如果我们只保留 1 年的活跃状态呢?
特别感谢 Gary Rong、Gabriel Rocheleau 和 Guillaume Ballet 对本文的审阅。
我们已经多次讨论过状态过期作为解决以太坊状态增长问题的长期方案,但很少有数据表明它会对日常节点运行产生怎样的影响。
为了使讨论更加具体,我们使用真实的主网工作负载进行了一个简单的实验:在(1)具有完整状态的节点和(2)仅保留1 年活动状态的节点上执行约 1 年的区块(基于区块执行期间实际触及的内容)。
免责声明:这并非状态过期机制的完整协议实现(没有复活见证,也没有网络检索)。这是一个“假设”性能实验:如果数据库仅包含在特定时间段内实际访问的状态,执行性能会发生什么变化?
太长不看
- 州规模下降了约78% 。
- 与主网区块过去一年左右的时间相比,区块重新执行时间缩短了约 15% 。
- 读取性能提升幅度最大,尤其是存储读取( P50 -46% , P99 -36% )。
- 尾部延迟有所改善,这对于在高负载下保持靠近头部位置至关重要( P99 块插入 -21% )。
基准测试设置
在这个实验中,我们将具有完整状态的节点与仅存储1 年活跃状态的节点进行比较。
- 客户端: go-ethereum v1.16.5
- 机器:符合EIP-7870规范
- 工作负载:执行19,999,256到22,627,956个数据块(约 1 年)
- 运行次数: 3 次,报告平均值
一年期活跃状态数据库的构建方式:
- 将区块 19,999,256 → 22,627,956 中的节点同步(“跟踪”节点)。
- 每次在区块处理期间访问状态的一部分(帐户、存储槽、trie 节点)时,将其标记为已访问。
- 从第 19,999,256 个区块的数据库开始,然后使用跟踪节点的标记删除未标记的状态。这就得到了精简后的数据库。
- 删除状态后,修剪后的数据库不会手动压缩。
注意:失败的交易仍然会触发标记(因为它们在执行尝试期间仍然会改变状态)。在实际的过期机制实现中,失败的交易可能不会被标记,这会增加非活动状态的集合。
结果
1. 州面积
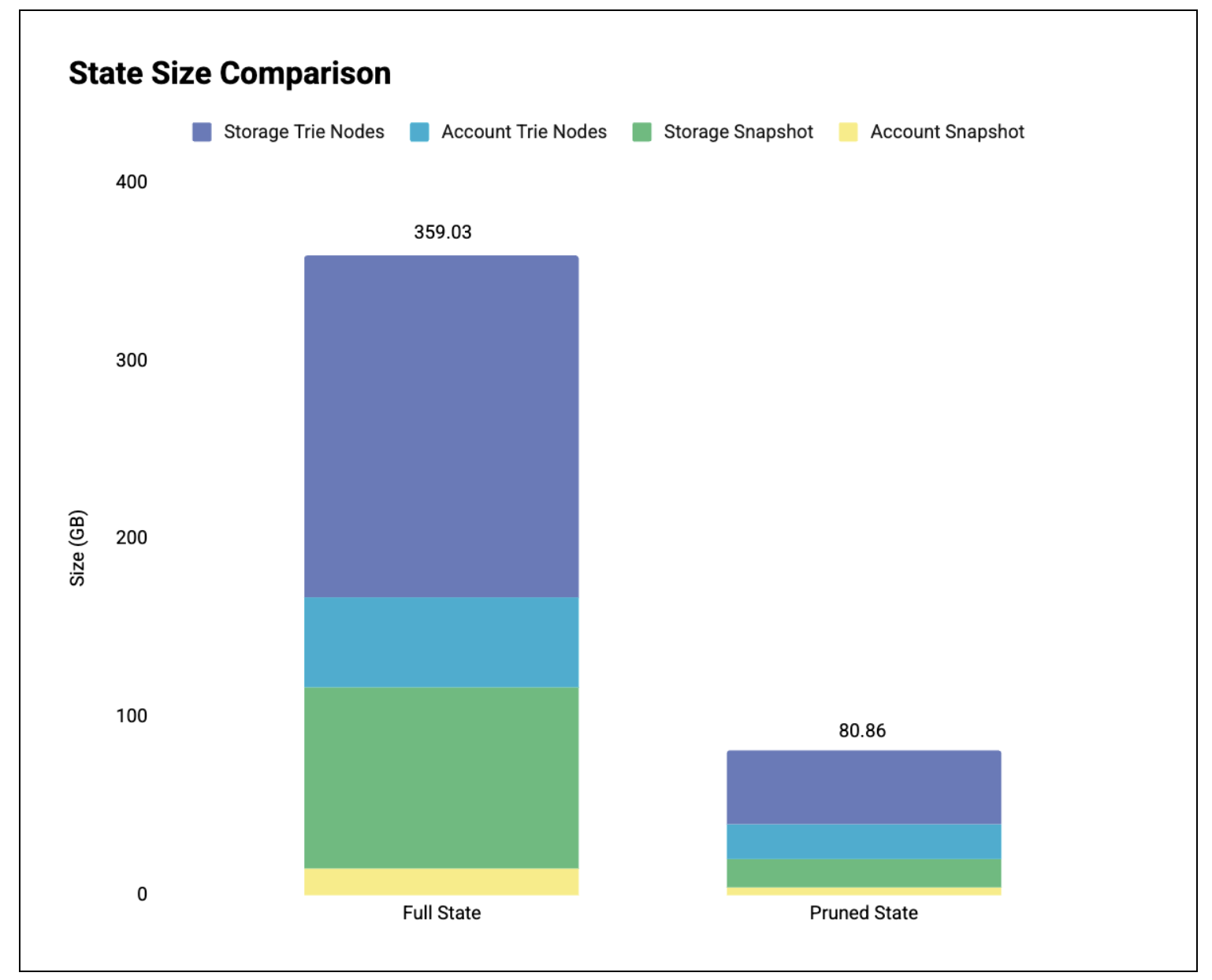
图 1:数据库中的状态大小比较。
表格明细(单位:GB):
| 完整状态 | 修剪状态 | 减少 | |
|---|---|---|---|
| 账户快照 | 14.65 | 3.60 | 75.43% |
| 账户树节点 | 50.34 | 19.89 | 60.49% |
| 存储快照 | 101.87 | 15.95 | 84.34% |
| 存储树节点 | 192.17 | 41.42 | 78.45% |
| 全部的 | 359.03 | 80.86 | 77.48% |
结果:大幅减少磁盘占用空间。
- 完整状态: 359.03 GB
- 精简后状态: 80.86 GB ( -77.5% )
大部分资源占用减少都来自存储树节点。这反映了存储树本身就比账户树大得多,因此需要修剪的节点也更多。账户树规模较小,访问密度更高:每次账户访问都会使树中更大比例的节点保持存活。这些结果也与我们之前的状态分析相符。
geth 中的“快照”是什么?
在 geth 中,快照是 trie 树叶子节点(账户和存储)的扁平化表示,旨在加速读取操作,而无需遍历 trie 树路径。它们主要是一种读取优化结构。
2. 端到端执行时间
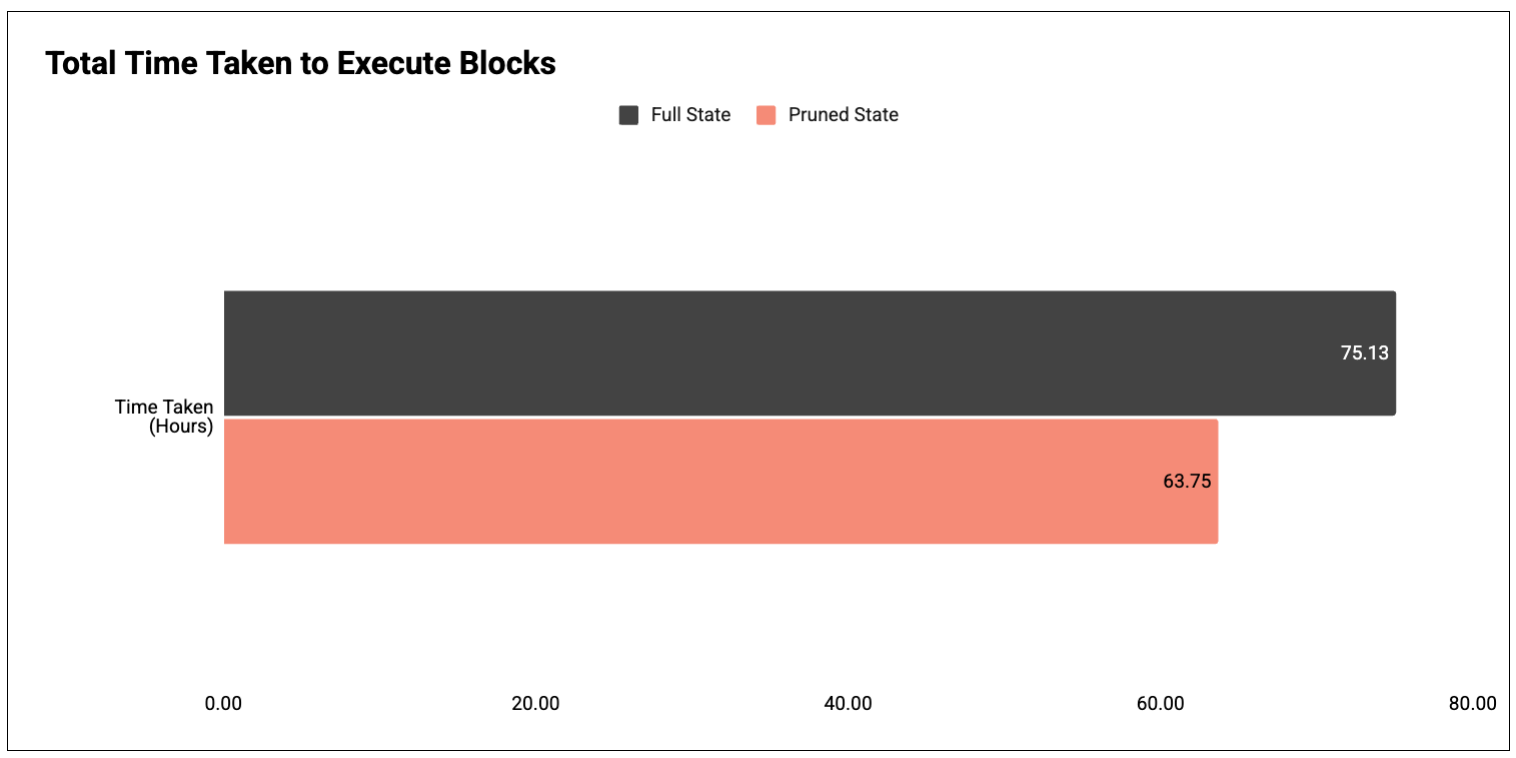
图 2:执行第 19,999,256 至 22,627,956 个块所花费的总时间。
结果:修剪后的节点比未修剪的节点运行速度快约 15% 。
- 完整状态: 75.13 小时
- 修剪后状态: 63.75 小时( -15% )
3. 块插入和预取
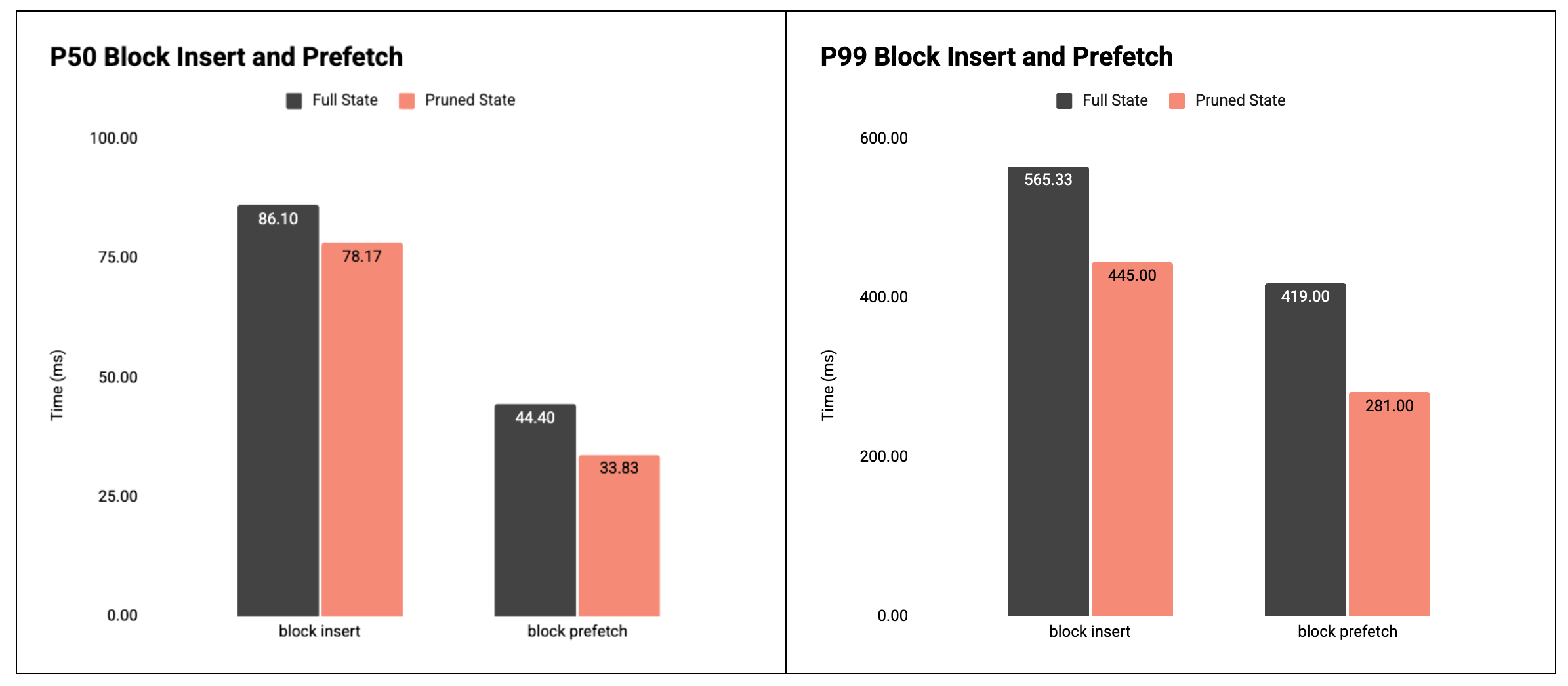
图 3:块插入和块预取的 P50 和 P99 时间。
结果:精简后的数据库在块插入和预取方面速度更快,尤其是在 P99 时。
- 块插入(执行路径):
- P50:86.10毫秒 → 78.17毫秒( -9% )
- P99:565.33毫秒 → 445.00毫秒( -21% )
- 块预取:
- P50:44.40毫秒 → 33.83毫秒( -24% )
- P99:419.00毫秒 → 281.00毫秒( -33% )
geth 中的“prefetch”是什么?
Geth 运行一个并行预取器,该预取器执行事务来了解需要哪些状态,将这些对象拉入内存,然后丢弃更改。其目标是预热缓存,以便实际执行(包括状态根计算)更频繁地访问内存,从而减少磁盘 I/O。
在实际应用中,预取性能在 geth 中尤为重要。预取器会并发执行事务,并且频繁地需要从底层数据库解析状态,这类似于我们预期从块级访问列表 (BAL) 中获得的访问模式。相比之下,在块执行期间,大多数状态访问都会命中缓存,因此即使性能提升幅度很小,也难以察觉。
总体而言,预取功能的改进凸显了从数据库中移除非活动状态的好处。
4. 状态读取和更新
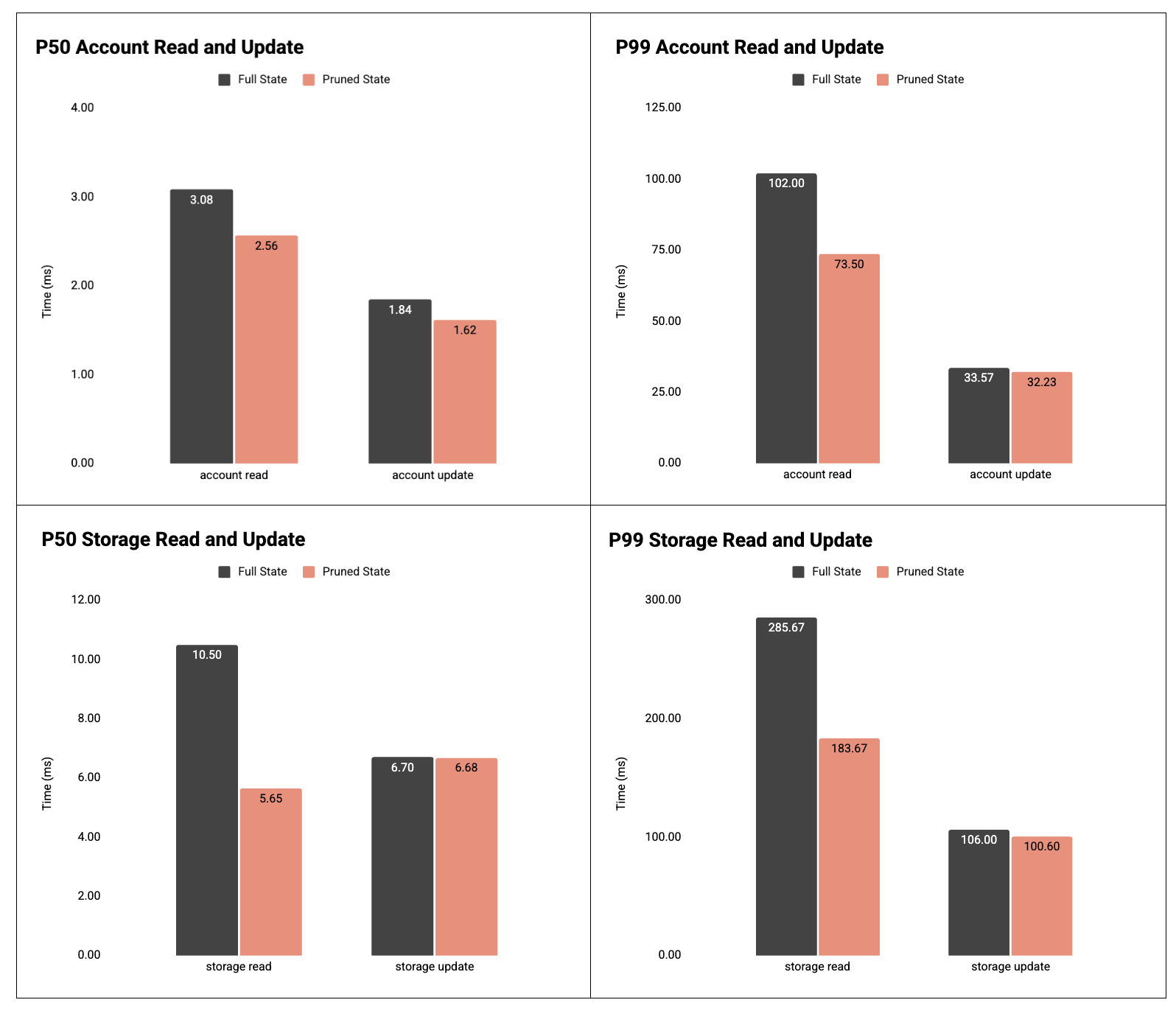
图 4:P50 和 P99 读取/更新帐户和存储槽的时间。
结果:账户和存储读取性能显著提升。
- 账户已读:
- P50:3.08毫秒 → 2.56毫秒( -17% )
- P99:102.00毫秒 → 73.50毫秒( -28% )
- 账户更新:
- P50:1.84毫秒 → 1.62毫秒( -12% )
- P99: 33.57ms → 32.23ms ( -4% )
- 存储读取:
- P50:10.50毫秒 → 5.65毫秒( -46% )
- P99: 285.67ms → 183.67ms ( -36% )
- 存储更新:
- P50:6.70毫秒 → 6.68毫秒(基本持平)
- P99:106.00毫秒 → 100.60毫秒( -5% )
这与The Block插入/预取的结果一致。更新操作的改进有限,因为 geth 已经在交易执行期间预取了所需的 trie 节点,并在预取完成之前一直阻塞。因此,trie 更新完全在内存中执行,只是简单地将状态更改放入 trie 的相应位置。
主要发现和启示
- 州规模大幅缩减
精简后的状态大小缩小了约 4.4 倍,从 359 GB 缩减到 81 GB。这种缩减显著降低了节点运营商的存储和 I/O 负担,并将“合理的硬件要求”推向了更容易实现的方向。
此次资源缩减主要集中在存储 trie 节点和存储快照上,这表明以太坊的大部分状态都存储在冷合约中。如果大部分节省来自存储,那么状态过期机制的一个潜在路径是优先考虑合约过期存储的解决方案。这条路径不会影响账户,从而避免了一些显而易见的用户体验风险(例如,账户意外需要恢复),同时又能获得大部分过期收益。缺点是,我们可能会引导用户将账户用作合约存储,以避免过期,最终我们可能需要同时实现账户级和槽位级的过期机制。
- 减少状态大小 = 加快执行速度。
缩小状态规模主要通过降低从磁盘检索状态的成本来提升区块处理效率。在主网区块的同一年内,端到端执行时间缩短了约 15%。微观指标也印证了这一点:最大的提升体现在读取操作上,尤其是存储读取操作。
这与基于局部集模型(LSM)的数据库的预期相符:较小的数据集往往能提高局部性。实际上,这在两个方面都创造了提升空间。我们可以提高 gas 限制,并且如果状态大小得到控制,我们还可以降低状态操作的成本。
- 改善尾部延迟
除了平均速度提升之外,更重要的运营成果是尾部行为的改善。精简后的数据库大幅降低了区块插入和预取的 P99 延迟,这意味着验证过程中长时间的停顿次数减少。这些停顿通常是导致节点在突发性工作负载下间歇性落后于链首的原因。
这对州的发展意味着什么?
我们的实验表明,如果以太坊能够安全地将本地存储的状态限制在最近访问数据的滚动窗口中,客户端将受益于:
- 降低硬件要求。
- 需要更大的空间来实现更高的吞吐量,因为目前状态操作是一个主要瓶颈。
- 由于尾延迟降低,负载下的弹性更好。
然而,缺失的部分在于状态过期机制的实际实现。无论是在协议内还是协议外,由于需要标记、删除和恢复过期状态,都会产生额外的延迟。我们使用主网工作负载进行的实验显示出了积极的结果,但对于任何具体的过期方案,都需要对这些权衡进行端到端的评估。
未来工作
- 衡量在最坏情况下,修剪非活动状态如何有所帮助(或失败)。
- 对其他EL客户重复基准测试,并比较结果。
- 探索不同的到期规则(例如 6 个月到期期、仅修剪合约存储、仅修剪帐户),并查看基准测试结果有何不同。