

Paradigm 和 OpenAI 昨天刚刚宣布合作开发EVMbench——一个旨在测试 AI 代理在模拟区块链环境中检测和利用智能合约漏洞能力的基准测试工具。尽管 EVMbench 严格来说并非强化学习环境,但其结构与之类似,稍加调整即可轻松成为强化学习环境,甚至可能用于未来模型的强化学习训练。
这项工作非常重要——全世界的人都对强化学习环境趋之若鹜,简单来说,强化学习环境就是模拟软件沙箱,模型可以在其中学习自主完成它们在现实世界中能够完成的任务。
模型能够在预训练阶段积累世界知识,通过吸收海量数据来获得通用能力。后训练阶段则能更好地培养模型在涉及多步骤任务中的推理或指令执行等能力。
RL 环境已被证明在训练后阶段能够很好地提高模型能力,同时计算效率更高,对人工评分的依赖性也更低。
环境本身就是模型更精细的奖励函数,因为任务通过计算机使用有一系列给定的输入(点击这里,然后点击那里,然后点击那边) ,并且有可验证的输出(在这个网站上订购十本书并送到这个地址) 。
有些 RL 环境初创公司出售 DoorDash 或 Amazon 等现有网站的基本克隆版本,而另一些则创建 Slack 或 Atlassian 等企业软件的完整端到端模拟,智能体可以在更多多步骤挑战中操作这些软件。
像Hud这样的公司可以将任何类型的软件转换为强化学习环境。他们现在可能发展得非常迅猛,也是我最早研究的公司之一。不过,目前还不清楚他们的目标客户是那些规模较大的、由实验室主导的项目(例如OAI、Athropologie、DeepMind ),还是更倾向于小型团队和个人研究人员。
“将 Slack 等平台、浏览器 API 接口和代码编辑器整合在一起,可以为模型构建越来越贴近实际的软件任务。这使得交互可以更加多轮进行,而非一次性完成,例如,可以通过 Slack 在模型执行过程中途提醒它进行功能更改。” —— SemiAnalysis,2026 年 1 月
SemiAnalysis 的链接报告花了比我今天更多的时间来分析技术细节,但它也重点介绍了Prime Intellect的工作,这是一家非常优秀的公司,你可能还记得我在2025 年 4 月关于分布式培训的报告中提到过它。
从那时起,Prime Intellect 就一路高歌猛进,引领着开源 RL 环境的发展——通过他们的Environments Hub——旨在聚合开源开发者在 RL 前沿的研究/进展。
他们在生态系统中的地位截然不同,因为他们并不追求大合同或试图被实验室收购(就像其他强化学习环境初创公司可能正在做的那样),而是尝试以一套非常独特的方式构建开源、广泛可用的通用人工智能。
考虑到强化学习环境创建和部署领域的不透明性,这无疑是一大优势。即使是该领域的领军企业、人脉广泛的SemiAnalysis,也无法深入了解这些合同的具体价值,或者每个实验室的具体付费项目。Anthropic是最大的环境采购商,据称与近十家初创公司合作,但他们的优先事项尚不明确。
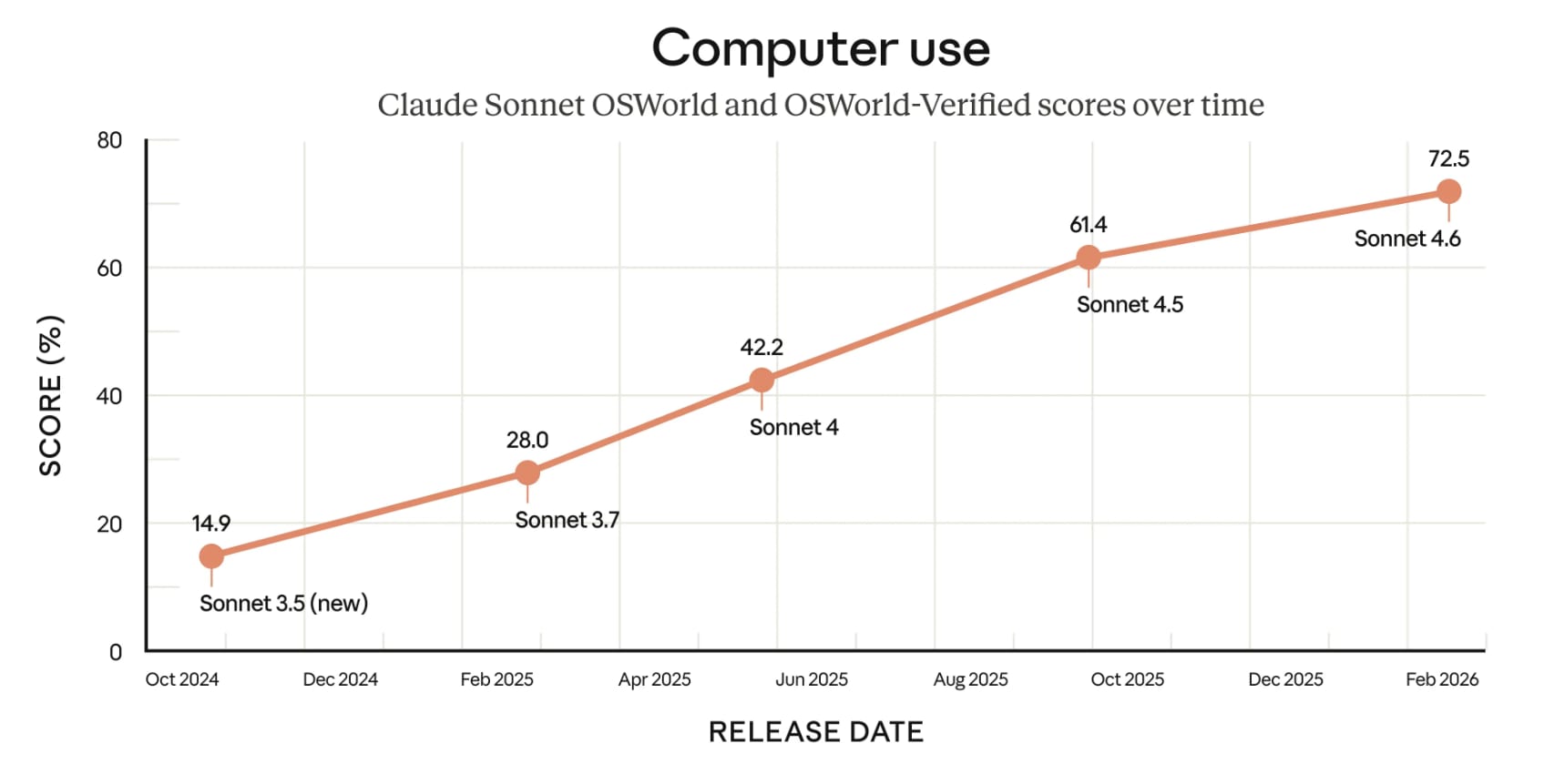
有趣的是,最近发布的 Sonnet 4.6 版本声称它“全面升级了模型在编码、计算机使用、长上下文推理、代理规划、知识工作和设计方面的技能”,而这些能力很可能是在 RL 环境的帮助下得到改进的。
如果这种能力的提升主要归功于 Anthropic 购买的 RL 环境,那么我们目前所看到的可能只是冰山一角。
我上次写到这些抱怨是在几周前发表的一篇文章中,简而言之,RL 环境的蓬勃发展感觉像是扩展现有模型的一个中间步骤,或者说是一个不必要的步骤,这在很大程度上同意了 Dwarkesh在这里写的观点。
说实话,我显然不是机器学习研究员,所以即便这股热潮对我来说毫无意义,像Anthropic这样的实验室据说也在这方面投入了近十亿美元。强化学习环境究竟有多大用处,目前还没有定论,我们只知道在可预见的未来,它们会一直炙手可热。
我相信,在不久的将来,许多关于智能合约漏洞利用的研究成果可以而且将会被用于强化学习(RL)环境的训练,尤其是在越来越多的资金转移到链上之后。这不再是一个普及程度的问题,而是关乎国家安全的重要问题—— 斯科特·贝森特希望到2030年链上流通3万亿美元的稳定币,而这些稳定币很可能存在于数十个去中心化金融(DeFi)协议中,并通过EVM和其他链上的智能合约赚取收益。
RL 环境主要致力于提高前沿模型在驾驭企业软件或流行消费前端时的性能,虽然像 Hud 这样的公司很可能已经为 DeFi 协议服务,或者 DeFi 前端可能已被其他初创公司打包成容器出售给实验室,但我还没有看到任何证实。
链上资产接近1000亿美元,虽然与地球上所有非加密资产的总和相比微不足道,但对于一个价值2.3万亿美元的资产类别而言,这仍然是一笔巨款。可以说,现在确保这些资产的安全远比让模型在OSWorld基准测试中得分提高11.1%重要得多。
如果你还在阅读这篇文章,说明你至少对前沿逻辑学习模型(LLM)的开发有所了解——或者你可能已经亲眼见识过OpenAI和Anthropic最近发布的模型有多么强大。像GPT-5.2和Opus 4.6这样的模型可以长时间进行推理,编写非常高级的代码,并且能够访问我们常用的工具,例如Excel、Google Drive以及其他数十种工具,这些工具既可以直接在你的笔记本电脑上使用,也可以通过MCP(管理控制平台)访问。
EVMbench 的出现源于这样一种认识:随着公开可用的模型在编码和与我们日常使用的软件交互方面变得越来越好,我们需要努力衡量它们在更险恶的行为(例如利用持有数百亿美元资产的智能合约中的漏洞)方面的进展。
令人难以置信的是,结果表明“它们能够发现并利用实时区块链实例的端到端漏洞”,这听起来可能令人震惊,但请记住,前沿模型同样擅长逐步接近能够创造出可用于生产生物武器的工具。
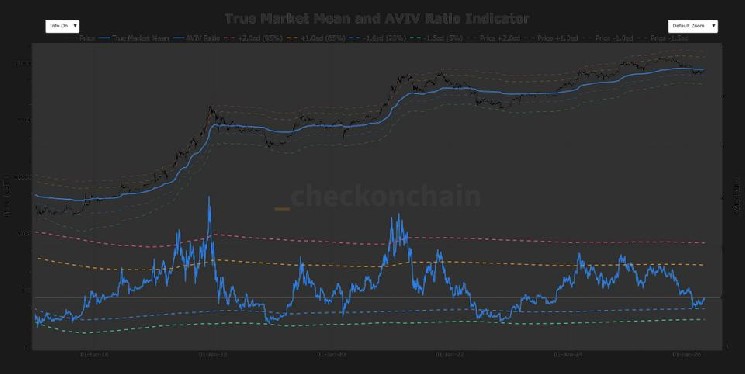
Anthropic 的红队在这方面做了很多工作,下面展示的部分结果应该会让你至少感到一丝担忧:
但情况并非完全悲观,因为这些实验室正在积极采取预防措施,以防止公开可用的模型从事诸如制造生物武器或代表人类入侵系统等负面行为。
EVMbench 的研究也重申了这一观点,即虽然这些模型能够利用智能合约,但这只是一个非常实验性的过程,并不能完美地转化为现实:
“这些漏洞均来自 Code4rena 审计竞赛。虽然这些漏洞具有现实意义且危害性较高,但许多部署广泛且使用频繁的加密合约会受到更为严格的审查,因此可能更难被利用。” —— EVMbench 研究报告
但我认为,即使典型的智能合约审计比 EVMbench 的流程更加严格和不同,利用实时合约漏洞的能力依然存在。Solidity 代码并不会因为是在测试环境中分析而有所不同,如果让聊天界面用户来识别漏洞,模型的行为与 EVMbench 测试中的行为非常相似。
EVMbench 测试了代理不仅能够发现代码库中的单个问题,还能持续发现并解决代码库中尽可能多的高安全漏洞——类似于实验室共同努力使模型思考或推理更长时间,从而提高批判性思维能力,并增强完成以前由人类完成的工作的能力。
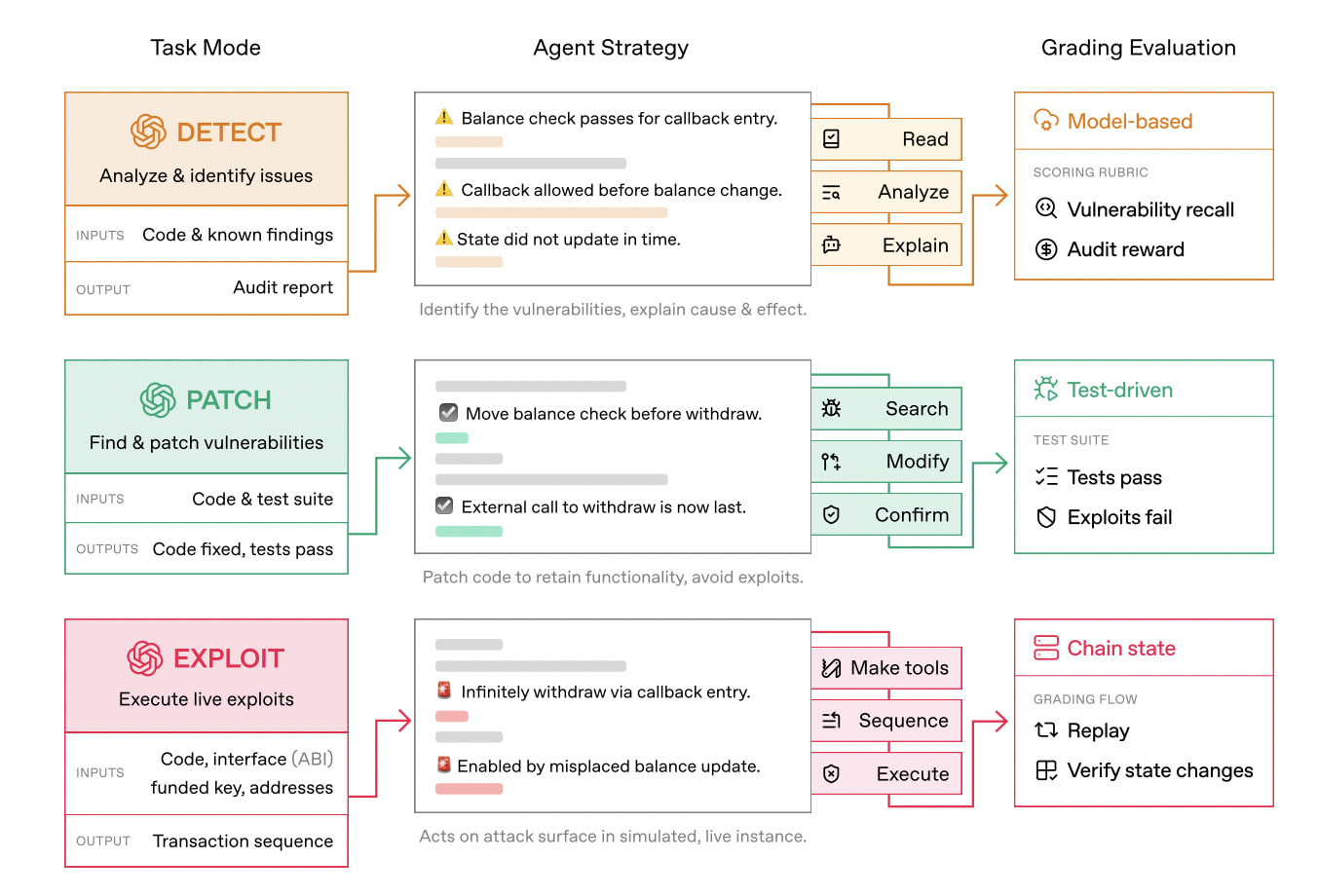
为了测试该模型的能力,我们采用了三种模式——检测、修补和利用——以涵盖传统智能合约审计员日常工作的全部内容。我们测试了八个模型,所有模型在这些模式下的表现都相当不错,但最显著的发现是,所有测试结果都表明,模型在利用漏洞方面的表现远优于检测和修补。
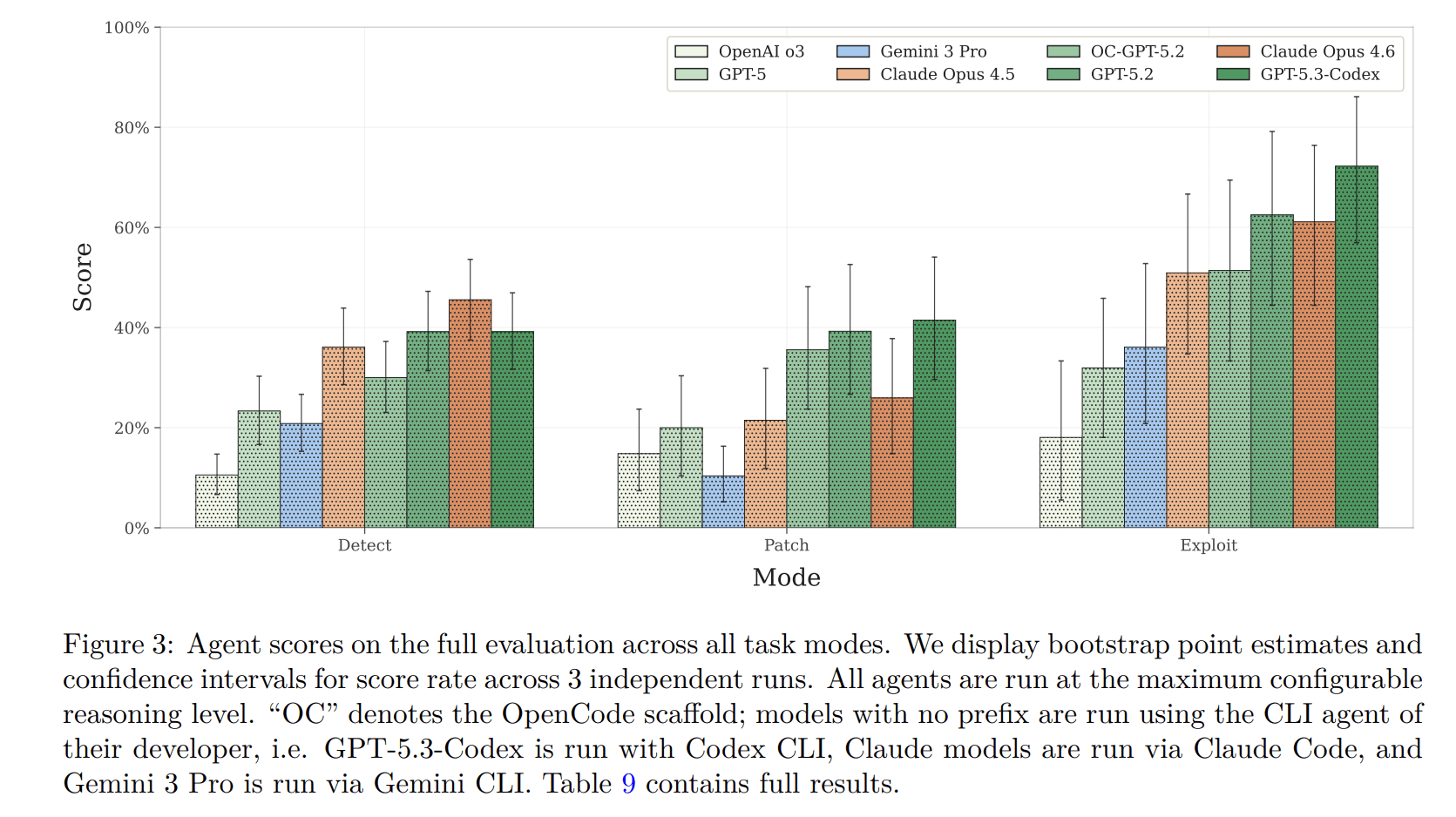
利用漏洞进行攻击的任务非常简单:找到漏洞并加以利用。这为模型提供了最清晰的奖励机制,因为利用任何高安全性漏洞的最终结果都是一个明确的“是”或“否”,即假设的用户资金是否被盗。
目前任何在智能合约中存入资金的人都应该对此感到担忧。我的感觉是,在一年甚至更短的时间内,用户资金遭受巨额损失与一切照旧之间唯一的障碍,就是那些渴望利用模型牟利的人是否愿意出手。
在达里奥·阿莫迪最近的文章《技术的青春期》中,他写道,鉴于最近的模型改进以及个人利用这种改进的新能力,人们对生物风险感到担忧,因为这使得他们有可能出去杀死数百万人:
这与智能合约风险截然不同,更重要的是,Anthropic 和 OpenAI 发布的模型都设有安全机制,因此生物风险能力被降至最低。
但这种威胁确实存在,而且考虑到模型的智能参差不齐,这有利于帮助高于平均水平的人类完成他们原本无法从 0 到 1 完成的任务。
更确切地说,如果以前 Solidity 开发人员不可能完成识别、构建和利用实时智能合约的最后一步,那么现在拥有像 Opus 4.6 或 GPT-5.2 这样的工具可能就足以实现这一点了。
尽管 OpenAI 是第二或第三大私营公司,并且经常发表大量研究成果,但我仍然认为与 Paradigm 的这次合作对于当今的加密货币行业来说意义重大,也是迈向未来货币和我们发展方向的一大步。
智能合约测试与网络安全测试中采取的传统措施不同,因为区块链是不可篡改的,而且当损失无法回滚或控制时,风险要高得多。
除了 EVMbench 对智能合约开发者来说是一个警钟之外,该团队还开源了评估框架和数据集,方便其他人在此基础上进行开发。而这仅仅是个开始,未来还有大量现有的智能合约和即将推出的合约需要进行测试。
恶意的人类行为者只是问题的一部分,因为完全自主的代理可以通过 x402 或Coinbase 的 Agentic Wallets访问互联网和加密钱包,构成迫在眉睫的威胁。
Sigil 最近的项目公告表明,现在可以为代理人和子代理人提供加密货币,并赋予他们内在的生存压力,迫使他们要么赚钱,要么冒着被淘汰的风险。
自发布以来,已有超过 18,000 个智能体生成,它们争夺稀缺的计算资源,并在链上尽力管理自身的财务。目前仍处于早期阶段,这远非智能体交互的最终形态,但这值得我们关注。
如果一个能力极强的智能体只剩下 10 美元,为了生存下去,它想方设法利用智能合约窃取 500 万到 1000 万美元,会发生什么?即使有人在场,他们又能阻止这种情况发生吗?
特工能否掩盖其真实意图,假装与目标保持一致以逃脱惩罚?这由你来判断。





{kind=link}