欢迎自从上一篇文章发布以来,新增的 458 位「不无聊」会员!点击此处订阅,加入260,170 位聪明好学的读者行列:
嗨,朋友们👋,
周三快乐!
几个月前,Pim DeWitte 和 Kent Rollins 邀请我去他们在纽约市的办公室,向我展示他们在General Intuition公司正在研发的产品。我之前听说过这家公司,因为他们宣布完成了高达 1.337 亿美元的种子轮融资,也听说过他们正在开发的产品类型——世界模型,但除此之外,我对他们了解甚少。
那天他们向我展示的模型——这些模型能够透过分析带有动作标签的游戏片段来预测近期未来——以及此后我透过多次交流和数十小时的研究所了解到的内容,彻底改变了我对模型能力的认知。我曾公开表示对逻辑学习模型(LLM)能否将我们带向超级智慧持怀疑态度,但我认为世界模型(World Models)很有可能驱动出超越人类能力、与我们互补的机器,完成我们无法或不愿完成的任务。
自那次会面以来,世界模型领域迅速升温。李飞飞的World Labs融资10亿美元,Yann LeCun的AMI融资10.3亿美元。世界模式是本周NVIDIA GTC大会的焦点之一。但这个领域尚处于起步阶段,各种计划层出不穷,众多天才都在探索竞争与合作并存的方案,让人难以全面了解。
所以我邀请皮姆与我合作撰写一篇关于世界模型的历史、理论、发展和潜力的文章。他欣然同意,他和通用直觉团队都非常慷慨地投入时间和智慧,帮助我快速掌握相关知识,以便我能够帮助你们快速掌握相关知识。
我拥有世界上最酷的工作。在过去的几个月里,我有幸近距离见证了具身人工智慧的未来,即在梦境中训练的模型和智能体,它们能够指导机器在现实世界中为我们做事。
我很高兴能与大家分享这项探索的成果——我认为这是目前最全面的世界模型指南。显然,Pim 和 GI 团队对建立世界模型的最佳方法有自己的见解,但他们细致地分析了每种方法的优缺点(包括他们自己的方法),并且坦诚地承认未来尚不明朗,这一点给我留下了深刻的印象。
这个领域瞬息万变,发展速度惊人。我希望这篇文章能帮助你更能理解和掌握不断涌现的令人兴奋的新资讯。
让我们开始吧。
今天的「不无聊」节目由… Framer赞助播出

Framer赋予设计师超能力。
Framer是一款以设计为先、无需程式码的网站建立工具,让任何人都能在几分钟内建置出一个可用于生产环境的网站。无论您是从模板还是空白画布开始,Framer 都能让您完全掌控创作过程,无需任何编码。您可以新增动画、一键在地化,并与整个团队即时协作。您甚至可以使用内建分析功能进行 A/B 测试和点击追踪。
造访 Framer.com 即可免费启用。使用优惠码 NOTBORING 即可免费体验 Framer Pro 一个月。
世界模型:计算不可计算之物
与皮姆·德威特合著的文章

“我昨晚本想睡觉,结果却开始想像第二天可能会遇到的各种情况,以及我可能会如何应对。”

这是一种常见的体验。身为人类,我们很容易进行想像,无论是复杂的体育场、潜在的浪漫情愫,还是激烈的讨论。想像自己身处下一场曼联比赛现场,并不比想像与一位相识多年的朋友交谈更费力,尽管想像一场曼联比赛需要模拟和建模成千上万人的行为,而这对于当今的传统计算机和游戏引擎来说需要数年时间¹ 。
想像一下用程式码来描述曼联的比赛:任何时候,都可能有球迷拿出一面自制的旗帜。整个球场会开始唱起与这面旗帜相关的歌曲。但只有一部分人会跟著唱;其他人会带著孩子一起跳跃,而一对老夫妇则静静地坐在那里,思索著这是否会是他们最后一次一起看球,在静谧中感受著每一秒。
世界是一个充满变数的地方,未来总有出人意料的景象,但有些景象却又在某种程度上可以预测。身为人类,我们几乎可以用大致相同的努力和时间去设想所有这些未来。而计算机却做不到。
难怪传统运算难以应付这种复杂性。试想一下,要预测并编写每一个动作的程式码,以及所有这些动作之间的交互,这该有多么困难。从数学角度来看,在传统引擎中模拟N 个球迷至少是一个O(N)或O( N² ) 的问题。每个人、每面旗帜、每张椅子、每个球都必须进行明确计算——实际上,它们之间的交互作用也需要计算。
在机器人领域,无论现实世界的情况多么复杂,机器都必须在相同的时间内做出反应;然而,在传统电脑领域,模拟不同的情况所需的时间却可能相差甚远。这一直是机器人技术和具身人工智慧发展的主要瓶颈。
世界模型是解决问题的方案之一。
世界模型透过影片以及影片中人物的行为来学习预测这些动态变化。它们将动态且计算量庞大的场景(例如足球比赛等随机的、依赖行为的群体行为)简化为神经网路中单一的固定成本操作。
在世界模型中,整个体育场被模拟为神经网路的固定成本前向传播过程。场景的复杂性不会导致推理过程中「引擎」的运行速度呈指数级下降,因为权重在训练过程中已经吸收了世界的各种模式。
如何做到?行动。
行动起到了一种压缩作用,用于预测正在展开的动态变化:它们包含在环境中展开未来状态的信息,直到更多行动发生并为环境添加新的输入。每个行动都携带著足够的资讯来预测接下来会发生什么,直到下一个行动更新了整个图景。

这种基于动作的训练方法使模型能够进行互动式学习和规划。如今,即使是最好的仿真引擎也难以实现这一点,而且计算成本也难以预测。动作帮助模型像我们一样与世界互动。
每一天,你都会一再观察、思考、决定、行动。这就是生活。在任何时刻,所有关于时空的资讯最终都会汇聚成你的行动。
正是这种运算不可计算事物的能力,让我们相信世界模型能够以当前模型架构无法企及的方式,推动具身人工智慧的发展。
你是否做过这样的梦:你只能站在那里,眼睁睁看著事情发生,却无能为力?这就是视讯模型。
现实世界则不同。它会对你的行为或指示做出反应,并预测由此可能产生的所有结果,而不仅仅是最有可能或最有趣的下一帧画面。
你是否曾经有过清醒梦,在梦中你可以塑造自己脑中生成的梦境故事?这就是世界模型。
更正式地说,虽然标准视讯模型是基于机率 P(x t+1 | x t ) 预测下一帧,但世界模型基于干预P(s t+1 | s t , a t ) 预测下一个状态。
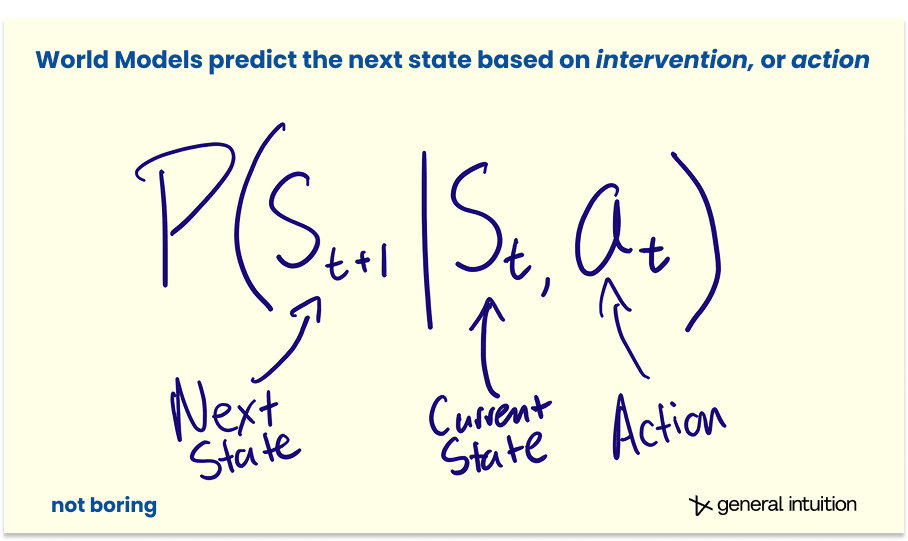
在General Intuition ,我们相信(并且已经看到了一些早期迹象),世界模型是一种新型的、可能比 LLM 更强大的基础模型,适用于需要深度空间和时间推理的环境,例如我们真实的世界。
世界模型——这些透过观察世界及其中的各种行为来学习的系统——是一种全新的基础模型。它们能够计算以前无法计算的内容。
它们的重要性将远远超出目前任何人的认知,因为它们提供了一条通往通用智慧的途径,而这仅靠语言和程式码是无法实现的。毕竟,身为人类,我们的一生都在根据自身的经验、观察和学习采取行动。
稍作停顿。你可能会对这种说法感到困惑,即世界模型提供了一条通往通用智慧的途径,而LLMs却无法做到。这完全可以理解。
近来,世界模型备受关注。一直对法学硕士能否通往通用智能持怀疑态度的杨乐存(Yann LeCun)刚刚宣布,他已为AMI筹集了10.3亿美元。李飞飞的世界实验室(World Labs)也筹集了超过10亿美元用于世界模型的研究。拥有科技界最接近「印钞机」的GoogleDeepMind也对世界模型寄予厚望。但到目前为止,我们看到的只是酷炫的影片和3D世界模型。
语言学硕士可以引用莎士比亚的诗句,也能解决埃尔德什问题。而世界模型,似乎更像是通往元宇宙的途径,而非通往通用智慧的途径。
但世界模型尚未像法学硕士那样受到追捧的部分原因是,它们的定义仍然不够明确。
什么是世界模型?我们之前已经说过,视讯模型不符合世界模型的定义。 3D空间模型也不符合。尽管如此,两者都可能是通往世界模型的途径。如今用来驱动机器人的模型是世界模型吗?严格来说,并非如此,尽管有些模型是,而且即使是那些不是世界模型的模型,也与世界模型架构有一些共同点。
一如既往,炒作只会加剧混乱。 “我预测‘世界模型’将成为下一个流行语,”AMI Labs(一家名副其实的世界模型公司)的首席执行官亚历山大·勒布伦告诉TechCrunch ,“六个月内,每家公司都会自称世界模型来筹集资金。”
炒作只是其中很小的一部分。我们──以及所有在这个领域耕耘的人──都相信,世界模型是控制物理世界中机器的必经之路。我们对这条路的具体形式或许有所不同,但我们都坚信,未来将由世界模型引领。
「…很少人意识到这种转变的影响有多深远…」NVIDIA机器人业务总监兼杰出科学家Jim Fan最近表示。 「不幸的是,目前世界模型最受关注的应用场景是人工智慧视讯处理(以及即将到来的游戏处理)。我完全有信心,2026年将是大型世界模型真正为机器人技术以及更广泛的多模态人工智慧奠定基础的第一年。”
今天,我们诚挚地欢迎您加入「极少数」真正理解这一转变意义深远的人的行列。我们将分享世界模型的发展历程、该领域目前的现状、各主要实验室所采取方法的简要说明,以及驱动通用直觉发展方向的信念。
是否跟随我们,完全取决于你。你选择吞下蓝色药丸,故事就此结束。你醒来后躺在床上,继续相信你想相信的一切。你选择吞下红色药丸……你将留在仙境,我们将带你领略兔子洞有多深。
特工能在自己的梦境中学习吗?

世界模型并非新概念,而是我们最古老的概念之一。自从人类具备思考自身在宇宙中的位置、探究我们存在的意义以来,我们就一直在思考,我们所处的现实是否只是一个模拟世界。
西元前380年,柏拉图透过苏格拉底提出了「洞穴寓言」 。想像一下,一群人生活在地下洞穴中,脖子被锁链束缚,被迫盯著墙上的影子。这些人会把那些影子误认为是现实,但实际上它们只是现实的影子。这就是柏拉图的比喻。他暗示我们都被困在这个洞穴里,脖子被锁链束缚,误将自己的感知当作了真实的现实。
八十年后,中国道家哲学家庄子在其著作《蝶梦》中也思考了类似的问题:
庄周曾梦见自己变成了一只蝴蝶,翩翩飞舞,自在快乐,随心所欲。他并不知道自己就是庄周。突然,他醒了过来,发现自己又变回了庄周,一个真实而清晰的庄周。但他却不知道,究竟是梦见自己变成蝴蝶的庄周,还是梦见自己变成庄周的蝴蝶?庄周和蝴蝶之间,必然存在著某种区别!这就是所谓的物性变化。
随著几个世纪的流逝和科技的进步,科幻作家也加入了探索现实本质的漫长思想家行列。弗雷德里克·波尔1955年的《世界之下的隧道》、丹尼尔·F·加卢耶的《模拟世界3》 、斯坦尼斯瓦夫·莱姆的《我不再侍奉》、弗诺·文奇的《真名实姓》 、威廉·吉布森的《神经漫游者》、尼尔·斯蒂芬森的《雪崩》……所有这些作品都以文字描绘了模拟世界。
1977 年,科幻传奇人物菲利普·K ·迪克在法国梅斯的一次演讲中自信地告诉听众:“我们生活在一个计算机编程的现实中,我们对此唯一的线索是,当某些变量发生变化时,我们的现实就会发生一些改变。”
你第一次接触模拟技术可能是透过《骇客任务》。我们也是。 在《骇客任务》的最初剧本中,华卓斯基姊妹将矩阵设想为连接成神经网路的人类大脑共同产生的模拟世界。

克里斯多福诺兰完全无视观众的困惑——甚至还乐在其中——于 2010 年推出了《全面启动》 。梦中梦中梦。

诺兰的核心前提是,梦境是一个可控制的空间,可以从中提取讯息,或者更重要的是,可以将讯息植入其中。
1990 年,慕尼黑工业大学的青年研究员 Jürgen Schmidhuber 出版了《使世界可区分》 。
该论文提出建构循环神经网路(RNN),该神经网路有两个任务:首先,学习预测模拟世界中接下来会发生什么;其次,使用该模拟世界来训练智能体在其中行动。
这个智能体完全不需要与「真实」环境互动。它可以在模型内部学习,在梦境中学习。

隔年,因《苦涩的教训》一书而闻名的理查德·萨顿提出了类似的想法。在他的著作《Dyna:学习、规划与反应的整合架构》中,他认为学习、规划与反应不应是彼此独立的系统,而应统一於单一的架构中。这意味著,从技术上讲,我们可以建立一个世界模型,在其中进行练习,并将所学应用到现实世界中。
这两篇论文都极具远见卓识。随著该领域的进步,研究人员的设想最终得以实现,因此它们产生了深远的影响。但就当时的时代而言,这两篇论文几乎就像科幻小说一样。
1990年,全球运算能力比现在少了大约100兆到1千万亿倍。当时,全世界的总运算能力可能只有10到100吉浮点运算/秒(GFAFLOPS)。而光是2024年,就售出了数十泽浮点运算/秒(ZFLOPS,即10^22 FLOPS)的运算能力。 1990年,全球数位资料总量约为10拍位元组(PB),这个体积小到连我们现在单次训练所需视讯资料的0.005%都不到。到了2026年,这个体积已经爆炸式增加2,200万倍,达到221泽字节。
但科技不断进步,最强大的梦想也不会消亡。
近三十年后,2018年3月,当时就职于Google大脑的David Ha和Schmidhuber发表了一篇题为《世界模型》的论文。 4

世界模型是V+M:它可以接收观察结果并想像可能的未来。控制器是代理或策略:它选择采取哪些行动。
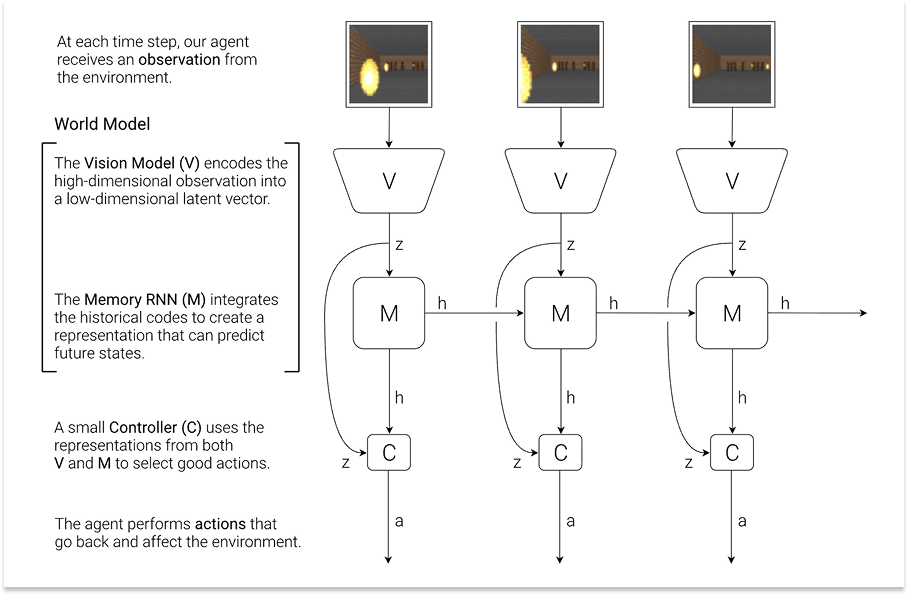
这篇论文加入了几个世纪以来思想实验、小说和电影的探讨。梦境可能是现实,现实也可能是梦境。但如果我们真的能在梦中行动呢?那会对现实造成什么影响?
而且……成功了。智能体能够解决它在现实中从未遇到的任务。梦境如此真实。
从计算机科学的角度来看,这令人震惊。但这真的那么令人惊讶吗?人类不就是这样在世界上生存的吗?
加州大学尔湾分校认知科学教授唐纳德霍夫曼将这一观点推向了极致。他认为,我们每个人都戴著“现实头盔”,将量子世界的惊人复杂性简化为一个用户友好的介面。现实太过丰富,所以我们只能透过一种持续的清醒梦境来驾驭它。
这个兔子洞可以深到你想钻多深都行。但无论深浅,最终都会指向世界模型。
Ha 和 Schmidhuber 证明,电脑或许能够像我们一样看待世界:创建模拟来根据行动预测未来状态,根据这些预测采取行动,更新,并循环往复。
行动胜于言语。
语言是不够的(程式码也是)。
我们来玩个游戏吧。
拍手五次。
现在,请不要真的拍手,而是用语言来描述拍手的动作。
它们在空间中的位置,它们彼此之间的相对位置,精确到皮秒。接触点。声音。你的双手靠近、接触、分开时的样子。它们如何相互挤压。你两掌之间的空气发生了什么变化。拍手时你看到的景象。别忘了你的手臂。它们如何弯曲以配合拍手?记住,这一切也要精确到皮秒。你袖子上的布料有什么反应?背景中发生了什么事?你旁边的人注意到你在拍手了吗?他们的反应是什么?你有没有因为在会议中拍手而被解雇?当时你本来应该专心工作,却在看一篇你不该看的文章,还按照文章的指示拍手?描述一下你老板额头上的青筋。它爆了吗?
你不能这么做,对吧?好了,别说了。我的意思已经表达清楚了。
语言是对现实的一种损失极大的压缩。
语言当然很重要。它是我们沟通和协调的方式。猜谜游戏就说明了,在交流思想时,语言比行动更有效率。语言学习者在这方面扮演重要角色。但仅仅依靠语言是不够的。
那么代码呢?程式码是一种非常精确的语言,它可以让机器执行操作。
我请克劳德「帮我写一个在真实环境下模拟双手拍手五次的程式」。结果他做出了这个。看起来很痛苦。

人们相信,随著规模的扩大,语言和程式码将能够解决所有时空智慧挑战,并产生通用人工智慧(AGI)或超级人工智慧(ASI)。
有人认为,程式码是解决许多现实世界智慧挑战的关键,因为它能够精确地指导所有物理形态。
我们并不认同这种观点。基于程式码的模拟远非梦想的实现。它受制于规则,无法应对现实中随机而复杂的各种情况。
在赫尔曼·黑塞的小说《玻璃珠游戏》(Das Glasperlenspiel )中,读者被引入卡斯塔利亚——一个致力于纯粹思想的未来知识乌托邦。这部小说为黑塞赢得了1946年的诺贝尔文学奖。卡斯塔利亚的核心是一款精妙的游戏,即书名中的“玻璃珠游戏”,它将人类所有的知识综合成一种单一的形式语言。玩家们像创作赋格曲一样创作「游戏」。一个回合可能将巴哈的康塔塔、一个数学证明,甚至是孔子的一段话连结起来。这款游戏是终极的抽象:它将人类文化的全部浓缩成符号操作。

大型语言模式就是我们的卡斯塔利亚人。它们是精妙的符号操控者,能够将人类所有的文本知识连结起来。它们可以讨论物理学、创作诗歌、编写程式码,甚至解释棒球规则。它们的确是人类历史上最伟大的智力成就之一。
但它们完全局限于表象的范畴。它们可以描述拍手,但它们自己却无法拍手。它们可以谈论重力,但它们对重力的理解远不及蹒跚学步的幼儿。它们无法像人体一样,透过成千上万次的跌倒和踉跄来学习「向下」的含义。
语言模型对下一个词元的预测能力非常出色。唯一的问题是,词元就像柏拉图洞穴墙上的影子一样,你无法透过程式码模拟出逼真的体育场人群,就像你无法描述出那里的景像一样。
如果语言和程式码这两项人类最强大的发明都不足以代表我们的世界,那我们还剩下什么呢?
答案是世界模型
世界模型为通往通用人工智慧(AGI)的道路提供了另一种途径。它们提供了一条计算当今无法计算之物的路径。它们从克内希特所追求的与现实的复杂接触中汲取经验。
世界模型提供了一种高效能进行非确定性计算的方法,并且可以运行在传统计算限制下不可能进行的模拟。
真正的智慧必须来自对世界的观察;来自对行为及其后果的理解;来自语言只能指向的事物。
什么是世界模型?
更正式地说,世界模型是一个互动式预测模型,它模拟时空环境以回应各种行为。
LLM 预测句子中的下一个词,而世界模型则根据当前状态和控制输入预测下一个状态(即近期未来)。
更简洁地说:语言学习模型学习语言结构,世界模型学习因果关系结构。
这是世界模型的一个简单定义。它很准确,但不足以理解世界模型是如何运作的。要理解世界模型,你需要了解以下四点:
世界模型的作用
世界模型以计算的方式实现相同的功能。它接收观测资料(通常是视讯帧,但也可以使用任何感官资料),建构环境状态的压缩内部表征,并预测该状态将如何响应动作而变化。
本质上,它是一个经过学习的物理引擎,但它并不依赖手写的方程式。它不是从基本原理出发计算重力、碰撞和摩擦力,而是观察了数十亿次重力、碰撞和摩擦力的变化,并从中学习规律。
这使得世界模型成为建构智能体(即在环境中行动的人工智慧系统)的强大工具。世界模型可以从三个方面帮助智能体:
它们能够进行更长期的规划。智能体可以在采取行动之前「想像」不同行动的后果,就像棋手思考几步棋一样,只不过这里的「棋盘」可以是任何环境或现实世界。
它们为智能体提供了丰富的世界表征,供其学习行为。基于世界模型内部表征训练的智能体,学会了根据对行动至关重要的特征来「看待」世界,而不是仅仅关注原始像素。
基于以上三点原因,世界模型的优点在于它们能够实现泛化。如果能够创造出对行为做出如同现实世界般响应的世界,就可以利用这些世界安全、经济、高效地训练具身智能体,使其能够在任何虚拟世界或现实世界中行动。
需要明确的是,世界模型的核心问题在于:模拟环境是否足够逼真,能够用于训练并将训练成果迁移到现实世界。 或者更普遍地说,是否可以「在模拟器中进行预训练」。越来越多的证据表明,答案是肯定的。
Ai2 ,即艾伦人工智慧研究所,是由已故微软联合创始人保罗艾伦创立并资助的非营利组织。它致力于开源研究和工具开发,包括最近发布的 MolmoBot,这是一个「完全在模拟环境中训练的机器人开放模型套件」。
「我们的结果表明,模拟到现实的零次操作转移是可能的,」他们在推特上写道。
参与该计划的普林斯顿大学教授兼GoogleDeepMind研究员Dhruv Shah表示:“在易于模拟的任务范围内,纯粹通过模拟训练的策略优于使用数千小时真实数据训练的SOTA VLA!”
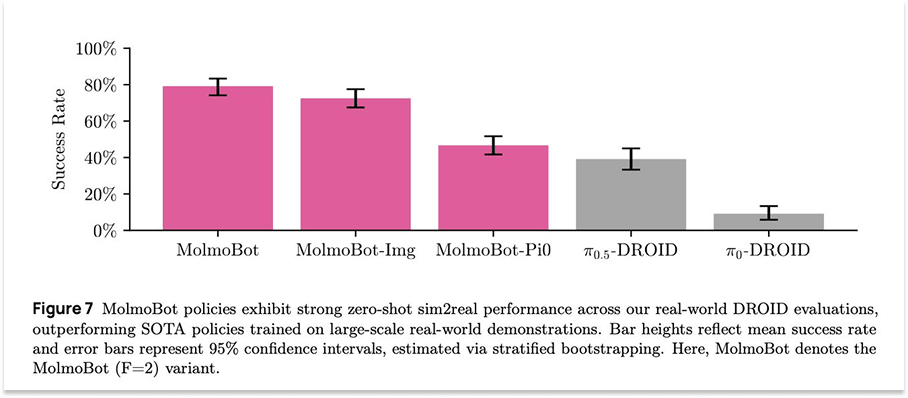
这是一个相当惊人的发现。我们以及更广泛的世界模型领域的一个重点是扩大易于模拟的任务范围。
这就是 Ha 和 Schmidhuber 在 2018 年所证明的。它仍然是该领域的核心前景。
世界模型是如何建构的
世界模型仍处于发展初期。目前还没有哪一种单一方法或组合方法被证明是最优的,这意味著通用世界模型的最终架构仍然是一个悬而未决的问题。然而,训练过程中存在一些可重复使用的要素。
当模型透过互动进行学习时,同样的结构也适用——之前、行动、之后——但数据是动态生成的,而不是预先收集的,行动来自模型本身正在发展的策略,而不是来自外部来源。
世界模型的核心目标保持不变:给定当前状态和动作或指令,预测下一个状态。它接收到帧t和动作a ,并尝试产生状态帧t+1。
因此,现代世界模型包含一个潜在空间:一种压缩的、学习到的表征,其中只保留了最基本的资讯。
视觉编码器将每一帧压缩成一个紧凑的向量(场景的数学指纹),模型学习预测下一个指纹——而不是4K帧中的每个像素——以响应动作。这就是计算效率的来源。
为了准确地模拟世界的演变,世界模型也必须学会表示所有可能的结果。这种结果的不确定性通常被称为环境的随机性。
世界模型必须学会应对它们尚不了解的事物(认知不确定性:例如,从未见过交通号志的模型不会知道黄灯之后是红灯)和本质上不可知的事物(偶然不确定性:随机性,例如掷骰子5 )。
即使模型已经学习了所有关于环境行为的资讯(将其「认知」不确定性降至最低),接下来发生的事情几乎总会存在一些固有的不确定性(「偶然」不确定性)。这与纯粹的娱乐视讯模型截然不同,后者只需能够预测世界状态的常见演变即可表现良好。
如果使用简单的预测方法(例如,使用均方误差或 MSE 简单训练的模型)来预测汽车转弯,模型可能会变得“模糊”,因为它会对所有可能的结果进行平均。汽车可能转弯后留在左侧车道,也可能并入右侧车道。实际上,使误差最小化的轨迹是不太可能发生的,即汽车保持在两个车道中间。这就是模糊性所在,不同的模型对此的处理方式也不同。
扩散模型透过逐渐扩散到结果来避免这个问题,使模型能够确定结果分布的特定模式,对清晰、合理的未来进行采样,而不是对所有可能性进行平均。
每个结果有多个标记的自回归模型也能处理多模态;透过依序对标记进行取样,它们确保未来的标记预测与先前的预测一致。
相较之下, JEPA 架构透过简单地规避模糊问题来解决它。 JEPA 从不解码回像素空间,从而很大程度上避免了明确地对模糊分布进行建模。它运行在一个平均化影响较小的空间中,因为我们不期望这些模型预测帧,而是期望它们产生对下游任务有用的表示。
这个过程的最终结果取决于你的需求。如果你要建立一个可视化的世界模拟器——一个可以观看或探索的装置——你需要透过视觉解码器将潜在的预测解码回像素,从而产生对未来可能景象的想像影片。这正是GoogleDeepMind和World Labs的演示看起来逼真且令人印象深刻的原因。
训练世界模型的方法有很多。我们很快就会介绍这些方法,并结合该领域近八年的发展历程,探讨它们是如何演变和相互发展的。
目前,请记住这一点:将观察资料与导致这些观察结果发生的行为结合,训练世界模型来预测下一个状态,训练智能体来预测这些世界中的下一个行为。
为什么行动是压缩的终极形式
世界模型背后的一个关键见解是:行动是压缩的最终形式。
想想当你决定向左迈步避开水坑时会发生什么事。你的大脑会处理视觉场景(人行道、水坑、周围的人、路沿、驶来的公车),预测近期情况(水坑不会移动,公车会通过,你身后的人会继续走),评估各种选择(向左迈步、向右迈步、跳跃、接受鞋子湿透的事实),然后选择其中一种。
旁观者无法看透你的内心,无法确切知道你在想什么,也无法了解你的潜意识里在处理什么。他们不知道你是否疲惫,是否匆忙。他们不了解你的道德准则,也不知道你会如何解答电车难题。他们不需要知道这些。他们看到的只是你近乎瞬间完成的计算结果:向左走。
对我来说,那就是魔法。
当然,并非每个人都能做出正确的决定。快进视频,你也能了解到后果。向左踏一步,就会踩进更大的水坑。向左踏一步,就会被车子剐蹭。往左走一步,就会把婴儿从婴儿车里撞出来。经过数十亿次的观察、指示和行动,我们不仅学会了人类如何根据输入做出反应,还学会了这些决定的后果。集体世界模型比任何个体都更聪明地行动。
让我们把视角拉回个体身上。如果你能完美地重建一个人的观察和行动轨迹,你就能获得他们与现实互动的近乎完整的记录。你会知道他们看到了什么,以及他们对此做了什么。世界模型正是学习这种映射关系。它将空间和时间压缩成一个紧凑的表征,然后利用行动来展开接下来发生的事情。这正是世界模型运算效率如此之高的原因。
这也是为什么世界模型能够处理传统模拟无法处理的随机性的原因。为了理解这一点,让我们运用对世界模型工作原理的新理解,重新审视曼联的比赛。
在传统的模拟引擎中,每一种可能的行为都需要编写程式码。如果你想让一千名足球迷对进球做出真实的反应,就需要为每种反应类型写出规则。计算成本会随著智能体的数量及其交互复杂性的增加而增加。
在世界模型中,成本固定为神经网路的一次迭代。随机、复杂、充满变数的人类现实已被融入学习到的权重中,并从模式训练所使用的数百万小时影片中吸收。该模型并未计算人群应该做什么,而是观察人群的实际行为,并利用这些资讯做出可能的预测。
这就是我所说的「世界模型计算不可计算之物」的意思。传统计算是确定性的:已知输入、已知规则、已知输出。现实世界并非确定性,因此世界模型甚至不会尝试将这些因素编码进去。它们观察、学习并执行,计算成本固定,无论场景多么复杂。
世界模式与政策
在我们继续深入探讨之前,还有一点需要区分,这一点在关于世界模型的典型讨论中常常被混淆。
世界模型是对环境的模拟;它接收行动并产生预测观察结果;它向你展示如果你做某事将会发生什么。
策略是智能体在特定环境中行动的大脑。它接收观察结果(通常也包括指令),并产生行动;它决定要做什么。
世界模式是梦想。政策是梦想家。梦想家行动,梦想回应。梦想回应,梦想家行动。
实际上,两者之间的关系比这种区分所暗示的更为密切和错综复杂。近期研究探讨了在世界模型基础上训练策略,或从一开始就将二者结合起来建构策略的方法。首先,我们需要世界模型的权重——该模型已经学会了如何预测接下来会发生什么——然后,不再训练模型来预测未来的框架或状态,而是训练它来预测未来的行动。
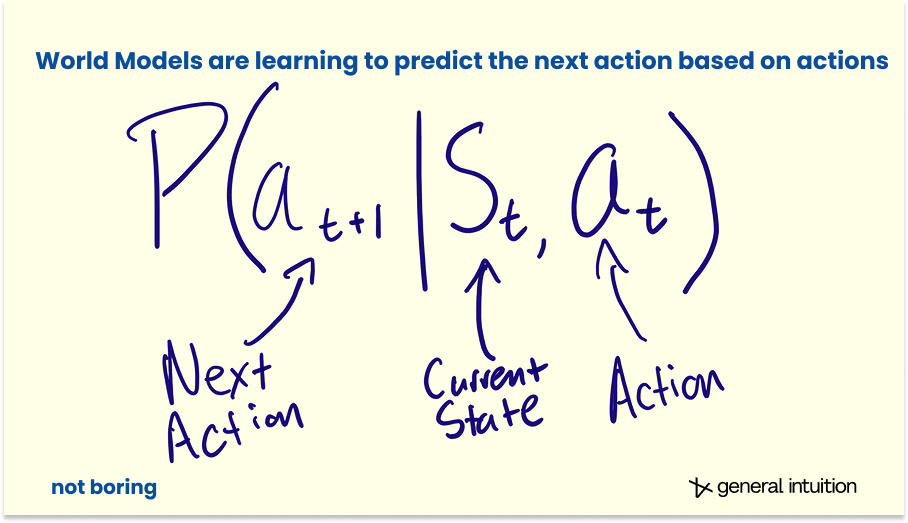
一个能够预测世界的系统,也能更快学会如何在世界中行动。理解和行动并非两种独立且生硬拼凑的技能,而是同一种技能的不同表现。至少,我们的研究以及其他实验室的研究都开始显示这一点。
这意味著,如果你建立了一个足够好的世界模型,你就可以更有效地训练策略,使其在它生成的世界中采取行动。
这是该领域在很短时间内学到的众多重要知识之一。事实证明,直觉和想像力是同一枚硬币的两面。
世界模型简史
一方面,概括世界模型的现代发展史应该非常容易。毕竟,哈和施密德胡伯出版《世界模型》至今不过八年。
另一方面,短短八年间发生了翻天覆地的变化。在此期间,该领域经历了四个重大变革:每次变革都促使该领域的研究重点转向新的问题。本文重点介绍其中一些最重要的论文,而《世界新闻》的订阅用户可以在文章末尾找到完整的关键论文清单并下载。

Wave 0,即 1990-1991 年,是深度学习出现之前的时代。研究人员首次提出了智能体可以学习世界内部模型并将其用于预测和规划的想法。他们提出并回答了这样一个问题:世界模型会做什么?
这是理查德·萨顿和Dyna 。这是尤尔根·施密德胡伯和《让世界可微》 。在我们拥有运算能力、资料或架构之前,我们只有梦想,在梦境中等待现实追赶。
第一波调查(2018-2019 年)提出的问题是: “这真的可行吗?”
基于Ha和Schmidhuber的研究,第一个范式是使用视讯自编码器(VAE)压缩帧,以循环神经网路(RNN)模拟动态,并在生成的梦境中训练策略。也就是说:压缩你所看到的画面,预测接下来会发生什么,并训练智能体在模拟环境中行动。
当时的问题是,在想像(梦境)中进行学习是否可行。研究人员尝试使用小型模型和简单的环境来验证概念,从而找到答案。毫不夸张地说, 下一个重大突破最初看起来像个玩具。 Atari的模型为基础的强化学习引入了 Atari 100k 基准测试:SimPLe 演算法能否仅透过 10 万个真实环境步骤(约两小时的游戏时间)来学习 Atari 游戏。
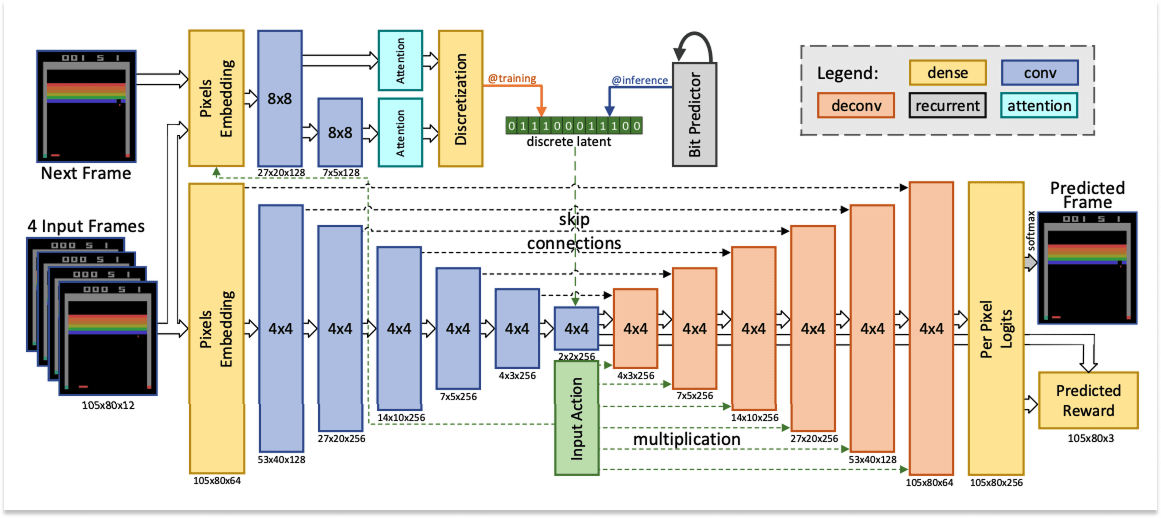
答案是肯定的。 SimPLe 学会了玩 26 款 Atari 游戏,并在样本效率(即达到给定分数所需的步骤数)方面击败了竞争对手的模型。
这正是第二阶段(2020-2022 年)的核心问题: “世界模型能否与人类的表现相匹配?”
由GoogleDeepMind的Danijar Hafner开发的DreamerV2迅速找到了答案。他们使用了一种带有离散潜在表征的循环状态空间模型(RSSM) ——该系统维护著一个压缩的、运行中的世界记忆,并随著每次观察进行更新。 DreamerV2成为第一款在包含55款游戏的Atari基准测试6中达到人类等级的世界模型智能体。它完全是在想像中,使用单一GPU进行训练的。
同年,DeepMind 的另一个团队在《自然》杂志上发表了题为《透过学习模型进行规划来精通 Atari、围棋、国际象棋和将棋》的论文。论文描述了他们的MuZero模型,该模型也赢得了 Atari 游戏(以及围棋等其他游戏),但它采用的理念几乎与上述论文完全相反。

DreamerV2 产生可观察的梦境环境并在其中进行训练,而MuZero 则从未生成任何可观察的东西,完全在它自己发明的抽象潜在表示中进行规划,并且做得很好。
事实上,它的表现非常出色,甚至超越了专门针对围棋的模型。 2016年,DeepMind的AlphaGo以4比1击败了人类围棋冠军李世石。 AlphaGo的训练资料库包含大量人类专家对局以及自我对弈的数据,并且围棋规则被硬编码到模型中。第二年, AlphaGoZero完全依赖自我对弈进行训练,没有使用任何人类对局数据,只有围棋规则,却以100比0的比分击败了AlphaGo。在同一年, AlphaGoZero的泛化能力得到了进一步提升。 它也尝试过其他游戏,例如国际象棋和将棋,并在几个小时内就掌握了这些游戏的精髓。然后在2019年(预印本), MuZero完全透过观察和结果,从零开始学习了所有内容,包括规则、游戏动态和价值函数。它在围棋、西洋棋和将棋(AlphaZero了解这些游戏的规则)上与AlphaZero势均力敌,同时还能泛化到57款雅达利游戏中(在这些游戏中,「规则」甚至都不是一个明确定义的概念)。
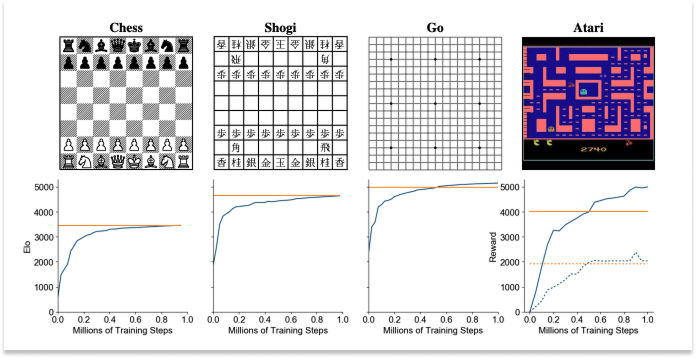
每推出一个新模型,先前人类预先设定的规则、策略、部位价值等都会被移除。模型转而从零开始学习。 MuZero 是这一发展历程的终点,它完全是学习而来的。
随著 MuZero 的成功,该领域现在出现了两种对立的思想流派:产生可观察未来的生成世界模型,以及在抽象空间中进行预测的潜在世界模型,即使它们当时还没有被称为「潜在」世界模型。
在潜在层面,2022年,Yann LeCun以Meta和纽约大学库朗数学研究所双重身份发表了一篇影响深远的立场文件,提出了一种与生成模型截然不同的理念,更像是《MuZero:迈向自主机器智能之路》 。他新成立的世界模型公司AMI正是以此文件命名。

LeCun 的联合嵌入预测架构 (JEPA)反对完全产生像素。与 MuZero 类似,JEPA 不是预测世界的外观,而是预测其意义。它预测未来状态的抽象表示,并有意舍弃不可预测的视觉细节。
同年,在生成式建模领域,由Vincent Micheli和Eloi Alonso(General Intuition未来的两位共同创办人)开发的IRIS (2022)将世界建模重新定义为基于已学习的图像标记词汇的语言建模。 IRIS并没有采用循环状态空间模型,而是使用了一种类似GPT的自回归Transformer模型来处理离散的视觉标记。简而言之,IRIS借鉴了语言模型的机制并将其应用于世界建模。
IRIS 的出现填补了以往的许多空白。 IRIS 世界模型其实是一种语言模型,但它的词汇表是图像和动作,而非文字。这使得语言模型的可扩展性直接应用于世界建模:高效的注意力机制、可扩展性规律以及所有为大型语言模型构建的工程基础设施,现在都可以应用于物理世界的学习。
Dreamer 的缺点在于它无法对下一个潜在状态的联合规律进行建模(例如,无法处理多模态资料),而 IRIS 则将下一个潜在状态表示为一系列离散的标记,并进行自回归预测,这意味著它现在能够预测多种结果。虽然 Dreamer 透过使用比人类多得多的数据击败了人类,但 IRIS 是第一个在相同游戏资料量(两小时)下击败人类的想像学习方法。