这篇文章还有更好的视觉化方式(使用动态图表,可以更清晰地解释一些概念和基准测试结果)。如果您喜欢这种方式,请查看: Binary Trie Group-Depth Benchmark — 比预期更窄
S1 – 执行摘要
二元树是以太坊协议的初步构想,旨在取代未来的状态树。目前,尚未有任何二元树实现进行大规模基准测试——无论是群组深度还是其他任何方面。鉴于此转型已列入路线图,评估效能特征是进行合理原型设计的前提。 Geth 实作( EIP-7864 )提供了一个 ` --bintrie.groupdepth参数,用于控制二元树层级在磁碟节点中的打包方式;本研究对八种配置进行了基准测试,以确定最佳设定。
结论:最佳选择是 GD-5 或 GD-6,取决于工作负载。 GD-5 的写入效能比 GD-4 高 7%(6.94 Mgas/s 对 6.47 Mgas/s, p < 1e-9)。 GD-6 在读取效能(6.39 Mgas/s)和混合工作负载(比 GD-4 高 19%,p < 1e-3)方面领先。 GD-7 证实性能在 GD-6 之后开始下降。
我们测试了
在包含约 4 亿个状态条目的 360 GB 资料库上,使用了八种组深度配置(GD-1 至 GD-8)。五种基准测试类型——两种合成测试(原始 SLOAD/SSTORE)和三种 ERC20 合约工作负载——每种类型在冷缓存协议下运行 9 次。所有结果均使用中位数,并采用Mann-Whitney U检定进行显著性检定。
我们发现了什么
- 读取结果证实了直觉(第 4 节):树越宽,读取速度越快。 GD-8 的读取吞吐量是 GD-1 的两倍以上(5.59 Mgas/s 对比 2.65 Mgas/s)。 GD-6 的读取吞吐量最高(6.39 Mgas/s),其次是 GD-5(6.11 Mgas/s)和 GD-7(6.04 Mgas/s)。 GD-3 到 GD-8 的吞吐量范围在 5.2 到 6.4 Mgas/s 之间。
- 写入性能展现出更明显的优化(第 5 节):GD-5 以 629 毫秒(6.94 Mgas/s)的写入速度位居榜首,比 GD-4(678 毫秒,6.47 Mgas/s)快 7%,比 GD-8(982 毫秒,4.47 Mgas/s)快 55%。写入效能的拐点位于 GD-5 和 GD-6 之间(杂凑/读取比率超过 1.0)。
- 节点大小在 GD-7 时达到 Pebble 区块大小的边界(第 5 节):每个 GD-7 节点序列化后约为 4 KB(128 × 32 位元组)-恰好是 Pebble 区块大小。低于此边界(GD-6:约 2 KB)时,每个节点都包含在一个区块内。高于此边界时,每个节点的读取操作可能需要两个区块。 Gary Rong 的 NVMe 基准测试表明,在 QD=1 时,随机读取 8 KB 的资料比读取 4 KB 的资料延迟高出 54%(77.8 微秒 vs 50.6 微秒)。这种每个节点的 I/O 开销会在约 37 个路径节点上累积,这解释了为什么 GD-7 的读取速度比 GD-6 慢,尽管路径更短。
- 最佳方案是 GD-5 或 GD-6 (第 6 节):GD-5 在写入效能上比 GD-4 高出 7%,而 GD-6 在读取效能(比 GD-5 高出 5%)和混合工作负载效能(比 GD-4 高出 19%)方面更胜一筹。 GD-7 证实了这一拐点——在所有基准测试中均逊于 GD-6。由于以太币的读取操作较多,因此 GD-6 可能是更合适的预设方案。
如何阅读这篇文章
- 第 2 节(背景)介绍了二元树和群体深度概念。
- 第 3 节(方法论)详细介绍了基准测试设定。
- 第 4-6 节以叙事弧线呈现结果:阅读、写作,然后是权衡。
- 第 7 节(模式)探讨了交叉观察结果。
- 第 8 节(结论)提出了双重建议和未解决的问题。
时间不够?那就从第 4 部分「ERC20 阅读:深度至关重要」开始——在这一部分,群体深度差异最为明显,并为其余的分析奠定了基础。

S2 – 背景
什么是二元树?
EIP-7864 提议用二进位 trie 树替换以太坊的 Merkle Patricia trie 树(MPT)。二元 trie 树将帐户 trie 树和所有储存 trie 树合并成一棵树,使用 SHA-256 杂凑演算法取代 Keccak-256 杂凑演算法,并储存映射到 256 个值的 32 位元组树干。这种设计简化了无状态客户端的见证生成,并实现了更有效率的证明。
从 MPT 到二元树的过渡是以太坊状态层最重要的变化之一。新结构的性能特征将直接影响区块处理时间、同步速度和验证者的经济效益。
什么是群组深度?
trie 树在根本层面上总是二元树-每个内部节点刚好有两个子节点(左子节点对应位元 0,右子节点对应位元 1)。群组深度控制单一磁碟节点中包含多少个二元树层级。在 GD-N 演算法中,每个储存的节点封装了一个 N 层二元树子树,因此从外部观察,它看起来有 2^N 个子节点:
- GD-1:每个节点 1 个二进位等级 → 2 个子指针,到叶子节点的路径上有 256 个节点
- GD-2:每个节点 2 个二进位等级 → 4 个子指针,路径上有 128 个节点
- GD-3:每个节点 3 个二进位等级 → 8 个子指针,路径上约 86 个节点
- GD-4:每个节点 4 个二进位等级 → 16 个子指针,路径上 64 节点
- GD-5:每个节点 5 个二进位等级 → 32 个子指针,路径上约 52 个节点
- GD-6:每个节点 6 个二进位等级 → 64 个子指针,路径上约 43 个节点
- GD-7:每个节点 7 个二进位等级 → 128 个子指针,路径上约 37 个节点
- GD-8:每个节点 8 个二进位等级 → 256 个子指针,路径上 32 个节点
你可以把它想像成邮递区号:GD-1 每次读取地址一位数字(256 步),而 GD-8 一次读取 8 位数字(32 步)。步数越少,磁碟读取次数就越少——但每个「捆绑节点」都更大,更新成本也更高,因为其内部的二进位子树必须重新杂凑。
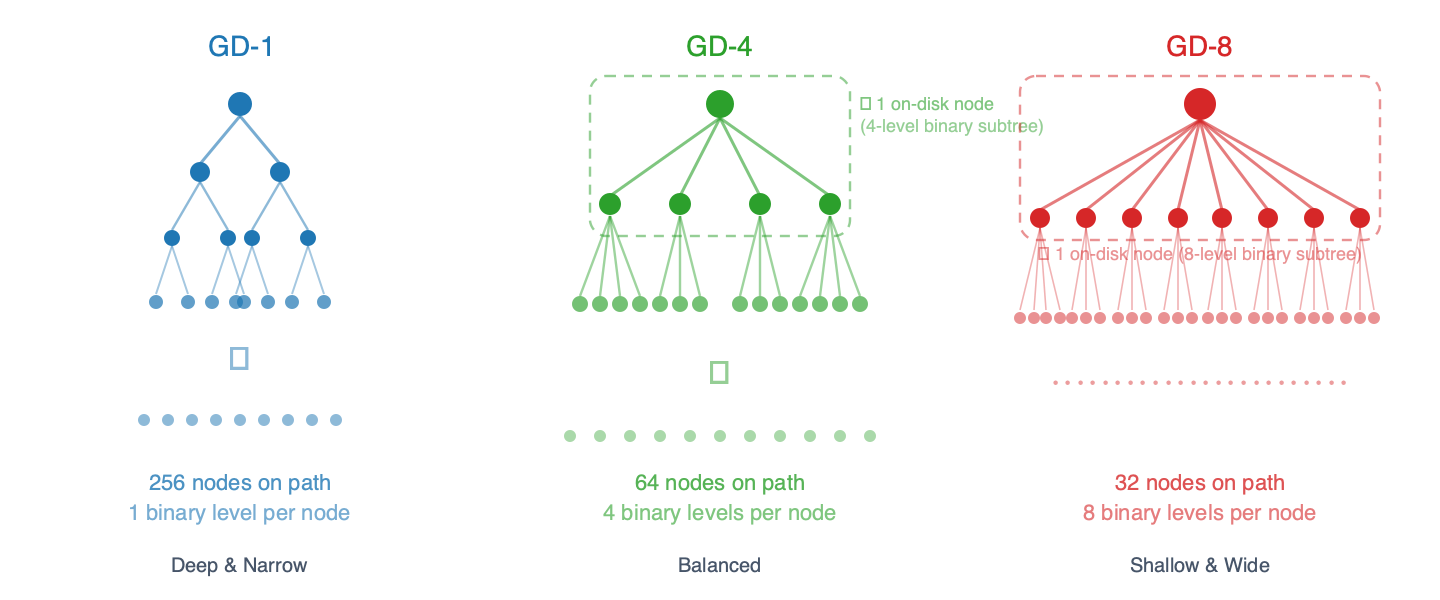
图 1 – 不同分组深度下的树状结构。每个节点内部捆绑了 N 个二进位层级,从而减少了到达叶节点的路径上的磁碟节点数量。
理论上,这种权衡很简单:读取操作受益于浅树结构(到达叶节点所需的磁碟 I/O 操作更少),而写入操作则受制于宽节点结构(节点修改时需要更多的内部杂凑运算)。问题在于,这种权衡的临界点在哪里。
S3 – 方法论
概括
基准测试设置
| 范围 | 价值 |
|---|---|
| 机器 | QEMU 虚拟机 – 8 个虚拟 CPU,30 GB 内存,3.9 TB 固态硬碟,Ubuntu 24.04 LTS |
| 资料库 | 约 360 GB,约 4 亿个帐户 + 储存槽位 |
| 配置 | GD-1、GD-2、GD-3、GD-4、GD-5、GD-6、GD-7、GD-8(Pebble,geth 使用的 LSM 树储存引擎,4KB 区块大小) |
| 协定 | 冷缓存(作业系统页面快取已清除 + Pebble 快取=0,运行间) |
| 跑 | 每个基准测试每个配置运行 10 次;排除运行 1(残留温度) |
| 气体目标 | 每个方块含1亿气体 |
统计方法
- 9 次保留运行的每次运行区块中位数汇总
- 用于成对比较的曼-惠特尼U检定(非参数检定)
- 效应量以与基线(GD-1)的百分比差异表示。
- 一致性评估的变异系数 (CV%)
基准分类
a) 综合基准测试sstore_variants (写入)和sload_benchmark (读取)。这些测试使用 EIP-7702 委托机制,并采用顺序储存槽。键值按数字顺序排列,导致 trie 树中存在大量的前缀共用。
b) ERC20 基准测试balanceof (读取)、 approve (写入)和mixed 。这些测试使用真实的 ERC-20 合约代码。储存金钥是随机位址的 Keccak 杂凑值,从而在 trie 树中产生均匀分布的存取模式。
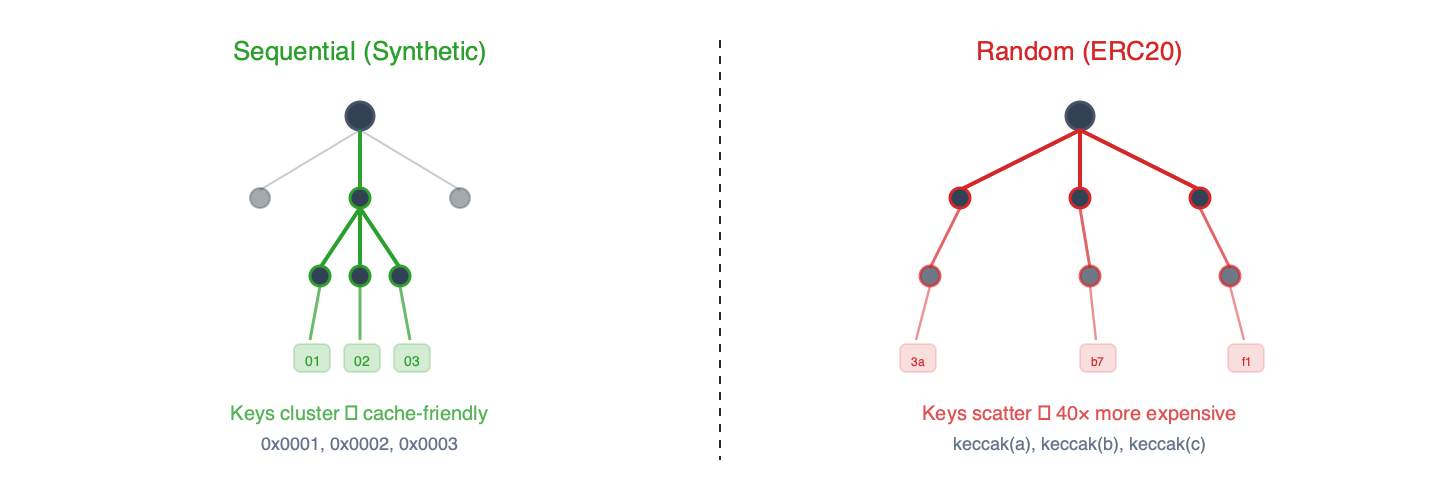
图 2 – 顺序键共享 trie 树前缀,并受益于快取。 Keccak 哈希键均匀分布,导致每一层都进行冷读取。
区块组成说明
执行规范测试框架会将所有基准测试交易一次传送到 Geth 的记忆体池(在 1秒内)。 Geth 的开发模式矿工( dev.period=10 )随后会在 10 秒的区块建立视窗内按顺序处理来自该记忆体池的交易——当计时器到期时,它会挖出所有已处理的交易。瓶颈在于 trie 树的运行时间,而非 gas 容量:每个 ERC20 认证交易仅消耗约 4.4M gas(1 亿 gas 的区块 gas 上限大约可以容纳 22 笔交易),但在速度较慢的配置下,trie 树操作(遍历、更新、哈希、提交)几乎会消耗整个交易时间,即使是整个交易时间也是如此。设定交易(简单的 ETH 转帐)在 77 毫秒内处理 7 笔交易,证实了 trie 树的成本——而非交易开销——才是限制因素。
经过验证的冷缓存移除(第三阶段),所有配置现在每个区块处理 1 笔交易(中位数 tx_count=1)。机制解释仍然有效——10 秒的dev.period作为时间预算,而 trie 树操作成本决定了可以容纳多少笔交易。 Mgas /s(吞吐量)是正确的比较指标,因为它消除了不同配置之间的 gas 差异。如果显示的是原始毫秒数,则反映的是该配置区块组成所需的实际区块处理时间。
S4 – 第一幕:阅读证实直觉
ERC20 读法:深度至关重要
| GD | 状态读取(毫秒) | 总计(毫秒) | 兆气体/秒 | 与 GD-1 (Mgas/s) 相比 |
|---|---|---|---|---|
| 1 | 5,878 | 6,284 | 2.65 | 基线 |
| 2 | 3,840 | 4,231 | 3.95 | +49% |
| 3 | 2,866 | 3,213 | 5.20 | +96% |
| 4 | 2,677 | 3,067 | 5.46 | +106% |
| 5 | 2,370 | 2,733 | 6.11 | +131% |
| 6 | 2,248 | 2,623 | 6.39 | +141% |
| 7 | 2,339 | 2,693 | 6.04 | +128% |
| 8 | 2,598 | 2,977 | 5.59 | +111% |
GD-1 到 GD-6 的读取吞吐量提升了约 2.4 倍。 GD -6 的读取吞吐量最高 (6.39 Mgas/s),其次是 GD-5 (6.11) 和 GD-7 (6.04)。读取效能从 GD-1 到 GD-6 单调递增,之后逐渐下降-如预期,由于路径较短,GD-4 (5.46) 的效能优于 GD-3 (5.20)。随著节点规模增加到足以抵销路径缩短带来的优势,GD-7 和 GD-8 的效能提升逐渐递减。
为什么与合成密钥存在如此巨大的差异? Keccak 密钥均匀分布,迫使从根到叶进行完整遍历。 GD-1 需要向下遍历 256 层;而 GD-8 只需 32 层。每一层都可能导致磁碟寻道。随机存取会暴露出完整的深度开销。
GD-3(3213毫秒,5.20兆位元组/秒)和GD-4(3067毫秒,5.46兆位元组/秒)在读取效能上非常接近,GD-4由于其路径更短(64个节点对比约86个节点)而略胜一筹,这与预期相符。 GD-3较小的节点序列化大小(约256位元组对比GD-4的约512位元组)与Pebble的4KB区块大小相辅相成,使得尽管树形差异很大,两者的效能差距仍保持在5%以内。 Pebble块大小的影响机制仍值得进一步研究(开放性问题#3 )。
每个插槽的成本:合成读取的成本约为 0.02 毫秒/插槽。 ERC20 读取的成本约为 0.4–1.0 毫秒/插槽(计算方法为 state_read_ms / 储存槽位_读取每个区块)-随机存取模式的成本是其 40 倍。
这个 40 倍的比率与 NVMe 的原始测量结果一致: Gary Rong 的磁碟页面读取基准测试显示,随机 4KB 读取速度为 77 MB/s,而顺序读取速度为 3,306 MB/s(43 倍),这证实了效能损失主要由 I/O 存取权而非 Pebble 开销模式。
为什么随机存取是基准而非例外?二元树将所有帐户和储存统一到一个树中。每个按键——无论是帐户余额、储存槽位还是程式码区块——都会经过 SHA256 杂凑处理,产生 256 位元金钥空间。单一合约的储存槽位分布在完全不同的树路径上。这使得随机存取成为二元树的基本存取模式,而非特殊情况。合成的顺序基准测试代表了不切实际的最佳情况,在统一的树部署中不可能出现。
目前来看,宽度越大越好——但也存在一定的限制。 GD-6 在读取效能方面领先,而 GD-7 和 GD-8 的效能提升则逐渐递减。接下来,我们测试了写入效能。
S5 – 第二幕:写作的惊喜
这是研究最重要的发现。
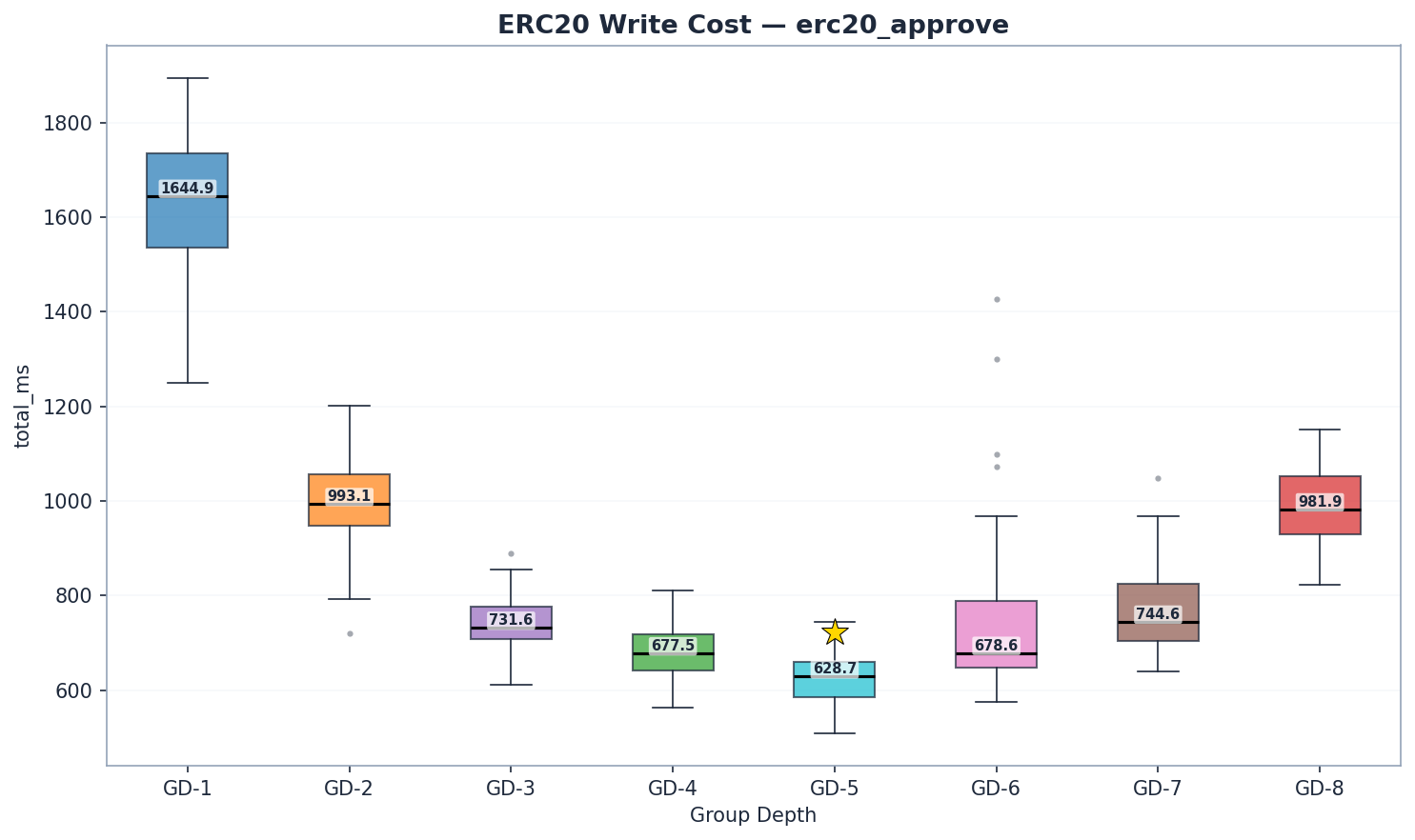
| GD | 状态读取 | trie_updates | 犯罪 | 全部的 | 兆气体/秒 |
|---|---|---|---|---|---|
| 1 | 812 | 691 | 77 | 1,645 | 2.67 |
| 2 | 483 | 393 | 61 | 993 | 4.42 |
| 3 | 349 | 287 | 44 | 732 | 5.95 |
| 4 | 313 | 254 | 53 | 678 | 6.47 |
| 5 | 271 | 242 | 57 | 629 | 6.94 |
| 6 | 272 | 283 | 76 | 679 | 6.41 |
| 7 | 264 | 328 | 103 | 745 | 5.81 |
| 8 | 313 | 433 | 158 | 982 | 4.47 |
trie_updates = state_hash_ms (AccountHashes + AccountUpdates + StorageUpdates) — 涵盖了完整的 trie 树变异和重哈希阶段,而不仅仅是哈希操作。所有配置均使用经过验证的冷缓存协定运行(作业系统页面快取会在运行之间清除)。第三阶段的变异系数 (CV) 在 Mgas/s 上大多小于10 %,证实了测量结果的可靠性。
GD-5 是最佳配方,气体流量为 6.94 Mgas/s,比 GD-4(6.47 Mgas/s, p < 1e-9)快 7%,比 GD-8(4.47 Mgas/s)快 55%。 GD-6(6.41 Mgas/s)排名第三,紧追在 GD-4 之后。 GD-7(5.81 Mgas/s)证实了气体流量的拐点在 GD-6 之后仍在继续。
组件分解图说明了一切:
- 读取速度: GD-5 (271 毫秒) 比 GD-4 (313 毫秒) 快 13%。 GD-6 (272 毫秒) 与 GD-5 相当,而 GD-7 (264 毫秒) 是速度最快的读取器-但原始的毫秒数必须与百万气体/秒 (Mgas/s) 结合才能进行公平的比较,因为每个模组的气体量可能有所不同。
- Trie 更新: GD-5 (242 ms) 比 GD-4 (254 ms)低 5% 。 GD-6 略微上升至 283 ms(比 GD-5 高 17%),并未像早期数据所显示的那样急剧上升。 GD-7 (328 ms) 和 GD-8 (433 ms) 证实了拐点仍在持续。
- 提交: GD-5 (57 毫秒) 略高于 GD-4 (53 毫秒)。 GD-6 (76 毫秒,比 GD-5 增加 33%) 和 GD-7 (103 毫秒) 的提交时间略有增加。真正的提交时间断崖出现在 GD-8 (158 毫秒),这是因为每次写入需要序列化约 256 KB 的数据,而每个节点约有 8 KB x 32 个路径节点。
写入拐点位于 GD-5 和 GD-6 之间:杂凑/读取成本比在 GD-6 处超过 1.0 (283/272 = 1.04),这表示 trie 更新开始超过读取成本。以 Mgas/s 计算,GD-5 (6.94) 比 GD-4 (6.47) 高 7%,比 GD-6 (6.41) 高 8%。
为什么?内部子树
每个深度为g的trie 节点都包含一个内部二叉树,该二叉子树有2^g - 1 2 g − 1 个节点,每次写入时都必须重新哈希。
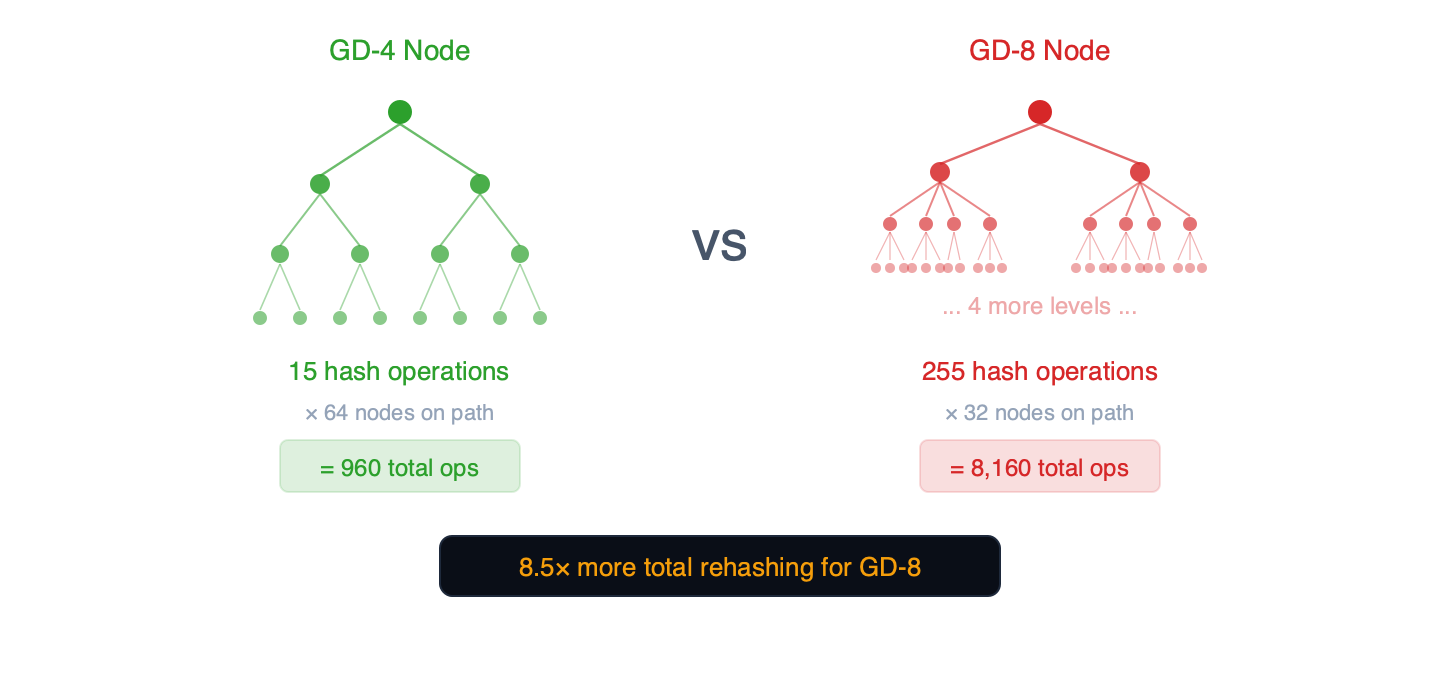
图 3 – 每个 trie 节点都包含一个内部二元树。节点越宽,每次写入所需的哈希运算量就呈指数级增长。
- GD-4 节点: 15 次内部杂凑操作 x 路径上的 64 个节点 =总共 960 次操作
- GD-5 节点: 31 次内部杂凑操作 x 路径上的约 52 个节点 =约 1,612 次总操作
- GD-8 节点: 255 次内部杂凑操作 x 路径上的 32 个节点 =总计 8,160 次操作
GD-5 找到了写入效能的最佳平衡点:其路径比 GD-4 短 19%(约 52 个节点对比 64 个节点),且每个节点的 31 次内部操作仍然可控。在 GD-6(每个节点 63 个内部节点)时,重新杂凑的成本略有上升——283 毫秒对比 GD-5 的 242 毫秒(+17%)。 GD-7(杂凑 328 毫秒,提交 103 毫秒)证实了拐点在 GD-6 之后仍在继续。写入效能的拐点位于 GD-5 和 GD-6 之间,此时杂凑/读取比率超过 1.0。
注: 17 倍的比例(255 次内部杂凑操作对比 15 次内部杂凑操作)是此资料结构的理论上限。我们的基准测试支援此机制:GD-8 trie 树的更新成本是 GD-4 的 1.71 倍(433 毫秒对比 254 毫秒),这与随机写入操作修改每个节点内部子树的一部分相符。 geth 实作是重哈希演算法的权威来源。
节点序列化大小
每个 trie 节点最多可储存 2^N 个子指标(每个指标 32 位元组)。 GD-4 节点:16 × 32 =约 512 位元组。 GD-7 节点:128 × 32 =约 4 KB-刚好是 Pebble 的区块大小。 GD-8 节点:256 × 32 =约 8 KB 。大小差异会产生连锁反应:
- Pebble 资料块边界: GD-6 节点(约 2 KB)可以容纳在一个 4 KB 的 Pebble 资料块内。 GD-7 节点(约 4 KB)则几乎占满整个资料区块-加上金钥开销,它们可能跨越两个资料区块,导致每次节点读取的 I/O 量翻倍。这部分解释了 GD-7 读取操作的逆向:尽管路径节点比 GD-6 少 14%(37 个节点对 43 个节点),但 GD-7 每次查找的总读取量约为 148 KB(37 × 4 KB),而 GD-6 每次查找的总读取量约为 86 KB(43 22 KB)。
- Pebble快取效率:在给定的快取预算内,可容纳的GD-8节点数量较少
- 写入放大:较大的串列节点会增加 LSM 压缩开销。
- 提交成本: 198% 的提交惩罚(158 毫秒对比 53 毫秒)部分反映了每个修改节点需要序列化的资料量是原来的 16 倍。

图 4 – 对于读取操作,只有向下遍历才重要(有利于 GD-8)。对于写入操作,重新杂凑和提交操作占主导地位(有利于 GD-4)。读取操作 = 仅步骤 1。写入操作 = 步骤 1 + 2 + 3。
S6 – 第三幕:权衡取舍
判决
| 标准 | GD-4 | GD-5 | GD-6 | GD-7 | GD-8 |
|---|---|---|---|---|---|
| 读取量(兆加仑/秒) | 5.46 | 6.11 | 6.39 | 6.04 | 5.59 |
| 写入量(兆气体/秒) | 6.47 | 6.94 | 6.41 | 5.81 | 4.47 |
| 混合气(兆气体/秒) | 5.13 | 6.09 | 6.27 | 5.87 | 5.43 |
| 类别获奖 | 0/3 | 1/3 | 2/3 | 0/3 | 0/3 |
GD-6 在读取和混合效能测试中均胜出;GD-5 在写入效能测试中胜出。 GD -5 的写入效能比 GD-4 高出 7%( p < 1e-9)。 GD-6 的读取效能比 GD-5 高出 5%,混合效能比 GD-4 高出 19%(p < 1e - 3)。 GD-7 的表现已过拐点,在所有三个基准测试中均逊于 GD-6。由于以太坊工作负载以读取为主,因此 GD-6 可能是更佳的预设选择,而 GD-5 则更适合写入为主的场景。
混合工作负载
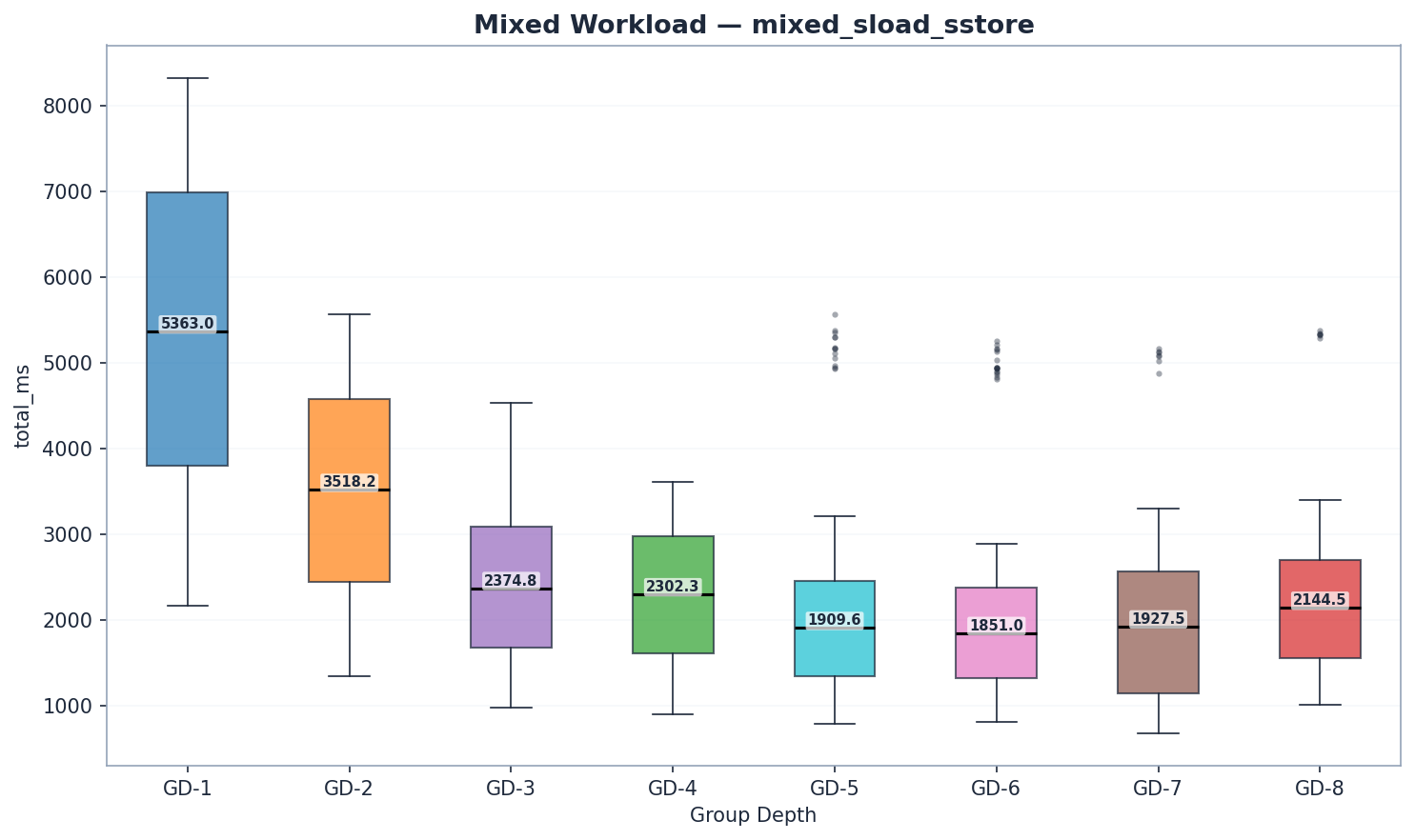
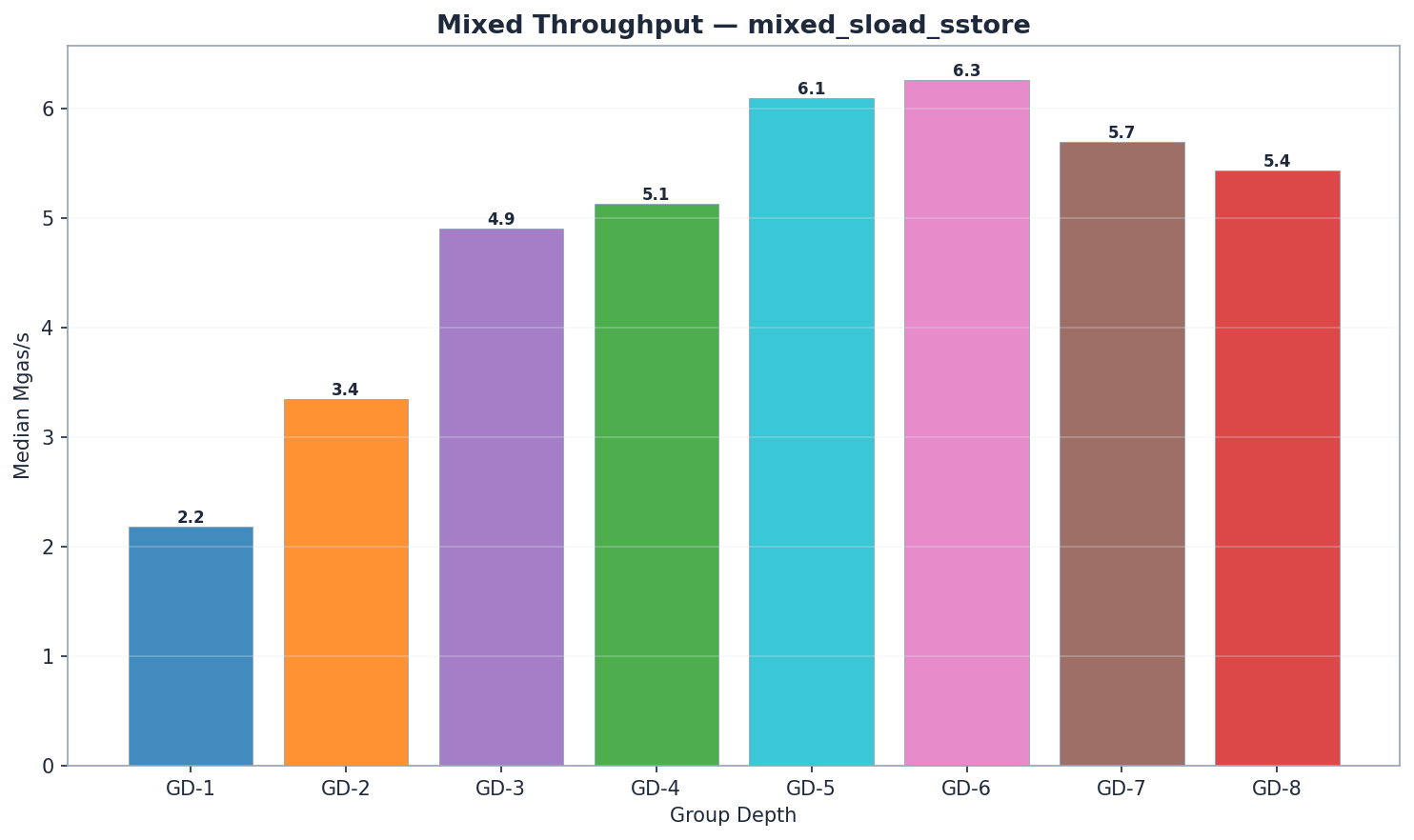
| GD | 状态读取 | trie_updates | 犯罪 | 总毫秒数 | 兆气体/秒 |
|---|---|---|---|---|---|
| 1 | 4,711 | 345 | 53 | 5,363 | 2.18 |
| 2 | 3,003 | 217 | 44 | 3,518 | 3.35 |
| 3 | 1,981 | 145 | 39 | 2,375 | 4.90 |
| 4 | 1,893 | 138 | 43 | 2,302 | 5.13 |
| 5 | 1,512 | 124 | 48 | 1,910 | 6.09 |
| 6 | 1,440 | 141 | 54 | 1,851 | 6.27 |
| 7 | 1,055 | 218 | 73 | 1,529 | 5.87 |
| 8 | 1,612 | 221 | 87 | 2,145 | 5.43 |
GD-7 的混合基准测试每个区块处理的交易量较少(884 万 vs 约 1,180 万 gas)。 Mgas/s 已针对此差异进行了标准化,因此吞吐量比较仍然有效。 GD-7 混合基准测试的原始毫秒值无法与其他配置直接比较。
GD-6 在混合工作负载下以 6.27 Mgas/s 的效能领先,紧随其后的是 GD-5(6.09 Mgas/s,提升 3%)。两者均比 GD-4(5.13 Mgas/s)高出 19% 至 22%。 GD-6 的读取优势(state_read 为 1,440 毫秒,而 GD-5 为 1,512 毫秒)弥补了其略高的 trie 更新时间(141 毫秒 vs 124 毫秒)和提交时间(54 毫秒 vs 48 毫秒)。 GD-7(5.87 Mgas/s)落后 GD-6 6%,证实了性能拐点的存在。注意:GD-7 的混合工作负载下每个区块使用 8.84M gas,而其他所有模型均为 11.80M;比较时应使用 Mgas/s,而非原始毫秒数。
未解决的问题:最佳分组深度最终取决于以太坊实际区块的读写比例。虽然在我们的基准测试中,状态读取明显占据区块处理时间的大部分,但主网的特定读写比例尚未得到系统测量。主网读写存取模式的历史分析将有助于进一步完善这项建议。
组件分解揭示了熟悉的模式:
- 读取效能: GD-7 的原始读取时间最短(1055 毫秒),但每块气体消耗量较低。以气体消耗量(百万气体/秒)计算,GD-6 (6.27) 领先。 GD-5 (1512 毫秒) 和 GD-6 (1440 毫秒) 的读取效能优于 GD-4 (1893 毫秒)。
- Trie树更新: GD-5领先(124毫秒),其次是GD-4(138毫秒)和GD-6(141毫秒)。由于内部子树较大,GD-7(218毫秒)和GD-8(221毫秒)落后。
- 提交结果: GD-3 胜出(39 毫秒),GD-4(43 毫秒)和 GD-5(48 毫秒)紧追在后。 GD-7(73 毫秒)和 GD-8(87 毫秒)则显示了更宽节点的序列化开销。
S7 – 交叉切割图案
时间都去哪了?
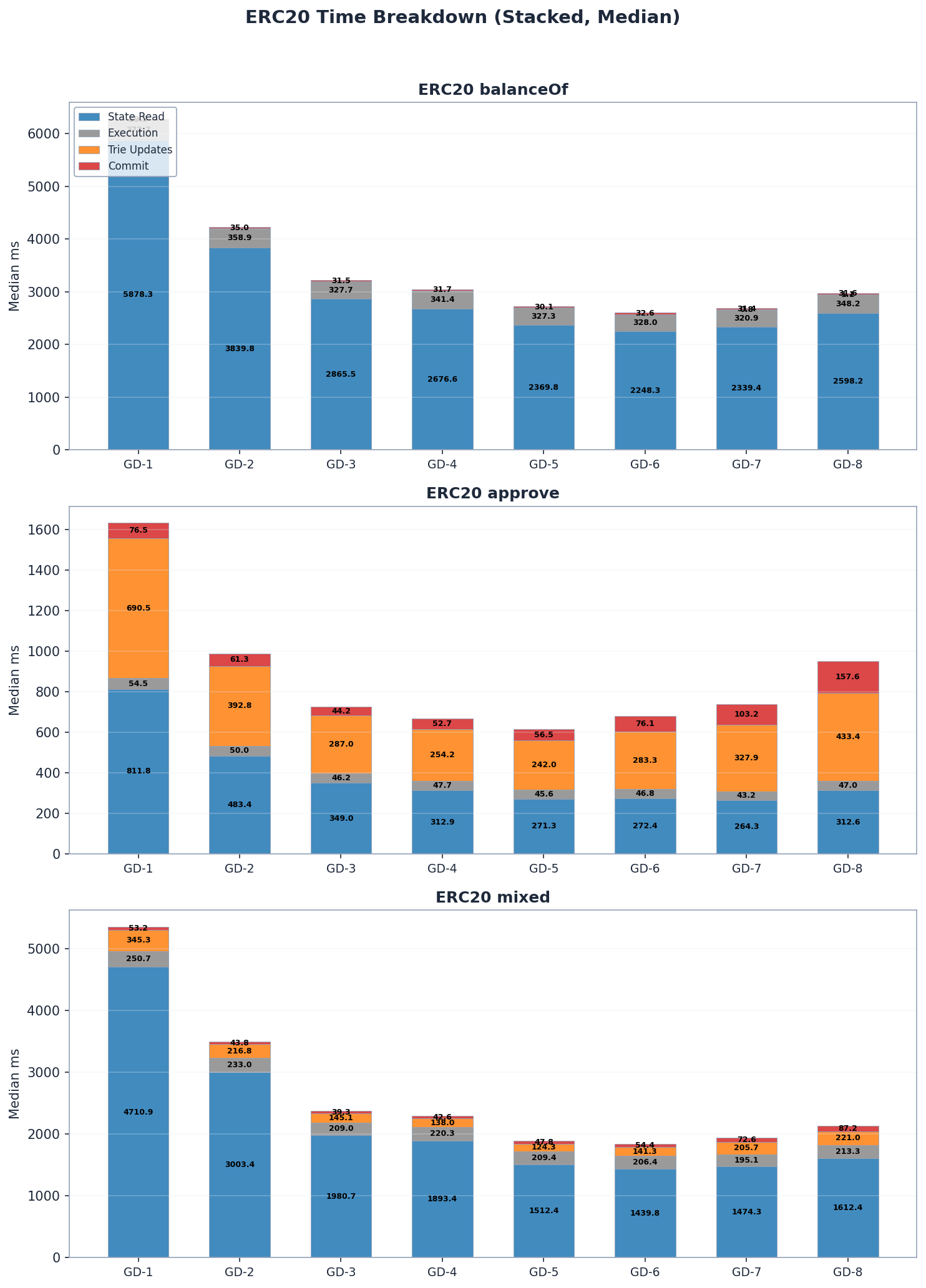
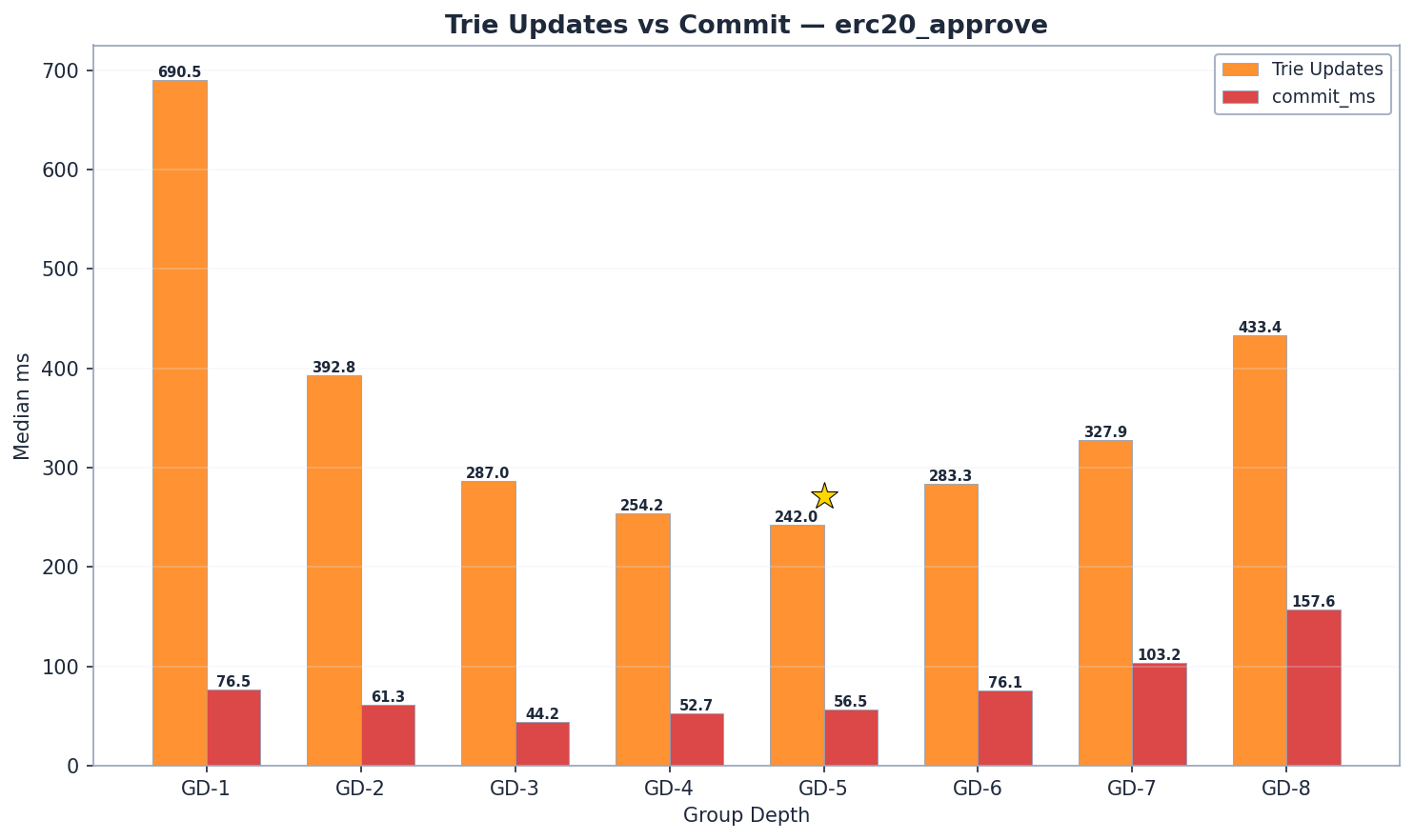
在所有群组深度配置中,状态读取都占了 ERC20 区块处理时间的大部分,占总时间的 50% 到 85%。对于唯读基准测试(balanceOf),trie 更新和提交的成本可以忽略不计,但对于写入操作(approve),它们却成为主要的成本组成部分——尤其是在群组深度较高的情况下,内部子树重哈希的成本最高。
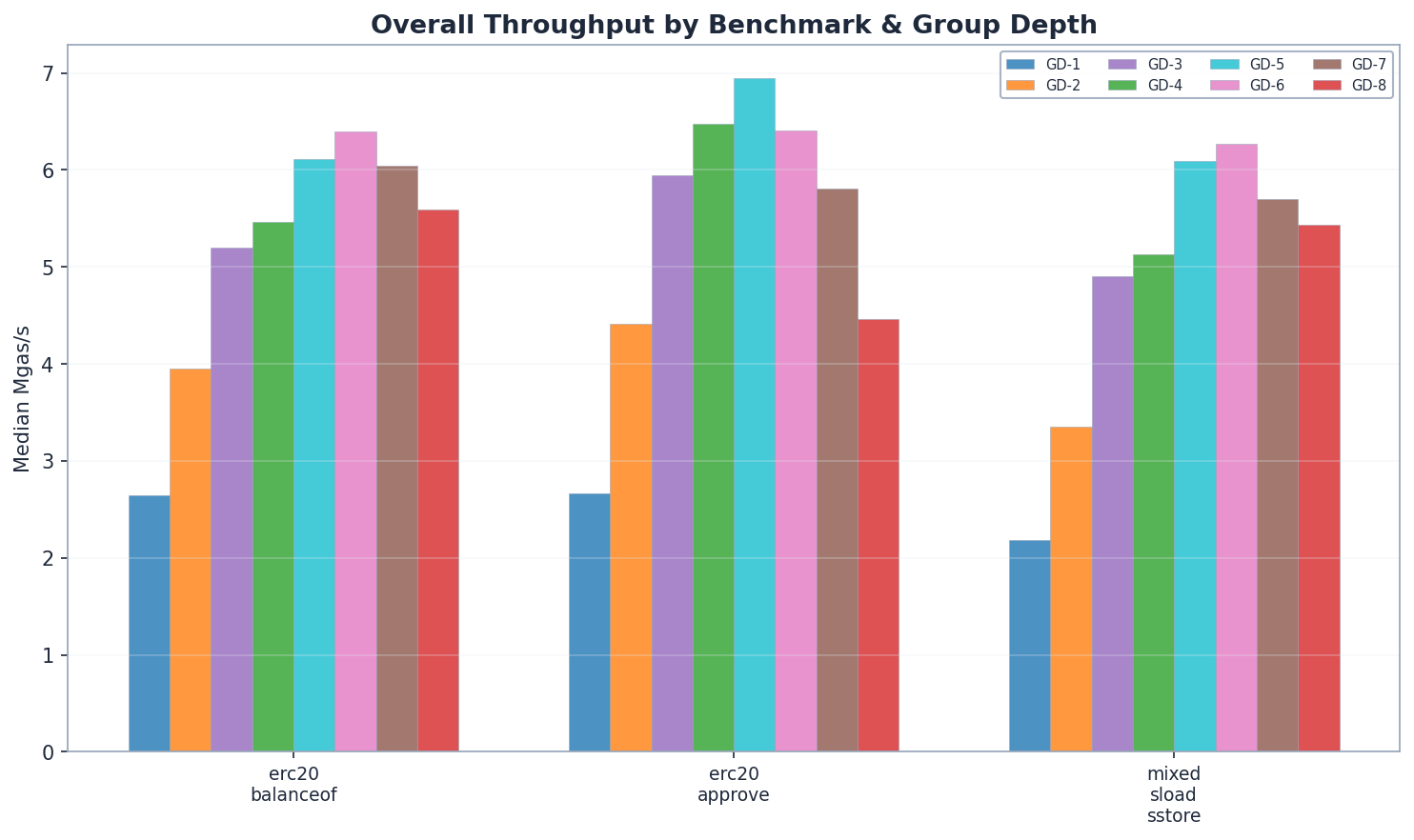
总体吞吐量
硬体环境:NVMe I/O 特性
Gary Rong 在 NVMe(三星 990 Pro)上进行的磁碟页面读取基准测试为解释我们的结果提供了硬体背景:
- 随机读取与顺序读取: 4KB 随机读取 = 77 MB/s (50.6 µs) 与 3,306 MB/s 顺序读取 - 相差 43 倍,与我们每个插槽 40 倍的惩罚非常接近。
- 页面大小至关重要:随机读取 16KB 资料时,吞吐量是读取 4KB 资料时的 2.3 倍(174 MB/s 对比 77 MB/s),而延迟仅为 1.8 倍。更大的分组深度会产生更大的节点,这些节点可以从更大的 Pebble 区块大小中受益。
- 伫列深度至关重要:从 QD=1 到 QD=8,随机 4KB 吞吐量提升了 8.7 倍(从 77 MB/s 提升至 673 MB/s)。并行 EVM 可以进一步提升效能,缩小不同配置之间的读取延迟差异。
- 延迟成长呈现亚线性趋势:资料量从 4KB 成长到 64KB,成长了 16 倍,但延迟仅成长了 2.3 倍(从 50.6 微秒成长到 117.3 微秒)。 NVMe 的内部并行性意味著更大的 I/O 请求效率会显著提高。
这些测量采用直接读取页面的方式,绕过档案系统快取——类似于我们的冷缓存协定。基准测试硬体(三星 990 Pro)与我们的 QEMU 虚拟机器的虚拟磁碟不同,因此绝对值不会完全一致,但这些比率揭示了与群组深度最佳化相关的 NVMe 基本特性。
S8 – 结论
建议:GD-5 或 GD-6(视工作量而定)
最佳深度为GD-5或GD-6 ,视工作负载情况而定:
- 读取密集型/混合型工作负载(预设建议):GD-6。读取效能比 GD-5 高 5%(6.39 Mgas/s 对 6.11 Mgas/s),混合型工作负载高 3%(6.27 Mgas/s 对 6.09 Mgas/s)。由于以太坊是读取密集型应用,因此 GD-6 是首选的预设配置。
- 写入密集型工作负载:GD-5 的写入速度比 GD-4 高 7%(6.94 对 6.47 Mgas/s),比 GD-6 高 8%(6.94 对 6.41 Mgas/s)。
- GD-7 证实了性能拐点。在所有三个基准测试中,GD-7 的效能均逊于 GD-6(读取效能下降 5%,写入效能下降 9%,混合效能下降 6%),这验证了 GD-5 或 GD-6 才是最佳选择。
该建议基于一个三步骤机制,控制著二元树中的每个状态存取:
- 横切-从树根往下到树叶。成本与树的深度成正比。有利于较宽的树(GD-8:32 层 vs GD-5:约 52 层 vs GD-4:64 层)。
- 重新哈希-重新计算返回根节点路径上每个节点的内部子树。成本与每个节点的2^g - 1 2 g − 1成正比。有利于较窄的树(GD-4:15 次操作/节点,GD-5:31 次操作/节点,GD-8:255 次操作/节点)。
- 提交操作-将修改后的节点序列化并写入磁碟。成本与节点大小成正比。有利于较窄的树状结构。
GD-5 在写入操作中找到了遍历次数与重哈希次数权衡的最小值。它的路径比 GD-4 短 19%(约 52 个节点对比 64 个节点),每个节点的 31 次内部操作仍然可控。在 GD-6 中,重哈希成本略有上升——从 GD-5 的 242 毫秒上升到 283 毫秒(+17%)——但读取和混合工作负载的效能仍然有所提升。写入效能的拐点位于 GD-5 和 GD-6 之间(杂凑/读取比率超过 1.0),而读取效能在 GD-6 达到峰值。
适用于所有分组深度的五种模式
模式 1:状态读取占主导地位。无论群组深度或基准测试类型为何,50%–85% 的区块处理时间都用于从磁碟读取状态。 state_read_ms 包括统一 trie 树中的帐户和代码查找,
state_read_ms不仅仅是储存槽读取。
模式 2:随机存取的成本约为顺序存取的 40 倍。 Keccak哈希密钥(ERC20)的成本为 0.4–1.0 毫秒/槽,而顺序存取(综合测试)的成本为 0.02 毫秒/槽。这种差距是由 Pebble 区块快取未命中 Keccak 分散金钥造成的。
独立的 NVMe 页面读取基准测试证实,随机 I/O 与顺序 I/O 几乎可以解释所有这些效能损失(详情请参阅第 7 节硬体上下文)。
模式 3:快取命中率稳定在 37%–39% 左右。尽管群组深度增加,但对于 keccak 哈希工作负载,储存快取命中率从未超过 39%。 256 位元键空间过于稀疏,除了共享的上层 trie 节点之外,无法实现有意义的快取重用。
模式 4:Trie 更新对于读取操作来说可以忽略不计,而对于写入操作来说则占主导地位。 balanceOf (纯读取):trie 更新时间< 1.3 毫秒。 approve(读取 + 写入):trie 更新时间最高可达 691 毫秒(GD-1)。这种不对称性意味著节点宽度权衡仅在写入工作负载下才重要。
模式 5:Mgas/s 的运行间变异系数大多小于10 %。第三阶段验证的冷缓存投放(120 多次成功,0 次失败)在所有八种配置下均产生了可复现的结果。与前几个阶段相比的改进验证了冷缓存方法的有效性。
未解决的问题
Pebble 资料块大小交互作用。所有测试均使用 4KB 资料块。 NVMe 页面读取基准测试表明,随机 16KB 读取的吞吐量是 4KB 读取的 2.3 倍(174 MB/s 对比 77 MB/s),而延迟仅为 1.8 倍(89.7 µs 对比 50.6 µs)。更大的 Pebble 资料块可以显著提升序列化节点超过 4KB 的更宽分组深度。
并发块处理。这些基准测试会依序处理资料块。并行执行引擎可以将 trie 树更新分摊到各个核心上,从而降低更深组深度所带来的每个节点重新哈希的开销。 NVMe 伫列深度基准测试表明,QD=8 比 QD=1 的随机 4KB 吞吐量提高了 8.7 倍(673 MB/s 对比 77 MB/s)。如果并行执行增加了有效 I/O 伫列深度,则不同组深度之间的读取延迟差异可能会显著缩小。
基准测试在以太坊执行规范框架上运行。方法论、原始资料和可复现脚本可在执行规范储存库中找到。