是时候以去中心化的方式扩展测试时间计算了。强化学习不仅仅是大语言模型的后训练范式,还是一个与苦涩教训相一致的范式。
本文为机器翻译
展示原文

Noam Brown
@polynoamial
04-17
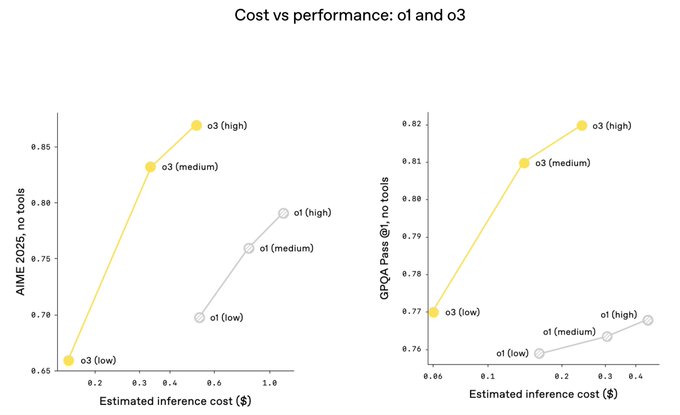
Our new @OpenAI o3 and o4-mini models further confirm that scaling inference improves intelligence, and that scaling RL shifts up the whole compute vs. intelligence curve. There is still a lot of room to scale both of these further.
来自推特
免责声明:以上内容仅为作者观点,不代表Followin的任何立场,不构成与Followin相关的任何投资建议。
喜欢
收藏
评论
分享