

我的初步研究表明,除了合同去重和存储时压缩代码之外,合同代码的存储空间还可以再减少 30%。
Solidity 编译器和其他所有编译器都必然会生成包含操作码模式的字节码。在压缩单个合约时,理想的压缩算法会在这些模式在合约中出现一次后学习它们,然后在合约的其余部分以简化的方式引用它们。
然而,这意味着压缩算法总是会对单个合约中首次出现的某种模式感到惊讶,因为该算法不知道这种模式在许多智能合约中都很常见,因此只能从它正在处理的单个合约中学习。
大多数压缩算法库都内置了解决方案——你可以提供一个预训练的小型“字典”,其中编码了历史数据中已出现的常见模式。这样,当这些常见模式首次出现在新数据中时,就可以立即对其进行压缩。
其次,使用预训练字典还能记住大量垃圾邮件/垃圾邮件合同中的常见模式。对于那些已被发送数万次且仅有细微差别的垃圾邮件合同,字典可以将这些合同的数量减少到原来的个位数百分比。
以下是结果:
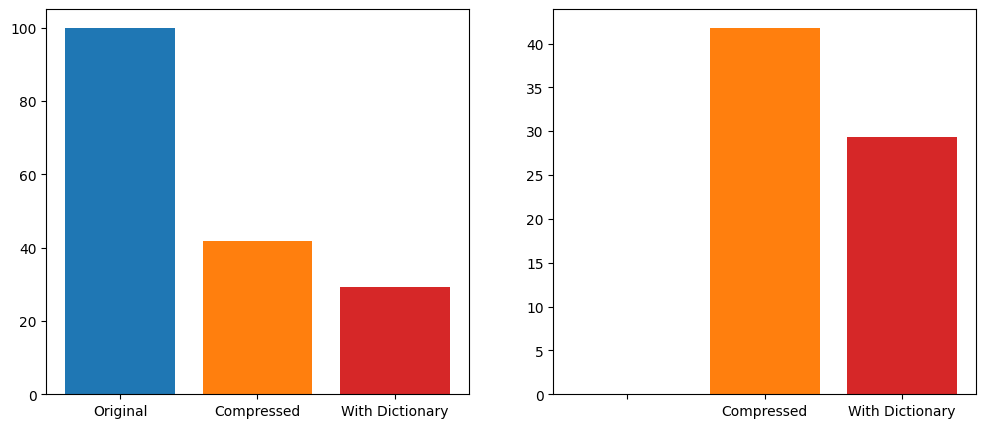
图片尺寸:986×428,11 KB
使用 zelliac 数据集,该数据集包含了截至 2025 年初部署的所有合约字节码,共有1,539,858去重后的已部署字节码集。
使用 Zstandard 压缩库,并采用其默认的快速压缩级别 3,对每个单独的字节码集进行压缩,总大小从原始大小的100%减少到41.8% 。添加一个 100KB 的字典,并在默认压缩级别下进行训练,最终字节码大小为原始大小的29.3% ,比压缩后的大小减少了30% 。
增加压缩字典的大小或提高压缩级别可以进一步减小最终文件的大小。我为了追求速度而进行了优化。此外,进一步调整字典训练参数也很有可能获得更小的文件大小。
不同大小的合约字节码所需的总存储空间:
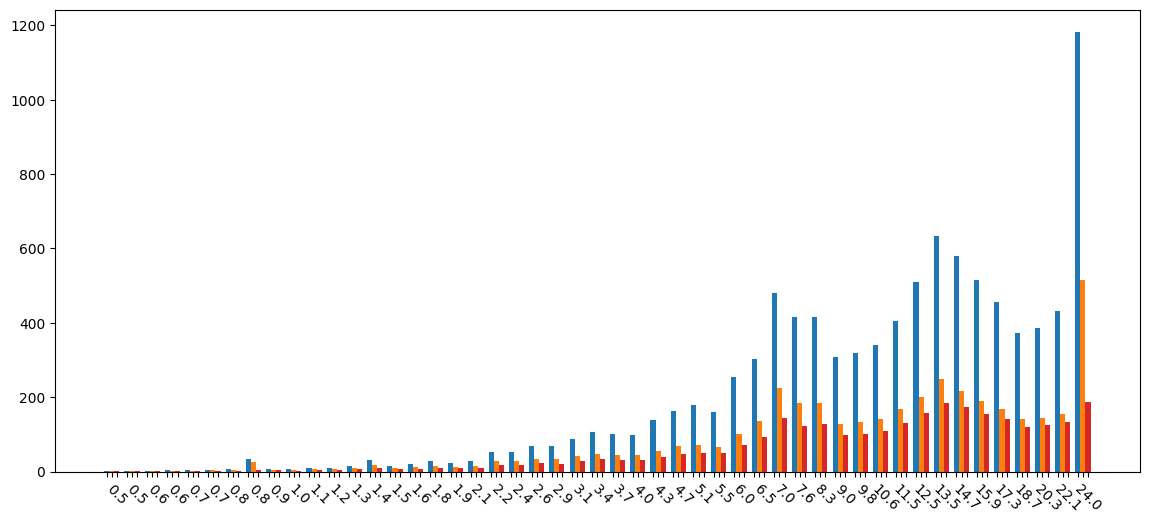
图片尺寸:1149×523,大小:17.7 KB
所有合同中的表现从最差到最佳。
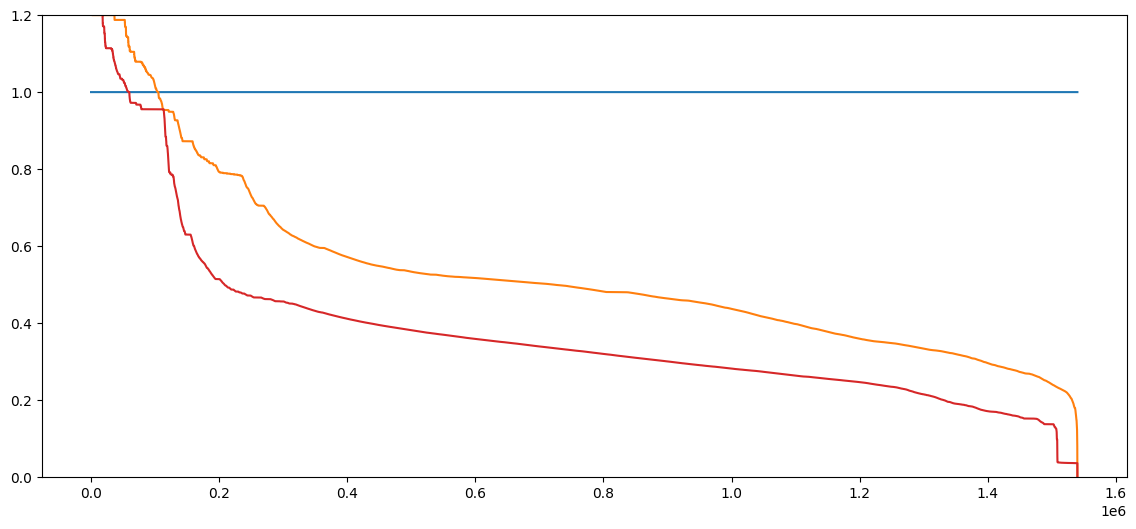
图片尺寸:1136×529,大小:26.4 KB
最后几点说明:
- 如果在客户端使用此功能,我建议存储一个字节来指示合约是否被压缩,如果被压缩,则指示使用了哪个字典/ALGO。这样可以方便将来平滑升级到更好的字典,同时也能避免压缩那些压缩后质量反而更差的文件。
- 我之所以选择 zstandard 作为压缩库,仅仅是因为我过去使用它的体验很好。目前我还没有比较过不同的压缩库或算法。





