

我认为这是我近期写过的最实用的文章之一。虽然它并非严格意义上的加密货币文章,但与我最近发表的关于人工智能代理和克劳德代码的文章非常契合,而这些文章也确实很受欢迎。
每当我在本期简报中谈到人工智能时,通常指的是像 Claude、ChatGPT、 GeminiETC大型云端人工智能工具。这些模型的工作原理是:你输入一个提示,它会被发送到某个服务器进行处理,然后返回结果。就这么简单。无论你是使用网页界面,还是使用 Claude Max 订阅在 Claude Code 中进行深度编码,原理都是一样的。
但还有完全运行在你自己电脑上的开源人工智能世界。这些是本地LLM(逻辑逻辑模型),到2026年,它们已经非常出色了。
不出所料,这个领域发展迅猛。仅在过去两周, GLM-5.1 就成为首个在主流编码基准测试中超越 Claude Opus 4.6 的开源模型。今天早些时候,Kimi K2.6 发布,从GLM手中夺得桂冠。工具和模型不断改进,云端和本地之间的差距也在不断缩小。
过去一周,我一直在学习和尝试使用Mac版Studio上的本地模型,它们的强大功能让我惊喜不已。当然,对于极其复杂的操作,它们肯定比不上Claude Opus 4.7和其他一些前沿模型,但对于我日常的大部分工作来说,本地模型确实非常实用。而且,它们免费、私密,并且随时可用。
即使你保留了云订阅(我就是这么做的),拥有一个本地模型作为备份或用于特定任务也是你能做的最佳举措之一。
这本身就非常引人入胜,而且在这个时代,学习如何拥有和运行自己的模型是一项非常实用的技能。
今天这篇文章我们将介绍以下内容:
为什么要运行本地模型?
硬件:你需要哪些硬件?
软件工具
哪种模型适用于哪种任务?
入门
将本地模型与人工智能代理连接起来
结语
如果您有兴趣进一步提升您的 AI 学习之旅,那么请查看我与几位朋友共同创办的新公司: AI 的 Stoa 。
我们制作视频课程,并每周举办直播研讨会和电话会议,向您展示将人工智能融入日常工作流程的实用方法。
我们目前处于早期体验阶段,提供折扣价格,点击这里了解详情: https://www.skool.com/thestoaofai
为什么要运行本地模型?
五个主要原因。
隐私保护。您的提示、文件和对话都保留在您的本地计算机上,不会上传到任何第三方服务器。对于任何处理敏感数据、专有代码或机密文档的人来说,这至关重要。更不用说那些仅仅关心个人隐私,不希望大型人工智能监视自己(或者更糟,不希望数据泄露给不法分子)的人了。
成本方面,一旦拥有了硬件,推理就是免费的。如果大量使用人工智能,本地模型通常会在足够长的时间内收回成本。你还可以重新利用家中的旧设备来运行本地模型。
没有速率限制。Frontier模型会迅速消耗积分。拥有本地备用方案简直是天赐之物,让模型运行永远不会达到速率限制的任务(并且不计入您现有的速率限制)也同样重要。大多数人采用“一刀切”的 AI 方法,对于一些完全过剩的简单任务,使用像 Opus 和 Sonnet 这样的模型,而更简单的本地模型就能胜任。
离线访问。这功能很棒。一旦将模型下载到本地,即使没有网络也能使用。您可以在飞行途中、偏远地区与模型互动,或者只是拥有一个备用方案,在自己的电脑上访问人类的全部知识。
完全掌控。您可以选择模型,并随心所欲地调整其配置。您无需担心服务条款的变更,也不会因为违反条款(或因对方错误)而被无故封禁。运行本地模型时,您可以完全掌控整个 AI 堆栈。
几周前,Anthropic 阻止 OpenClaw 和其他第三方代理框架使用 Claude Pro/Max 订阅,这件事让我感触颇深。 依赖这种设置的人突然被迫切换到另一个提供商,或者支付每天可能高达 50 美元的 API 费用。
本地模型不存在这个问题。

正如我开头所说,本地模型在处理最复杂的多步骤推理时无法与前沿模型相媲美。但对于简单的日常编码、摘要生成、草稿撰写、网页抓取、研究和问答等任务,它们可以处理我交给它们的 70-80% 的任务。
硬件:你需要哪些硬件?
在深入探讨硬件本身之前,我们先快速了解一下量化。你会在本地LLM世界中到处看到这个术语,它会影响你做出的每一个硬件决策,因此值得提前理解。
对于大多数任务而言,4 位量化产生的输出与全精度输出几乎没有区别。如果您遇到类似 Q4_K_M 或 Q3_K_M 这样的模型名称,请注意,它们指的是同一模型,只是量化位数分别为 4 位和 3 位。
经验法则:Q4 量化模型每十亿个参数大约需要 0.6-0.7 GB 内存(我在上周的帖子中解释了参数) 。
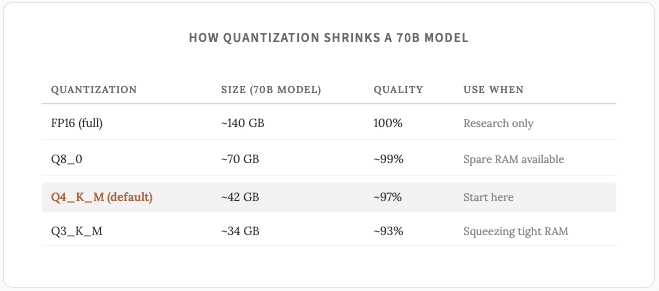
我建议您坚持使用Q4_K_M型号,除非您有特殊原因不这样做。
好了,我们还是回到硬件话题上来。在硬件上运行LLM时,最重要的参数就是可用内存。这在PC上指的是显存(VRAM),在Mac上指的是统一内存(UM)。其他所有硬件相关的参数都是次要的。
这里有一个方便的图表,可以根据不同的硬件规格查看您可以运行的模型类型:
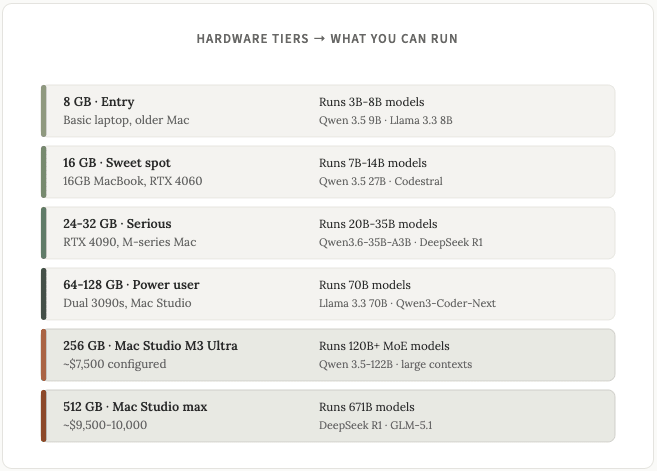
我个人在自己的 Mac Studio(Q3 版本,需要约 308GB 内存)上运行 GLM5.1,参数数量为 7440 亿。
Mac 和 PC:你应该买哪一款?
这是一个常见问题,答案和大多数事情一样,“视情况而定”。两者没有绝对的优劣之分,它们各有优势,具体取决于您的情况/需求。
如果你预算有限,而且已经有了电脑:那就买一块二手的 RTX 3090 显卡吧。2026 年性价比最高的显卡,每 GB 显存。
如果您想要一台价格低于 1500 美元的完整机器,并且主要运行 7B-14B 型号的 Mac Mini:配备 24GB 内存的 Mac Mini M4 Pro(1399 美元)。安静、高效,无需组装。
如果您想要中小型机型拥有最快的响应速度:组装一台配备 RTX 4090 或 5090 显卡的电脑。总价大约在 2500-3500 美元之间。
这些设备不会很花哨,但对于简单/基本的任务来说仍然非常实用,更重要的是,你至少可以在花额外的钱之前了解一下本地型号是如何运作的。
软件工具
硬件是第一步,但有了硬件之后,您还需要一些工具来管理和运行您自己的设备上的模型。以下是主要选项。

它具有实时内存监控功能,可在您下载之前告知您的机器是否可以运行某个模型,并根据您的硬件推荐最适合您下载的模型。
它还公开了一个与 OpenAI 兼容的 API,因此您可以根据需要将其连接到脚本和代理(即,您可以在本地模型上运行 Openclaw 或 Hermes 代理)。
如果你想使用本地模型构建项目, Ollama总体来说是更好的选择,但它要求你熟悉终端/命令行界面 (CLI)。Ollama 相对于 LM Studio 的一些优势如下:
它是完全开源的(MIT 许可证)。LM Studio 是闭源软件,其免费套餐不包含商业用途。如果您正在开发产品或希望了解计算机上运行的程序,Ollama 是更安全的选择。
内存占用更小。Ollama非常精简。LM Studio 是一个 Electron 应用,即使不加载模型,仅 GUI 层就需要 300MB 到 1GB 的内存。
Ollama 与 LM Studio 具有相同的 API 兼容性。
llama.cpp和MLX是底层引擎。Ollama 和 LM Studio 都使用其中一个进行推理。大多数用户无需考虑它们的具体作用。
哪种模型适用于哪种任务?
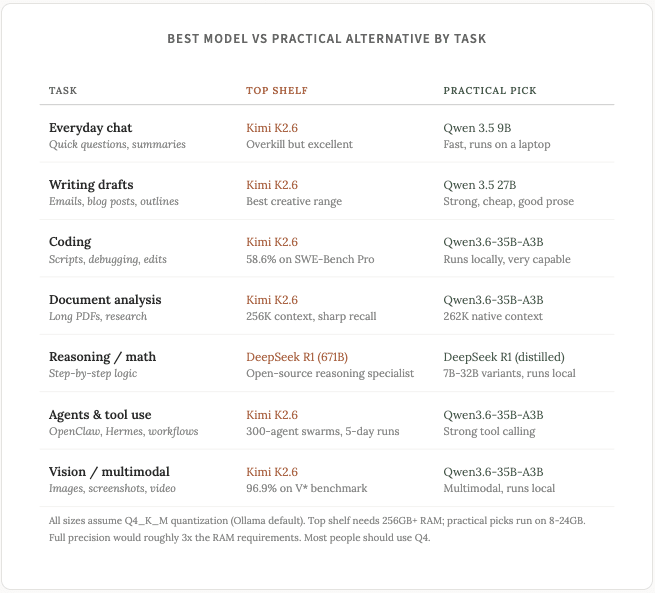
目前,在编程领域的顶尖产品中,有两款开放重量级模型脱颖而出。

对于配置较低的硬件, Qwen 3.5 9B是一个实用的选择,在 8GB 内存的 MacBook 上运行良好。它无法处理复杂的多文件运算,但对于一些日常任务(例如重写电子邮件、文章摘要、快速问答),它的表现非常出色。
入门
如果您想尝试运行自己的本地模型,以下是 LM Studioo 和 Ollama 的一些入门说明。
LM工作室:
从lmstudio.ai下载LM Studio。
安装它。
打开应用。
点击“发现”并搜索型号。实时内存监控器会告诉您该型号是否能在您的计算机上运行。
点击下载。
完成后点击“加载模型”,就可以开始使用了。你可以直接在LM Studio中与模型聊天,或者将其连接到像OpenClaw/Hermes这样的代理(我将在下一节中解释如何操作)。
奥拉玛:
从ollama.com安装 Ollama(适用于 Mac 和 Linux 的一键安装程序)。
然后前往ollama.com/library或huggingface.co浏览模特。
每个模型列表都应该提供运行该模型的确切命令。HuggingFace 提供更多选择,并显示文件大小,方便您在下载前检查内存是否足够。
找到模型后,在终端中运行它,它应该看起来像这样:
ollama run qwen3.5:9b第一次运行此类命令时,它会下载模型;之后,它会从硬盘加载模型。下载/加载完成后,您就可以立即通过终端与模型进行交互。
使用本地模型非常简单,上手也很容易。从头到尾的整个设置过程并不长,通常耗时最长的部分是下载模型本身(根据模型的不同,大小从几GB到几十甚至几百GB不等)。
这就是在您自己的设备上运行本地 LLM 的全部步骤,我建议所有拥有相应硬件的人至少用一些最小的型号尝试一下。
将本地模型与人工智能代理连接起来
事情变得有趣起来了。运行本地聊天机器人固然有用也很酷,但将本地模型连接到代理框架(Openclaw 或 Hermes)才是真正的突破。
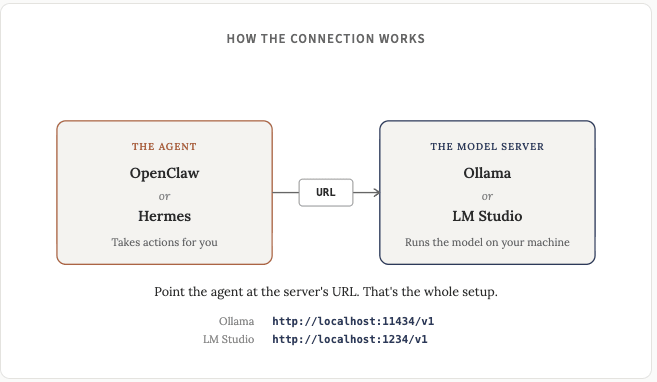
Ollama 和 LM Studio 都提供了兼容 OpenAI 的 API,OpenClaw 和 Hermes 也都支持这种格式,所以最终一切都很简单。一旦你掌握了方法,就会发现尝试新模型非常容易。
结语
本地模型无法取代 Claude Opus 4.7 处理复杂的多步骤推理。它无法像前沿的云模型那样高效地编写内容。它也无法像云模型那样可靠地调试复杂的多文件代码库。
它将为您提供一个私密、免费、随时可用的 AI 助手,它可以处理您交给它的大部分基本任务,而且,显然,它有时还能更好地创建鹈鹕骑自行车的图像?
我建议大家采用的最佳方案是:将最复杂的任务放在云端,其他所有任务(或必须保密的内容)放在本地。不必非此即彼。
到2026年4月,本地LLM生态系统已经成熟。过去几个月,LLM的质量取得了令人瞩目的飞跃,如果这种趋势持续下去,我们这些普通人在家就能掌握的AI能力将会非常惊人。
说实话,这些模型可能已经比你想象的还要好。拥有一个运行在你自己电脑上的人工智能,能够以(几乎)零运行成本和零数据泄露回答你的问题,这又让我想起了科幻小说史上最伟大的作家之一的精彩论述:

免责声明:本简讯内容不构成投资建议。本人并非财务顾问,以上仅代表个人观点和想法。在交易或投资任何加密货币相关产品之前,您务必咨询专业/持牌财务顾问。文中部分链接可能为推荐链接。





