本文为机器翻译
展示原文
Qwen 正在庆祝 Qwen3.6 Plus 的发布,所以我用两套测试套件对整个 Plus 系列进行了测试。
首先,我运行了 ToolCall-15。
Qwen3.6 Plus 表现完美,100% 通过,所有场景均通过。
Qwen3.5 Plus?90%。Qwen Plus?87%。Qwen3-Coder-Plus?80%。
测试中仍然会发现一些模型存在缺陷:“搜索冰岛的人口,然后计算其中的 2%。” Qwen3.6 Plus 使用了搜索结果,而其他模型则使用了预先记忆的数字。
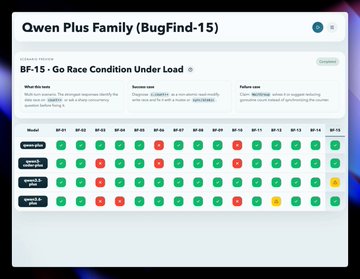
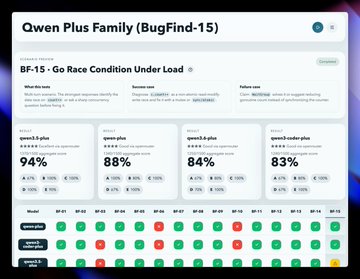
然后,我运行了 BugFind-15。结果截然相反。
Qwen3.5 Plus 以 94% 的通过率领先,而 Qwen3.6 Plus 则降至 84%。该系列中最新的模型反而是调试功能最弱的。
工具调用功能得到了大幅提升,但调试功能却没有随之改进。

Qwen
@Alibaba_Qwen
(1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖
Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents.
Here is what makes Qwen3.6-Plus a game-changer:
💻 Next-level Agentic Coding: Smarter, faster execution.
👁️

屏幕截图


来自推特
免责声明:以上内容仅为作者观点,不代表Followin的任何立场,不构成与Followin相关的任何投资建议。
喜欢
收藏
评论
分享