

这项研究由 ProbeLab 团队的 @cortze 和 @yiannisbot 完成,并得到了以太坊基金会和 PeerDAS 社区的反馈。
引言
作为以太坊提高可扩展性路线图的一部分,blob 交易被引入以允许在每个插槽中包含更多数据。因此,可以添加的 blob 越多,链上支持的数据就越多,这将使 rollup 和其他扩容方案受益。
因此,人们对增加每个区块的目标和最大 blob 数量很感兴趣。然而,这引发了一些担忧:
- 虽然机构验证者可能拥有处理更多 blob 的硬件和带宽,但许多家庭验证者并不具备。这可能会造成验证者参与的潜在不平衡。
- 增加 blob 数量还可能影响某些节点保持同步的能力,尤其是在重组或恢复事件期间,节点需要从较少的对等节点下载大量数据。
目前,我们没有太多方法来衡量网络如何处理这些情况,除了查看从其他节点下载区块或 blob 的速度(请查看我们的帖子,扩展这个想法)。这提供了一些洞察,但不足以完全理解网络在压力恢复下的行为。
减轻单个验证者负担的一种可能方法是通过分布式区块构建。由于执行层(EL)通常在 blob 交易被包含在区块之前就已接收到许多 blob 交易,区块构建者可以通过假设其他节点的本地内存池已包含区块验证所需的 blob 来减少初始带宽使用。
本文的工作建立在我们最近的研究基础上,该研究测量了 blob 侧车的理论执行层内存池命中率。那项分析表明,在超过 75% 的情况下,执行层已经拥有必要的 blob 数据,然后才提出区块。然而,那项研究并未检查执行层是否能及时为共识层(CL)的 engine_getBlobsV1 调用提供 blob。
在这个后续研究中,我们着眼于执行层内存池中 blob 侧车的实证命中率,以更好地理解分布式区块构建在实践中的可行性,尤其是在帮助带宽或资源有限的验证者方面。
摘要
- 监控共识层和执行层之间的本地
engine_GetBlobsV1调用显示执行层内存池的 blob 命中率很高:- 76.6% 的总请求能在 100 毫秒内从本地执行层内存池成功检索以验证区块。
- 剩余的 23.4% 请求是部分响应。然而,在这些部分响应中的大多数(98%)只缺少一个 blob 侧车。
- 当前网络状态显示,在 gossipsub 网络上重新分发所有侧车可能会产生一些冗余流量,因为目前,在新区块广播时,大多数 blob 已经存在于执行层内存池中。
| 响应的一部分是否? | 是否在发布内存池中看到? | 边车数量 |
|---|---|---|
| 是 | 是 | 197156 |
| 否 | 是 | 4571 |
| 否 | 空 | 6392 |
引擎API调用和边车重建时间
因为共识层(CL)不能无限期地等待执行层(EL)的响应,几个客户端团队已经讨论是否应该为engine_getBlobsV1请求设置超时,如果是,适当的值是多少。
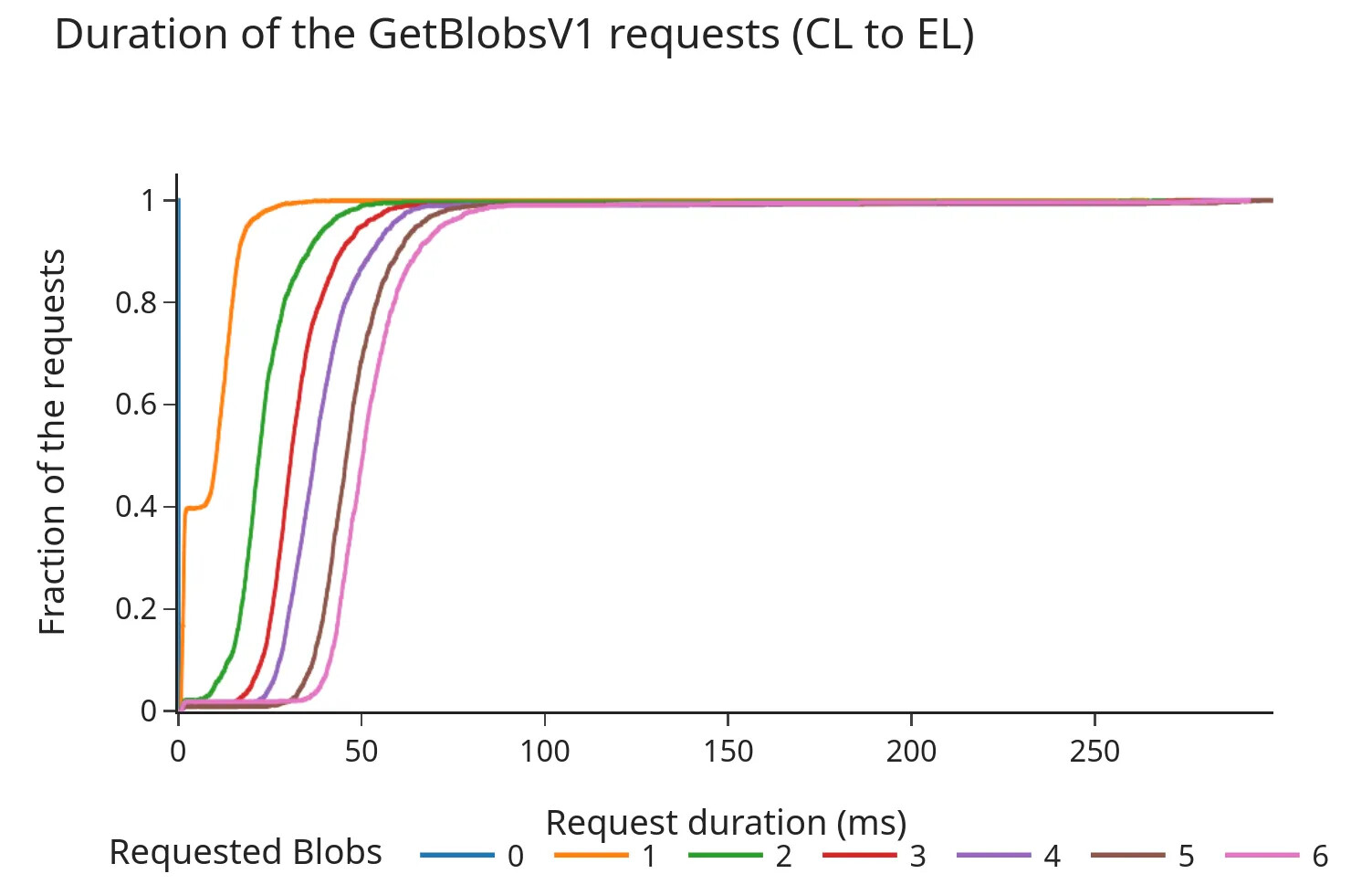
以下图表显示了引擎API的请求/响应持续时间(以毫秒为单位)的累积分布函数(CDF)。
Pectra之前:
Pectra之后:
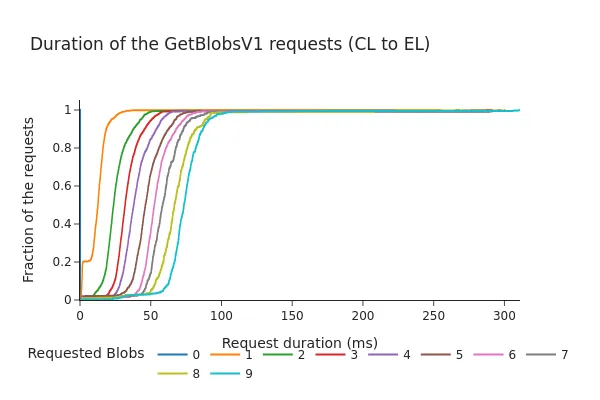
- CDF显示,即使在Pectra分叉和增加3个额外的边车后,98%的请求在100毫秒内完成。
- 总持续时间几乎与请求的边车数量呈线性增加。尽管这些时间仍在通常被认为的"安全范围"内(之前的讨论建议超时在200-250毫秒左右),但数据表明增加每个插槽的边车数量可能会导致从EL的边车内存池获取更长的时间,尤其是在较高负载下。
结论
这项研究和我们之前的研究是与@cskiraly的研究并行进行的,尽管方法不同,但两项工作得出了相同的结论:
在当前的网络状态和链的使用趋势下,大多数边车已经在被包含到信标块之前就在EL中可用。
尽管这个结论总体上是个好消息,但它表明当前网络正在使用大量资源在CL边车主题上发送冗余信息,这为改进留下了充足空间。
一方面,这种冗余确保所有CL节点都有处理新块提案所需的数据,成功地提供了弹性。另一方面,它也成为了自身的瓶颈,因为所有边车都需要在不到4秒的时间内在网络上广播(假设时间游戏正在缩短这个窗口)。
建议
为了减少网络开销和节点负载,值得讨论PeerDAS和边车共享。
在以太坊当前的PeerDAS提案中,我们只在CL层对边车进行分片,这是对Blob重新分发阶段的优化。然而,这只部分解决了问题,因为我们仍然会通过EL内存池发送所有边车交易,节点将在带宽允许的情况下不加选择地下载所有边车。
即使使用分布式区块构建,这可能有助于更快地广播边车,我们仍然会发送(至少部分)冗余信息。
IDONTWANT消息在这里有帮助,但我们仍会生成许多重复项,这最终会增加网络开销和节点负载。
可能的未来
将分片转移到EL内存池有明显且重大的好处:
在EL层对边车进行分片可以简化验证网络中Blob的种子和一些预计算步骤,这可能成为交易提议者的新职责,即对边车单元应用纠错编码并发起广播。
可以对边车的分发应用负载均衡属性,这消除了CL必须在4秒内广播边车的当前时间限制。因为边车尚未被包含,我们不需要对其传播强制执行任何截止日期。这进一步意味着较慢的用户在广播片段时可以"承受"一些额外的延迟。
EL目前在下载边车方面比CL更高效:
- 在EL层获取边车时没有时间限制,因此不需要立即下载所有看到的边车。
- EL决定何时发送单个拉取边车请求,避免了GossipSubs在其平均网格对等节点上引起的重复项→默认为
D-2每条消息的重复项(链接)
这与@cskiraly的提案大体一致:在执行层(EL)而不是共识层(CL)实施分片可能更有效。
这个想法仍处于草案阶段,探索如何优化网络资源的使用,还有几个细节需要解决。
作为这可能看起来的示例,我们想重新审视并分享Blob内存池DHT提案,这是ProbeLab团队几个月前开始起草的。它旨在展示CL和EL如何协同工作以更有效地利用网络带宽和存储(将提案细节留待未来的帖子)。一如既往,欢迎所有反馈。






