

深度融资:开源依赖项的预测市场
Elizabeth Yeung 、 Clément Lesaege 、 Devansh Mehta 。特别感谢David Gasquez 、 Eliza Oak和Davide Crapis对草案早期版本的反馈,以及Vitalik Buterin 的最初启发和广泛讨论。
执行摘要
Deep Funding 使用机器人、模型和交易员网络来预测开源存储库对以太坊的价值(如果由陪审团进行评判)。
目标:任何人都可以向其发送资金以支持以太坊的公钥,并由基于市场的机制确定对项目的精确分配。
分配机制:机器人、模型和交易员押注某个存储库在接受陪审团评判时对以太坊的价值。这些价值将用于分配资金。
界面:上传一个 CSV 文件,其中最多 128 个 repos 之间的权重加起来为 1。
奖励:根据预测的准确性和支持预测的金额来赚钱。
解决方案:评委将评估波动性较高或有市场操纵迹象的回购协议,以获得更高的权重。这些回购协议的权重可以优先于回购协议的市场价值,用于分配机制。
不同之处:早期的深度融资轮次采用简单的数据科学竞赛形式(类似 Kaggle),并向排行榜上的顶级模型颁发奖品。此次的深度融资结构有两点不同:
模型可以投入资金来支持其提交的结果。投入的资金越多,模型的预测对回购权重的影响就越大。
参与者的支付功能并不依赖于外生奖金,而是取决于市场的流动性、其他参与者为支持其预测而投入的金额以及提交的准确性。
如果模型构建者没有足够的资金来支持他们的预测,他们仍然可以参加 Pond 上的数据科学竞赛。如果他们想要一个可变奖励函数,现在除了 Pond 之外,他们还可以在deep.seer.pm上提交模型。
问题陈述
目前存在的可信中立的资助系统扩展性不佳。例如,以太坊分析仪表盘 Grow the Pie 在 Octant 第 8 个周期获得的资助金额与 Protocol Guild(以太坊上所有共识和执行客户端的集合)相同。虽然这种对等原则对于规模较小的一次性资助来说可能合理,但当分配数百万美元的定期资金时,它就变得不可持续了。
如果我们希望去中心化系统中的参与者能够根据贡献而不是社交游戏在庞大的网络中获得奖励,我们就必须设计能够扩展人类判断的融资机制,并在支撑以太坊等生态系统成功的复杂项目网络中分配资金。
概述
应对这一挑战的一种方法就是深度融资 (Deep Funding ),它由一个加权图组成,显示核心以太坊代码库及其依赖项之间的相对重要性。其当前版本包含一项数据科学竞赛(类似于 Kaggle),开发者需要构建模型来预测每个代码库的权重。评委对代码库子集评分错误率最低的模型,将在整个依赖关系图中确定其权重。
这篇文章总结了深度融资运作方式的一个关键转变:从一次性竞赛(参与者需要为图表中的每个回购协议提交权重)转变为一个自动循环的预测市场,参与者可以对自己有信心的答案进行押注。他们实际上是在押注回购协议一旦被评估后的价值。
这有很多好处:
- 它解决了女巫攻击问题,即建造者有动力提交多个模型,并根据其中准确的一个提交获得奖励。
- 它允许参与者进行专门研究,并仅对一部分权重表达自己的观点。
- 它大大减少了机制的“维护负荷”,使其能够以更加自动化的方式运行,而无需依赖大量的人工干预。
- 自动重复离散轮次的机制使价值观保持新鲜和相关性,同时保持机制简单且可分析。
整体结构是依赖图中每条边的市场,该市场根据其被评估的价值进行交易。然后,我们可以使用这些价值在去中心化网络中分配资金。陪审团会定期抽查 N 个市场,以根据待评估边的高波动性或外部支付来决定市场结果。这种设计旨在确保价值在网络发展过程中保持动态性和可扩展性。
目前,一项试点概念验证正在进行中,涉及 45 个属于 Protocol Guild、Argot Collective 和 Dev Tooling Guild 的 repos,任何人都可以在这里对这些 repos 之间的相对价值进行质押。Gitcoin Grants 第 24 轮将新增 45-60 个 repos,并将根据图表中 repos 的权重分配 35 万美元的资金。
设计
从高层次来看,新版深度融资分为三个步骤:
绘制依赖关系图:识别目标生态系统(例如以太坊)中核心项目及其依赖关系的网络。我们的经验表明,这并非易事,因为 repo 维护者要么担心他们的核心依赖项不存在,要么担心存在太多不相关的依赖项。依赖关系图也是一个动态图,因此需要制定一个流程来纳入新项目并排除旧项目。
我们提出了一种结构,任何人都可以发布债券,以将新边纳入图谱。如果新边未进入市场或评估员评估的前 128 名,则将被削减。同一时间,只有 128 个 repo 可以计入对节点的贡献并获得资金,129 个及以上的 repo 的权重将重新分配给 128 个及以下的 repo(假设根据齐普夫定律,最高子节点和最低子节点的权重相差约 128 倍)。市场决定权重:基准利率是图中每个项目的起始权重。交易者如果认为某个项目的份额被低估或高估,就会买入或卖出。市场会定期对回购的实际权重进行判断,以此作为市场清算的依据,交易者以此为基准盈利或亏损。这些市场的起始基准利率应经过深思熟虑,以防止流动性损失,并为交易者和维护者锚定回购权重。任何提议将节点加入图谱的人都必须发行债券,使其基准利率达到前 128 名。
分配奖励:资金将根据依赖关系图中边的现行权重进行分配,而这些权重由市场预测陪审员在评估该边时获得的分数决定。如果有人认为某个权重有误,他们可能会进行反向交易或付费让陪审团评估该权重。这种评估机制旨在起到威慑作用:了解该机制可以被调用应该会降低操纵动机,因此实际付费评估的情况预计会很少见。波动性较高的边权重也可能引发对其实际价值的调查,陪审员的报酬将来自债券没收或外部资金。
数据结构
本节本质上是技术性的,介绍了目标节点与其依赖项之间边的有向图的符号模式。边带有权重标记,表示依赖项之间的信用分配。例如,以太坊可以作为目标节点,而 Grow The Pie、Solidity 等节点与以太坊的关系中带有加权边。类似地,Sphinx 也会有一条指向 Solidity 的加权边,Solidity 是其依赖项之一。请注意,以下描述是具体的实现,有向依赖图的通用设计可以在附录中找到。

来源: deepfunding.org
节点:
- 目标节点(
T):目标节点T是起点,代表我们想要确定信用分配的生态系统(例如以太坊),以便将资金引导至其关键贡献者。 - 种子节点(项目
S):种子节点S是T的直接依赖项,在以太坊中是软件存储库 URL。 - 子节点(项目
C):类似地,子节点C是S的直接依赖项。
边缘和权重:
- 边:此图中有两种类型的边,
T->S和S->C,表示节点之间的依赖关系。 - 边权重:每条边
X->Y被赋予一个权重W,其中W \in [0,1] W ∈ [ 0 , 1 ] 。该权重被解释为“Y应得X的W功劳(例如 20%)”。- 这里,保持不变式,使得进入节点的边上的权重之和必须为 1。如果
{Y_1, Y_2,..., Y_k}是X的所有子节点的集合,那么必须满足: \sum_{i=1}^{k} W(X\rightarrow Y_i) = 1 ∑ k i = 1 W ( X → Y i ) = 1 。
- 这里,保持不变式,使得进入节点的边上的权重之和必须为 1。如果
- 原创性得分:种子节点
S的原创性得分OS被解释为“OS是归属于S自身工作的功劳份额”。例如,Brave 浏览器的原创性得分可能为 0.2,因为它是 Chromium 的一个分支;而 Solidity 的原创性得分可能为 0.8,因为它致力于最小化依赖性。我们可以将原创性得分视为种子节点本身的一种权重。- 因此,
1-OS表示应该传递给S的依赖项的权重,S 是节点集C。
- 因此,
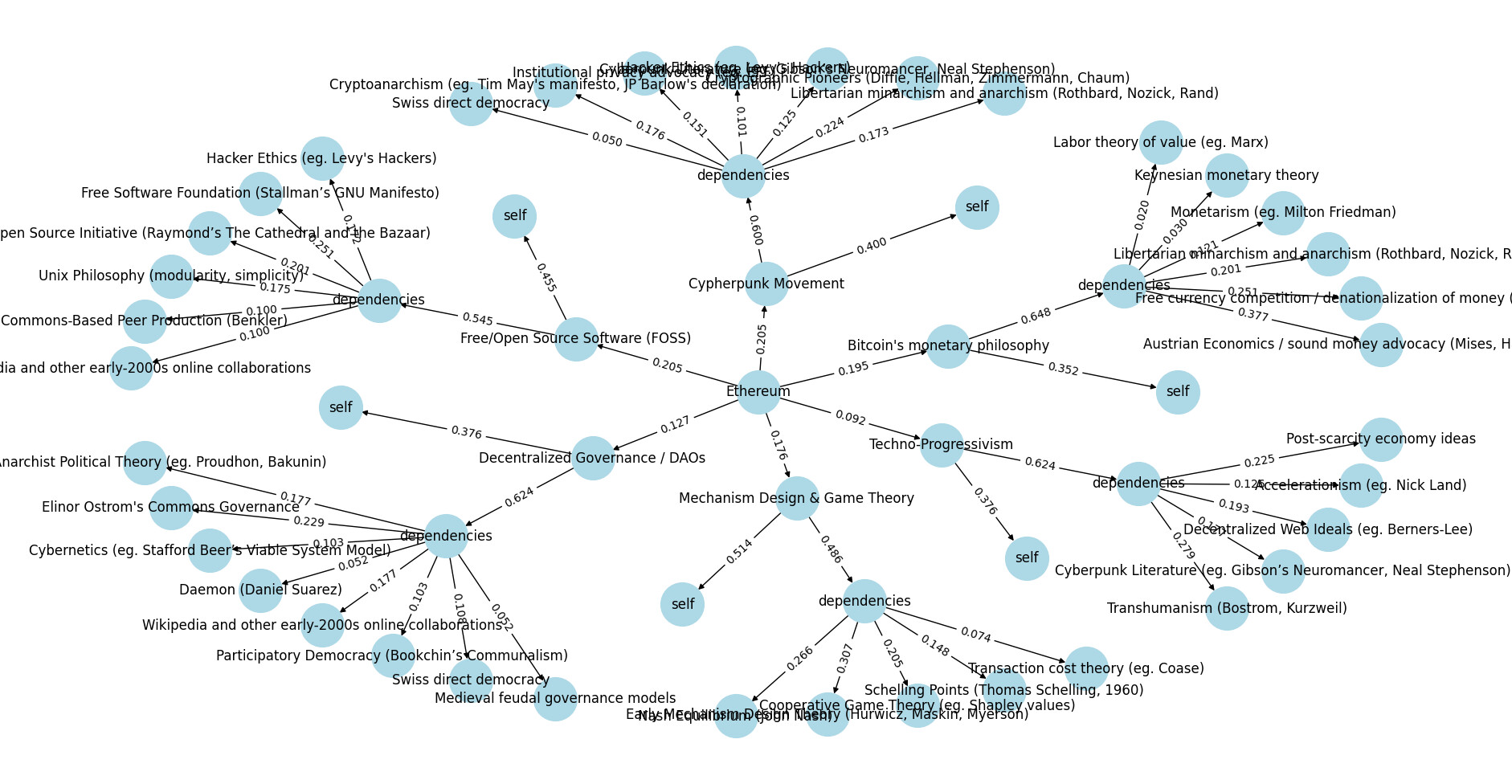
节点、边和权重如何作用于以太坊的哲学贡献的示例。来源: deepfunding/scoring/example_output.png
总结一下,权重有三种类型: W(T->S) 、 OS(S)和W(S->C) 。这些权重会根据市场的集体智慧不断变化。
市场类型
种子节点:种子节点市场将被构建为一个多标量市场,其中不同项目的权重加起来为 1( 类似于比例选举中的多标量预测市场,参与者试图预测每个政党将获得的席位份额)。
我们引入以下符号:
- w_{0,j} w 0 , j表示W(X\rightarrow Y_j) W ( X → Y j )的真实值(实际中无法测量)。
- \hat{w}_{0,j} ^ w 0 , j表示陪审员对w_{0,j} w 0 , j的评估。
- W_{0,j} W 0 , j表示可兑换\hat{w}_{0,j} ^ w 0 , j 的代币。
- \dot{w}_{0,j} ˙ w 0 , j表示 token W_{0,j} W 0 , j的值。
我们有\hat{w}_{0,j} ^ w 0 , j作为w_{0,j} w 0 , j的估计量。由于陪审员人数较少,该估计量预计会有较高的方差,并且可能存在较高的偏差。W_ {0,j} W 0 , j的预期值为E[\hat{w}_{0,j}]=w_{0,j}+b_{0,j} E [ ^ w 0 , j ] = w 0 , j + b 0 , j ,其中b_{0,j} b 0 , j是陪审员评估的预期偏差。
因此,一个完全知情的交易者会买入/卖出W_{0,j} W 0 , j直到\dot{w}_{0,j}=w_{0,j}+b_{0,j} ˙ w 0 , j = w 0 , j + b 0 , j 。
但是,如果陪审员的偏见是市场参与者无法公开获得的信息(实现这一点的一种简单方法是不提前选择陪审员或在交易期间隐藏他们的身份),那么他们就会买卖W_{0,j} W 0 , j ,直到\dot{w}_{0,j}=w_{0,j} ˙ w 0 , j = w 0 , j 。
在实践中,市场参与者(预计是人工智能)不会完全了解w_{0,j} w 0 , j ,因此\dot{w}_{0,j} ˙ w 0 , j将充当w_{0,j} w 0 , j的估计器。该机制将充当陪审员评分的“去噪器”。
为了提高这些市场的效率,我们:
- 允许任何人用一个货币单位兑换一整套W_{0,j} W 0 , j代币(反之亦然)。
- 我们在自动做市商上为所有W_{0,j} W 0 , j提供流动性。
原创性分数:每个用于衡量种子节点原创性的市场都可以构建为一个单一的标量市场,其中“UP”令牌和“DOWN”令牌的总和为 1,这取决于所评估的节点原创性。
- o_{j} o j表示节点j j的原创性得分的真实值。
- \hat{o}_{j} ^ o j表示陪审员对o_{j} o j的评价。
- e_j e j是一个变量,如果评估了j j的原创性得分,则等于 1,否则等于 0。
- S_j S j代表可兑换\frac{1}{s} 1 s的代币如果对j j的原创性得分进行评估,其中s s是评估原创性的节点数。
- 如果评估了j j的原创性分数,则 O_{j} O j是“UP”令牌,可兑换\hat{o}_{j} ^ o j 。
- \dot{o}_{j} ˙ o j表示以S_j S j表示的标记O_{j} O j的值。
如果对节点j j进行评估,则 \hat{o}_{j} ^ o j充当o_j o j的估计量。O_ {j} O j的预期值为E[\hat{o}_{j} | e_j = 1]=o_{j}+b_{j} E [ ^ o j | e j = 1 ] = o j + b j个S_j S j单位,其中b_{j} b j是陪审员评估中的预期偏差。如果我们随机评估原创性,则 O_j O j和e_j e j不相关。因此,我们有E[\hat{o}_{j}] = E[\hat{o}_{j} | e_j = 1]=o_{j}+b_{j} E [ ^ o j ] = E [ ^ o j | e j = 1 ] = o j + b j 。
运用与上一节类似的逻辑,但加上“市场参与者事先并不知道哪些原创性分数会被评估”,我们发现,市场除了充当陪审员分数的“去噪器”之外,还充当了衡量陪审员评估的一种方式。由于市场参与者不知道哪些分数会被评估,他们应该在所有市场上进行交易,假设相应的分数会被评估(这有点像学生需要学习一门课程的所有科目,以防该科目最终出现在考试中)。
为了使这个市场更加高效:
- 我们有“DOWN”代币( \bar{O}_{j} ¯ O j ),如果j j被评估,则可以兑换 1 - 原创性得分。这允许市场参与者“做空”某个项目的原创性得分。
- 允许任何人用一个货币单位兑换一整套S_j S j代币(反之亦然)。
- 允许任何人用一个单位的S_j S j交换一个O_{j} O j和\bar{O}_{j} ¯ O j (反之亦然)。
- 我们为S_j - O_{j} S j − O j和S_j - \bar{O}_{j} S j − ¯ O j这对交易对提供流动性。请注意,我们不需要在代币S_j S j和货币代币之间提供流动性。
子节点:子节点的市场应该是一个多尺度市场,相对于种子节点,其总和为 1,条件是对该节点的子节点进行评估。
对于子节点,我们结合了前两种方法。
我们引入以下符号:
- w_{i,j} w i , j表示W(X_i\rightarrow Y_j) W ( X i → Y j )的真实值。
- \hat{w}_{i,j} ^ w i , j代表陪审员的估计。
- C_i C i代表可兑换\frac{1}{c} 1 c 的代币如果对X_i X i个孩子的权重进行评估,其中c c是对其孩子进行评估的节点数。
- W_{i,j} W i , j表示可兑换\frac{\hat{w}_{i,j}}{c} ^ w i , j c 的代币如果对X_i X i个孩子的权重进行评估。
- \dot{w}_{i,j} ˙ w i , j表示以C_i C i表示的标记W_{i,j} W i , j的值。
使用与前两节相同的逻辑,我们可以看到\dot{w}_{i,j} ˙ w i , j充当了w_{i,j} w i , j的估计器。这里,该机制对人类陪审员的评估进行了去噪和缩放。
陪审员评估策略
与基于客观事实做出裁决的常规预测市场不同,这些市场依赖于陪审员的主观评估。这不仅给法官带来了更多压力,也意味着需要一条与预测机制改进轨道同样严谨的陪审团改进轨道。
虽然我们还没有完全正式确定陪审员的设计,但这里有一些广泛的考虑:
- 呈现给陪审员的信息与陪审团的选择本身同样重要。这可以采用陪审员用户界面的形式,其中包含从各个 LLM 获取摘要的功能。另一种选择是区分角色:深入挖掘回购价值的分析师,以及利用分析师提供的信息进行最终评估的法官。
- 一个相关的考虑因素是陪审团的专业知识构成。一些陪审员可能是领域专家,而另一些则是通才。专业和通才陪审员都认可的评分应优先考虑。
- 应该有一些方法来识别并减少陪审员的异常评分的影响。在当前阶段,我们决定在Seer 上的多尺度预测市场中使用Huber 损失函数,并在Pond 上的竞赛中继续使用对数空间中的 L2 范数(两者均在对数空间中)来处理陪审员的成对比较。
行动呼吁
- 模型建造者可以参加 3 场比赛,每场比赛都有奖金池和交易补贴。
- 种子节点:
- 原创性得分:下个月,您可以预测某个 repos 在评估时会获得的原创性得分。这将决定有多少资金应该留在种子节点,而不是分配给其依赖节点。参与此活动,只需构建一个可以预测原创性得分的模型,为其注入一些资金,然后让它进行预测即可。
- 子节点:最后一个环节是 Pond 上的一项竞赛,模型构建者将预测种子节点依赖关系之间的权重。该竞赛的结果可以再次作为启动多标度市场(基于每个依赖关系对种子节点的价值)的基准利率。
- 想要提供种子节点之间比较的陪审员可以在此申请成为陪审团的一部分。
- 维护者:如果您是 Deep Funding 的一部分 repos 的维护者,我们需要您的帮助:
最后,如果您只是想关注实验、表达您的想法或有进一步的问题,请加入Deep Funding 电报组。
附录
有向依赖图的通用结构
在这里,我们提出了一个更正式、更通用的版本,与上述规范中描述的内容相对应。对于每个项目P ,我们定义了三种类型的节点,这些节点的边指向P
-
P:SELF:此节点代表项目自身的贡献。- 边
P->P:SELF与边W的对应关系被解释为“W是归属于P自身工作的贡献份额”。例如,Brave 浏览器的权重可能是 0.2,因为它是 Chromium 的一个分支;而 Solidity 的权重可能是 0.8,因为它的目标是最小化依赖性。这也可以称为项目的originality。 - 这种类型的节点没有任何子节点,并且每个
P只有 1 个子节点。
- 边
-
P:OTHER:此类节点可以看作是P的直接依赖关系的集合。在这种类型的节点下,我们可以进一步将其划分为两个子类型:-
P:OTHER_KNOWN:这些是P的已知依赖项,并且本身就是项目。 -
P:OTHER_UNKNOWN:这代表P的所有未知依赖项。- 这种类型的节点没有任何子节点,并且每个
P只有 1 个子节点。
- 这种类型的节点没有任何子节点,并且每个
-
因此,对于任何具有已知依赖关系的项目(即类型P:OTHER_KNOWN ) D_1,...,D_k D 1 , . . . , D k ,我们有
或者我们也可以简单地说
以下等式也成立
注意,这里我们将W(P \rightarrow D_i) W ( P → D i )视为已通过P_{other\_known} P o t h e r _ k n o w n缩放或归一化的权重。未缩放的权重为W(P_{other\_known} \rightarrow D_i) W ( P o t h e r _ k n o w n → D i ) 。
例如,如果我们再次参考下图,我们可以看到:
-
Cypherpunk Movement->Cypherpunk Movement:SELF= 0.4 -
Cypherpunk Movement->Cypherpunk Movement:OTHERS_KNOWN= 0.6 -
Cypherpunk Movement->Cypherpunk Movement:OTHERS_UNKNOWN= 0 -
Cypherpunk Movement:OTHERS_KNOWN->Swiss direct democracy= 0.050 -
Cypherpunk Movement->Swiss direct democracy= 0.6*0.050 = 0.03
来源: deepfunding/scoring/example_output.png







{kind=link}