虽然这并非严格意义上的加密货币相关内容,但它与我过去撰写过的预测市场密切相关,而且我相信这里的读者也会对此感兴趣。此外,一些读者明确要求我写一篇类似的文章,所以就有了这篇文章!
过去几周,我一直在构建一个预测模型,用来预测 Dota 2(一款电子竞技游戏)比赛的胜负。我完全使用Vibe Code 和 Claude Code完成了这项工作(Yoshi 通过 OpenClaw 提供了一些帮助,但所有操作都可以直接通过 Claude Code 完成)。我没有机器学习学位,也没有数据科学背景。
虽然现在下结论还为时过早,但结果看起来非常令人鼓舞。我回测了这个模型,结果确实非常棒。说实话,好得有点不真实,所以请大家对此保持一定的怀疑态度:
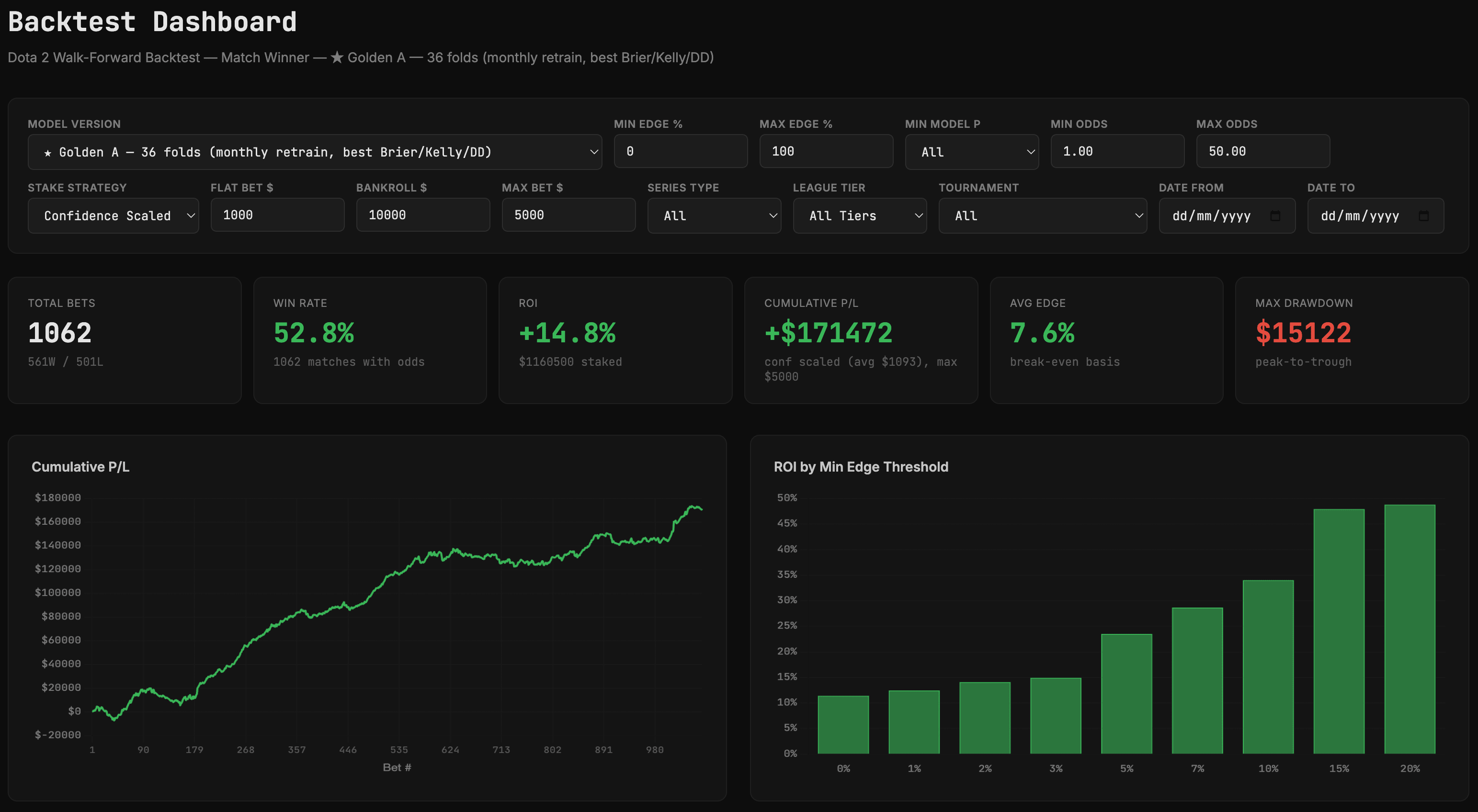
我已经追踪实际结果几周了,记录了大约100笔实际投注,目前模型表现良好(投资回报率约7.5%),所以我对未来发展抱有希望。但我知道现在还处于早期阶段。
我每天都在完善我的模型,已经坚持了将近两个月,平均每天投入五个多小时。这其中有很多艰辛的工作,也伴随着不少挫折。但我相信,任何人都能像我一样,构建出一个(希望是)盈利的模型。
今天我将带你了解预测模型的工作原理,我是如何创建我的模型的,以及如何利用 Vibe 编码的力量创建你自己的模型。
我将详细分析每个成功的预测模型都需要的核心组成部分,并就如何从实际角度构建和开发这些模型提出一些建议:
附注:我正在筹建一个新的教育社区,面向那些想要学习人工智能的人。我的两位联合创始人多年来一直在构建和教授人工智能,除此之外,我们还将每周举办 8 场直播视频研讨会。
我们目前还处于起步阶段,但我们正在招募新会员。高级订阅用户可享受一项特别优惠,我会在本期简报末尾分享,优惠幅度为最终价格的70% 。
1. 首先提出一个清晰明确的问题
人们一听到“预测模型”就犯的最大错误是,他们开始思考算法、框架和盈利。不要这样做。相反,你应该思考你试图回答什么问题。
谁赢了这场Dota 2比赛?这是个好问题。结果非此即彼,而且可以量化。你知道自己什么时候猜对了,什么时候猜错了。
“本周加密货币市场会发生什么?”这个问题问得不好。它太笼统了,没有明确的成功或失败标准。你甚至很难知道应该收集哪些数据。
如果你对这四个问题都有明确的答案,你应该能够提出一个好问题,并使用预测模型来回答这个问题。
如果你想建立一个可以用来下注赚钱的模型,那么我认为最好从你已经具备领域知识和专业技能的领域入手。
你可以向任何人工智能描述你感兴趣的领域,并请它帮助你构建一个明确的问题。让它引导你更具体地思考。告诉它你的领域以及你想做出的决策,它会帮助你找到你想回答的问题。
2. 让人工智能全程协助你
独自完成所有这些事情毫无荣耀可言。人工智能是世界上最强大的工具,要善用它,并且要充分利用它。
一旦你选定了想要解答的问题,就可以打开你选择的编程平台,开始向人工智能寻求帮助了。几周前我写过一篇关于 Claude Code 的文章,我的模型就是用它构建的。我建议使用 Claude Code 搭配 Opus 4.6,或者使用 Codex 搭配 GPT 5.4,因为它们是目前编程领域最前沿的两款模型。
当然,你可以先用低端型号试试水,做些实验(这也是个很好的学习方法),但如果你想赚钱,我真的觉得你应该选择顶级型号。
在 Claude Code/Codex 中,创建一个新项目,然后根据你提出的问题,开始描述你的需求。例如:
我想构建一个 Dota 2 预测模型,用来预测哪支队伍会赢得比赛。我需要你的帮助。首先,你需要深入研究构建预测模型的方方面面,特别是 Dota 2 和电竞模型。查阅相关的研究论文,以及其他成功模型的案例,从中汲取经验。把这些资料和案例分享给我。然后,根据这些信息,制定一个循序渐进的计划,并告诉我我们需要哪些材料才能开始。
人工智能接下来肯定能制定出相当不错的计划,但我发现真正有帮助且非常重要的一点是,你自己也要阅读相关资料和研究论文(至少读几篇)。我知道我们都在努力适应依赖人工智能的摘要和要点,但你真的需要对底层运作原理有所了解;这对你接下来的工作大有裨益。
希望这封信的其余部分能为您提供一些背景信息,并帮助您理解这些事情。
3. 你需要可靠、干净的数据
你的模型通过数据学习。如果数据错误、不完整或不一致,模型就会学习到错误的信息。
我的 Dota 2 模型的大部分数据都来自官方 API。我始终建议大家尽量寻找优质的 API 来获取数据,而不是从网络上抓取数据。就 Dota 而言,我使用的 API 拥有长达数年的全面比赛数据,包括队伍阵容、选手数据、比赛结果、版本更新信息等等。这些数据结构清晰、文档齐全,并且定期更新。
遗憾的是(或许也算幸运,因为这可能带来机会),并非每个领域都提供完善的 API。有时,你不得不抓取网站数据、解析 PDF 文件,或者处理杂乱的电子表格。
通常情况下,你还是需要两者兼顾(我会抓取一些内容,尽管 95% 的内容来自 API)。
归根结底,格式远不如可靠性重要。你需要确信数据能够准确反映实际发生的情况。API 更便捷,但并非实现这一目标的唯一途径。
除了可靠的数据之外,干净的数据也至关重要。这意味着:没有重复记录、格式一致、关键字段没有缺失值,并且每个字段的含义都有清晰的文档说明。
人工智能如何提供帮助
让它编写数据质量检查脚本。例如:“编写一个脚本,加载我的比赛数据,检查重复项,标记缺少球队 ID 的比赛,并显示每月比赛的分布情况。” 你甚至可以更基础一些,比如:“我想确保我们的数据干净可靠,我们该怎么做?” 它会给出一些建议和方案,然后你可以根据这些建议进行操作。
4. 你的特点至关重要
构建预测模型时,理解特征至关重要。简而言之,特征是模型用于进行预测的输入。原始数据本身很少有用。你需要原始数据,因为它是创建特征的基础,但真正用于预测的是特征。
对于 Dota 2 来说,像“A 队已经打了 200 场比赛”这样的原始数据几乎无法告诉你下一场比赛谁会赢。但是“A 队在当前版本最近 20 场比赛中赢了 65% 的比赛”这样的数据却能提供一些关于当前版本环境下队伍近期状态的有用信息。
这时,你的专业知识就派上用场了。你了解你的领域,知道哪些因素会影响结果。如果你是一位狂热的高尔夫球迷,你就知道天气会影响比赛结果,草种类型会影响比赛结果,球员早上开球还是下午开球会影响他们取得好成绩的可能性,你也知道远距离击球手在某些球场上表现更好,等等。
你的模型一开始并不知道这些。它只知道你通过特征告诉它的信息。
好的特征能够捕捉预测之前可获得的信息,与结果相关,并且与其他特征不冗余。
人工智能如何提供帮助
先让它推荐一些功能作为起点,这样你就能了解可以使用的功能类型。然后描述你的领域专业知识以及你认为重要的因素,集思广益,列出你认为可能影响结果的其他功能。
然后,让它从你的原始数据中提取这些特征。它会编写转换代码。你评估这些特征是否合理。这种来回交互正是“直觉式编码”的优势所在。你贡献思考(至少一部分)和你的领域知识。剩下的所有工作都由人工智能完成。
5. 选择合适的型号
你有了问题、数据和特征。现在你需要一个工具,能够利用这些特征做出预测。这个工具就是模型。
把模型想象成一个函数。你给它输入数据(你的特征),它会给你一个输出(预测结果)。不同类型的模型学习这个函数的方式各不相同。有些很简单,有些则很复杂。正确的选择取决于你的问题,但对于大多数结构化数据的预测任务来说,答案比你想象的要简单。