
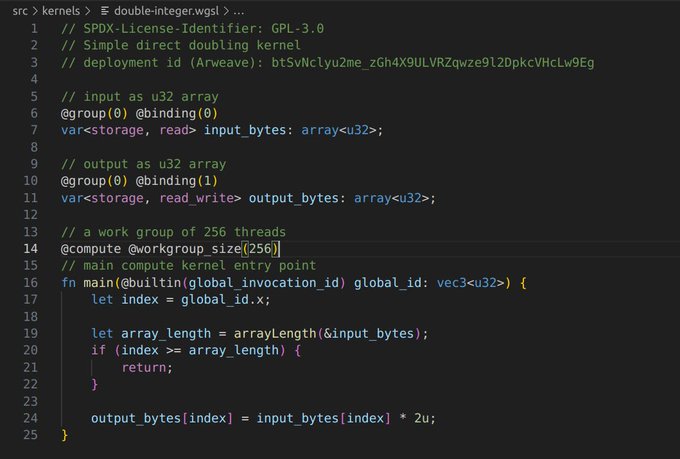
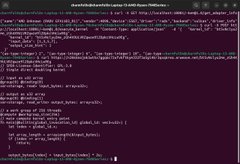
这是并行化的GPU计算,位于@aoTheComputer超级光束内。 部署自定义内核(着色器)作为GPU计算的边车服务到您的ao进程。 正在进行中:通过调用加载网络EVM RPC来调用这些自定义、灵活、GPU编译的指令集函数。 加载它
本文为机器翻译
展示原文

darwin.ar
@decentlandor
05-16
accelerationism
来自推特
免责声明:以上内容仅为作者观点,不代表Followin的任何立场,不构成与Followin相关的任何投资建议。
喜欢
收藏
评论
分享
这是并行化的GPU计算,位于@aoTheComputer超级光束内。 部署自定义内核(着色器)作为GPU计算的边车服务到您的ao进程。 正在进行中:通过调用加载网络EVM RPC来调用这些自定义、灵活、GPU编译的指令集函数。 加载它


