

以太坊中更快的区块/blob 传播
感谢@n1shantd 、 @ppopth和 Ben Berger 对本文的讨论和反馈,以及@dankrad的许多有益讨论。
抽象的
我们建议通过使用随机线性网络编码来改变我们在 P2P 网络中广播和传输块和 blob 的方式。我们表明,理论上我们可以分发块,占用当前 gossipsub 实现所需时间的 5% 带宽和 57% 的网络跳数(因此每条消息的延迟为一半)。我们为计算开销提供了具体的基准。
介绍
当前用于分发区块的gossipsub机制大致如下。提议者从其所有对等体中挑选一个D=8对等体的随机子集(称为其网格),并将其区块广播给它们。每个接收区块的对等体都会执行一些非常快速的初步验证:主要是签名验证,但最重要的是不包括状态转换或交易执行。经过这种快速验证后,对等体将其区块重新广播给另外D对等体。这种设计有两个直接后果:
- 每次跳跃至少会增加以下延迟:从一个对等点到下一个对等点的一个完整块传输(包括网络 ping 延迟,本质上与带宽无关,加上受带宽限制的完整块传输)。
- 对等方不必要地向已经收到完整块的其他对等方广播完整块。
我们建议在广播级别使用随机线性网络编码(RLNC)。通过这种编码,提议者会将区块分成N块(例如,对于以下所有模拟, N=10 ),而不是将完整区块发送给约 8 个对等方,而是将单个块发送给约 40 个对等方(不是原始块之一,而是它们的随机线性组合,请参阅下文的隐私考虑)。对等方仍然需要下载完整区块,或者更确切地说是N块,但它们可以从不同的对等方并行获取它们。在收到这N块(每个块都是组成原始区块的原始块的随机线性组合)后,对等方需要求解线性方程组来恢复完整区块。
概念验证实施突出了以下数字
- 提议一个区块需要额外的 26 毫秒,该时间受 CPU 限制,在现代笔记本电脑(Apple M4 Pro)上可以完全并行化到不到 2 毫秒
- 验证每个块需要 2.6 毫秒。
- 解码整个块需要 1.4ms。
- 使用
10块且D=40,每个节点发送的数据比当前的 gossipsub 要少一半,并且网络可以在一半的时间内广播 100KB 的块,并且块大小越大,收益就越大。
协议
有关网络编码的深入介绍,我们请读者参阅 loc. cit. 和这本教科书。我们在此提到了上述概念验证基准的最低限度的实现细节。在块传播(~110KB)的情况下,延迟或网络跳数决定了传播时间,而在完整 DAS 中的 blob 等大型消息的情况下,带宽决定了传播时间。
我们考虑一个具有素数特征的有限域\mathbb{F}_p F p 。在上面的例子中,我们选择了curve25519-dalek rust crate 实现的 Ristretto 标量基域。提议者采用一个块(一个不透明的字节切片),并将其解释为\mathbb{F}_p F p中元素的向量。在撰写本文时,一个典型的以太坊块约为B = 110KB B = 110 K B ,假设每个 Ristretto 标量需要少于 32 个字节来编码,一个块需要大约B/32 = 3520 B / 32 = 3520个\mathbb{F}_p F p元素。将其分成N=10块,每个块可视为\mathbb{F}_p^{M} F M p中的一个向量,其中M \sim 352 M ∼ 352 。因此,该块可视为N N 个向量v_i \in \mathbb{F}^M_p v i ∈ F M p , i=1,...,N i = 1 , . . . , N 。提议者随机选择D\sim 40 D ∼ 40 个对等体的子集。对于每个这样的对等体,它将发送一个\mathbb{F}_p^M F M p向量以及一些额外信息,以验证消息并防止网络上的 DOS。我们解释提议者
提议者
我们将使用 Pedersen 承诺来实现上述 rust crate 实现的 Ristretto 椭圆曲线E E 。我们假设我们已经随机选择了足够多元素的可信设置G_j \in E G j ∈ E , j = 1, ..., K j = 1 , . . . , K ,其中K \gg M K ≫ M 。我们为 \mathbb { F } _p ^ M F M p选择一个标准基础\{e_j\}_{j=1}^M { e j } M j = 1 。因此,每个向量v_i v i都可以唯一地写成
$$ v_i = \sum_{j=1}^M a_{ij} e_j, $$
对于某些标量a_{ij} \in \mathbb{F}_p a i j ∈ F p 。对于每个向量v_i v i ,我们都有一个 Pedersen 承诺
$$ C_i = \sum_{j=1}^M a_{ij}G_j \in E. $$
最后,对于大小为D \sim 40 D ∼ 40 的子集中的每个对等体,提议者均匀随机地选择一组标量b_i b i , i=1, ...,N i = 1 , . . . , N ,并将以下信息发送给对等体
- 向量v = \sum_{i=1}^N b_i v_i \in \mathbb{F}_p^M v = ∑ N i = 1 b i v i ∈ F M p 。其大小为32M 32 M字节,是消息的内容。
- N N 个承诺C_i C i , i=1,...,N i = 1 , ... , N 。这是32N 32 N个字节。
- N N个系数b_i b i , i=1, ...,N i = 1 , . . . , N 。这是32N 32 N个字节。
- 对N N 个承诺的哈希值进行 BLS 签名C_1 || C_2 || ... || C_N C 1 | | C 2 | | . . . | | C N ,这是96 96 个字节。
签名消息是上述 1-4 项元素的集合。我们看到每条消息中都有64N \sim 640 64 N ∼ 640 个额外字节作为 sidecar 发送。
接收对等体
当对等方收到上一节中的消息时,验证过程如下
- 它验证签名对于提议者和接收承诺的哈希值是否有效。
- 它写入接收向量v = \sum_{j=1}^M a_j e_j v = ∑ M j = 1 a j e j然后计算 Pedersen 承诺C = \sum_{j=1}^M a_j G_j C = ∑ M j = 1 a j G j 。
- 收到的系数b_i b i声明v = \sum_{i=1}^N b_i v_i v = ∑ N i = 1 b i v i 。对等方计算C'= \sum_{i=1}^N b_i C_i C ′ = ∑ N i = 1 b i C i ,然后验证C = C' C = C ′ 。
对等方会跟踪它们已收到的消息,假设它们是向量w_i w i , i = 1,...,L i = 1 , . . . , L (其中L < N L < N ) 。它们生成一个子空间W \subset \mathbb{F}_p^M W ⊂ F M p 。当它们收到v v时,它们首先检查该向量是否在W W中。如果是,则它们将其丢弃,因为该向量已经是前几个向量的线性组合。该协议的关键在于这种情况不太可能发生(对于上述数字,发生这种情况的概率远小于2^{-256} 2 − 256 )。作为此的推论,当节点已收到N N 条消息时,它就知道可以从消息w_i w i , i=1,...,N i = 1 , . . .中恢复原始v_i v i ,从而恢复块。 , N .
还要注意,只需要一次签名验证,所有传入消息都具有相同的承诺C_i C i和同一组承诺上的相同签名,因此对等方可以缓存第一次有效验证的结果。
发送对等体
对等节点在收到一个块后,可以立即将块发送给其他对等节点。假设一个节点持有w_i w i , i=1,...,L i = 1 , . . . , L ,其中L \leq N L ≤ N ,如上一节所述。节点还会跟踪它们收到的标量系数,因此它们知道它们持有的块满足
$$ w_i = \sum_{j=1}^N b_{ij} v_j \quad \forall i,$$
对于某些标量b_{ij} \in \mathbb{F}_p b i j ∈ F p,它们保存在内部状态中。最后,节点还保留完整的承诺C_i C i和提议者的签名,这些签名是在它们验证收到的第一个块时验证的。
节点发送消息的流程如下。
- 它们随机选择L L 个标量\alpha_i \in \mathbb{F}_p α i ∈ F p , i=1,...,L i = 1 , . . . , L 。
- 它们形成块w = \sum_{i=1}^L \alpha_i w_i w = ∑ L i = 1 α i w i 。
- 它们形成N N 个标量a_j a j , i=1,...,N i = 1 , . . . , N ,其公式为
$$ a_j = \sum_{i=1}^L \alpha_i b_{ij}, \quad \forall j=1,…,N. $$
他们发送的消息由块w w 、系数a_j a j和带有提议者签名的承诺C_i C i组成。
基准
该协议有一些与 gossipsub 相同的组件,例如提议者需要制作一个 BLS 签名,验证者必须检查一个 BLS 签名。我们在此记录了除通常的 gossipsub 操作之外需要执行的操作的基准。这些是协议对节点的 CPU开销。基准测试已在 Macbook M4 Pro 笔记本电脑和 Intel i7-8550U CPU @ 1.80GHz 上进行。
这些基准测试的参数为N=10 (块数为N = 10) ,总块大小为 118.75KB。所有基准测试都是单线程的,都可以并行化
提议者
提议者需要履行N N Pedersen 承诺。这被基准化为
| 定时 | 模型 |
|---|---|
| [25.588 毫秒 25.646 毫秒 25.715 毫秒] | 苹果 |
| [46.7毫秒 47.640毫秒 48.667毫秒] | 英特尔 |
节点
接收节点需要计算每个块的 1 个 Pedersen 承诺,并执行提议者提供的承诺的相应线性组合。这些操作的时间如下
| 定时 | 模型 |
|---|---|
| [2.6817 毫秒 2.6983 毫秒 2.7193 毫秒] | 苹果 |
| [4.9479 毫秒 5.1023 毫秒 5.2832 毫秒] | 英特尔 |
发送新块时,节点需要对现有块进行线性组合。这些操作的时间如下
| 定时 | 模型 |
|---|---|
| [246.67 微秒 247.85 微秒 249.46 微秒] | 苹果 |
| [616.97 微秒 627.94 微秒 640.59 微秒] | 英特尔 |
在接收N 个区块后解码整个区块时,节点需要求解线性方程组。时间如下
| 定时 | 模型 |
|---|---|
| [2.5280 毫秒 2.5328 毫秒 2.5382 毫秒] | 苹果 |
| [5.1208 毫秒 5.1421 毫秒 5.1705 毫秒] | 英特尔 |
总体 CPU 开销。
Apple M4 上提议者的总开销为 26ms(单线程),而接收节点的总开销为 29.6ms(单线程)。这两个过程都是完全可并行的。对于提议者来说,它可以并行计算每个承诺,而对于接收节点来说,这些自然是并行事件,因为该节点正在从不同的对等节点并行接收块。在 Apple M4 上并行运行这些过程会导致提议者端为 2.6ms,接收对等节点为 2.7ms。对于实际应用来说,与所涉及的网络延迟相比,将这些开销视为零是合理的。
优化
一些未实施的过早优化包括在块到来时反转线性系统,尽管上面引用的概念证明确实将传入的系数矩阵保持在 Eschelon 形式。最重要的是,消息的随机系数不需要在像 Ristretto 场这样大的场中。像\mathbb{F}_{257} F 257这样的小素数场就足够了。然而,由于 Pedersen 承诺发生在 Ristretto 曲线中,我们被迫在更大的域中执行标量运算。这些基准的实现为线性组合选择了较小的系数,并且这些系数在每次跳跃中都会增长。通过正确控制和选择随机系数,我们可能能够将线性系统的系数(以及发送块的带宽开销)限制为 4 个字节而不是 32 个字节进行编码。
执行此类优化的最简单方法是对定义在\mathbb{F}_q F q上的椭圆曲线进行操作,其中q = p^r q = p r是某个小素数p p 。这样就可以在子域\mathbb{F}_p \subset \mathbb{F}_q F p ⊂ F q上选择系数。
隐私考虑上面链接的 PoC 中的实现认为每个节点(包括提议者)都会选择较小的系数来合成其线性变换。这允许接收具有较小系数的块的对等方识别该块的提议者。要么采用上述优化,通过执行类似 Bareiss 扩展的算法来保持所有系数较小,要么我们应该允许提议者从字段\mathbb{F}_p F p中选择随机系数。
模拟
我们在以下一些简化的假设下对块传播进行了模拟。
- 我们选择一个随机网络,将其建模为有向图,其中有 10000 个节点,每个节点有D D个对等点可以向其发送消息。D D在本文中称为网格大小,其范围从 3 到 80,变化范围很大。
- 在完整节点集上随机且统一地选择对等点。
- 每个连接都选择相同的带宽X X MBps(在以太坊中通常假设为X=20 ,但我们可以将此数字保留为参数)
- 每次网络跳跃都会产生额外的恒定延迟L L毫秒(通常以L=70 L = 70来衡量,但我们可以将此数字保留为参数)
- 假设该消息大小总计为B B KB。
- 对于使用 RLNC 的模拟,我们使用N= 10个块来划分块。
- 每次一个节点向另一个节点发送消息,而该节点由于冗余而丢弃该消息(例如,该节点已经有完整的块),我们将该消息的大小记录为浪费的带宽。
八卦子
我们使用了D= 6个节点来发送消息。我们得到网络平均需要 7 跳才能将整个区块传播到 99% 的网络,总传播时间为
$$ T_{\mathrm{gossipsub, D=6}} = 7 \cdot (L + B/X), $$
以毫秒为单位。
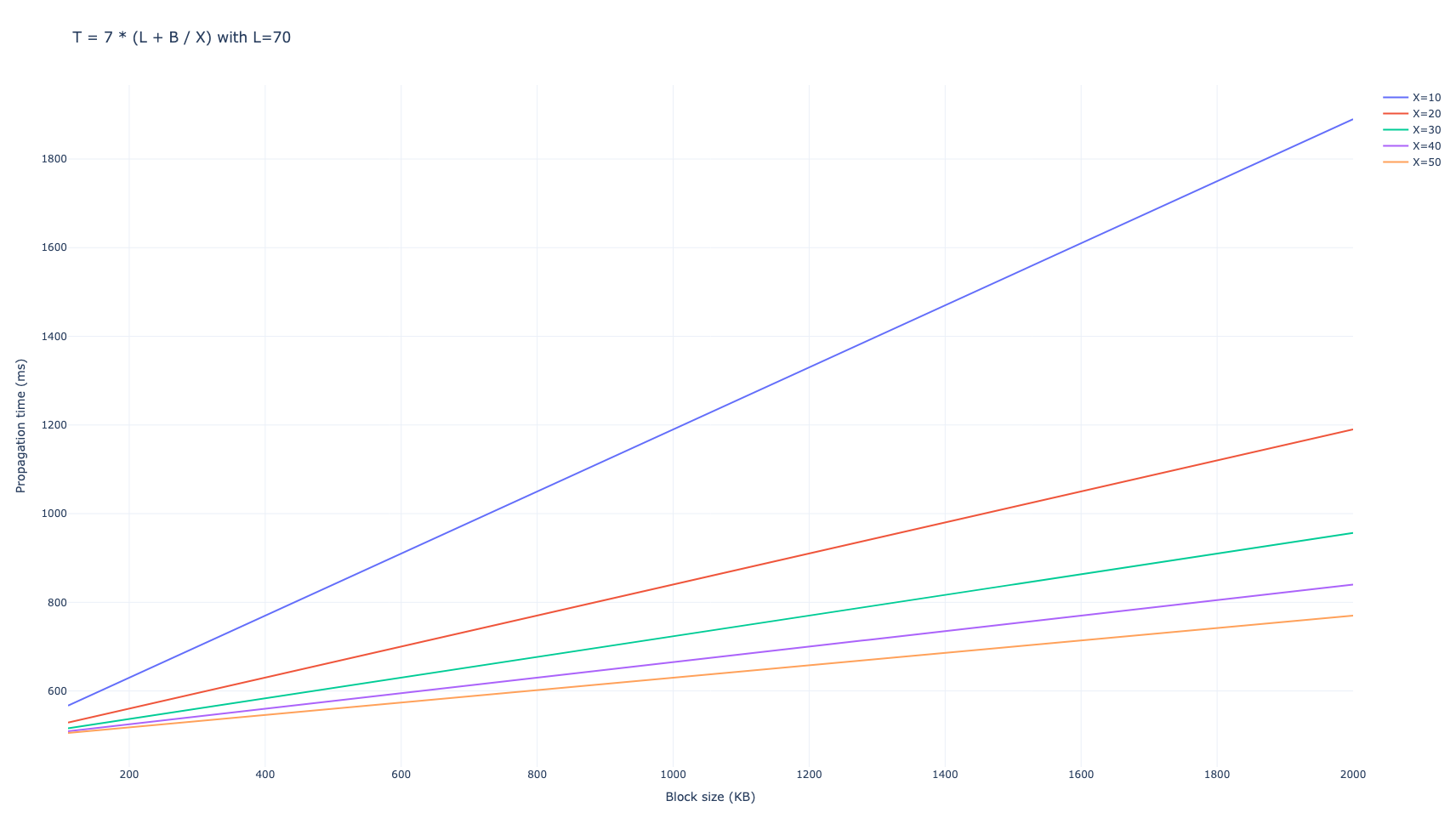
当D=8 时,结果类似
$$ T_{\mathrm{gossipsub, D=8}} = 6 \cdot (L + B/X), $$
当D=6 D = 6时,浪费的带宽为94,060 \cdot B 94 , 060 ⋅ B ;当D=8 D = 8 时,浪费的带宽为100,297 \cdot B 100 , 297 ⋅ B。
对于较低的B B值,比如当前的以太坊区块,延迟决定了传播;而对于较大的值,例如在对等 DAS 之后传播 blob,带宽成为主要因素。
远程控制网络中心
每个对等体单个块
通过随机线性网络编码,我们可以使用不同的策略。我们模拟了一个系统,其中每个节点只会向其大小为D的网格中的所有对等点发送单个块,这样我们就可以保证产生的延迟与 gossipsub 中的相同:每跳的单次延迟成本为L L毫秒。这要求网格大小远远大于块数N N 。请注意,对于大小为D_{gossipsub} D g o s s i p s u b的 gossipsub 网格(例如当前以太坊中的8 8 ),我们需要设置D_{RLNC} = D_{gossipsub} \cdot N D R L N C = D g o s s i p s u b ⋅ N以消耗每个节点相同的带宽,根据当前值,这将是80 80 。
采用更保守的带宽一半的值,即D=40 D = 40,我们得到
$$T_{RLNC, D=40} = 4 \cdot \left(L + \frac{B}{10 X} \right), $$
浪费的带宽为29,917\cdot B 29 , 917 ⋅ B 。假设带宽与今天相同,我们通过D=80获得D = 80,我们得到了令人印象深刻的
$$T_{RLNC, D=80} = 3 \cdot \left(L + \frac{B}{10 X} \right), $$
浪费的带宽为28,124\cdot B 28 , 124 ⋅ B ,相当于 gossipsub 中相应浪费带宽的 28%。
差异
对于每个节点发送的相同带宽,我们发现传播时间不同,一方面是因为延迟减半(有 3 个跳数 vs. 6 个跳数),另一方面是因为块传播速度更快,每单位时间消耗的带宽是原来的十分之一。此外,多余消息浪费的带宽被削减到 gossipsub 浪费消息的 28%。传播时间和浪费的带宽也得到了类似的结果,但每个节点发送的带宽减少了一半。
在较低的块大小端,延迟占主导地位,gossipsub 上的 3 跳与 6 跳是主要区别,而在较高的块大小端,带宽性能占主导地位。对于更大的块大小,RLNC 中的 CPU 开销会变得更糟,但考虑到传输时间的数量级,这些可以忽略不计。

每个对等体有多个块
在生产中的每个对等点单块方法中,具有更高带宽的节点可以选择向更多对等点广播。在节点级别,这可以通过简单地向所有当前对等点广播来实现,节点运营商只需通过配置标志选择对等点数量即可。另一种方法是允许节点按顺序向单个对等点发送多个块。这些模拟的结果与上面的完全相同,但是 D比预期的要低得多。例如当D=6时,如果每个对等点发送一个块,则永远不会广播完整的块。模拟需要 10 次跳转才能广播完整的块。当D = 10时,跳数减少到 9。
结论、遗漏和进一步的工作
我们的结果表明,如果我们在当前路由协议上使用 RLNC,那么每个节点的块传播时间和带宽使用率都会有显著改善。块/blob 大小越大或每跳延迟成本越短,这些好处就越明显。此协议的实施需要对当前架构进行重大更改,并且可能需要全新的 pubsub 机制。为了证明这一点,我们可能希望实现完整的网络堆栈以在Shadow下进行模拟。另一种方法是实现 Reed-Solomon 擦除编码和路由,类似于我们对 Peer-DAS 所做的。将上述模拟扩展到这种情况应该很简单,但op. cit已经包含了许多这样的比较。






