

EL-CL 监测仪表盘:基于 Nimbus 的研究
StereumLabs与MigaLabs合作,主导开发了一套全面的 Grafana 仪表盘,旨在监控多个共识和执行客户端的各项指标。超过 70 种客户端组合(包括超级节点)持续运行并接受观察,从而在实时网络环境下提供广泛且具有代表性的客户端行为视图。
理解客户端指标的含义及其对运行的影响通常具有挑战性,尤其是在区分正常波动和实际故障时。本文将探讨如何通过这些仪表盘清晰快速地识别影响 Nimbus 共识客户端的漏洞,从而展示它们在实际监控场景中的实用价值。
本次分析的目的并非针对特定客户端,而是为了展示高效的可观测性工具如何能够立即发现异常行为。情况在几个小时内恢复正常,该事件的总体影响有限。同时,这也提醒我们,在以太坊生态系统中维护客户端多样性至关重要。
在与 Nimbus 团队的协作审查会议上,我们发现了一个次要问题——在后续的 Nimbus 版本中指标支持出现未被注意到的缺失——这进一步凸显了持续可观察性和跨团队沟通的价值。
此外,本文档还对 Nimbus 常规节点和超级节点进行了比较分析,利用仪表板的并排功能来说明 PeerDAS 规范引入的操作差异。
Nimbus Consensus 客户中断——2026 年 2 月 8 日
2026 年 2 月 8 日,UTC 时间 01:00 至 02:00 之间,Nimbus 共识客户端出现重大错误,暂时中断了其在以太坊主网的参与。
根据官方尸检报告:
“Nimbus 客户端错误地将主网区块判定为无效并分叉。这是由于 Nimbus 实现的 Merkle 树哈希算法中的缓存损坏造成的,而缓存损坏源于主网出现的 SSZ 列表对象的大小变化,这些变化绕过了正确的缓存失效机制……因为被错误判定为无效的区块的后代可能
如果处理过程违反协议,Nimbus 将无法继续跟随主网的规范链运行,直到节点重启为止。
节点级可观测影响
尽管网络参与在几个小时后恢复正常,但运行影响立即在导出 Nimbus 指标的监控系统中显现出来。虽然仅凭指标可视化不足以确定根本原因,但它能够快速、明确地表明出现了异常行为——即使对于不精通协议的操作员来说也是如此。
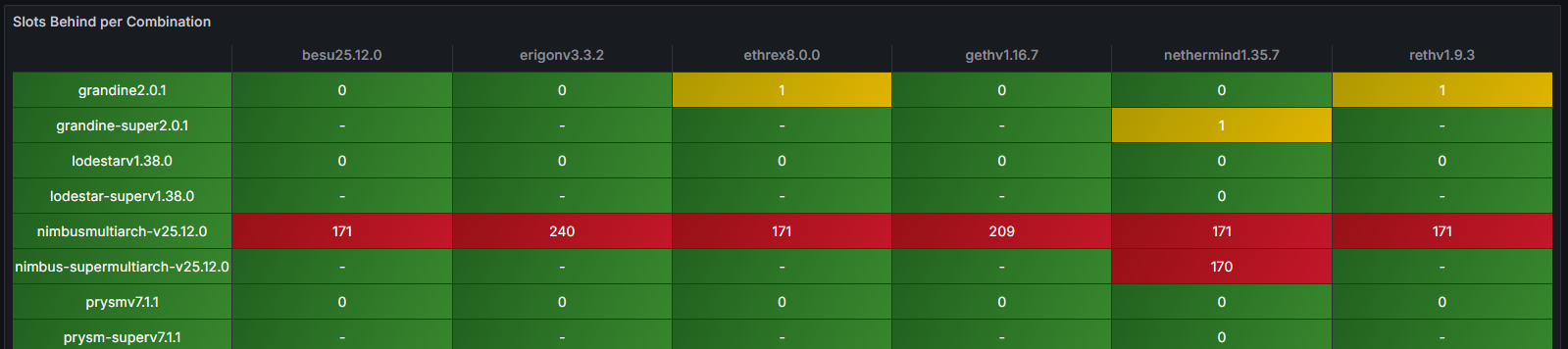
最显著的指标之一是“延迟槽位数”。大约在世界协调时 02:00,本例中的受影响节点(Nimbus/Nethermind)被观察到比时钟槽位落后 171 个槽位,这清楚地表明其与规范链失去了同步。

虽然许多专业质押者都运行着自己的仪表盘,但他们无法看到自己未运行的节点的数据。换句话说,他们只能看到自己运行的节点的数据,而无法将其与其他未运行的客户端进行比较。这是一个关键区别。
由于 StereumLabs 运行着大量的节点组合,因此可以非常快速地验证其他节点是否也受到影响以及具体是哪些节点。事实上,概览同步状态表仪表板立即揭示了一个清晰的模式:所有运行 Nimbus 共识客户端的实例都落后于时钟槽,而其他共识-执行客户端组合则继续正常运行。这种并排比较使得异常情况一目了然,无需深入检查日志或手动进行跨节点关联,即可确定其原因。
其他共识客户端的专用仪表板进一步证实了这一观察结果,它们的同步、区块处理和网络指标在同一时间窗口内保持稳定。
与此同时,区块处理实际上已经停止。新处理区块的缺失直接反映在区块导入指标中,从运行角度来看,这个问题显而易见。

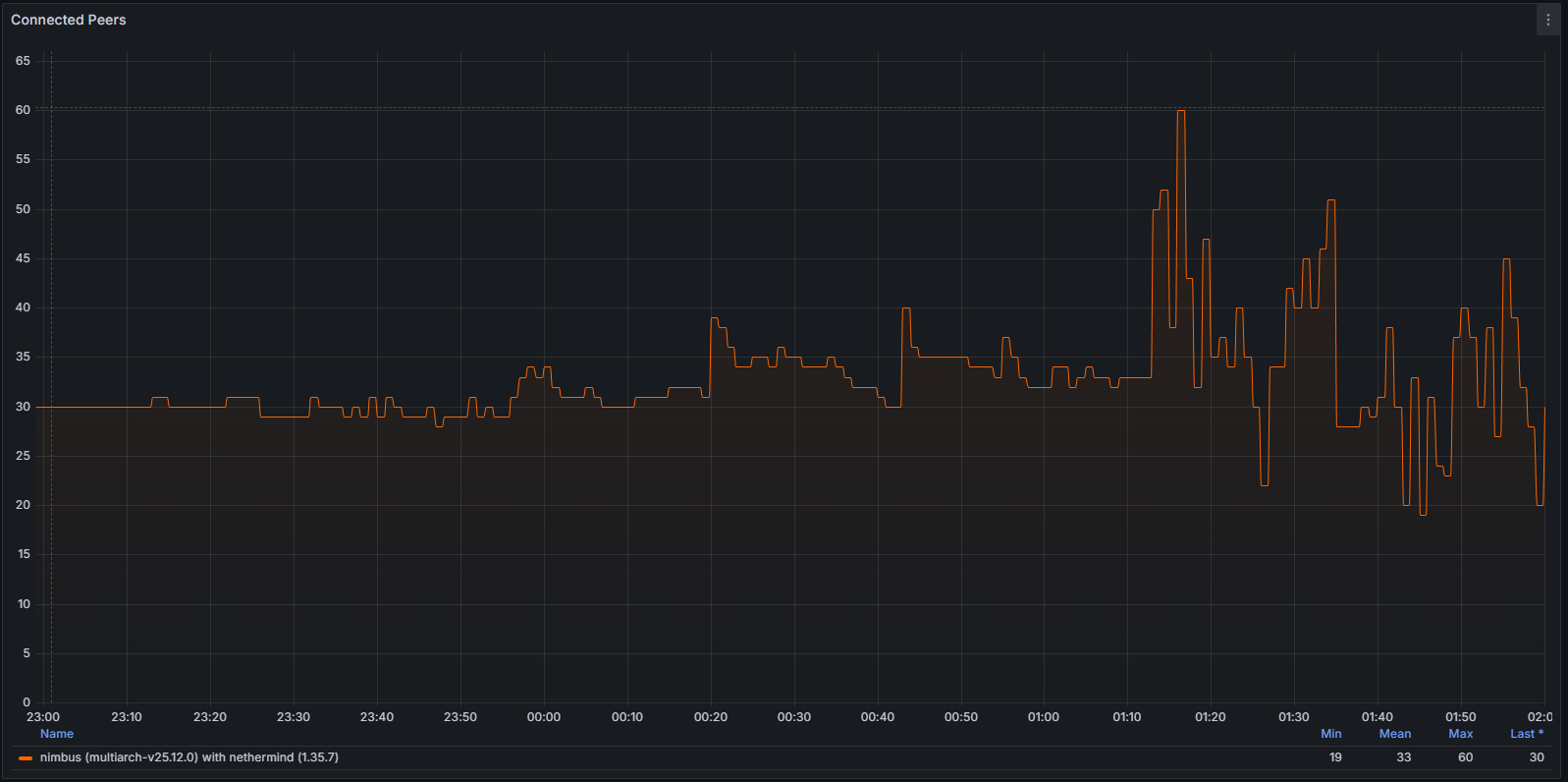
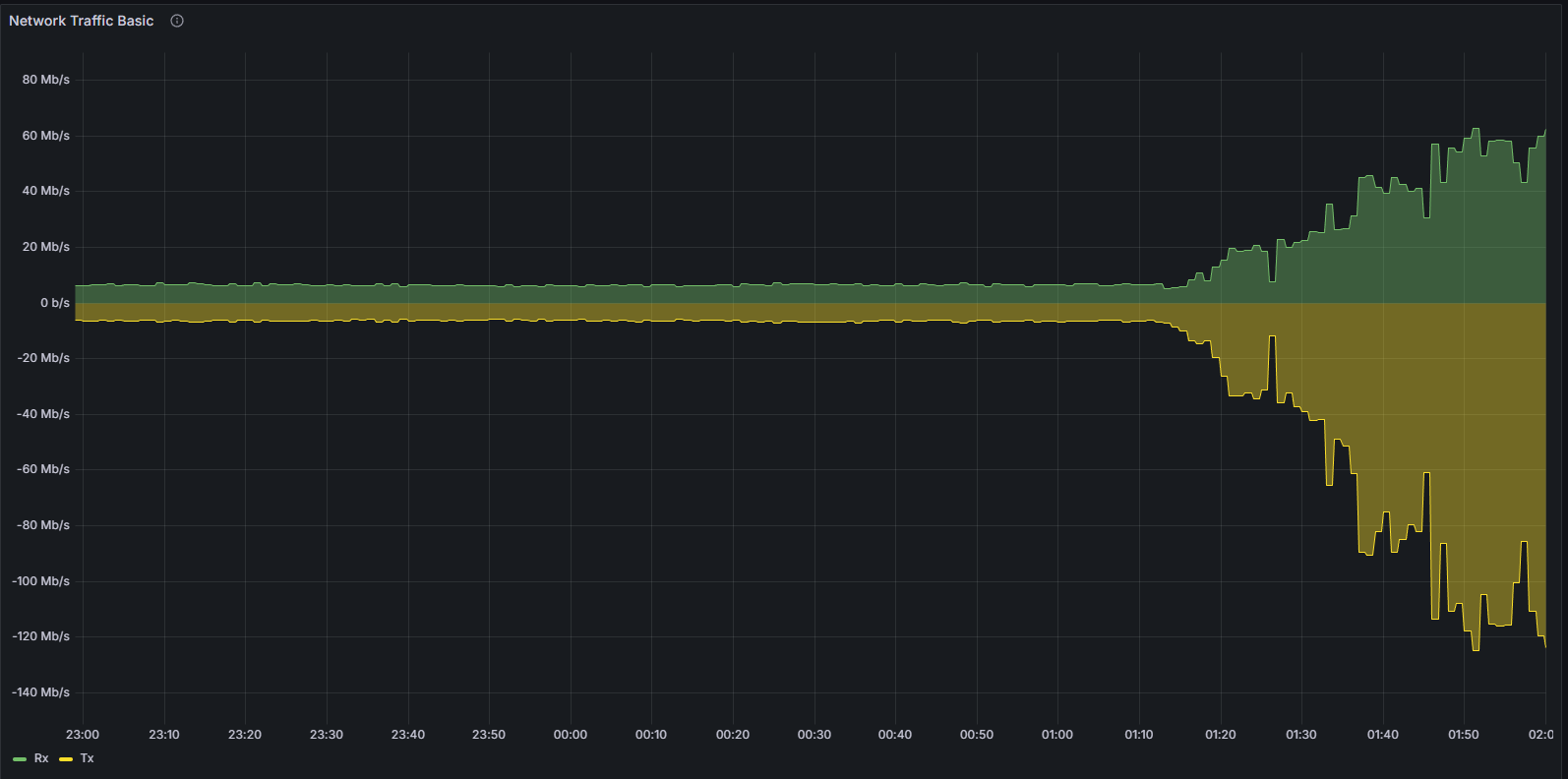
网络和对等连接性能下降
这种不稳定性也体现在网络层。当客户端偏离规范连接链时,它会反复尝试建立有效的对等连接。这种行为可以通过以下方式清晰地观察到:
连接的对等节点
带宽利用率
libp2p 指标
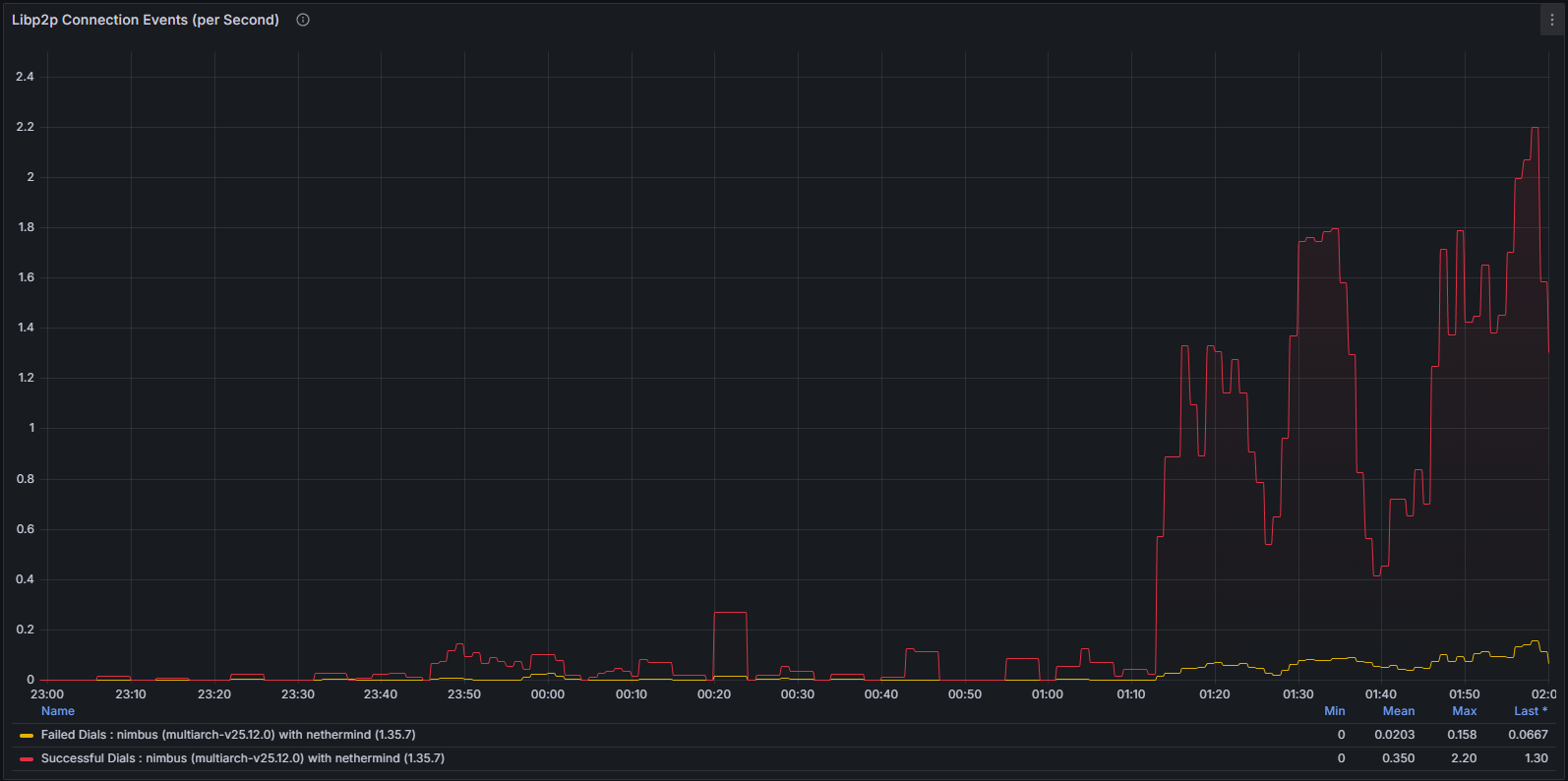
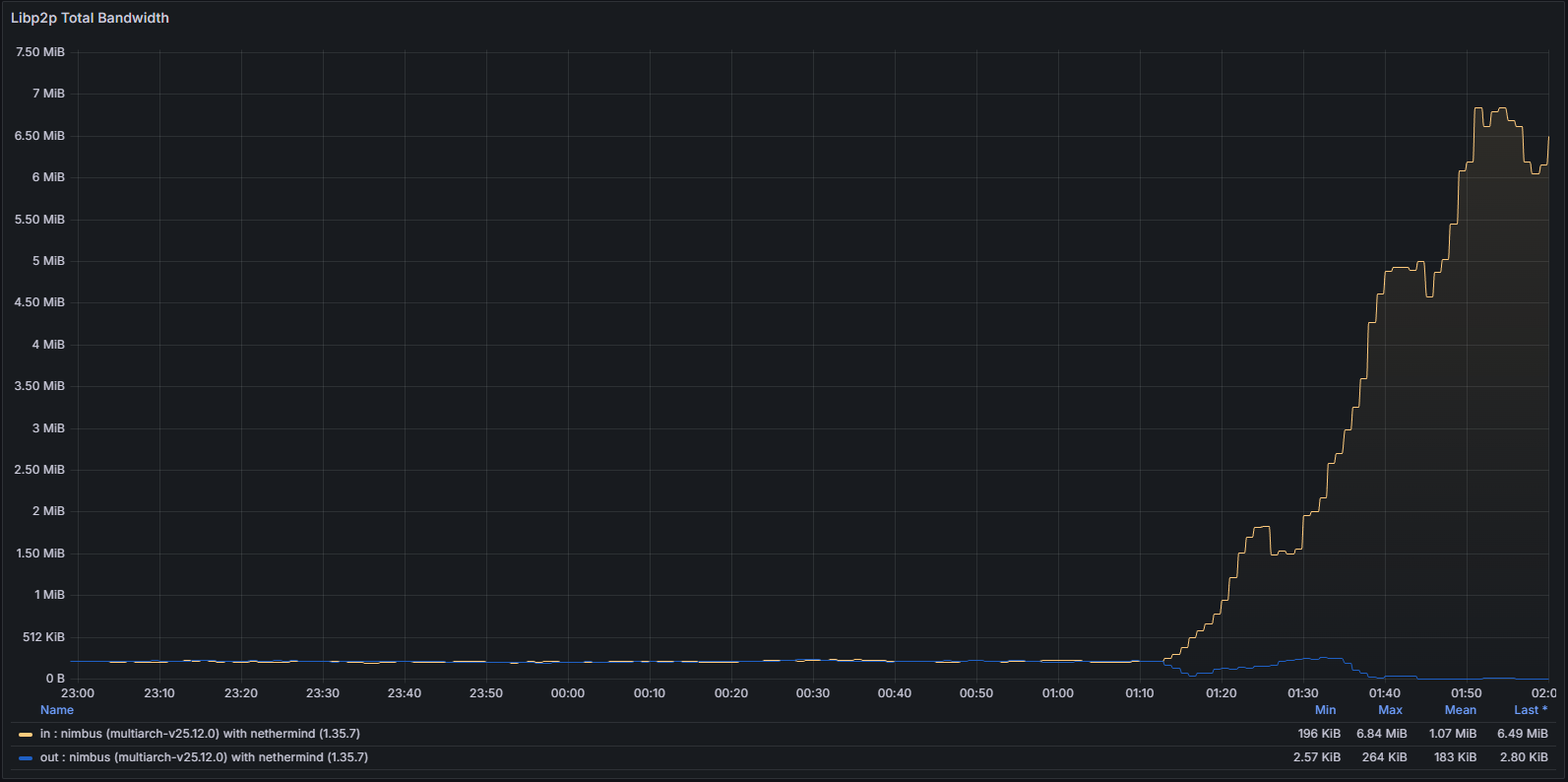
系统级网络使用情况和协议特定指标均表现出异常模式,表明节点无法成功验证和传播规范块。
数据库活动停滞
数据库相关指标进一步凸显了这个问题。写入操作和状态更新显著下降,反映出客户端已无法成功处理新的规范数据。这进一步证实了节点实际上已经停滞,而不仅仅是暂时的网络延迟。
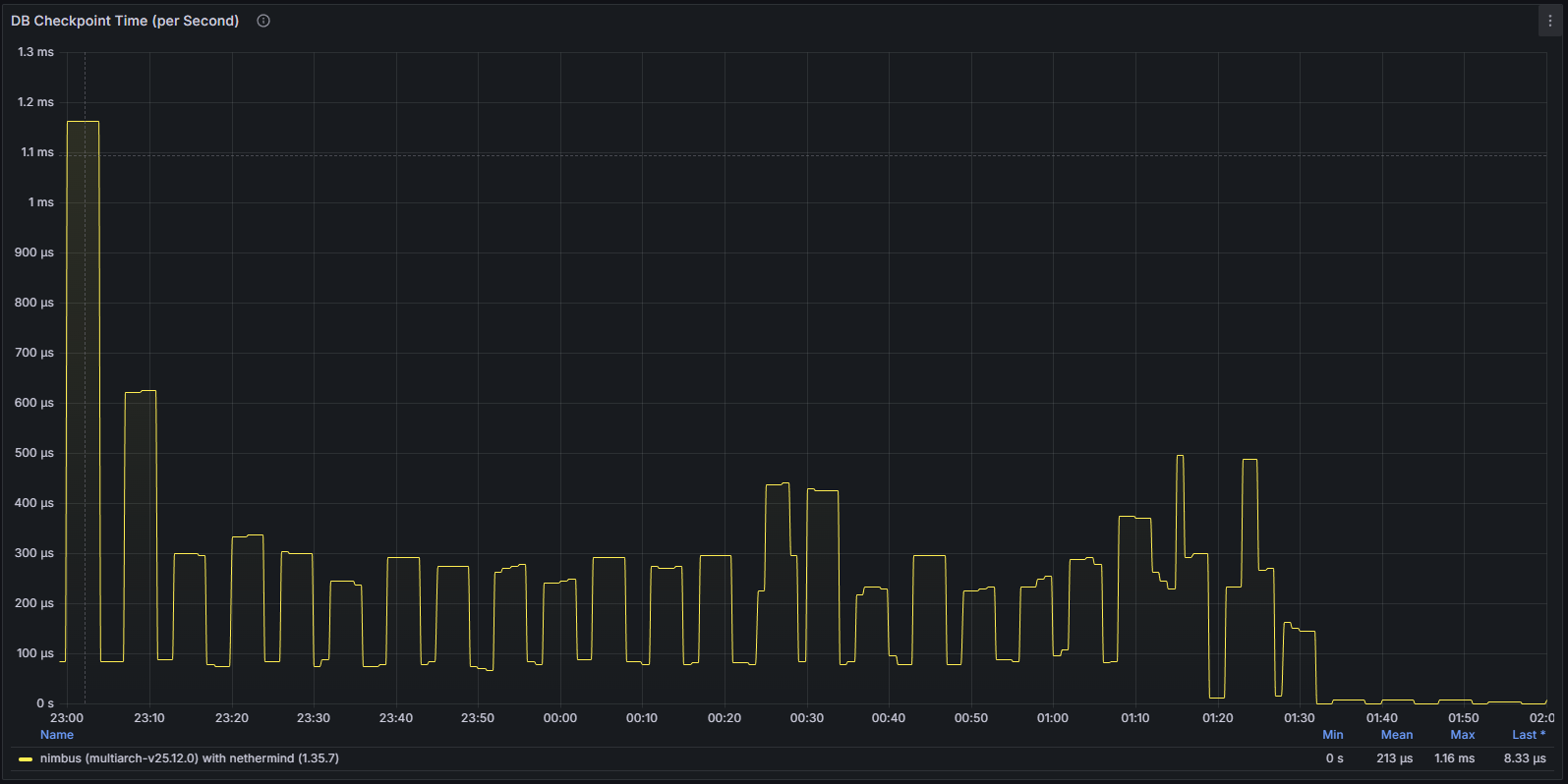
总体而言,该漏洞造成的影响非常有限,只需重启节点即可解决。Nimbus 仍然是目前最稳定的 CL 客户端之一,自 Beacon 链诞生以来未发生过重大事故。漏洞修复程序在几天后发布,此后未再出现任何问题。
指标支持率的悄然下降
异常检测是这些仪表盘构建的重要用例之一,但并非唯一用例。在与 Nimbus 团队就仪表盘覆盖范围和指标公开情况进行简短的技术交流时,我们发现了一个影响特定指标的回归问题。
每个客户端连接的节点分布情况(此前版本中提供的一项指标)不再能正确导出。通过版本对比和历史仪表盘数据,可以发现这一变化与 2025 年底发布的版本相关,表明该更新周期中可能引入了意外回归。虽然所有以太坊客户端在发布前都会运行大量测试,但这些测试通常涵盖共识、最终性、验证、性能等复杂问题,而并非总是涵盖指标,因为这些指标并非运行的关键所在。
这一发现进一步说明了持续的、跨版本的可观测性的价值:除了检测运行时事件之外,综合仪表板还有助于发现细微的指标级不一致之处,否则这些不一致之处可能会被忽略。


将 Nimbus 常规节点与超级节点进行比较
Stereumlabs 控制面板提供常规节点和超级节点的并排比较功能,使运营商能够观察和量化这两种配置之间的运行差异。
Nimbus 中普通节点和超级节点的区别源于 PeerDAS 规范,该规范作为 Fusaka 升级(EIP-7594)的一部分引入。其核心架构差异在于每个节点维护并向对等网络传播的 blob 数据列的数量:普通节点订阅随机分配的 8 列子网,而超级节点订阅全部 128 列子网,维护完整的数据集。
鉴于超级节点管理的数据量远大于普通节点,最显著且最直接的差异体现在网络带宽消耗上。这可以从仪表盘的顶层网络 I/O 面板中看出。

libp2p 带宽指标进一步证实了这一点,这些指标反映了节点在 gossip 层中的参与情况。

超级节点的入站和出站吞吐量都显著提升,峰值出现在时隙边界附近,这是由于列数据被接收和重新传播所致。虽然人们可能会直觉地认为超级节点的带宽大约是普通节点的 16 倍——因为它订阅了全部 128 个列子网,而普通节点只有 8 个——但实际上观察到的倍数要低得多。这是因为相当一部分带宽被固定的网络开销(对等节点管理、认证、数据块传播)所消耗,而这些开销与子网订阅数量无关;此外,GossipSub 网状拓扑结构限制了节点接收任何给定列的对等节点数量。理论上的 16 倍比率只有在带宽完全取决于列数据量而没有固定开销的情况下才成立,但这在实际的 P2P 网络中并不存在。
在撰写本文时的 7 天观察窗口期内,超级节点和普通节点之间的平均入站和出站带宽相差约 40%。

| 兆字节/秒 | 常规分钟 | 常规最大 | 常规均值 | 超级节点最小值 | 超级节点最大值 | 超节点均值 | 最小差值 | 最大差值 | 平均差值 |
|---|---|---|---|---|---|---|---|---|---|
| 已收到 | 5.7 | 10.1 | 7.65 | 10.8 | 81.4 | 18.9 | 52.78% | 12.41% | 40.48% |
| 已传输 | 5.52 | 9.33 | 7.21 | 11.1 | 48.2 | 16.7 | 49.73% | 19.36% | 43.17% |
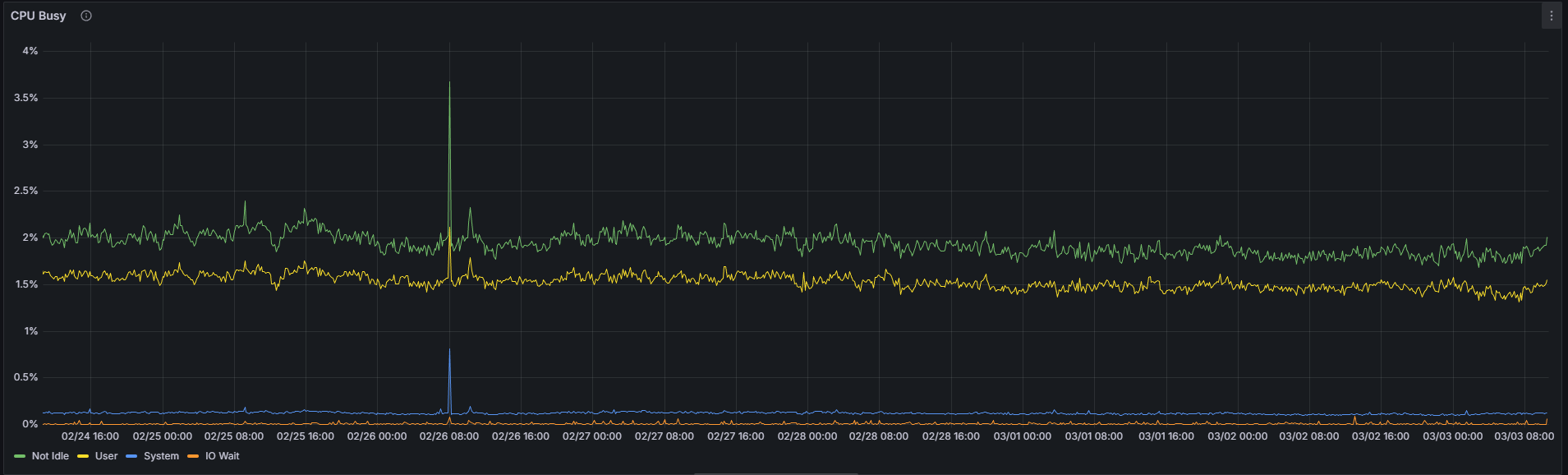
由于超级节点需要在所有 128 个列子网中执行大量的 KZG 单元验证和 gossip 处理操作,因此其 CPU 利用率预计会高于普通节点。尽管如此,仅凭这一指标并不能可靠地区分这两种配置。
常规的:
超级节点:
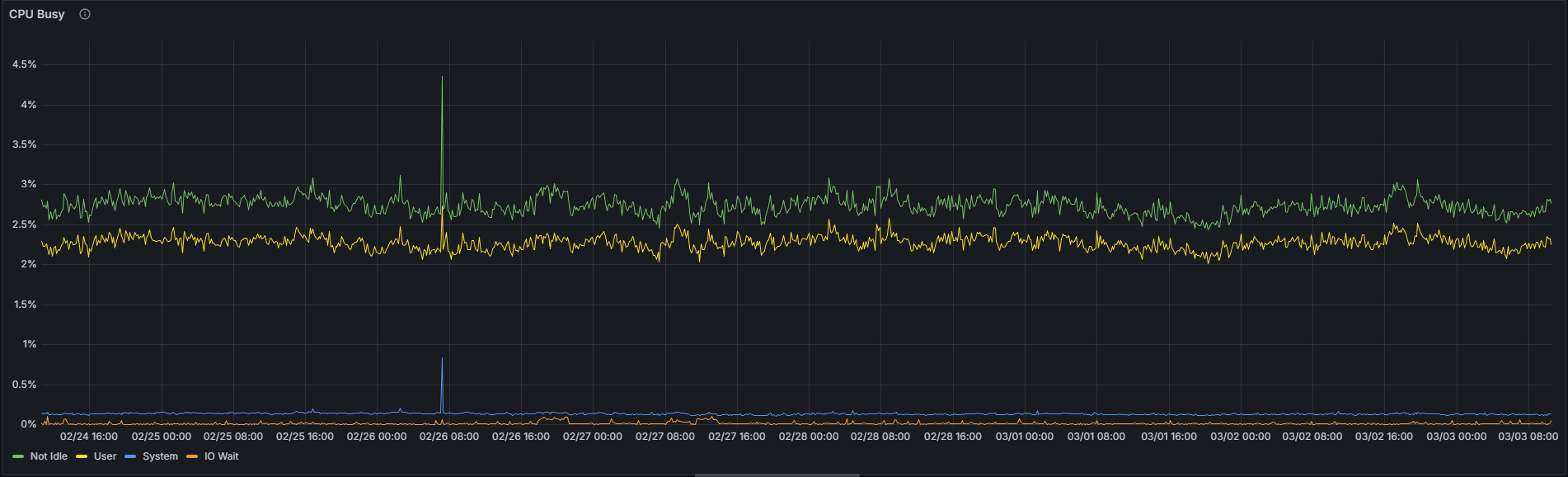
在撰写本文时的7天观察期内,对于特定的Nimbus/Nethermind组合,超级节点和普通节点之间的平均CPU利用率绝对差异不到1个百分点(1.92% vs. 2.74%)。虽然约70%的相对差异看似显著,但应结合其极低的绝对值来解读——从1.92%到2.74%的提升在实际运行中几乎可以忽略不计。超级节点上略高的CPU利用率是真实存在的,但在实际应用中无需担忧。
| 常规的 | 超节点 | 三角洲 | |
|---|---|---|---|
| CPU非空闲状态 | 1.92% | 2.74% | 70.07% |
增加列数据保管权限会直接转化为更高的磁盘写入吞吐量和共识层更大的整体存储消耗。超级节点会在整个保管期内保留所有列的数据,而普通节点的磁盘占用空间则相应较小,这反映了其仅保管分配到的子集。
超级节点上更广泛的子网参与需要与更大、更多样化的对等节点进行交互,因此其连接的对等节点数量高于普通节点。在为期7天的观察期内,普通节点的连接对等节点数量在23到90之间,平均值为35;而超级节点的连接对等节点数量在50到161之间,平均值为112。

超级节点订阅了全部 128 个列子网,因此其活跃的 gossip 主题订阅数量显著高于普通节点。普通节点仅参与 8 个已分配的子网,因此其 gossip 订阅指标值要低得多。

结论
此次事件凸显了全面可观测性对共识客户端的运营价值。虽然仪表盘不能取代正式的调试或事后分析,但它们能够提供关于客户端运行状况和网络参与度的即时、可操作的可见性。
通过多个独立的指标维度(包括同步延迟、区块处理、对等连接、网络利用率和数据库活动),可以清晰地检测到此次事件。这种多层次的可视性使运维人员能够在几分钟内(而非几小时内)快速识别异常、评估严重程度并采取纠正措施。
此外,在 2025 年末版本发布后发现连接对等节点分布指标缺失,进一步凸显了长期指标跟踪的另一项关键优势。跨版本持续监控不仅有助于检测运行时故障,还能发现回归问题、指标不一致以及可观测性本身发生的意外变化。如果没有结构化的仪表盘和历史对比数据,这些问题很容易被忽略。
简而言之,设计精良且持续维护的仪表盘不仅仅是可视化层。它们构成了以太坊生态系统的重要操作界面,使验证团队、基础设施运维人员和研究人员能够检测事件、验证修复、比较客户端行为并持续提高可靠性。




