

看来大家最近都很喜欢人工智慧相关的内容,所以我们会继续更新。话虽如此,最近市场行情一路走高,所以我们得尽快再关注一下加密货币,看看哪些值得关注。
但今天,我们先来了解LLM的基本原理。我注意到,大多数每天使用ChatGPT或Claude的人根本不知道它们是如何运作的。
当然,这无可厚非。你不需要了解引擎的工作原理才能开车。但我认为,对引擎内部运作机制有基本的了解能让你成为更好的使用者。它能帮助你理解为什么人工智慧在某些方面表现出色,而在其他方面则表现不佳;它能帮助你提出更好的问题;它还能让你更不容易对输出结果过度信任或信任不足。
这篇文章写得有点长了,下面我们将讨论以下内容:
什么是法学硕士(LLM)?
法学硕士是如何「学习」的?
等等,所以这是自动补全功能?
什么是令牌?
参数方面呢?
LLM 究竟是如何产生反应的?
这些模型究竟「知道」什么?
训练和微调有什么不同?
为什么有些模型比其他模型更好?
模型尺寸:为什么有些可以在笔记型电脑上运行,而有些则需要资料中心?
了解这些对你有什么帮助?
如果您有兴趣进一步提升您的 AI 学习之旅,那么请查看我与几位朋友共同创办的新公司: AI 的 Stoa 。
我们制作视讯课程,并每周举办直播研讨会和电话会议,向您展示将人工智慧融入日常工作流程的实用方法。
我们目前处于早期体验阶段,提供折扣价格,请点击这里了解详情: https://www.skool.com/thestoaofai
什么是法学硕士(LLM)?
LLM 代表大型语言模型。 ChatGPT、Claude、 Gemini以及所有其他 AI 聊天机器人都是基于这个模型构建的。
语言。这些模型与语言打交道。输入文本,输出文字。你输入单词,它们产生单字回传。 (是的,它们现在也能处理图像、音讯和程式码,但其本质是语言机器,「语言」一词可以用来指称这些语言学习模型产生的任何输入/输出。)
模型。在人工智慧领域,模型是指经过资料训练以识别模式的程式。如果你给一个从未见过猫的人看一百万张不同品种猫的照片,最终他就能很好地区分它们。 LLM 的概念也是如此。
规模庞大。这些模型规模非常庞大。它们基于海量资料进行训练。我们说的是整个互联网的很大一部分。书籍、文章、维基百科、论坛、程式码库、学术论文。数十亿,甚至数万亿个单字。
将它们组合在一起,你就得到了:一个已经阅读了大量人类文本并从中学习语言模式的程式。

法学硕士是如何「学习」的?
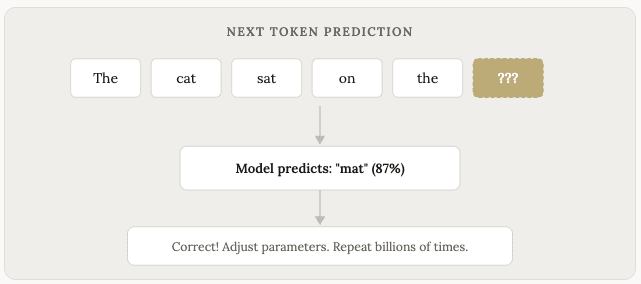
「训练」过程的核心学习原理其实非常简单。你取一个句子,隐藏最后一个词,然后让模型预测接下来是什么。
模型进行猜测。如果猜错了,你就稍微调整一下模型,让它下次猜得更好。然后,你重复这个过程数十亿次,处理数十亿个句子。
随著时间的推移,模型能够越来越准确地预测下一个词。然后是下一个字。再下一个字。直到它能够产生听起来像是人写的整段整页的内容。
这是该过程的简化版本(专业术语是“下一个词元预测”),但它抓住了核心思想。 LLM 的本质是预测机器。它们根据之前接收到的所有资讯来预测接下来应该出现什么文字。
等等,所以这是自动补全功能?
手机的自动补全功能会根据简单的模式预测下一个单字。语言学习模型(LLM)也能做到这一点,但它拥有大量的数据、更强大的运算能力,以及对情境更深刻的理解。
它是否真正理解问题,是目前人工智慧领域争论的焦点之一。我认为我们无需在此一一解答。从实际应用的角度来看,重要的是输出结果有用,而且往往非常出色。

什么是令牌?
代币是LLM(生命周期模型)的计量单位,也算是LLM的货币。使用Anthropic或OpenAI的前沿模型时,通常需要按使用的代币数量付费。
大多数人没有意识到一点:模型其实根本看不到你的文字,它看到的只是数字。
这些数字是模型运作的基础。模型内部的每一次计算,包括模式匹配和预测,都是基于数字进行的数学运算。模型透过神经网路处理这些数字,并输出…更多的数字。这些输出的数字随后会被解码,最终呈现在你萤幕上的文字。
将文字转换为数字的过程称为编码。将输出的数字转换回文字的过程称为解码。您永远不会看到这些数字,模型也永远不会看到这些文字。在您和模型之间有一个转换层(称为分词器),负责来回进行编码和解码。
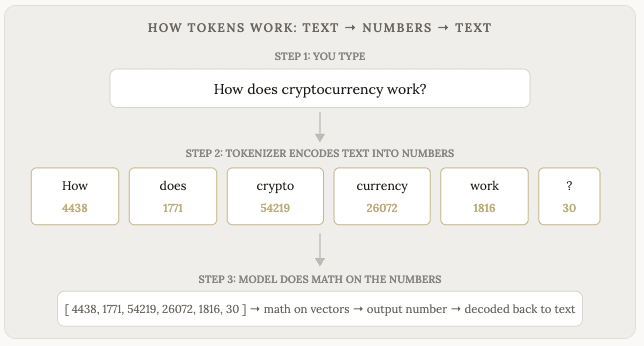
一个词元大约是单字的四分之三,或大约四个字元。像“the”或“and”这样的常见短词算一个词元。较长或不常用的单字会被拆分成多个词元。
这对你很重要,因为LLM(逻辑学习模型)一次能处理的词元数量是有限的。这被称为上下文视窗。你可以把它想像成模型的工作记忆。
但要记住的是,更大的上下文视窗并不一定更好,也并非本质上就更好。
就像所有人工智慧相关的领域一样,这些模型在这方面也不断进步。 Claude 在长上下文基准测试中名列前茅,而且每一代模型在短上下文和长上下文效能之间的差距都在缩小。

参数方面呢?
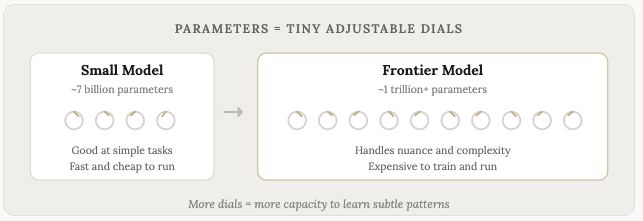
这是另一个你经常听到的庞大数字。许多模型都标榜拥有数十亿甚至数千亿个参数;有些模型甚至拥有数万亿个参数。但参数究竟是什么呢?
参数是模型的内部设定。可以把它们想像成一个个小旋钮,在训练过程中,每次模型做出预测并获得预测结果正确与否的回馈时,这些旋钮都会微调。
更具体地说,参数是决定上一节提到的向量在通过模型时如何转换的数值。它们控制著诸如以下方面:这个词应该对那个词给予多少关注?这个概念应该如何与那个概念关联?哪些模式是重要的,哪些模式是噪音?
通常来说,参数越多,模型就越智能,但这并非唯一因素。训练资料的品质、架构选择和微调也同样重要,我们稍后会详细讨论。但在其他条件相同的情况下,参数越多,模型学习复杂问题的能力就越强。
对于这类事情,你其实不需要记住确切的数字,也不需要了解事情的精确运作原理。
LLM 究竟是如何产生反应的?
当你向 Claude 或 ChatGPT 输入讯息时,大致会发生以下情况:
这就是为什么你会看到人工智慧回应时,文字是逐字逐句显示的。它是即时产生回应的,一次产生一个部分。它不会先写出完整的答案再显示出来,而是边生成边思考。
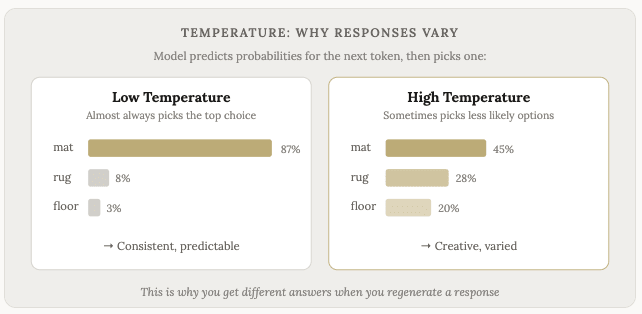
这也是为什么同样的提示有时会给出不同的答案。选择过程中内建了一定程度的随机性(称为“温度”)。模型并非总是选择最有可能的下一个词元。有时它会选择第二或第三可能的选项,这使得反应的方向略有不同。
大多数模型都允许您调整此设置,并要求模型使用更多非常规的响应。如果您正在进行创意写作或其他需要跳脱固有思维模式的工作,这将非常有用。而对于任何需要事实和精确性的任务,低温模型往往表现较佳。
这些模型究竟「知道」什么?
逻辑学习模型(LLM)没有一个用来找出事实的资料库。当你向它们提问时,它们不会翻阅文件柜。相反,知识就蕴含在它们的参数模式中。模型学习到某些事实倾向于出现在特定的情境中,并在情境需要时重现这些事实。
这就是为什么语言学习模式有时会编造内容。人工智慧界称之为「幻觉」。模型并没有说谎。它只是产生了一些看似最有可能的对话延续内容,而有时最有可能的内容并非事实。它是在进行预测,而不是回忆。
这是理解语言学习模型(LLM)最重要的一点。它们的目标是产生听起来自然流畅的文本,而不是内容正确的文本。这两者很多时候会重叠,但并非总是如此。
经验法则:事实越晦涩或越具体,模型出错或编造结果的可能性就越大。如果询问的是训练资料中频繁出现的、有据可查的主题,那么模型相当可靠。如果询问的是小众主题、近期事件或具体数字,则需要验证输出结果。

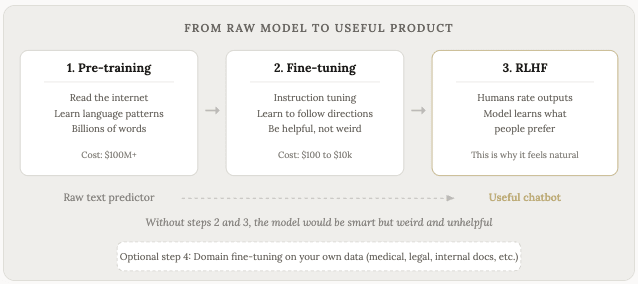
训练和微调有什么不同?
训练是模型读取所有文字并学习模式的初始过程。这既耗时又昂贵。仅计算成本,训练一个前沿模型就需要数亿美元(这个阶段有时被称为预训练,因为它发生在任何进一步改进之前)。
微调是将基础模型转化为实用工具的关键。它是第二轮训练,使用规模更小、经过更精心挑选的资料集进行。在这一阶段,模型学习如何遵循指示、回答问题、进行对话,以及表现得像个合格的聊天机器人。
预训练和微调之间的成本差异巨大。从头开始预训练 GPT-5 或 Claude 模型需要花费数亿美元。而使用自己的资料微调开源模型,成本则从几美元到几千美元不等,取决于模型的大小和使用的资料量。
为什么有些模型比其他模型更好?
我们之前已经稍微提到过这一点,但为了更详细地强调和扩展几个因素,这里再补充一些内容:
训练资料品质。数据量并非越多越好。更干净、更高品质的数据才能带来更好的模型。如果用大量垃圾资料进行训练,模型也会产生垃圾结果。
规模。通常情况下,更多的参数和更多的训练计算量会带来更好的效能,但这种提升是有极限的。随著规模的扩大,收益会递减,有时用更好资料训练的小型模型会胜过用较差资料训练的大型模型。

模型尺寸:为什么有些模型可以在笔记型电脑上运行,而有些则需要资料中心
正如我们之前提到的,并非所有模型的大小都相同。参数数量差异巨大,这直接决定了运行它们所需的硬体配置。
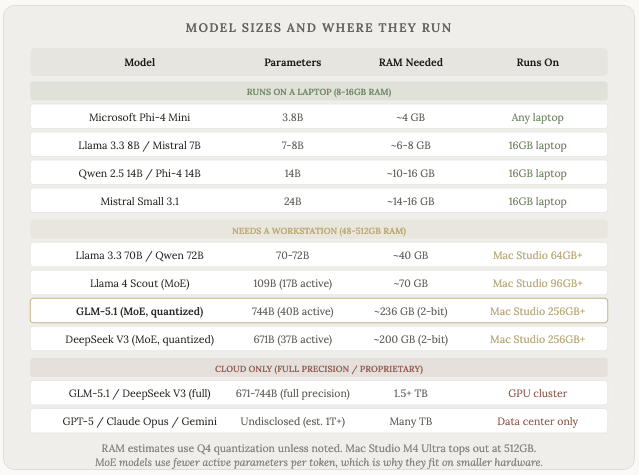
最小模型和最大模型之间的品质差距确实存在,但这种差距也在缩小。如今,即使与最前沿的模型相比,在你的笔记型电脑上运行一个精心挑选的 140 亿参数模型也能很好地完成日常和简单的任务(尽管速度可能较慢)。
这种差距在复杂的多步骤推理、长篇创意写作以及需要大量世界知识的任务中最为明显。但对于撰写电子邮件、总结文件或回答问题等日常任务,本地模型的表现却出奇地好。
了解这些对你有什么帮助?
我的意思是,希望你也能像我一样,觉得这些东西超有趣!知识是有价值的,了解事物运作原理也很有价值,即使你使用它们时并不一定需要知道这些原则。
这些工具的部分价值来自于您在使用这些工具时可能做出的一些改变。
当你了解模型是基于模式预测下一个词元时,你就能明白为什么提供更多上下文资讯能带来更好的输出。你就能明白为什么提示语要具体明确。你就能明白为什么它有时会自信地给予错误的讯息。
当你了解上下文视窗时,你就会明白为什么长时间的对话有时会偏离主题。
当你了解温度和随机性之后,就能明白为什么重新产生反应有时会得到更好(或更差)的结果。这是机率空间中的一条不同路径。而且,知道可以根据任务调整温度设置,就能让你以更符合自身需求的方式运用这些工具。
了解这些内容应该能让你成为更好的用户,并让你对未来的提示操作更有信心。
免责声明:本简讯内容不构成投资建议。本人并非财务顾问,以上仅代表个人观点与想法。在交易或投资任何加密货币相关产品之前,您务必咨询专业/持牌财务顾问。文中部分连结可能为推荐连结。




