

了解区块链系统中键值查找的实际磁盘 I/O 成本
在实际区块链状态工作负载下对 Pebble 进行实证研究
抽象的
许多区块链分析和性能模型都假设键值(KV)存储读取操作的磁盘 I/O 复杂度为O(log N) (例如TrieDB 、 QMDB ),尤其是在使用 Pebble 或 RocksDB 等 LSM 树引擎时。这一假设源于 SST 遍历的最坏情况,即查找操作需要访问多个层级,并且在每个层级都要检查布隆过滤器、索引块和数据块。
然而,我们发现这种模型并不能反映真实世界的行为。实际上,缓存通常会保存大部分的过滤块和索引块,这可以显著减少 I/O 操作。
为了解基于 LSM 的数据库在实际缓存条件下的磁盘 I/O 行为,我们使用 Pebble 作为代表性引擎进行了大量的受控实验,数据集大小从22 GB 到 2.2 TB ( 2 亿到 200 亿个键),结果表明:
- 一旦布隆过滤器(不包括LLast )和Top-Index都加载到缓存中,大多数否定查找将不会产生磁盘 I/O ,并且每次 Get 操作的 I/O 次数会迅速下降到 ~2。
(读取 1 个索引块和 1 个数据块)。 - 当所有索引块都能放入缓存时,每次 Get 操作的 I/O 次数将进一步收敛到~1.0–1.3 ,并且很大程度上与数据库总大小无关。
- 在纯随机读取工作负载下,数据块缓存对整体 I/O 的影响微乎其微。
总体而言,当缓存足以容纳布隆过滤器(不包括 LLast)和 Top-Index 时,情况就是如此。
在类似区块链的工作负载下,Pebble 的磁盘 I/O 性能仅占数据库总大小的约 0.1%–0.2% ,对于随机读取操作,其磁盘 I/O 性能表现出有效的 O(1) 特性,这挑战了常见的磁盘 I/O 性能。
假设每次键值查找都必然消耗O(log N)次物理 I/O。这会对区块链 trie 数据库和执行层存储系统的性能建模和设计产生直接影响。
动机
区块链执行层通常依赖于 LSM 树键值存储来处理数十亿个随机访问的密钥。一个常见的假设是:
“LSM 树中每次 KV 查找的成本为
O(log N)磁盘 I/O。”
然而,在实际的区块链系统中,这些假设往往并不成立。现代基于 LSM 的键值引擎(例如 Pebble)严重依赖于:
- 布隆过滤器可以消除大部分否定查找;
- 小型、高度可重复使用的索引结构;
- 块缓存和操作系统页面缓存将频繁访问的元数据保存在内存中。
因此,KV 查找的实际物理 I/O 行为通常受限于一个很小的常数(≈1-2 次 I/O),并且一旦布隆过滤器和索引块能够放入缓存,它就很大程度上与数据库总大小无关。
这些观察结果引出了一个重要的实际问题:
在实际的区块链场景中,随机键值查找的实际磁盘 I/O 成本是多少?
本研究旨在通过直接的实证测量来回答这个问题,以便:
- 验证或质疑常见的
O(log N)KV 查找假设, - 量化实现近乎恒定的读取 I/O 实际需要多少缓存,
- 为区块链执行层持久键值存储后端(包括状态存储和快照键值存储)提供经验缓存大小建议。
我们如何验证假设
本节描述了我们如何验证我们的假设:在实际缓存条件下,Pebble 的实际读取 I/O 成本主要取决于元数据的缓存驻留时间,而非如最坏情况 O(log N) 模型所预测的那样取决于 LSM 树的深度。我们首先分析 Pebble 的读取路径,以确定具体的 I/O 来源;然后引入两个由缓存驱动的拐点,用于表征读取行为中 I/O 成本的变化;最后,我们概述了用于实证观察这些阶段并量化其对每次 Get 操作 I/O 次数影响的实验设置。
了解卵石
Pebble 读取路径和 I/O 源
Pebble 中的Get操作按以下步骤进行:
1. Lookup MemTable / Immutable MemTables and return value if found ( in memory) 2. Lookup MANIFEST to find candidate SST files ( in memory) 3. For each SST:a) Load Top - level index at reader initialization (used to locate internal index blocks after filter check )b) Table - level Bloom filter check ( except LLast) → skip SST if key absentc) Internal index block lookup → locate data blockd) Data block lookup → read value and return上述读取路径引用了本文中出现的几个内部组件。为了清晰起见,我们在此简要介绍一下这些组件。
顶级指数(简称顶级指数)
每个 SST 的极小顶级索引指向内部索引块。
几乎每次查找都会用到它,而且通常会完全缓存。
内部索引块(简称索引块)
每个 SST 中的索引块将键范围映射到数据块。
在成功通过筛选检查后即可访问它们,如果未进行缓存,则可能会产生一次磁盘 I/O。
最后
LSM树的最深层。它存储了大部分数据,并且在查找过程中不使用布隆过滤器。
因此,到达 LLast 的查找遵循完整路径:顶级索引 → 索引块 → 数据块。
为什么筛选条件会排除 LLast
为 LLast 设置布隆过滤器会非常庞大,缓存成本高昂,而且在实践中收益有限,因为大多数正例查找最终都会探测 LLast。因此,Pebble不会使用布隆过滤器来查找 LLast。
两个实际缓存拐点
从上述读取路径可以看出, Get操作会反复查询一组定义明确的小型元数据组件。这些组件是否驻留在缓存中直接决定了读取路径的哪些部分会产生物理 I/O。基于此观察以及每个元数据类的缓存占用总量,我们定义了两个缓存大小阈值(称为缓存拐点),它们将作为后续章节分析读取 I/O 行为的基础。
拐点 1 — Filter + Top-Index
缓存可以容纳:
- 所有布隆过滤器(非LLast)
- 所有 Top-Index 块
→ 否定查找几乎总是在内存中解决。
拐点 2 — Filter + All-Index
缓存可以容纳:
- 所有布隆过滤器(非LLast)
- 所有级别的所有索引块
→ 正向查找避免索引未命中,并接近最小 I/O。
组件定义
- 过滤器:所有非 LLast级别的 Bloom 过滤器
- 顶级索引:所有顶级 SST 索引块
- 所有索引:顶层索引 + 所有内部索引块
缓存驱动的读取 I/O 行为的三个阶段
根据上面定义的两个缓存拐点,我们将缓存大小划分为三个阶段,并描述每个阶段的预期读取 I/O 行为。
第一阶段——
Cache Size < Inflection Point 1
过滤器和顶部索引未命中频繁 → 许多不必要的 SST 检查 →更高的预期读取 I/O 成本。第二阶段——
Inflection Point 1 < Cache Size < Inflection Point 2
过滤器和 Top-Index 被缓存 → 否定查找主要在内存中解决 → 随着索引块开始驻留在缓存中,读取 I/O预计会减少。第三阶段——
Cache Size > Inflection Point 2
过滤器和所有索引块都被缓存 → 剩余的 I/O预计主要来自数据块→ 超过这一点收益递减。
实验装置
本节描述了用于评估 Pebble 在类似区块链工作负载下实际随机读取 I/O 性能的实验方法。它总结了实验环境、数据集、工作负载以及用于测量缓存驻留时间和每次 Get 操作 I/O 次数的指标,重点关注稳态随机读取性能。
硬件和软件
- CPU:32个核心
- 内存:128 GB
- 磁盘:7 TB NVMe RAID0
- 操作系统:Ubuntu
- 存储引擎:Pebble v1.1.5
注意:所有实验均在 Pebble v1.1.5 上进行。Pebble v2+ 的读取路径行为、过滤器布局或缓存行为可能有所不同,应单独评估。
所有基准测试代码、Pebble 仪器数据和原始实验日志均已公开。
可在bench_kvdb上查看,以便进行复现。
数据集
| 数据集 | 小的 | 中等的 | 大的 |
|---|---|---|---|
| 钥匙 | 2亿把钥匙 | 2B 钥匙 | 20B 钥匙 |
| 数据库大小 | 22 GB | 224 GB | 2.2 TB |
| 文件数量 | 1418 | 7105 | 34647 |
| 筛选器 + 顶部索引 | 32 MB (0.14%) | 284 MB (0.12%) | 2.52 GB (0.11%) |
| 筛选(包括 LLast) | 238 MB | 2.3 GB | 23 GB |
| 所有索引 | 176 MB | 1.7 GB | 18 GB |
| 筛选器 + 全索引 | 207 MB (0.91%) | 2.0 GB (0.89%) | 20.5 GB (0.91%) |
密钥:32 字节哈希值
值:110 字节(大约是 geth trie 节点的平均 RLP 大小)
工作量
- 纯随机读取
- 每次测试 1000 万次获取操作
- 热身:0.05% 的键空间
- 不进行范围扫描
- 没有并发的大量写入或压缩操作
笔记。
所有实验都侧重于单个节点上的稳态纯随机读取工作负载,没有并发的大量写入、压缩压力或范围扫描。
指标
我们依靠 Pebble 的内部统计数据来描述阅读行为,包括:
- 布隆过滤器命中率
- 顶级指数命中率
- 索引块命中率
- 数据块命中率
- 总体块缓存命中率
- 每次获取操作的 I/O 次数——最终目标指标
在 Pebble 中, Get操作期间的所有块读取(过滤器、Top-Index、索引和数据块)
所有请求都通过块缓存进行路由。每次查找都会首先查询缓存,如果块缓存未命中,通常只会导致一次底层物理读取,且预读和压缩的干扰极小。
其中BlockCacheMiss是所有块类型中块缓存未命中的总数。
(布隆过滤器、Top-Index 块、索引块和数据块), GetCount是已完成的Get操作的数量。
因此, BlockCacheMiss能够紧密跟踪实际的物理读取压力,并提供稳定、与实现一致的每次查找 I/O 成本度量。
结果
我们首先分析缓存大小如何影响布隆过滤器、Top-Index 块和索引块的命中率。然后,我们展示这些影响如何转化为整体块缓存命中率,并最终转化为每次 Get 操作的 I/O次数指标。
在本节中,拐点 1 (IP1)指的是保存所有非 LLast Bloom 过滤器和 Top-Index 块所需的缓存大小(在我们的基准数据集中约为数据库大小的 0.11%–0.14% ),而拐点 2 (IP2)指的是保存所有非 LLast Bloom 过滤器和所有索引块所需的缓存大小(在我们的基准数据集中约为数据库大小的 0.9% )。
布隆过滤器和顶级索引命中率
| 缓存大小 | 小数据集 (筛选命中率) | 中等数据集 (筛选命中率) | 大型数据集 (筛选命中率) | 小数据集 (顶级指数命中率) | 中等数据集 (顶级指数命中率) | 大型数据集 (顶级指数命中率) |
|---|---|---|---|---|---|---|
| 在 IP1 | 98.5% | 99.6% | 98.9% | 96.4% | 97.8% | 95.4% |
| 超出 IP1(≈0.2% DB) | 100% | 100% | 100% | 100% | 100% | 100% |
一旦缓存超过拐点 1 ,布隆过滤器和顶级索引的命中率都接近 100%,并且否定查找在内存中得到解决。
索引块命中率
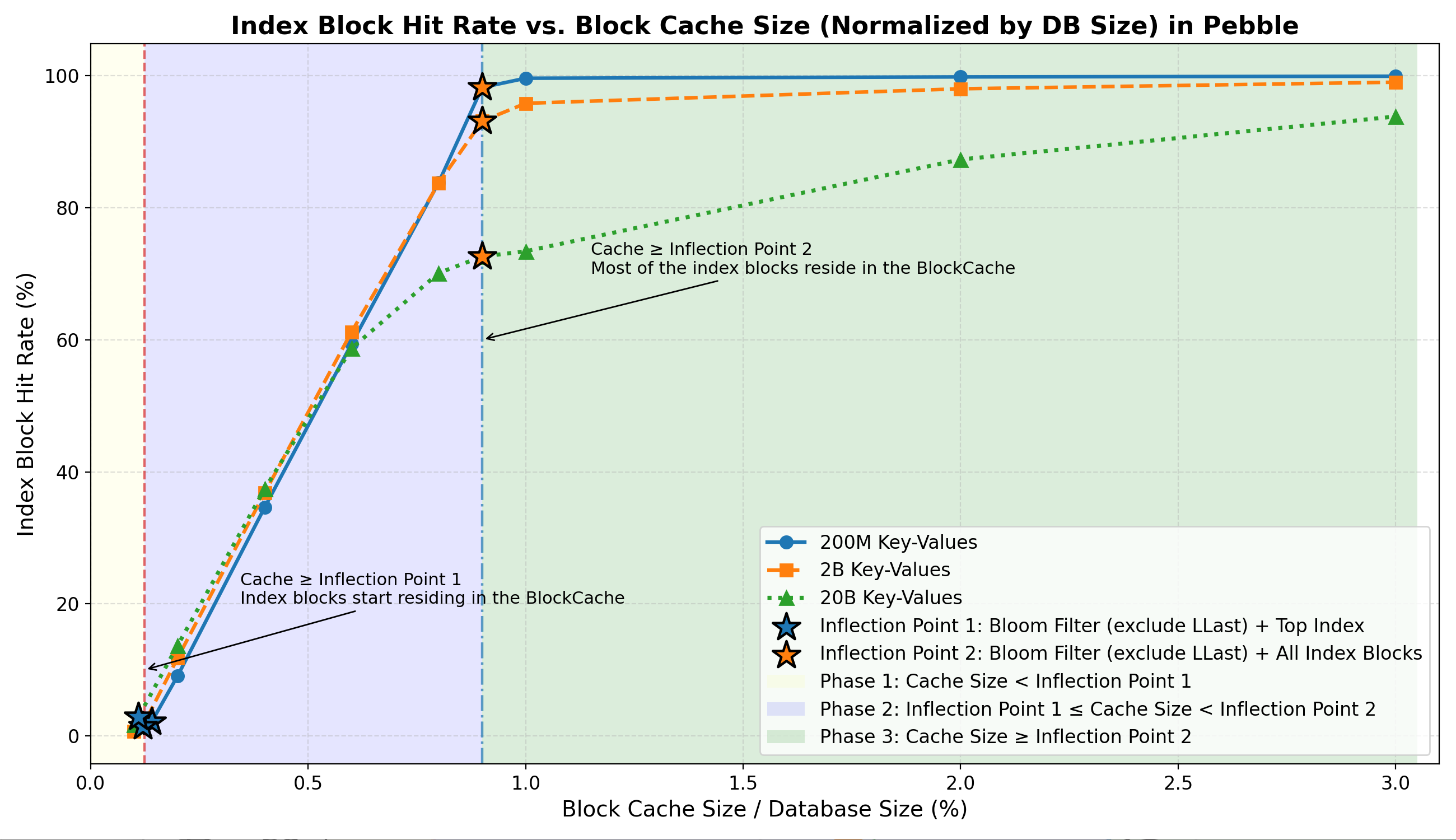
- 第一阶段:缓存的索引块非常少(可能约 1%–3% )。
- 第二阶段:随着缓存接近拐点 2,索引命中率急剧上升至约 70-99%。
- 第三阶段:大部分索引块驻留在内存中,命中率达到一个较高的平台期(~70%–99%),之后只有很小的提升空间。
数据块命中率
| 缓存大小 | 小数据集 (数据块命中率) | 中等数据集 (数据块命中率) | 大型数据集 (数据块命中率) |
|---|---|---|---|
| 在 IP1 | 1.0% | 0.7% | 1.3% |
| 超出 IP1(≈0.2% DB) | 1.2% | 0.9% | 1.6% |
| 在 IP2 | 1.4% | 1.1% | 2.4% |
| 超出 IP2(≈3% DB) | 3.2% | 3.0% | 4.3% |
在所有三个阶段中,数据块命中率始终很低,数据块缓存对随机读取工作负载中观察到的 I/O 减少贡献甚微。
总体块缓存命中率
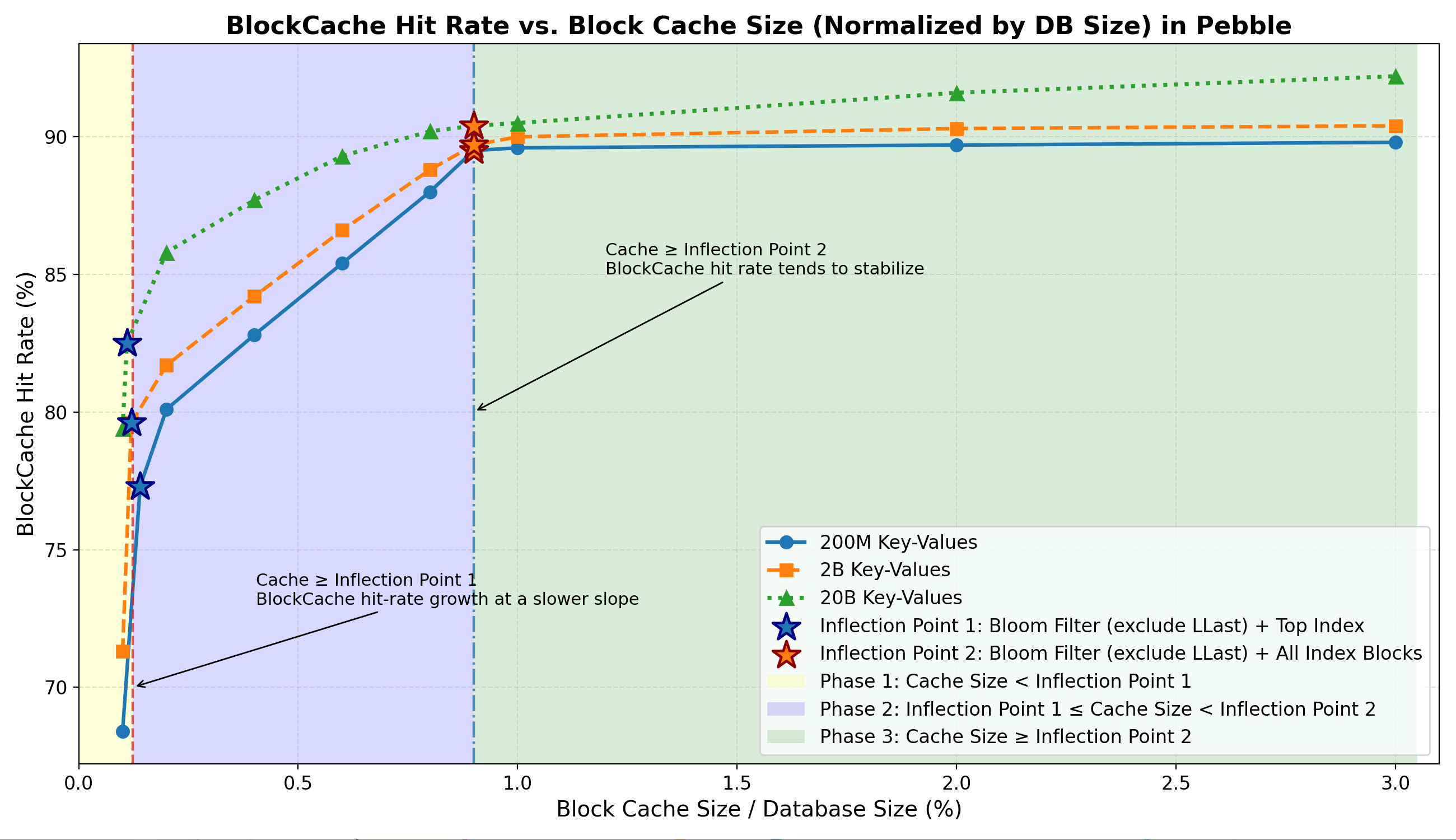
- 第一阶段:命中率急剧上升,这是由于布隆过滤器和顶级索引在内存中的快速驻留所致。
- 第二阶段:由于索引块驻留,命中率增长速度放缓。
- 第三阶段:命中率趋于稳定,因为在随机读取工作负载下,数据块缓存的贡献很小。
每次获取的读取 I/O 成本(关键结果)
本节总结了不同元数据组件的缓存驻留最终如何转化为端到端随机读取 I/O 成本。
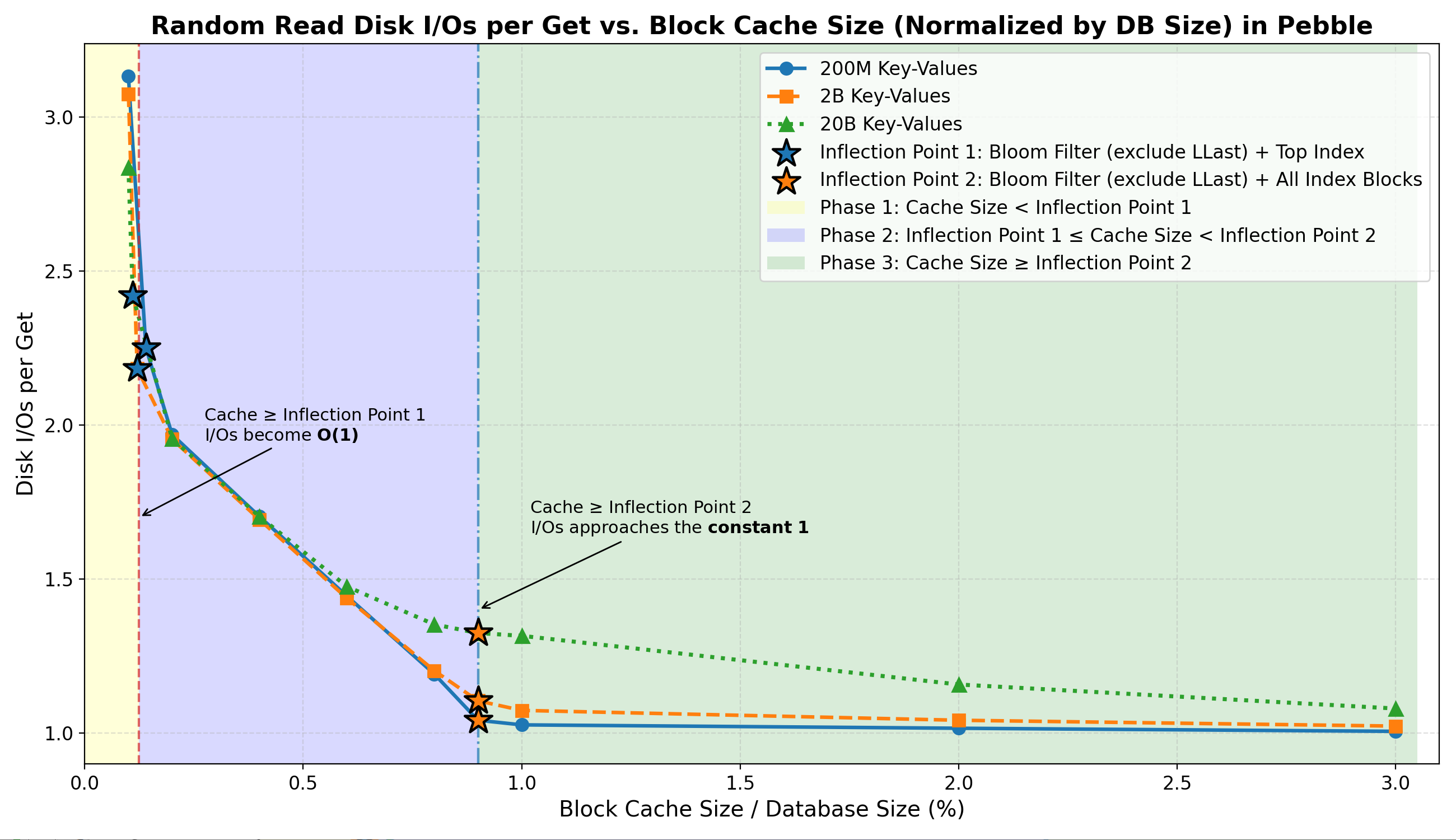
- 拐点 1(
Filter + Top-Index)
当缓存到达这一点时:- 筛选和热门索引命中率达到~100% 。
- 大多数否定查询完全在内存中完成。
-
I/Os per Get稳定在 ~2.2–2.4(有效 O(1) 查找)。
- 第二阶段(两个拐点之间)
在这个过渡区域:- 索引块驻留率迅速增长,索引块命中率急剧上升至约 70%–99% 。
- 每 Get 的 I/O 次数急剧下降至 1.0–1.3。
- 拐点 2(
Filter + All-Index)
再往后:-
I/Os per Get次数接近紧下限 ~1 。 - 进一步增加缓存容量只会带来微乎其微的 I/O 减少。
-
- 在所有阶段,数据块缓存都微不足道。
- 不同数据集大小(22 GB – 2.2 TB)的行为一致:
这证实了:
总体而言,随机读取 I/O 主要受布隆过滤器和索引驻留的限制。
结论与建议
虽然 Pebble 的理论最坏情况读取复杂度为O(log N) ,但在实际的缓存配置下,这一界限在实践中很少能观察到。
如果布隆过滤器(不包括 LLast)和索引块有足够的缓存驻留时间,Pebble 的实际读取 I/O 行为实际上是 O(1) ,并且每次 Get 操作都会稳定地收敛到 1-2 次 I/O 。
缓存配置建议
我们的结果表明,Pebble 的读取 I/O 开销主要取决于哪些元数据组件适合缓存,而不是 LSM 树的深度。因此,在实践中,可以直接根据所需的读取性能来选择缓存大小。
读取性能接近恒定(每次 Get 操作约 2 次 I/O)
缓存超过拐点 1 (布隆过滤器排除 LLast + Top-Index 块)。
这只需要一个很小的缓存(通常小于数据库大小的 0.2% ),并消除了大部分否定查找 I/O。
适用于内存受限且需要可预测读取性能的部署环境。接近单次 I/O 读取(每次 Get 操作约 1.0–1.3 次 I/O)
缓存超过拐点 2 (布隆过滤器 + 所有索引块)。
这只需要一个较小的缓存(通常小于数据库大小的 1.5% ),并且使读取次数接近实际的下限。
适用于对延迟要求严格的执行层和读取密集型工作负载。
超过拐点 2后,在随机读取工作负载下,进一步增加缓存大小只能提供微乎其微的 I/O 减少。






