特别感谢 Guillaume Ballet、Marius van der Wijden、Jialei Rong、CPerezz、Han、soispoke、Justin Drake、Maria Silva 和 Anders Elowsson 的反馈和审阅。
为了在未来五年内扩展以太坊,我们需要扩展三种资源:执行(EVM 计算、签名验证等)、数据(交易发送方、接收方、签名、调用数据等)和状态(账户余额、代码、存储)。我们的目标是将以太坊的容量扩展约 1000 倍。但是,前两种资源与第三种资源之间存在着根本性的不对称性。
| 短期 | 长期 | |
|---|---|---|
| 执行 | ePBS、区块级访问列表 (BAL) 和 gas 重新定价 →增长约 10-30 倍 | ZK-EVM(大多数节点可以完全避免重复执行区块)→性能提升约 1000 倍 对于某些特定类型的计算(例如签名计算、SNARK/STARK 计算),链下聚合可以将性能提升约 10000 倍。 |
| 数据 | p2p 改进,多维气体 →增长约 10-20 倍 | 块存储 + PeerDAS → 8 MB/秒(约 500 倍提升) |
| 状态 | 与 BAL 同步、P2P 改进、数据库改进 →性能提升约 5-30 倍 | ? |
短期内,我们可以提高这三种资源的效率。但要实现长期所需的1000倍提升,我们需要一些“灵丹妙药”。ZK-EVM是执行效率的“灵丹妙药”,PeerDAS是数据效率的“灵丹妙药”,但状态管理方面却没有这样的“灵丹妙药”。那么,我们该怎么办?
本文提出了一个雄心勃勃的解决方案:除了对当前状态进行渐进式改进(例如二叉树、叶子过期)以及对多维 gas 等进行定价改进之外,我们还在现有状态之外引入了新的(更便宜但限制性更强的)状态形式。
主要的权衡之处在于,如果我们把状态增长的“目标”水平设定为例如今天的 20 倍,执行速度的“目标”水平设定为今天的 1000 倍,那么执行速度和存储速度之间的“相对价格”将与现在相比发生巨大变化。创建一个新的存储槽位可能真的比验证一个 STARK 验证还要贵(!!)。很可能两者都很便宜,但人们对哪种更便宜的认知模型将会发生巨大改变。
因此,开发者将面临选择:如果他们继续沿用目前的应用开发方式,则可以获得相对较低的交易费用;或者,如果他们重新设计应用以利用新型存储方式,则可以获得极低的交易费用。对于常见用例(例如 ERC20 余额、NFT),将会有标准化的工作流程。而对于更复杂的用例(例如 DeFi),开发者则需要自行摸索出针对特定应用的技巧。
为什么我们不能将现有状态放大 10-20 倍以上?
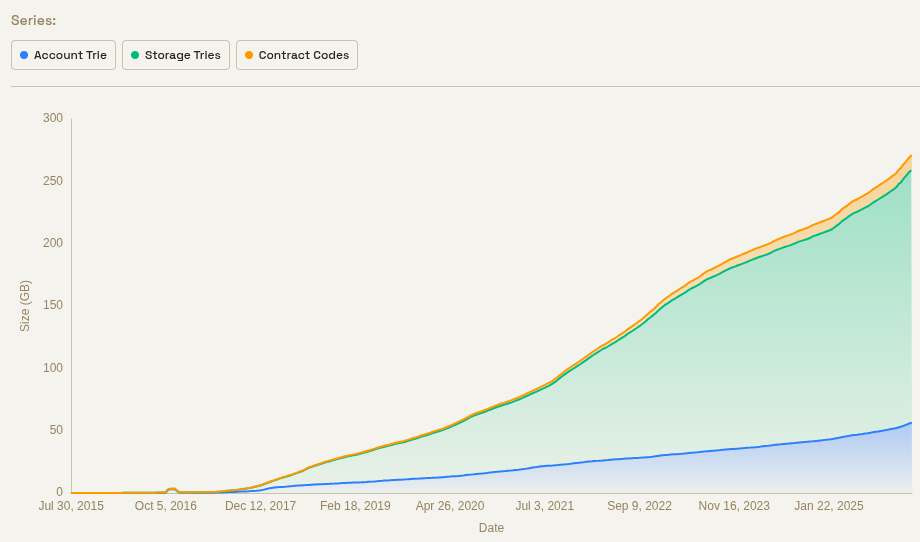
目前,状态数据正以每年约 100 GB 的速度增长。如果增长 20 倍,则每年增长 2 TB。4 年后,状态数据的大小将达到 8 TB。
完全验证节点无需存储此状态(因为它们可以通过 ZK-EVM + PeerDAS 获取所需的一切),FOCIL 节点也无需存储(VOPS 的容量要小得多;即使没有任何更改,容量也将低于 1 TB,很可能低于 512 GB 甚至 256 GB,而且还可以进一步优化)。但构建者(不仅是高级构建者,也包括运行“原生”软件的本地“家庭构建者”)需要它。
在磁盘上存储 8TB 数据本身并不难。我们可能需要一些技巧,比如只存储部分“热”状态数据,并对其他部分收取额外的 gas 费用,以便将它们存储在平面文件而不是数据库中。但归根结底,8TB 的磁盘很容易获得。难点有两个:一个是短期的,一个是长期的。
- 短期目标:数据库效率。目前客户端的数据库并非为处理数TB级的状态而设计。如今的一个主要问题是,状态写入需要对树进行log(n)次更新,而每次更新本身在数据库中也需要log(n)次操作,一旦n远大于内存,具体的计算量就会迅速增长。目前已经有一些数据库设计方案可以解决这个问题;它们只需要进一步完善并得到广泛应用。
- 长期目标:同步。我们希望构建过程无需权限,且设置简便。即使效率完美,同步 8TB 的数据也需要很长时间,而且在很多情况下甚至会达到每月带宽限制。
除了上述问题之外,还有状态同步的来源、RPC节点的运行者以及其他诸多问题。粗略估计,状态大小每翻一番,愿意无私地(甚至有偿地)使用状态的参与者数量就会减少一半。数据库效率的提升,例如使用HDD和平面文件代替SSD和数据库等等,只能部分解决部分问题,而对另一些问题则完全无济于事。
与数据和计算不同,这些领域并非我们可以说“我们依赖专业建造者来扩大规模,如果他们全部消失,普通建造者也可以建造只有原来10%大小的方块”的领域。要建造一个方块,你需要完整的状态信息。降低gas限制并不会缩小状态信息的大小。
这意味着 (i) 我们需要对状态比对计算和数据更加保守,(ii) 许多适用于计算和数据的“分片”技术并不适用于状态存储。
为什么强无国家状态可能不足以解决问题
解决此问题的一个主要策略是强无状态性。我们要求进行交易的用户:(i) 指定其交易读取和写入的账户和存储槽位,并规定任何超出此范围的读取或写入操作都将失败;(ii) 提供 Merkle 分支以证明其状态访问。
如果我们这样做,就不再需要构建者来存储完整的状态。相反,用户自己可以存储与自身使用相关的状态(以及更新后的证明),或者由去中心化网络来存储状态(例如,每个节点可以随机保留 1/16 的状态)。
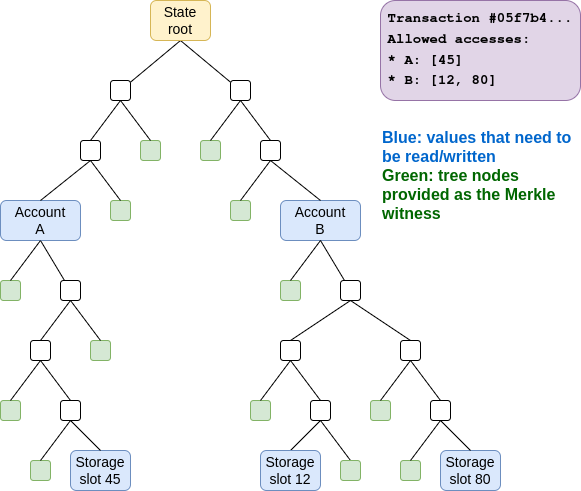
这种方法有三个主要缺点:
- 链下基础设施依赖性:实际上,用户无法存储与其自身使用相关的状态和证明,因为“与其自身使用相关”的内容会不断变化,而且许多用户无法始终在线下载更新的分支。因此,我们需要一个去中心化网络来进行状态存储和检索。这也会对用户的隐私造成影响。
- 向后不兼容:访问存储是交易执行动态函数的应用,从根本上来说与绑定访问列表不兼容。这可能包括链上订单簿、可追加列表以及许多其他类型的结构。对于这些应用,用户需要在本地进行模拟,创建访问列表,然后大部分情况下,链上交易会失败(同时消耗 gas),用户不得不反复重试。
- 带宽成本:每次访问存储槽位,交易都需要提供约 1000 字节的证明。这将大大增加交易大小(例如,一个简单的 ERC20 转账可能需要 4 kB 的见证数据:一个分支用于发送方账户,一个用于 ERC20 代币,一个用于发送方余额,一个用于接收方余额,而目前仅需约 200 字节)。
弱化版的强无状态概念被称为“冷状态”。其核心思想是,某些状态(例如,一年以上未被访问的状态)仍然可以访问,但存在异步延迟(实际上,延迟时间介于一秒到一格之间)。这样,构建者无需实际存储这些状态即可运行,因为每当需要读取数据时,他们都会向去中心化网络请求数据。
这个方案或许可行,但由于其对基础设施的依赖性过强,因此非常脆弱,而且同样存在向后不兼容的问题。在最坏的情况下,某些事务会涉及复杂的多跳依赖关系图,需要经过不同的冷状态区域:调用 A,根据其输出结果调用另一个地址 B,根据 B 的输出结果调用另一个地址 C……
为什么状态过期机制很难实现向后兼容?
过去十年间,人们一直在尝试提出状态过期机制:这种设计会将长时间未被访问的状态自动从活动状态中移除,而想要继续使用该状态的用户必须主动“恢复”它。
这些设计都不可避免地会遇到一个问题:当你创建一个新的状态时,如何证明之前那里从来没有任何东西?
如果你在地址 X 创建一个账户,你必须证明在地址 X 上没有创建过任何其他东西,不仅是今年或去年,而是以太坊历史上的每一年。
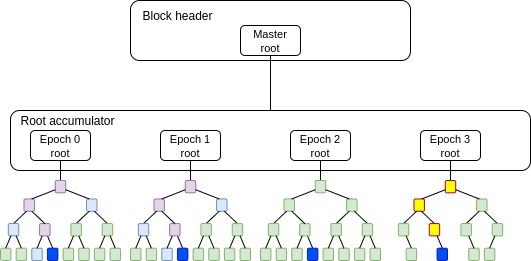
如果我们每年创建一个新树来表示该年修改的状态(“重复再生”),那么在第 N 年创建一个新帐户需要 N 次查找。
为了缓解这个问题,我们提出了一种地址周期机制:我们添加了一个新的账户创建规则集(“CREATE3”),允许您创建一个仅在年份 >= N 时有效的地址。当您创建这样的账户时,无需为任何年份 < N 提供证明,因为在那些年份不可能存在这样的账户。
然而,一旦我们尝试将这种设计集成到以太坊的实际环境中,就会发现它存在重大局限性。尤其需要注意的是,对于每个新账户,我们不仅需要创建账户,还需要创建存储槽位。如果您创建了一个名为 X 的新账户,那么对于您想要持有的每个代币,您都必须为 X 创建相应的 ERC20 余额。更糟糕的是,现有的 ERC20 代币无法“理解”地址周期机制:即使以太坊协议可能理解,一个地址通过某种新的地址生成机制编码了“2033”的账户 X 不可能创建于 2033 年之前,但 X 余额的存储槽位却是 sha256(…, X),这是一种协议无法理解的不透明机制。
我们可以用一些巧妙的技巧来解决这个问题。一种方法是设计新的 ERC20 代币,使其每年生成一个新的子合约,用于存储当年关联的账户余额。另一种方法是创建一种新型存储方式,这种存储方式可以由代币合约拥有,但与你的账户“共存”,因此可以与你的账户一起过期和复活。但是,这两种方法都需要 ERC20 代币合约完全重写其逻辑,因此不向下兼容。
所有旨在使状态过期机制向后兼容的尝试似乎都遇到了类似的问题,这些问题都源于缺乏有效方法来证明状态不存在。此外,遗憾的是,目前无法创建一个比当前状态更简洁或更小的“哪些地址/存储槽之前未被创建”的映射。一个映射 {32 字节键:{0,1}} 的实现复杂度与一个映射 {32 字节键:32 字节值} 的实现复杂度完全相同。
从这些探索中吸取到的经验教训
我们可以将对强无国家状态和国家消亡的研究得出的宏观教训概括为两个主要的“典型事实”:
- 将所有状态访问都替换为 Merkle 分支会占用过多带宽,而将特殊情况下的状态访问替换为 Merkle 分支是可以接受的。 “状态过期”实际上就是后者的一个例子:假设例如 90% 的状态访问访问的是六个月以内的状态,而 10% 访问的是更早的状态,那么我们可以只将最近的状态保留在“构建者必须访问”的容器中,并要求对较早的状态提供见证。这样一来,我们平均只需支付 2 倍的开销(加上原始交易),而不是 20 倍。
这种探索似乎不可避免地会得出这样的结论:我们需要分层状态:区分高价值状态(我们知道它们会被频繁访问)和低价值状态(我们预期它们会被很少访问)。分层可以通过两种方式实现:(i) 按访问时间(例如状态过期提案)进行分层;(ii) 通过显式划分不同的状态类别(例如,VOPS 就是这种分层方式的一个非常有限的版本)。 - 向后兼容非常困难。较低层级的状态不仅在某些方面(尤其是动态同步调用)操作成本更高,而且根本无法以这些方式操作。因此,如果我们想要避免彻底破坏应用程序,唯一的选择可能是将现有应用程序迁移到成本更高的状态层,并要求开发人员主动选择使用更新、成本更低的状态层。
创建新型的、成本更低的国家会是什么样子?
如果现有状态无法以向后兼容的方式失效,那么自然的解决方案就是接受缺乏向后兼容性的事实,转而采取“哑铃式解决方案”。
- 保持现有状态几乎完全不变,但允许其相对成本更高(例如,执行成本可能降低 1000 倍,但创建新状态的成本可能只降低 20 倍)。
- 创建从一开始就设计成易于实现极高可扩展性的新型状态。
在设计这些新型状态时,我们应该牢记以太坊当前状态的大部分是由哪些类型的对象构成的现实:例如 ERC20 代币和 NFT 等余额。
临时存储
一种思路是创建一种新的临时存储类型,其持续时间为中等长度。例如,我们可以创建一个新的树状结构,每当一个新的周期(例如 1 个月)开始时,该结构都会被清零。
这种存储方式非常适合处理链上事件的临时状态:例如拍卖、治理投票、游戏中的单个事件、防欺诈挑战机制ETC。它的 gas 成本可以设置得非常低,使其能够随着执行速度的提升而扩展 1000 倍。
要在这种状态下实现 ERC20 风格的余额,必然会遇到一个问题:如果有人进入山洞超过一个月会发生什么?
ERC20 的一个优点是它支持乱序恢复。例如:如果您在 2025 年收到 100 Dai ,然后忘记了,接着在 2027 年同一账户又收到 50 Dai ,最后您突然想起之前还有余额,于是恢复了余额,您将拿回 150 Dai 。您甚至无需提供任何证据证明您的账户在 2026 年是否发生过任何事件(如果您当时也收到了代币,可以稍后提供证明)。我们唯一要防止的是使用相同的历史状态两次恢复余额。
以下是复活可能运作方式的示意图:
- 作为树形设计的一部分,在每个节点中存储该节点“下方”的叶子节点总数。这样,在证明任何叶子节点时,就可以同时验证该叶子节点在树中的索引(从左到右):只需在证明中将所有左侧的姊妹节点的总数相加即可。
- 每个月,我们都会存储一个永久状态位域,删除时树中的每个值对应一位。该位域初始状态为全零。
- 如果账户 X 在第 N 个月拥有写入槽位 Y 的权限,那么在任何大于 N 的月份,该账户都可以编辑其对应的位域值。此外,任何人随时都可以提供证明。
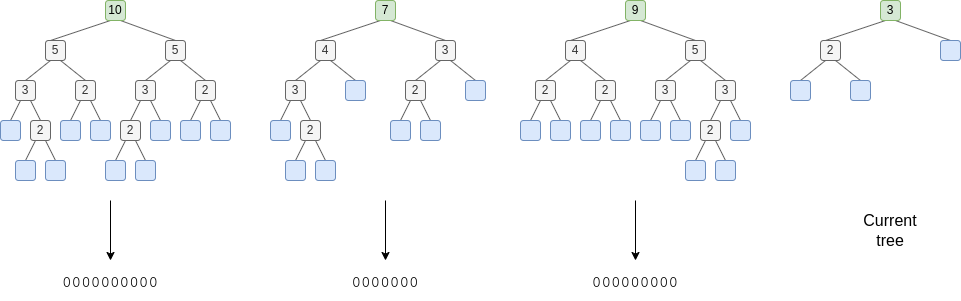
- ERC20 合约默认会将余额存储在当前树中,但它会有一个余额恢复功能,该功能以证明发送者历史状态条目的分支作为输入,并在将位从 0 翻转为 1 的同时恢复余额,因此它不能再次恢复。
如今,以太坊的状态数据每年增长约 100 GB。如果我们将以太坊的规模扩大 1000 倍,我们可以想象状态数据的增长速度也会乘以 1000,但所有数据都存储在临时树中。这意味着大约需要 8 TB 的状态数据(假设状态数据过期时间为 1 个月),再加上少量永久存储空间(每个 64 字节的状态条目占用 1 位,因此每月需要 8 TB * 1/8 / 64 = 16 GB)。
UTXO
或者,我们可以将临时存储的概念推向极致:将过期时间设为零。本质上,合约可以创建记录,这些记录会被哈希到该区块中的一棵树里,并立即进入历史记录。对于每个区块,状态中会有一个位域来存储记录是“已花费”还是“未花费”,这将是永久状态,除此之外就没什么了。
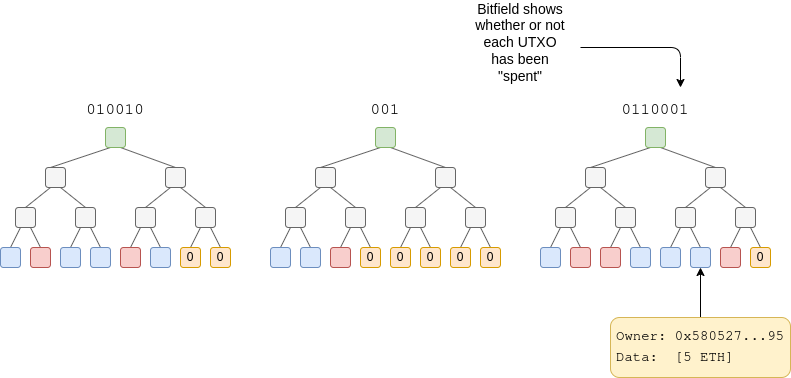
理论上,UTXO 可以通过复用现有的 LOG 机制,并在其上添加状态位域机制来构建。如果确实需要,甚至可以完全采用协议外的 ERC 方式,但这也有一些缺点:少数随机用户需要支付比其他用户高出 256 倍的费用,才能率先创建一个代表位域中 256 个字节的新存储槽。
ERC20、NFT 和各种其他状态都可以建立在这些类型的 UTXO 之上。
还有一种介于这两种方案之间的混合方案。我们使用 UTXO,但允许直接从状态访问最近一个月的树数据,无需见证人。这降低了带宽负载(但需要更大的存储空间)。与临时存储方案的主要区别在于,这里只需要一个“接口”来处理先前创建的对象(作为 UTXO),而不是两个(一个作为当前纪元的存储槽,另一个作为前一个纪元的 UTXO)。
强无状态存储树
我们还可以创建一个单一的存储树,访问该存储树需要使用默克尔分支(或者,节点需要存储其前 N-8 层,即 1/256 的大小,并且节点需要提供 256 字节的见证)。这个新的存储树将与现有的存储树并存,因此我们将拥有两个存储树:一个是需要见证且成本较低的存储树,另一个是不需要见证且成本较高的存储树。
然而,我认为这种方案不如临时存储方案。原因在于,从长远来看,如果这样一棵树的大部分内容都是被遗忘的垃圾信息,而人们只关心其中的一小部分,那么网络最坏的情况是必须存储整棵树(包括垃圾信息),最好的情况也只是存储证明有用状态的超长默克尔分支(因为树中的每个有用状态对象都会被垃圾信息“包围”)。双树设计仅允许两层存储,而临时存储设计则为在其上构建状态过期机制创造了空间,从而允许在经济分层之上叠加近期分层。
对开发者体验的影响
下面简要概述了一些应用程序和工作流程如何在这种分层架构下运行:
- 用户帐户(包括与原生 AA 关联的新的每个帐户的状态)将永久存储。因此,用户帐户可以随时以低成本且便捷的方式访问。
- 智能合约代码将全部永久存储。
- NFT、ERC20 代币余额ETC将存储在 UTXO 或临时存储中。
- 与短期事件相关的状态(例如拍卖、防欺诈游戏、预言机游戏、治理行动)将存储在临时存储中。
- 核心 DeFi 合约将永久存储,以最大限度地提高可组合性。
- 在许多情况下, defi 活动的各个单元(例如 CDP)将存在于 UTXO 或临时存储中。
初期,开发者可以继续将所有内容存入现有的永久存储中。NFT 和 ERC20 代币余额可能最容易转移到 UTXO 或临时存储中。之后,生态系统会逐步优化,以实现更高效的存储利用。
这里的基本假设是,“混合永久存储和UTXO”比“仅使用UTXO”更容易开发。以太坊作为开发者平台如此成功的一个重要原因在于,账户和存储槽位比UTXO对开发者更加友好。如果我们能够提供对开发者友好的抽象,例如,允许95%的状态使用轻松迁移到UTXO,并将剩余的5%保留为永久存储(同时允许对这种做法感到困惑的开发者以更高的成本为代价,继续使用永久存储来存储所有数据),那么我们就可以同时获得UTXO的大部分扩展性优势和以太坊式账户和存储槽位的大部分开发者友好性优势。