感谢Justin Drake和Tom Wambsgans的深刻且建设性的反馈。
简介:为什么以及如何在未来将 WHIR 用于以太坊?
随着以太坊的持续扩容,对 SNARK 证明系统的要求也日益严格:证明必须精简,验证必须快如闪电,并且整个系统必须保持简洁和稳健,以便在极简硬件上进行验证——理想情况下,就像 Justin Drake 最近在Ethproofs 大会第二轮电话会议中所建议的那样,像 Raspberry Pi Pico 2 这样性能受限的设备。在此背景下,一个应用脱颖而出,成为下一代 SNARK 的试验场:以太坊即将推出的精益链的签名聚合。它满足了所有约束条件——高吞吐量、严格的延迟、最低的验证成本、后量子设定——并将作为本文的运行示例。
这些需求正在推动证明系统的一种更广泛的趋势:证明系统中从单变量多项式表示向多线性多项式表示的转变。然而,在多线性环境中工作需要新的工具——尤其是在邻近度测试方面,像FRI(快速 Reed-Solomon 交互式预言邻近度证明)这样的协议不再适用。这就是WHIR 的用武之地。WHIR 是一种用于受约束 Reed-Solomon 码的递归、基于哈希的邻近度测试协议。它旨在在单变量和多线性模式下高效运行,使其足够灵活,适用于各种证明系统。WHIR 的核心结合了两个优雅的理念:一种递归折叠机制(受 STIR 启发),可以逐轮压缩域;以及一种轻量级的基于和校验的约束检查(类似于 BaseFold),可以最小的开销确保代数正确性。
最终成果是一个体现简洁性(以太坊的关键特性)的工具,它提供小型证明(通常小于 100 KB,128 位安全位,推测 Reed Solomon 码具有最大容量的相互关联一致性)、快速验证(通常在一毫秒到几毫秒内,具体取决于所选的哈希函数)和低内存占用,所有这些都仅依赖于基于哈希的加密假设。WHIR 支持紧凑、低 gas 的 SNARK 验证,实现高效的签名聚合,并为在验证器简单性至关重要的系统中实现递归证明铺平了道路。
在本文的其余部分,我们将阐述 WHIR 的工作原理、它的重要性以及它如何帮助塑造以太坊上高效证明系统的未来。
关于现代 SNARK 的一些背景
现代 SNARK 通常通过在多项式交互式预言机证明 (PIOP) 之上叠加多项式承诺方案 (PCS) 来构建。一个常见的例子是 AIR(代数中间表示)模型,其中证明者通过将表的每一列编码为单变量多项式来提交执行轨迹。这种策略虽然简单,但却带来了可扩展性瓶颈:每一列都成为一个单独的多项式,导致证明规模庞大且验证成本高昂——当涉及数百列时,通常需要耗费数兆字节(MB)的验证成本。
为了克服这个问题,最近的证明系统正在从单变量表示转向多线性表示。不再对每一列分别进行提交,而是将整个见证编码为单个多线性多项式。这种变化带来了诸多优势:更好的压缩效果、更简单的约束表达式,以及取决于轨迹总面积而非形状的证明大小。Binius、 Jolt和SP1 Hypercube等系统都顺应了这一趋势——其中 SP1 率先使用多线性承诺实现了以太坊区块的实时证明。
可以使用和校验协议来完成这种多线性设置中的约束验证,而不是构造和评估商多项式。和校验提供了更好的模块化并可以与多线性编码无缝协作,尽管在使用小字段时会带来性能上的权衡。这个限制最近已通过“单变量跳过”优化得到解决,它通过在第一轮中将多个变量完全折叠在基字段内来加速和校验。通过在廉价的基字段域中预先做更多的工作,单变量跳过减少了后续轮次中昂贵的扩展字段评估,从而显着提高了证明器的速度而不会牺牲健全性。除了这种方法之外,人们还在探索其他加速和校验协议的方法。最近一个值得注意的研究途径是由S. Bagad 及其合著者提出的。
在这个新的堆栈中,WHIR 起着至关重要的作用:它执行接近度测试步骤,验证提交的多线性函数确实接近有效的代码字。
WHIR 如何工作?
本节将以直观而严谨的方式解释 WHIR 的运作方式,重点介绍其核心机制,而无需深入探讨完整的形式化证明。旨在为工程师提供清晰易懂的理解。
Reed–Solomon 码接近度测试
从高层次上讲,WHIR 是一种工具,用于验证函数f : \mathcal{L} \to \mathbb{F} f : L → F是否“接近”低次多项式,以及该多项式是否满足某些代数约束。
什么是里德-所罗门码?
Reed-Solomon 码是通过在有限域上求低次多项式而得到的函数集。更准确地说,假设我们选择一个有限域\mathbb{F} F和一个子集\mathcal{L} \subseteq \mathbb{F} L ⊆ F ,我们称之为求值域。一个d次Reed-Solomon 码为:
换句话说,这些只是域\mathcal{L} L上所有可能的次数小于d的多项式的求值表。当我们说函数f f “符合码”时,是指它与这样的多项式一致。当f f “接近”码时,是指它与\mathcal{L } L中大多数点上的某个码字一致——这称为接近度。
我们为什么要关心接近度测试?
在证明系统中,证明者可能会向验证者发送一个函数f ,该函数看起来像是在求一个低次多项式的解,但实际上可能并非如此。为了确保可靠性,验证者必须检查f是否接近 Reed-Solomon 码中的一个真实码字。这是邻近度测试的核心。
多线性视图和平滑代码
WHIR 使用的是结构更完善的 RS 码。它不使用任意多项式,而是使用多线性多项式——即每个变量的次数最多为 1 的多项式。例如,对于变量x、y 、 z ,多线性多项式可以表示为3 + 2x + 5y + 7xz ,但不能表示为x ^ 2 x 2或y ^ 2z y 2 z 。
为此,WHIR 假设:
- 定义域\mathcal{L} L是\mathbb{F}^* F ∗的乘法子群,其大小为 2 的幂,
- 度数界限d d也是 2 的幂,比如d = 2^m d = 2 m 。
在这些条件下,任何次数小于2^m 2 m的单变量多项式\hat{f} ^ f都可以唯一地视为一个包含m个变量的多线性多项式。在点x \in \mathcal{L} x ∈ L处求原多项式的解,等价于在由x x导出的一个特殊向量处求其新的多线性对应项(我们也称之为\hat{f} ^ f )。这给出了以下优雅的重新解释:
此变换将简单单变量域\mathcal{L} L中的每个点映射到m m维布尔超立方体上的一个点。它使我们能够应用高效的多线性技术(例如和校验协议),同时保留原始代码结构的简洁性。
向代码添加约束
在许多协议中,我们不仅要检查f是否接近某个多项式,还要确保该多项式满足某个代数条件。例如,我们可能希望强制执行以下规则:
其中\hat{w} ^ w是固定约束多项式, \sigma σ是已知值。
为了表达这一点,WHIR 使用了 RS 码的一种变体,称为约束 Reed-Solomon 码。正式定义如下:
其中f f是多线性多项式\hat{f} ^ f在\mathcal{L} L上的求值。
此约束确保f f不仅来自多项式,而且满足特定代数恒等式。
折叠问题:递归压缩
为了提高邻近度测试的效率,WHIR 应用了一种称为折叠的递归压缩技术。受 FRI 和STIR等协议的启发,折叠技术会逐渐将大问题简化为更小的等效问题。每一轮都会缩小函数的定义域和复杂度,同时保留其基本属性,从而使验证者能够轻松地进行最终检查。经过足够多的轮次后,问题会变得非常小,可以直接且低成本地进行检查。
WHIR 回合:结合折叠和校验
此过程中的核心操作是折叠,最好通过直观的交错式 Reed-Solomon 解释来理解。与其使用复杂的递归公式,不如将域\mathcal{L} L想象成被分组为小块。每个块中的证明者数据定义了一个小的局部多线性多项式。折叠整个块就像在验证者发出的随机挑战\alpha α下评估这个局部多项式一样简单。
从数学上讲,如果我们让p_y(X_1, \dots, X_k) p y ( X 1 , ... , X k )成为与新的较小域中的点y y对应的点块的局部多项式,则折叠操作就是:
此单一评估使用随机挑战向量\alpha \in \mathbb{F}^k α ∈ F k ,优雅地将原始块中2^k 2 k个点的信息压缩为新函数的单个值。
WHIR 有力地增强了这一想法。在一轮中,它使用k k维随机挑战\alpha α ,通过将其并行应用于两个进程,一次性消除k k个变量:
- k k轮和校验将主要代数约束简化为一个新的、更简单的约束。
- 折叠(作为局部评估)将函数本身缩小为更小的函数。
整个轮次将原始邻近实例转换为一个明显较小的新实例,其中约束多项式\hat{w} ^ w和目标\sigma σ均被更新:
这带来了至关重要的效率提升。虽然我们将变量数量减少了k k (将多项式空间缩小了2^k 2 k倍),但求值域仅减少了一半。这显著提高了代码速率\rho = 2^m / |\mathcal{L}| ρ = 2 m / | L | 。新的速率\rho' ρ ′计算公式如下:
2^{-k} 2 − k项来自于消息空间的缩减(更少的多项式系数),而2^1 2 1项来自于域大小的减半。降低每轮的编码率是 WHIR 查询复杂度低的关键原因。
折叠的健全性保证
折叠过程经过精心设计,坚固耐用,这对于整个证明系统的安全性至关重要。
- 折叠保留了函数与代码的距离。如果函数起始位置距离任何有效代码字较远,则折叠后它仍然保持较远。错误无法通过代数混合来隐藏或抵消。
- 在列表解码设置中,多个有效码字可能接近证明者的函数。折叠操作保证(以高概率)将整个邻近码字列表忠实地映射到新的、更小的问题上。递归过程中不会引入任何伪解或错误解,从而确保验证者不会被误导。
WHIR 迭代总结
如下图所示,每次 WHIR 迭代都会将接近度测试问题简化为一个较小的问题,同时保持合理性。
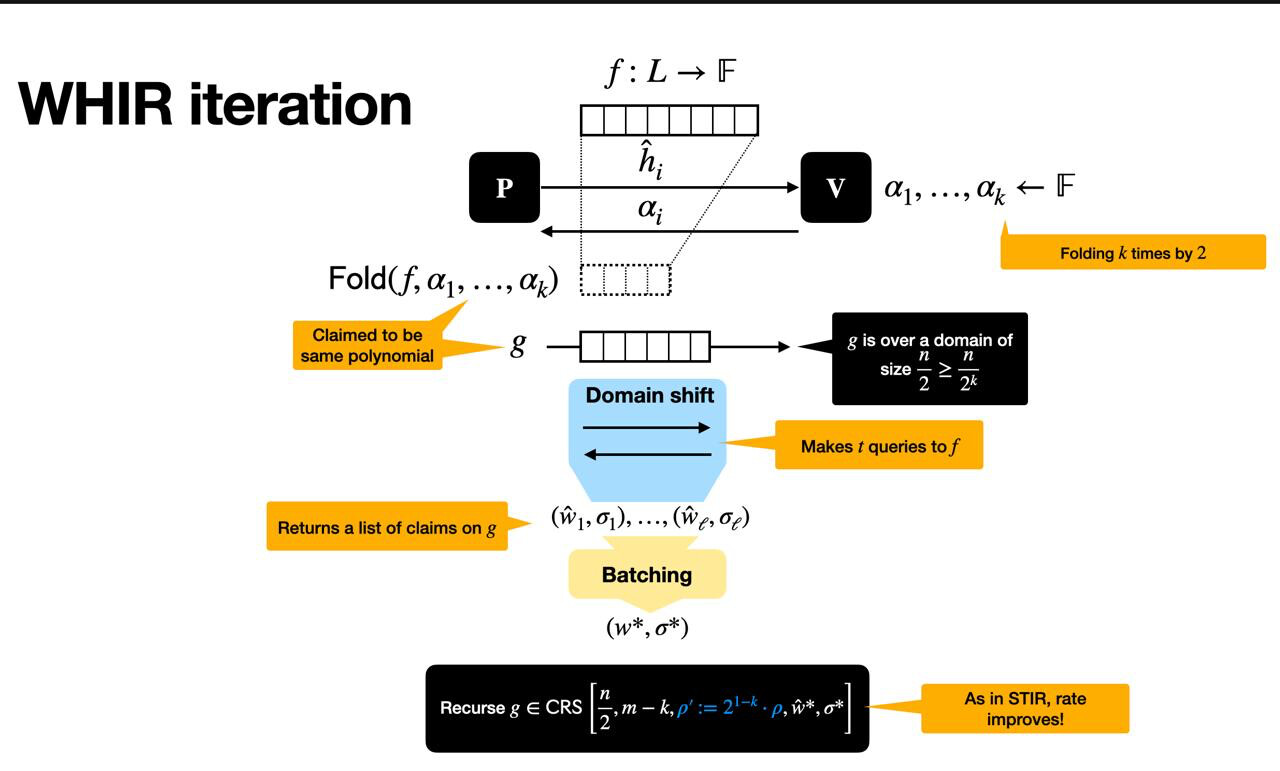
这主要分为三个阶段:
设置
我们从一个函数f : \mathcal{L} \to \mathbb{F} f : L → F开始,该函数定义在结构化域\mathcal{L} L (大小为2^m 2 m的乘法子群)上。证明者声称f f来自于对多线性多项式\hat{f} ^ f求值,并且该多项式满足如下约束:
其中\hat{w} ^ w是一个简单的约束多项式。这是我们想要验证的核心命题。
交互阶段
验证者发送一个随机挑战\alpha α ,指示证明者折叠函数——通过隐藏一个变量将两个输入压缩为一个。这将生成一个新函数f' = \mathrm{Fold}(f, \alpha) f ′ = F o l d ( f , α ) ,该函数定义在较小的域\mathcal{L}^{(2)} L ( 2 )上,并且涉及m - 1 m − 1 个变量,而不是m m 。
为了确保折叠是诚实进行的,验证者会执行几项检查:
- 它在域外随机采样一个点并要求证明者对其进行评估,确保f' f ′确实来自低次多项式。
- 它从折叠函数中采样一些值,并将它们与f f所说的值进行比较,以强制一致性。
- 它使用随机线性组合将所有这些检查(连同约束)组合成一个方程,并为下一轮准备一个新的约束多项式。
递归声明
在这一轮结束时,验证者和证明者就一个新的断言达成一致: f' f ′在更小的定义域和更少的变量上接近于一个新的多项式\hat{f}' ^ f ′ ,并且\hat{f}' ^ f ′满足一个新的约束:
这个新实例的形式与原始实例完全相同,只是更小。WHIR 随后递归此断言,重复相同的步骤,直到函数小到可以直接检查。
这种方法的妙处在于,每一轮可以一次性去除k个变量,同时仅将域缩小2倍,从而降低验证率。最终,验证者可以高度确信原始函数f接近于满足约束的有效码字——而这一切都只需付出很少的努力。
WHIR 能为以太坊带来什么
WHIR 的独特之处在于其执行邻近度检查的方式。WHIR 并不依赖 FRI 等传统技术,而是采用基于折叠加和校验的递归方法,这使得它在多线性设置(其中见证是\{0,1\}^m { 0 , 1 } m上的函数)中尤其有效。这种设计带来了一些与以太坊及类似链上环境尤其相关的优势。
极低的查询复杂度。WHIR仅需少量查询即可执行邻近度测试。这意味着更少的 Merkle 开启次数、更少的链上数据发送次数,最终显著降低验证成本。
快速验证,通常以微秒到几毫秒为单位。WHIR专为超快速验证而设计——使用 Keccak 或 Blake3 等快速哈希函数时,通常在几百微秒内完成;使用 Poseidon2 等支持 SNARK 的哈希函数时,则最多可在几毫秒内完成。它通过结合两个强大的思想来实现这一点:BaseFold 的和校验协议(以最小开销验证多项式恒等式)和 STIR 的递归折叠(压缩每轮问题规模)。两者结合,将全局邻近度检查分解为一系列易于验证的较小检查。
更小的证明。WHIR显著减少了证明的大小,尤其是在多线性设置下。WHIR 不再将迹的每一列提交为单独的单变量多项式,而是将整个见证表示为单个多线性多项式\hat{f} ^ f 。只需一次提交,递归折叠可以逐轮减小域的大小。这可以减少提交次数、查询次数和编码开销,即使对于大型计算,也能显著减小证明大小。
灵活的编码。WHIR支持单变量和多线性编码。这使得它与各种 SNARK 结构兼容——无论它们使用传统的单变量编码(例如 PLONK 或基于 FRI 的系统),还是多线性方法。
以太坊上的应用
由于其紧凑的证明和微秒级验证,WHIR 特别适合以太坊应用:
- Rollups。Rollups中的状态转换可以编码为多线性多项式。WHIR 有助于简洁地证明这些转换,并为以太坊 Layer-1 验证者提供极快的验证速度。
- 签名聚合:随着未来对 BLS 签名后量子时代替代方案的需求,高效验证数千个基于哈希的签名至关重要。WHIR 提供的加密引擎可以将这些庞大的集合压缩为单个恒定大小的证明,并最大程度地减少链上验证占用的空间。
- 低 Gas 的 SNARK 验证:链上 Gas 成本主要由数据存储和计算决定。WHIR 的目标在于最小化查询复杂度(减少 Merkle 路径数据)和验证者的计算工作量。虽然某些前量子 SNARK 仍处于高度优化状态,但 WHIR 的性能使其成为后量子系统中的领先竞争者,因为在后量子系统中,链上效率是不可协商的,正如本研究文章所探讨的那样。
简而言之,WHIR 是一种快速、递归且灵活的邻近协议,能够自然地融入现代 SNARK 堆栈。对于以太坊而言,它提供了一条通往更小、更便宜、更快速证明的途径——尤其是在已经受益于多线性编码的系统中。
WHIR 与 FRI:近距离测试的代际飞跃
FRI 一直是现代证明系统(尤其是 STARK)的基石。其设计使用递归折叠来有效地测试承诺函数是否接近低次多项式。在经典的 STARK 流程中,首先将所有代数约束组合成一个高次“组合多项式”,然后对其运行 FRI 来证明它实际上是一个具有预期低次的多项式。这种方法非常强大,并确立了使用多对数验证器进行后量子证明的可行性。
然而,SNARK 设计的格局正在发生变化。像 Jolt、Binius 和 SP1 Hypercube 这样的现代系统正在从这种两步“先合并后测试”的模型转向更集成的多线性方法。在这个新范式中,证明是围绕和校验协议构建的,该协议是一种用于验证多线性多项式声明的工具。WHIR 正是在此体现了其根本性的演进。
WHIR 重新思考了接近度测试,以适应这个现代的、以和校验为生的世界。WHIR 不再是处理约束后运行的通用低阶测试,而是将约束验证直接集成到其递归过程中。FRI 轮大致包括折叠域并对随机点执行一致性检查。相比之下,WHIR 轮将这种折叠与轻量级和校验相结合,这不仅确保折叠的正确性,还将计算的代数约束传递到下一个更小的实例。
这种架构差异带来了关键的性能优势:
查询次数渐近减少。这是 WHIR 最大的优势。对于包含2^ m个元素的计算,FRI 的查询复杂度随m m线性增长,而 WHIR 的查询复杂度随m m呈对数增长。对于大规模计算而言,这是一个显著的改进。实际上,这意味着 Merkle 路径开口次数会大大减少,而 Merkle 路径开口次数是影响证明大小和链上验证 gas 成本的主要因素。
原生多线性和约束支持。WHIR是约束 Reed-Solomon 码的近似 IOP。它旨在处理定义现代证明系统的多线性多项式和基于和校验的关系。虽然 FRI 可以适应这些设置,但 WHIR 将它们视为“一等公民”,从而实现更简洁、更高效的设计。
极快的验证速度。更少的查询次数和基于校验和的轻量级验证器逻辑相结合,使 WHIR 能够实现数百微秒的验证时间。这使得它非常适合链上应用,因为验证器工作的每一微秒都会直接转化为用户成本和网络吞吐量。
签名聚合:WHIR 的具体用例
以太坊未来共识层面临的关键挑战之一是找到一个后量子时代的 BLS 签名替代方案。目前已探索了多种方案,包括基于格的方案和基于累积的协议,但其中许多方案难以在可扩展性、效率和后量子安全性之间取得平衡。
一个特别有前景的方向是使用XMSS 签名,它基于哈希值,且设计为量子安全。然而,XMSS 签名数据量大,单独验证成本高昂,因此聚合签名至关重要。其思路是使用基于哈希值的 SNARK 算法将数千个单独的签名压缩成一个简洁的证明,然后将其发布到链上。正如 这篇以太坊研究文章所述,这样的协议必须支持两种操作:
- 聚合:将大量原始签名压缩成一个 SNARK 证明,
- 合并:递归地将两个现有的聚合证明组合成一个证明。
合并操作引入了递归证明要求——而这正是 WHIR 的优势所在。得益于其折叠机制和极低的查询复杂度,WHIR 使得构建小型且易于验证的 SNARK 变得更加容易。更少的查询意味着更少的哈希计算,从而直接降低了验证每一层递归的成本。与 FRI 等传统的 PCS 结构相比,WHIR 能够实现更快的递归证明——这对于实时签名聚合至关重要。
今日表现及未来展望
在这种情况下,衡量性能的自然方法是每秒可证明的哈希值(例如 Poseidon2)数量。我们目前的 WHIR 实现实现了:
- 在高端 GPU(RTX 4090)上每秒执行 100 万次 Poseidon2 哈希运算,
- 消费级 CPU 上每秒可执行 100,000 次 Poseidon2 哈希运算。
PCS 逻辑 ( WHIR-P3 ) 和 PIOP 层 ( Whirlaway ) 均已公开,并正在积极优化。尽管目前的瓶颈在于 CPU 性能,但目前正在努力达到与 GPU 速度相当的水平——目标是在 CPU 上实现每秒 100 万次哈希运算,与Plonky3等系统已经实现的水平相当。
总结和后续步骤
WHIR 提供了一种引人注目的全新邻近度测试方法,尤其适合以太坊的需求:较小的证明大小、快速验证,以及与单变量和多线性证明系统的无缝集成。其递归折叠策略和通过 sumcheck 进行的约束检查机制,使其成为现代 SNARK 堆栈的理想之选,尤其是在效率和简洁性至关重要的应用中——例如 rollups、zkVM 和精益链的签名聚合。
在本文中,我们重点介绍了 WHIR 协议本身及其优势。但 WHIR 只是完整 SNARK 的一个组成部分。在后续文章中,我们将描述如何围绕 WHIR 构建一个完整的证明系统,并展示它如何融入基于哈希加密的签名聚合完整流程。
与此同时,我们正在积极优化我们的实现——旨在使 GPU 和 CPU 的验证速度达到甚至超越当今最佳系统,同时保持协议的模块化和易于采用。我们目前维护着一个基于 Plonky3 的开源 WHIR 实现 ( WHIR-P3 ),并计划将其作为社区驱动的成果直接上传到Plonky3 。这符合我们将 WHIR 打造成公共产品的愿景——开放、集体维护,并易于集成到其他项目中。
目前,一些致力于 zkVM 的团队已经表示有兴趣采用 WHIR,我们相信,随着以太坊生态系统的发展,将会出现更多的用例。
我们的目标是让 WHIR 不仅仅是一个快速而优雅的想法,而且成为下一代链上证明的实用基石。