels),2017 年意味着 Plasma,然后是 2019 年的 rollups。rollups 比状态通道或 Plasma 更强大,但它们需要大量的链上数据带宽。幸运的是,到 2019 年,分片研究已经解决了大规模验证 “数据可用性(data availability)” 的问题。结果,两条路径汇聚在一起,我们得到了以 rollup 为中心的路线图,这仍然是当今以太坊的扩展战略。
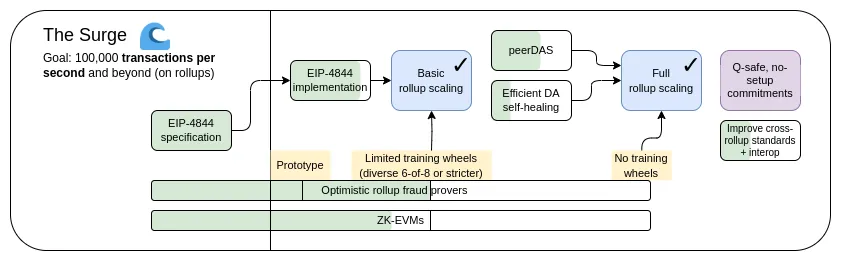
以 rollup 为中心的路线图提出了一种简单的分工:以太坊 L1 专注于成为一个鲁棒且去中心化的基础层,L2 则承担帮助生态系统扩展的任务。这种模式在社会中随处可见:法院系统(L1)不是为了极度高效而存在,而是为了保护契约和产权,企业家(L2)则要在坚固的基础层(layer)之上构建并将人类带上(比喻和字面意义上的)火星。
今年,以 rollup 为中心的路线图取得了重要的成功:随着 EIP-4844 blob 的出现,以太坊 L1 数据带宽大幅提升,多个 EVM rollup 现已处于第 1 阶段。一种高度异构与多元化分片应用的路径已经成为现实,其中每个 L2 都充当一个具有自己内部规则和逻辑的 “分片”。但正如我们所见,走这条路有其独特的挑战。所以现在我们的任务是完成以 rollup 为中心的路线图,并解决这些问题,同时保持以太坊 L1 的鲁棒性(robustness)与去中心化。
The Surge:主要目标
- L1+L2 上 100,000+ 的 TPS
- 保持 L1 的去中心化和鲁棒性
- 至少一些 L2 完全继承了以太坊的核心属性(无需信任、开放、抗审查)
- 最大化 L2 之间的互操作性。以太坊应该让人感觉像一个生态系统,而不是 34 个不同的区块链。
本章内容
- 补充:可扩展性三难困境
- 数据可用性采样(data availability sampling)的进一步进展
- 数据压缩(data compression)
- 通用 Plasma
- 成熟的 L2 证明系统(proof systems)
- 跨 L2 互操作性和用户体验改进
- L1 上的扩展执行
补充:可扩展性三难困境(scalability trilemma)
可扩展性三难困境是于 2017 年提出 的一个想法,主要讨论的是以下三个属性之间矛盾:去中心化(更具体地说:运行节点的成本低)、可扩展性(更具体地说:处理高交易数量的能力)和安全性(更具体地说:攻击者需要先破坏网络的大部分节点才能使单笔交易失败)。
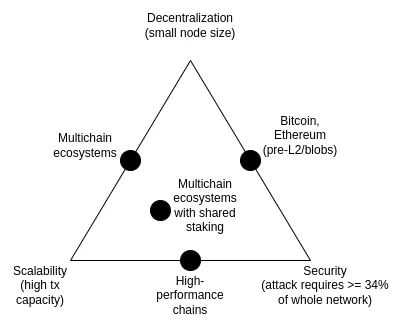
值得注意的是,三难困境并不是一个定理,介绍三难困境的文章也没有提供数学证明。它确实给出了一个启发式的数学论证:如果支持去中心化的节点(如消费级笔记本电脑)每秒可以验证 N 笔交易,且存在一条每秒处理 k*N 笔交易的链,那么要么 (i) 每笔交易仅被 1/k 的节点看到,这意味着攻击者只需要破坏几个节点就能推动恶意交易通过,要么 (ii) 节点非常强大,难以去中心化。本文并不是表明打破三难困境不可能;相反,本文旨在阐明为什么打破三难困境非常困难 —— 它需要以某种方式跳出论证所暗示的思维定式。
多年来,一些高性能链常常声称:不需要在基础架构层面精妙设计,使用软件工程技巧来优化节点就能解决三难困境。这样的言论具有误导性,在这样的链上运行节点比在以太坊中困难得多。这篇博文深入探讨了为什么会出现这种情况(以及为什么仅靠 L1 客户端软件工程无法扩展以太坊本身)。
然而,数据可用性采样(data availability sampling)和 SNARK 的结合确实解决了三难困境:它允许客户端验证一定数量的数据可用性,并且在只下载那部分数据的一小部分的情况下,用更少的计算量来验证是否正确执行了一些计算步骤。SNARK 是无需信任(trustless)的。数据可用性抽样有一个微妙的少数节点信任模型(few-of-N trust model),但它仍保留了不可扩展链所拥有的基本属性 —— 即使是 51% 攻击也无法强迫网络接受恶意区块。
解决三难困境的另一种方法是 Plasma 架构,它使用巧妙的技术以激励兼容的方式将监视数据可用性的责任推给用户。早在 2017-2019 年,对扩展计算这一目标,我们所能做只有欺诈证明(fraud proofs)时,Plasma 的安全功能非常有限。当 SNARK 成为主流,Plasma 架构的用例也变得比以前更加的广泛。
数据可用性采样(data availability sampling)取得进一步进展
我们要解决什么问题?
截至 2024 年 3 月 13 日,当 Dencun 升级上线时,以太坊区块链每 12 秒时隙(slot)有 3 个大约 125 kB 的 “blob”,或者说数据可用带宽为大约 375 kB 每时隙。假设交易数据直接在链上发布,一笔 ERC20 转账约为 180 字节,则以太坊上 rollups 的最大 TPS 为:
375000 / 12 / 180 = 173.6 TPS
如果加上以太坊的 calldata [理论最大值:每时隙 3000 万 gas / 每字节 16 gas = 每时隙 1,875,000 字节],这个数字就会变成 607 TPS。如果使用 PeerDAS,计划是将 blob 计数目标增加到 8-16,加上 calldata 后速度为 463-926 TPS 。
与以太坊 L1 相比,这已经是很大的提升。但这还远远不够,我们还想要更好的可扩展性。我们的中期目标是每时隙 16 MB,如果结合 rollup 数据压缩的改进, 速度将提升至 大约 58,000 TPS。
它是什么,如何做到的?
PeerDAS 是对 “一维采样(1D sampling)” 相对简单的实现。以太坊中的每个 blob 都是 253 位素数域上的 4096 阶多项式(degree-4096 polynomial over a 253-bit prime field)。我们广播多项式的 “份额(shares)”,每个份额由 16 个 evaluation 组成,位于相邻的、从 8192 个 坐标组中抽取的 16 个坐标。8192 个 evaluation 中的任意 4096 个(使用当前建议的参数:128 个可能样本中的任意 64 个)都可以恢复 blob。
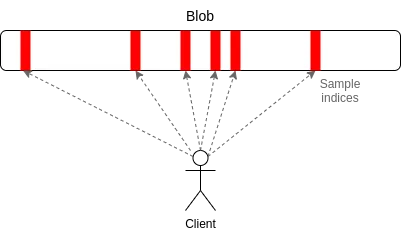
PeerDAS 的工作原理是:每个客户端仅监听少数子网,其中第 i 个子网负责广播 blob 的第 i 个样本;当客户端需要获取其他子网上的 blob 时,可以通过全球 p2p 网络向监听不同子网的节点发起请求。与 PeerDAS 相比之下,SubnetDAS 的方案更为保守,它仅保留了子网机制,去除了节点间相互询问的流程。根据当前提案,参与权益证明的节点将采用 SubnetDAS,而其他节点(即 “客户端”)则使用 PeerDAS。
理论上一维采样(1D sampling)的扩展空间相当大:如果我们将 blob 的最大数量提升至 256(相应的 target 为 128),就能达到 16MB 的 target 容量。在这样的情况下,每个节点进行数据可用性采样所需的带宽开销计算如下:
16 个样本 × 128 个 blob × 512 字节(每个 blob 的单个样本大小)= 1MB 带宽/时隙 ;
这个带宽要求刚好处于可接受范围的边缘:虽然技术上可行,但带宽受限的客户端将无法参与采样。我们可以通过减少 blob 数量并增加单个 blob 的大小来优化这一方案,但这类数据重构的方案成本更高。
为进一步提升性能可以采用二维采样(2D sampling)技术 —— 既在单个 blob 内部进行采样,又在不同 blob 之间进行采样,利用 KZG 承诺(KZG commitments)的线性特性来 “扩展” 区块中的 blob 集合,生成一系列新的 “虚拟 blob”,这些 “虚拟 blob” 通过冗余编码的方式存储相同的信息。
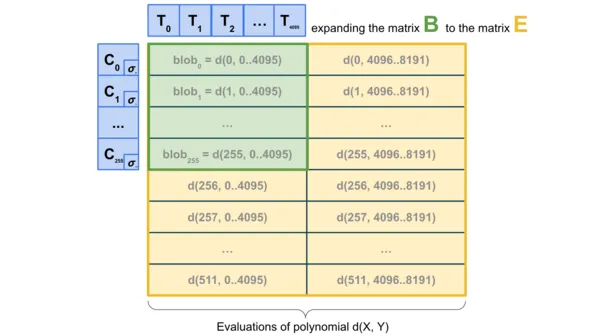
这个方案有一个重要特点:计算承诺的扩展过程无需获取完整的 blob 数据,这使得它天然适合分布式区块的构建。具体而言,负责构建区块的节点只需持有 blob 的 KZG 承诺,就能通过 DAS 系统验证这些 blob 的可用性。同样一维 DAS(1D DAS)也具备这类构建分布式区块的优势。
与现有研究有哪些联系?
- 介绍数据可用性的原始帖子(Original post introducing data availability)(2018 年):https://github.com/ethereum/research/wiki/A-note-on-data-availability-and-erasure-coding
- 后续论文(Follow-up paper):https://arxiv.org/abs/1809.09044
- 关于 DAS、Paradigm 的解释帖子(Explainer post on DAS, paradigm):https://www.paradigm.xyz/2022/08/das
- 具备 KZG 承诺的二维可用性(2D availability with KZG commitments):https://ethresear.ch/t/2d-data-availability-with-kate-commitments/8081
- ethresear.ch 上的 PeerDAS(PeerDAS on ethresear.ch):https://ethresear.ch/t/peerdas-a-simpler-das-approach-using-battle-tested-p2p-components/16541,以及论文:https://eprint.iacr.org/2024/1362
- Francesco 关于 PeerDAS 的演讲(Presentation on PeerDAS by Francesco):https://www.youtube.com/watch?v=WOdpO1tH_Us
- EIP-7594:https://eips.ethereum.org/EIPS/eip-7594
- ethresear.ch 上的 SubnetDAS:https://ethresear.ch/t/subnetdas-an-intermediate-das-approach/17169
- 二维采样中可恢复性的细微差别(Nuances of recoverability in 2D sampling):https://ethresear.ch/t/nuances-of-data-recoverability-in-data-availability-sampling/16256
还有什么要做,需要权衡什么?
当前的首要任务是完成 PeerDAS 的开发和部署工作。接下来就是循序渐进的推动 —— 通过持续监控网络状况和优化软件性能、确保系统安全的同时,稳步提升 PeerDAS 的 blob 处理容量。同时,我们需要推动更多学术研究,对 PeerDAS 及其他 DAS 变体的正式验证,并深入研究它们与分叉选择规则安全性等问题之间的相互作用。
在未来的工作中,我们需要进一步研究确定二维 DAS 的最优实现形式,并对其安全性进行严格证明。另一个长期目标是寻找 KZG 的替代方案,新方案需要同时具备抗量子特性和免信任设置(trusted-setup-free)的特点。然而,目前我们尚未找到任何适合分布式区块构建的候选方案。甚至连使用递归(recursive)STARK 来生成行与列、重建有效性证明这种计算成本高昂的 “暴力” 方法也不是很有效 —— 尽管从理论上看,采用 STIR 后 STARK 的大小仅需 O(log(n) * log(log(n)) 个哈希值,但实际应用中 STARK 的数据量仍然接近一个完整 blob 的大小。
从长远来看,我认为有以下几条可行的发展路径:
- 采用理想的二维 DAS 方案
- 继续采用一维 DAS 方案 —— 虽然会牺牲采样带宽效率,需要接受较低的数据容量上限,但能确保系统简单、稳定(robustness)
- (重大转向)完全放弃数据可用性采样(DA),转而将 Plasma 作为重点发展的 Layer 2 架构方案
我们可以从以下几个维度来权衡这些方案的利弊:
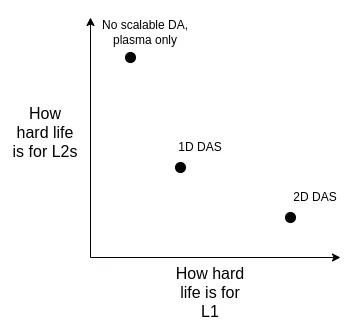
需要特别指出的是,即使我们决定直接在 L1 上进行扩容,这些技术选择的权衡问题仍然存在。这是因为:如果 L1 要支持高 TPS,区块大小会显著增加,在这种情况下,客户端节点就需要高效的验证机制来确保区块正确。这就意味着我们不得不在 L1 上应用那些原本用于 rollup 的底层技术(比如 ZK-EVM 和 DAS 等)。
它如何与路线图的其他部分互动?
数据压缩(data compression)(详见后文)的落地将显著降低或推迟对二维 DAS(2D DAS)的需求;如果广泛采用 Plasma,需求还将进一步下降。不过,DAS 也给分布式区块的构建带来了新的挑战:尽管从理论上看 DAS 有利于分布式重建,但在实际应用中,我们需要将其与纳入列表(inclusion list)提案以及相关的分叉选择机制进行无缝整合。
数据压缩(data compression)
我们要解决什么问题?
在 rollup 中,每笔交易都需要在链上占用可观的数据空间:一笔 ERC20 转账交易约需 180 字节。即便采用理想的数据可用性采样机制,这仍然会限制二层协议的可扩展性。按照每个时隙 16 MB 的数据容量计算,易得:16000000 / 12 / 180 = 7407 TPS
除了优化分子部分,如果我们还能处理分母问题 —— 即降低 rollup 中每笔交易在链上的字节占用量,会带来什么效果?
它是什么,如何做到的?
我认为最好的解释是两年前的这张图:
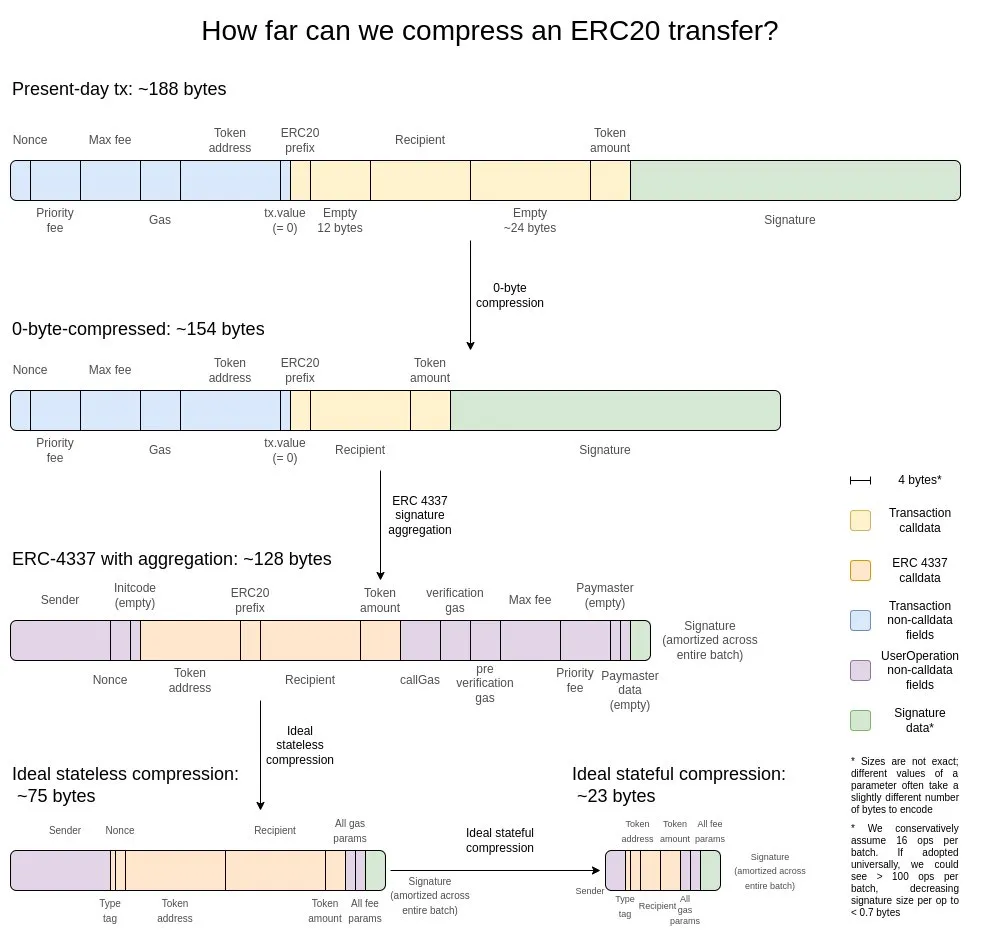
首先是最基础的优化手段 —— 零字节压缩:用两个字节来表示连续的零字节序列的长度,从而替代原始的零字节串。要实现更深层的优化,我们可以利用交易的以下特性:
- 签名聚合(signature aggregation)—— 将签名系统从 ECDSA 迁移至 BLS,后者能够将多个签名合并为单个签名,同时验证所有原始签名的有效性。虽然由于验证的计算开销较大(即便是在聚合场景下),这一方案并不适用于 L1,但在 L2 这样的数据受限环境中,其优势就显得非常明显。ERC-4337 的聚合特性为实现这一目标提供了可行的技术路径。
- 地址指针替换机制 —— 对于历史上出现过的地址,我们可以用 4 字节的指针(指向历史记录中的位置)来替代原本的 20 字节地址。这种优化能带来最大的收益,但实现起来相对复杂,因为它要求将区块链的历史记录(至少是部分历史)实质性地整合到状态集中。
- 交易金额的自定义序列化(serialization)方案 —— 大多数交易金额实际上只包含少量有效数字。例如,0.25 ETH 在系统中被表示为 250,000,000,000,000,000 wei。gas 的最大基础费率(max-basefee)和优先费率(priority fee)也具有类似特点。基于这一特性,我们可以采用自定义的十进制浮点格式,或建立常用数值字典,从而大幅压缩货币数值的存储空间。
与现有研究有哪些联系?
- 来自 sequence.xyz 的探索(Exploration from sequence.xyz):https://sequence.xyz/blog/compressing-calldata
- 来自 ScopeLift 的针对 L2s 的 Calldata 优化合约(Calldata-optimized contracts for L2s, from ScopeLift):https://github.com/ScopeLift/l2-optimizoooors
- 替代策略 - 基于有效性证明的 rollups(又名 ZK rollups)发布状态差异而不是交易(An alternative strategy - validity-proof-based rollups (aka ZK rollups) post state diffs instead of transactions):https://ethresear.ch/t/rollup-diff-compression-application-level-compression-strategies-to-reduce-the-l2-data-footprint-on-l1/9975
- BLS 钱包 —— 通过 ERC-4337 实现 BLS 聚合(BLS wallet - an implementation of BLS aggregation through ERC-4337):https://github.com/getwax/bls-wallet
还有什么要做,需要权衡什么?
目前的首要任务是将上述方案落地实施。这涉及以下几个关键的权衡:
- BLS 签名迁移 —— 转换至 BLS 签名体系需要投入大量工程资源,同时会降低与安全增强型可信硬件(TEE)的兼容性。对此,一个可行的替代方案是采用其他签名算法的 ZK-SNARK 封装。
- 动态压缩实现 —— 实施如地址指针替换等动态压缩机制会显著提高客户端代码的复杂度。
- 状态差异发布 —— 选择向链上发布状态差异而非完整交易会削弱系统的可审计性,同时导致区块浏览器等现有基础设施无法正常运行。
它如何与路线图中的其他部分互动?
通过引入 ERC-4337 并最终将其部分功能在 L2 EVM 中标准化化,将显著加速聚合技术的部署进程。同样,将 ERC-4337 的部分功能纳入 L1 也将促进其在 L2 生态中的快速落地。
通用 Plasma 架构
我们要解决什么问题?
即便结合了 16 MB blob 存储和数据压缩技术,58,000 TPS 的处理能力仍然不足以完全支撑消费支付、去中心化社交网络等高带宽场景。当我们考虑引入隐私保护机制时,这一问题会变得更加突出,因为隐私特性可能会使系统的可扩展性降低 3 至 8 倍。目前,对于高吞吐、低价值内容的应用场景,一个可选方案是 validium。它采用链下数据存储模式,并实现了一个独特的安全模型:运营商无法直接盗取用户资产,但他们可能通过失联来临时或永久性地冻结用户资金。不过,我们有机会构建更优的解决方案。
它是什么,如何做到的?
Plasma 是一种扩容解决方案,与 rollup 将完整区块数据上链不同,Plasma 的运营商在链下生成区块,仅将区块的 Merkle 根记录到链上。对于每个区块,运营商会向用户分发 Merkle 分支,用以证明与该用户资产相关的状态变更(或未发生的变更)。用户可以通过提供这些 Merkle 分支来提取其资产。一个关键特性是:这些 Merkle 分支不必指向最新状态 —— 这意味着即使在数据可用性出现故障的情况下,用户仍然可以通过提取其所掌握的最新可用状态来找回资产。如果有用户提交了无效的分支(比如尝试提取已转移给他人的资产,或运营商试图凭空创造资产),链上的挑战机制可以对资产所有权进行仲裁。
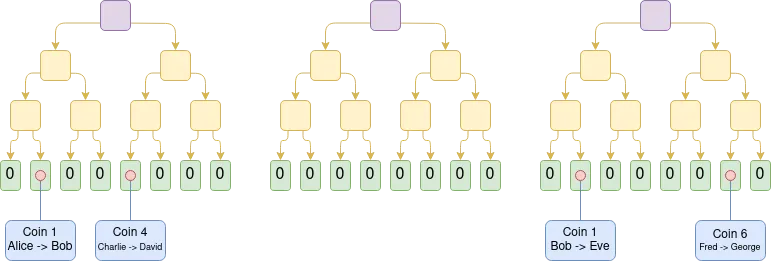
Plasma 的早期实现仅限于支付场景,难以实现更广泛的功能扩展。然而,如果我们引入 SNARK 来验证每个根节点,Plasma 的能力将得到显著提升。由于这种方式可以从根本上消除大部分运营商作弊的可能性,挑战机制可以大大简化。同时,这也为 Plasma 技术开辟了新的应用路径,使其能够扩展到更多样化的资产类型。更重要的是,在运营商诚实行为的情况下,用户可以即时提取资金,无需等待为期一周的挑战期。
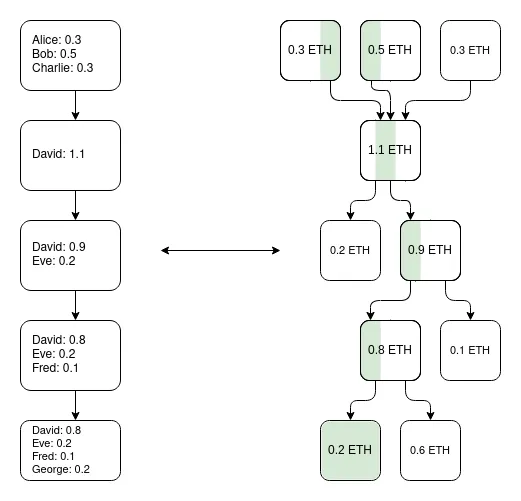
一个重要的洞见是:Plasma 系统无需追求完美。即便它只能保护部分资产(比如仅保护过去一周内未发生转移的代币),也已经大大改善了超可扩展(ultra-scalable)EVM 的现状,这是一个 validium。
另一种架构方案是 plasma/rollup 的混合模式,Intmax 就是典型代表。这类架构在链上仅存储极少量的用户数据(每个用户约 5 字节),从而在特性上达到了 plasma 和 rollup 的平衡点:以 Intmax 为例,它实现了极高的可扩展性和隐私性,但即便在 16 MB 数据容量的场景下,其理论吞吐量也被限制在约 266,667 TPS(计算方式:16,000,000/12/5)。
与现有研究有哪些联系?
- 原始 Plasma 论文(Original Plasma paper):https://plasma.io/plasma-deprecated.pdf
- Plasma 现金(Plasma Cash):https://ethresear.ch/t/plasma-cash-plasma-with-much-less-per-user-data-checking/1298
- Plasma 现金流(Plasma Cashflow):https://hackmd.io/DgzmJIRjSzCYvl4lUjZXNQ?view#🚪-Exit
- Intmax(2023 年):https://eprint.iacr.org/2023/1082
还有什么要做,需要权衡什么?
当前的核心任务是将 Plasma 系统推向生产环境。如前所述,Plasma 与 Validium 的关系并非非此即彼:任何 validium 都可以通过在其退出机制中整合 Plasma 特性来提升其安全属性,哪怕是细微的改进。研究重点包括:
- 为 EVM 寻找最优性能参数(从信任假设、L1 最坏情况 gas 开销和抗 DoS 能力等维度考量)
- 探索特定应用场景的替代性架构方案
同时,我们需要正面解决 Plasma 相比 rollup 在概念上更为复杂的问题,这需要通过理论研究与优化通用框架实现的双重路径来推进。
采用 Plasma 架构的主要权衡在于:它对运营商的依赖程度更高,且更难实现"基础化(based)"。尽管混合 plasma/rollup 架构通常可以规避这一劣势。
它如何与路线图的其他部分互动?
Plasma 解决方案的效用越高,对 L1 层提供高性能数据可用性的压力就越小。同时,将链上活动迁移至 L2 也能够降低 L1 层面的 MEV 压力。
成熟的 L2 证明(proof)系统
我们要解决什么问题?
目前,大多数 rollup 尚未实现真正的无信任机制 —— 它们都设有安全委员会,可以对(optimistic 或 validity)证明系统的行为进行干预。某些情况下,证明系统甚至完全缺失,或仅具有"建议性"功能。在这一领域最具进展的是:(i) 一些应用特定的 rollup(如 Fuel),它们已实现了无信任机制;(ii) 截至本文撰写时,两个完整的 EVM rollup —— Optimism 和 Arbitrum,已达到了称为"阶段一(stage 1)"的部分无信任里程碑。rollup 未能进一步发展的主要障碍是对代码漏洞的顾虑。要实现真正无信任的 rollup,我们必须正面应对这一挑战。
它是什么,如何做到的?
首先,我们来回顾之前这篇文章介绍的 “阶段(stage)” 系统。虽然完整要求更为详细,但主要内容概括如下:
- 阶段 0:用户必须能够独立运行节点并完成链同步。验证机制可以是完全中心化或基于信任的。
- 阶段 1:系统必须实现 (无信任 trustless)证明机制,确保仅有效交易能被接受。允许设立安全委员会对证明系统进行干预,但需达到 75% 的投票阈值。同时,超过 26% 的委员会成员必须来自主要开发公司以外。可以采用功能较弱的升级机制(例如 DAO),但必须设置足够长的时间锁,确保用户能在恶意升级生效前安全提取资金。
- 阶段 2:系统必须实现 (无信任 trustless)证明机制,确保仅有效交易能被接受。安全委员会只能在出现明确的代码缺陷时介入,比如:两套证明系统产生冲突,或单个证明系统对同一区块生成了不同的后状态根(或在较长时间内,如一周,没有生成任何结果)。允许设置升级机制,但必须采用极长的时间锁。
我们的最终目标是达到阶段二。迈向第二阶段的关键挑战是:确保人们对证明系统有足够的信任,并认为它足够可信。目前有两种主要的实现路径:
- 形式化验证:我们可以借助现代数学和计算机科学技术,来证明(optimistic 或 validity)证明系统只会接受符合 EVM 规范的区块。虽然这类技术已有数十年历史,但近期的技术突破(如 Lean 4)大大提升了其实用性,而 AI 辅助证明的发展有望进一步加快这一进程。
- 多重证明机制:构建多个证明系统,并将资金存入由这些系统和安全委员会(以及/或其他基于信任假设的组件,如 TEE)共同控制的 2/3 多签(或更高阈值)合约中。当各证明系统达成一致时,安全委员会不具有决策权;当系统之间存在分歧时,安全委员会只能在现有结果中选择其一,而不能强制推行自己的方案。
与现有研究有哪些联系?
- EVM K Semantics(2017 年开始的形式化验证工作):https://github.com/runtimeverification/evm-semantics
- 关于多重证明器理念的演示(2022 年)(Presentation on the idea of multi-provers):https://www.youtube.com/watch?v=6hfVzCWT6YI
- Taiko 计划使用多重证明(Taiko plans to use multi-proofs):https://docs.taiko.xyz/core-concepts/multi-proofs/
还有什么要做,需要权衡什么?
在形式化验证方面,还有大量工作要做。我们需要为 EVM 的完整 SNARK 证明器开发一个经过形式化验证的版本。这是一个极其复杂的项目,虽然我们已经着手进行。不过,有一个技术方案可以显著降低复杂度:我们可以先为最小化虚拟机(如 RISC-V 或 Cairo)构建一个经过形式化验证的 SNARK 证明器,然后在这个最小化虚拟机上实现 EVM(同时形式化证明其与其他 EVM 规范的等价性)。
关于多重证明机制,还有两个核心问题需要解决:首先,我们需要建立对至少两个不同证明系统的充分信心。这要求这些系统不仅各自都具备足够的安全性,而且即使发生故障,也会因不同且无关的原因而失效(这样就不会出现同时崩溃的情况)。其次,我们需要对合并这些证明系统的底层逻辑建立极高的可信度。这部分代码量相对较小。虽然有方法可以将其进一步简化 —— 比如将资金存入一个 Safe 多签合约,由代表各证明系统的合约作为签名方 —— 但这种方案会带来较高的链上 gas 开销。因此我们需要在效率和安全性之间寻找适当的平衡点。
它与路线图的其他部分如何互动?
将链上活动迁移至 L2 能够缓解 L1 的 MEV 压力。
跨 L2 互操作性改进
我们要解决什么问题?
当前 L2 生态系统面临的一个主要挑战是用户难以在不同 L2 间无缝切换。更糟糕的是,那些看似便捷的解决方案往往会重新引入信任依赖 —— 比如中心化跨链桥、RPC 客户端等。如果我们真正希望将 L2 作为以太坊生态的有机组成部分,就必须确保用户在使用 L2 生态时能够获得与以太坊主网一致的统一体验。
它是什么,如何做到的?
跨 L2 互操作性的改进涉及多个维度。从理论上看,以 rollup 为中心的以太坊架构本质上等同于 L1 的执行分片(sharding)。因此,我们可以通过对比这一理想模型,来发现当前以太坊 L2 生态在实践中存在的差距。以下是几个主要方面:
- 链特定地址:链标识(如 L1、Optimism、Arbitrum 等)应该成为地址的组成部分。实现后,跨层转账流程将变得简单:用户只需在"发送"栏输入地址,钱包就能自动处理后续操作(包括调用跨链桥协议)。
- 链特定支付请求:应建立标准化机制,简化"在链 Z 上发送 X 数量的 Y 类型代币给我"这类请求的处理。主要应用场景包括:
- 支付场景:包括个人间转账和商户支付
- DApp 资金请求:如上述 Polymarket 的例子
- 跨链兑换与 gas 支付:需要建立标准化的开放协议来处理跨链操作,例如:
- "我将在 Optimism 上支付 1 ETH,以换取他人在 Arbitrum 上支付给我的 0.9999 ETH"
- "我将在 Optimism 上支付 0.0001 ETH,给任何愿意在 Arbitrum 上打包此交易的人"
- 轻客户端:用户应该能够直接验证所交互的链,而不是完全依赖 RPC 服务提供商。A16z crypto 开发的 Helios 已经在以太坊主网实现了这一功能,现在我们需要将这种去信任特性扩展到 L2 网络。ERC-3668(CCIP-read)提供了一种可行的实现方案。
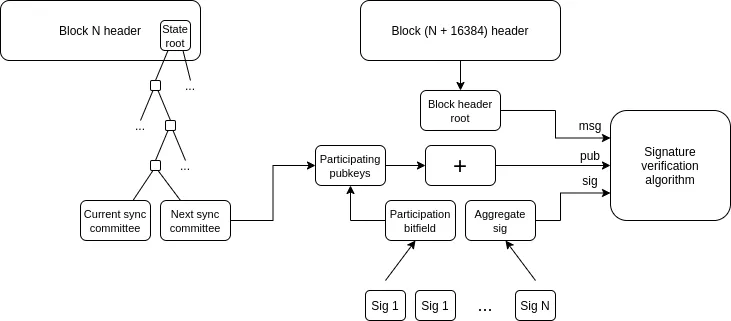
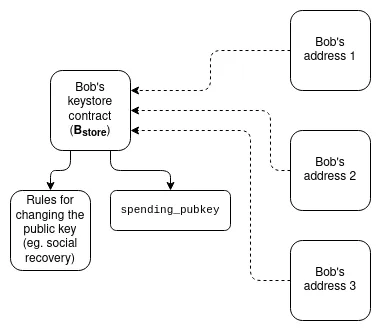
密钥库钱包:目前,如果您希望更新控制智能合约钱包的密钥,必须在该钱包存在的所有 N 条链上进行更新。密钥库钱包是一种技术,允许密钥仅存在于一个地方(要么在 L1 上,或者将来可能在 L2 上),然后从任何拥有钱包副本的 L2 读取。这意味着更新只需进行一次。为了提高效率,密钥库钱包需要 L2 提供一种标准化的方式来无成本地读取 L1;为此,有两个提案是 L1SLOAD 和 REMOTESTATICCALL。
- 更激进的 “共享代币桥” 理念:想象一个世界,所有的 L2 都是有效性证明的 rollup,每个时隙都提交到以太坊。即使在这种情况下,想要在 L2 之间 “原生地” 移动资产,仍然需要提现和存款,这需要支付大量的 L1 gas 费用。解决这个问题的一种方法是创建一个共享的最小化 rollup,其唯一功能是维护每个 L2 拥有的各种类型代币的余额,并允许这些余额通过任何 L2 发起的一系列跨 L2 发送操作进行整体更新。这将使跨 L2 转账能够发生,而无需为每次转账支付 L1 的 gas 费用,也不需要像 ERC-7683 这样的基于流动性提供者的技术。
- 同步可组合性(synchronous composability):允许在特定的 L2 和 L1 之间,或多个 L2 之间进行同步调用。这可能有助于提高 DeFi 协议的金融效率。前者可以在无需任何跨 L2 协调的情况下完成;后者则需要使用共享排序。based rollup 对所有这些技术都天然友好。
与现有研究有哪些联系?
- 链特定地址:ERC-3770(Chain-specific addresses: ERC-3770):https://eips.ethereum.org/EIPS/eip-3770
- ERC-7683:https://eips.ethereum.org/EIPS/eip-7683
- RIP-7755:https://github.com/wilsoncusack/RIPs/blob/cross-l2-call-standard/RIPS/rip-7755.md
- Scroll 密钥库钱包设计(Scroll keystore wallet design):https://hackmd.io/@haichen/keystore
- Helios:https://github.com/a16z/helios
- ERC-3668(有时称为 CCIP-read):https://eips.ethereum.org/EIPS/eip-3668
- Justin Drake 提出的 “Based(共享)预确认” 提案(Proposal for "based (shared) preconfirmations" by Justin Drake):https://ethresear.ch/t/based-preconfirmations/17353
- L1SLOAD (RIP-7728):https://ethereum-magicians.org/t/rip-7728-l1sload-precompile/20388
- Optimism 中的 REMOTESTATICCALL(REMOTESTATICCALL in Optimism):https://github.com/ethereum-optimism/ecosystem-contributions/issues/76
- AggLayer,包括共享代币桥接理念(AggLayer, which includes shared token bridge ideas):https://github.com/AggLayer
还有什么要做,需要权衡什么?
上述许多示例都面临着标准化的常见困境:何时标准化,以及在哪些层面进行标准化。如果过早标准化,可能会使劣质的解决方案根深蒂固;如果过晚标准化,则可能导致不必要的分裂。在某些情况下,既存在性能较弱但易于实施的短期解决方案,也存在需要相当长时间才能实现但 “最终正确” 的长期解决方案。
这部分的的独特之处在于,这些任务不仅是技术问题,甚至可能主要是社会问题。它们需要 L2、钱包和 L1 的合作。我们成功处理这一问题的能力,是对我们作为一个社区团结一致能力的考验。
它与路线图的其他部分如何互动?
这些提案大部分都是 “高层” 结构,因此对 L1 层面的考虑影响不大。唯一的例外是共享排序,它对 MEV 有着重大影响。
在 L1 上扩展执行
我们要解决什么问题?
如果 L2 变得非常可扩展且成功,但 L1 仍然只能处理极少量的交易,那么以太坊可能会面临许多风险:
- ETH 资产的经济状况会变得更具风险性,进而影响网络的长期安全。
- 许多 L2 受益于与 L1 上高度发达的金融生态系统的紧密联系,如果这个生态系统大幅削弱,成为 L2(而非独立的 L1)的动机也会减弱。
- L2 要达到与 L1 完全相同的安全保证还需要很长时间。
- 如果一个 L2 发生故障(例如,由于恶意行为或运营者消失),用户仍需要通过 L1 来恢复他们的资产。因此,L1 需要足够强大,至少能够偶尔实际处理 L2 的高度复杂和混乱的关闭过程。
出于这些原因,继续扩展 L1 本身,并确保其能够继续满足日益增长的使用需求,是非常有价值的。
它是什么?它是如何工作的?
最简单的扩容方式就是直接增加 gas 上限。然而,这可能导致 L1 的中心化,从而削弱以太坊 L1 作为强大基础层的另一个重要特性:其可信度。关于简单增加 gas 上限的可持续程度,一直存在争议,而且这也取决于为了让更大区块更易于验证,将实施哪些其他技术(例如历史数据过期、无状态化、L1 EVM 有效性证明)。另一个需要持续改进的重要方面是以太坊客户端软件的效率,如今的客户端比五年前已优化了许多。一个有效的 L1 gas 上限增加策略将涉及加速这些验证技术的推进。
另一种扩展策略涉及确定可以降低成本且不会损害网络去中心化或其安全属性的特定功能和计算类型。这方面的例子包括:
- EOF:一种新的 EVM 字节码格式,更有利于静态分析,允许更快速的实现。考虑到这些效率,EOF 字节码可以被赋予更低的 gas 成本。
- 多维(multidimensional)gas 定价:为计算、数据和存储分别建立基础费用和限制,可以在不增加以太坊 L1 最大容量(从而避免新的安全风险)的情况下,提高其最大容量。
- 降低特定操作码和预编译的 gas 成本:历史上,为了避免拒绝服务攻击,我们曾提高了好几轮某些定价过低操作的 gas 成本。我们较少做的、但可以大力推进的,是降低那些定价过高操作的 gas 成本。例如,加法比乘法便宜得多,但目前 ADD 和 MUL 操作码的成本是相同的。我们可以使 ADD 更便宜,甚至像 PUSH 这样更简单的操作码也可以更便宜。
- EVM-MAX 和 SIMD:EVM-MAX(“模算术扩展”)是一个提案,允许在 EVM 的一个独立模块中更高效地进行原生大数模运算。EVM-MAX 计算出的值只可被其他 EVM-MAX 操作码访问,除非被有意导出;这允许以优化的格式存储这些值,提供更大的空间。SIMD(“单指令多数据”)是一个提案,允许在一组值上高效地执行相同的指令。两者结合可以在 EVM 旁创建一个强大的协处理器,可用于更高效地实现加密操作。这对于隐私协议和 L2 证明系统尤其有用,因此有助于 L1 和 L2 的扩容。
这些改进将在未来的 Splurge 博文中更详细地讨论。
最后,第三种策略是原生 rollup(或 “内置 rollup” 英文原文:“enshrined rollups”):本质上,创建多个并行运行的 EVM 副本,形成一个与 rollup 所能提供的功能等价的模型,但更原生地集成到协议中。
与现有研究有哪些联系?
- Polynya 的以太坊 L1 扩展路线图(Polynya's Ethereum L1 scaling roadmap):https://polynya.mirror.xyz/epju72rsymfB-JK52_uYI7HuhJ-W_zM735NdP7alkAQ
- 多维 gas 定价(Multidimensional gas pricing):https://vitalik.eth.limo/general/2024/05/09/multidim.html
- EIP-7706:https://eips.ethereum.org/EIPS/eip-7706
- EOF:https://evmobjectformat.org/
- EVM-MAX:https://ethereum-magicians.org/t/eip-6601-evm-modular-arithmetic-extensions-evmmax/13168
- SIMD:https://eips.ethereum.org/EIPS/eip-616
- 原生 rollups:https://mirror.xyz/ohotties.eth/P1qSCcwj2FZ9cqo3_6kYI4S2chW5K5tmEgogk6io1GE
- 采访 Max Resnick 谈论扩展 L1 的价值(Interview with Max Resnick on the value of scaling L1):https://x.com/BanklessHQ/status/1831319419739361321
- Justin Drake 谈论使用 SNARK 和原生 rollups 进行扩展(Justin Drake on the use of SNARKs and native rollups for scaling):https://www.reddit.com/r/ethereum/comments/1f81ntr/comment/llmfi28/
还有什么要做,需要权衡什么?
L1 扩容有三种策略,可以单独或并行推进:
- 改进技术(例如客户端代码、无状态客户端、历史数据过期)以使 L1 更易于验证,然后提高 gas 上限。
- 降低特定操作的成本,在不增加最坏情况风险的情况下提高平均容量。
- 原生 rollup(即 “创建 N 个并行运行的 EVM 副本”,同时可能在部署的副本参数上为开发者提供很大的灵活性)。
需要理解的是,这些是不同的技术,有着各自的权衡取舍。例如,原生 Rollup 在可组合性方面与常规 rollup 有许多相同的弱点:您无法像在同一个 L1(或 L2)上的合约那样,发送一个单一交易在多个 rollup 上同步执行操作。提高 gas 上限,会削弱通过使 L1 更易于验证所能获得的其他好处,例如增加运行验证节点的用户比例和提高独立质押者的数量。根据具体实现方式,降低 EVM 中特定操作的成本可能会增加 EVM 的整体复杂性。
任何 L1 扩容路线图需要回答的一个重要问题是:究竟什么应该属于 L1,什么应该属于 L2?显然,让所有内容都运行在 L1 上是不现实的:潜在的用例可能需要每秒处理数十万笔交易,这将使 L1 完全无法验证(除非我们采用原生 rollup 路线)。但我们确实需要一些指导原则,以确保我们不会陷入这样的局面:将 gas 上限提高 10 倍,严重损害以太坊 L1 的去中心化,结果却只是将 99% 的活动在 L2 上降低到 90%,因此整体结果几乎没有变化,但却不可逆转地失去了以太坊 L1 的许多独特价值。
它与路线图的其他部分如何互动?
将更多用户引入 L1 意味着不仅要提高可拓展性,还需要改进 L1 的其他方面。这意味着更多的 MEV 将留在 L1(而不是仅仅成为 L2 的问题),因此需要更紧迫地明确处理它。这也极大地提高了在 L1 上实现缩短时隙消耗时间的价值。此外,这在很大程度上取决于 L1 的验证(即 “Verge” 阶段)的顺利推进。
免责声明:作为区块链信息平台,本站所发布文章仅代表作者及嘉宾个人观点,与 Web3Caff 立场无关。文章内的信息仅供参考,均不构成任何投资建议及要约,并请您遵守所在国家或地区的相关法律法规。
欢迎加入 Web3Caff 官方社群:X(Twitter)账号丨微信读者群丨微信公众号丨Telegram订阅群丨Telegram交流群





