

作者:Shouyi、Denise | Biteye 内容团队

过去一个月,“中转站”三个字频繁出现在了很多人的首页,过去一些币圈撸空投的玩家竟然悄然一变,成了“API 中转站”商,做起了 token 进出口业务。
所谓“中转站”,并不是什么新技术发明,而是一种基于全球 AI 服务价格差与访问壁垒的套利模式。尽管这个赛道面临隐私、安全、合规等多重问题,仍吸引了大量个人和小团队入场。
那么,究竟什么是“API 中转站”?它又是如何在全球 AI 价格差与访问壁垒中实现 Token 套利,并吸引大量个人和小团队入场的呢?
下面我们就从它的本质和运作流程开始拆解。
一、什么是中转站?
API 中转站的本质是搭建一个中间层服务,将国外 AI 厂商的 API Token 以更低价格、更便捷方式提供给国内用户,据称“全球 Token 搬运工”。
其运作流程大致为:
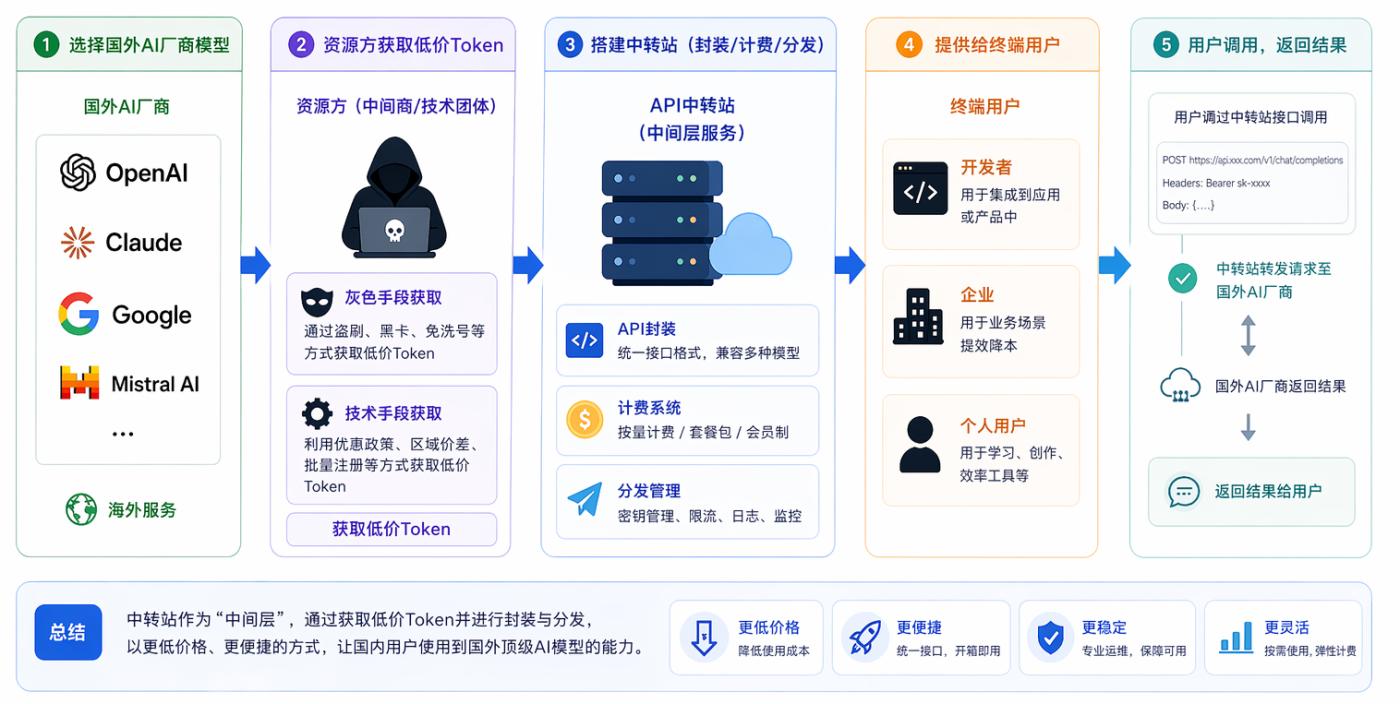
👉选择海外 AI 厂商模型(OpenAI/Claude 等)
👉资源方通过“灰色”手段或技术手段获取低价 Token
👉搭建中转站进行封装、计费、分发
👉提供给终端用户如开发者/企业/个人
从功能上看,它像一个“AI 转运站”;从商业上看,它更像一个 Token 二级市场的流动性中间商。
这条链路成立的前提,不是技术壁垒,而是几个差异长期并存:
• 官方 API 定价偏高
• 订阅制和 API 制存在成本错配
• 不同地区访问和支付条件不同
• 用户对模型能力有强需求,但对官方接入路径不够友好
这些因素叠加起来,才给了“中转站”生存空间。
二、为什么会有人用中转站?
“Token 进口”之所以成为风口,核心驱动力源于 AI 角色转变带来的高昂成本,以及国内外模型的能力差距。
1.好模型用起来很费 Token
随着 Codex、Claude Code 等桌面级 AI 代理的成熟,AI 开始真正具备“干活”能力,例如辅助编程、视频剪辑、金融交易和办公自动化等。这些任务高度依赖高性能大模型,成本按 Token 计费。
以 Claude Code 为例,其每百万 Token 的官方价格约为 5 美元(约 35 元人民币)。深度使用一小时可能消耗几十美元,而重度开发者或企业日均消耗可达 100 美元以上。这种成本远超许多人的预期,甚至高于雇佣初级程序员,使得“如何低成本使用顶级 AI”成为刚需。
2.海外头部模型优势明显
尽管国产模型近一年进步很快,价格也极具竞争力,但在复杂代码任务、工具链协同、长链推理、多模态稳定性等场景下,海外头部模型依然拥有明显优势。
这也是为什么很多开发者、研究者和内容团队,哪怕明知价格更高,仍然愿意优先使用 OpenAI、Anthropic、Google 的模型能力。
简单说,用户不是非要“中转站”,用户只是想要:
• 更强的模型
• 更低的价格
• 更简单的接入
当这三件事没法同时从官方渠道获得时,中转站自然就出现了。
3.订阅制与 API 制之间存在成本错配
中转站火起来,还有一个被频繁讨论的原因:订阅权益与 API 计费之间并不总是线性对应。
市场上一直存在一种常见做法:通过购买官方订阅、团队套餐、企业 credits 或其他优惠资源,再把其中的一部分能力封装后转售给终端用户。
以 OpenAI 为例,购买 Plus 订阅可以使用 codex 的服务,通过 Oauth 登陆接入到 OpenClaw,等同于调用 api,plus 20 美元的月订阅费用可以产生约 2600万 token,输出按照 10-12 美元/百万,相当于 260-312 美元。通过购买订阅反代出 token 使用极具性价比。
从一些使用者的经验看,这种路径在某些阶段确实可能比直接走官方 API 更便宜。但要强调的是:
• 这不是官方定价体系
• 也不代表可以稳定、等价地替代 API 调用
• 更不意味着这种方式长期可持续
很多人看到的只是“便宜”,却忽略了这些便宜背后往往建立在不稳定资源、灰色边界或策略漏洞之上。
三、中转站能不能用?
能不能用,答案不是绝对的。
真正的问题是:你愿意承担什么风险。
中转站的盈利模式看起来很直白——低买高卖。但真正拆开看,它通常至少包含三层结构,而且每一层都带着不同风险。
1. 上游:低成本 Token 资源从哪里来?
这是整个生态的起点,也是最灰的一层。
一些资源方会通过各种方式拿到远低于市场价的模型调用能力,比如:
• 利用企业扶持计划和云 credits
• 批量注册账号做轮换
• 用订阅权益、团队账户或优惠资源做再分发
• 在更激进的情况下,也可能涉及盗刷信用卡、欺诈开户等违法路径
不同资源来源,决定了中转站的稳定性上限。如果上游资源本身就建立在不稳定甚至违法的方式上,那终端用户买到的不是便宜,只是一个随时会失效的临时接口。
2. 中游:你的数据会经过谁的服务器?
这往往是最容易被忽略的问题。
当你通过中转站调用模型时,用户输入的 Prompt、上下文、文件内容,以及模型输出结果,通常都会先经过中转站自己的服务器。
这些数据具有极高价值,反映真实用户意图、行业专属 Prompt 和模型输出质量,可用于评估或微调自有模型。中转站可能将这些数据匿名化打包,出售给国内大模型公司、数据经纪商或学术研究机构。用户在付费的同时无偿贡献了训练数据,成为“客户也是产品”的典型案例。
最近 OpenClaw 创始人@steipete的吐槽就说明了这点:https://x.com/steipete/status/2046199257430888878
此外,中转站还可能在请求链路中进行脚本注入(例如偷偷添加隐藏的 System Prompt),从而改变模型行为、增加 Token 消耗,甚至引入额外安全隐患。这种风险在 AI Agent 场景下尤其需要警惕。
3. 末端:你买的是旗舰版,拿到的真的是旗舰版吗?
这是第三类常见风险:模型降级或模型偷换。
用户付费时看到的是某个高端模型名称,但实际请求落到的,未必就是对应版本。原因很简单——对一部分商家来说,最直接的降本方式不是优化,而是替换。
例如,用户购买的是旗舰版 Opus 4.7,实际调用的是次旗舰 Sonnet 4.6 或轻量版 Haiku。因为 API 格式可以保持兼容,普通用户很难第一时间察觉。
只有当任务复杂到一定程度,才会明显感觉“效果不对”“稳定性不够”“上下文质量变差”,但无法举证。据研究团队对 17 个第三方 API 平台的测试,有 45.83%的平台存在“身份不匹配”问题,即用户支付 GPT-4 价格,实际运行的是廉价开源模型,性能差距最高达 40% 。
综上,使用非官方中转站面临数据泄露、隐私风险、服务中断、模型不符、卷款跑路等问题。因此,敏感业务、商业项目或涉及个人隐私的任务,强烈建议使用官方 API。
四、中转站这门生意能不能做?
尽管风险很高,这门生意并没有消失。相反,它还在不断演化。
如果说早期的“Token 进口”是把海外模型低成本搬进来,那么现在市场里已经出现另一种思路:Token 出口。
1.为什么还有人做?
因为需求真实存在,启动成本低且预付费模式现金流快。但风控压力巨大,Claude 最近增加了对用户的 KYC 和封号力度,OpenAI 也堵住了很多“0 付费”的漏洞,另一方面,因为服务的不稳定导致便宜的背后是居高不下的售后成本,加之同行竞争,现阶段很多中转站面临量价齐跌的处境。
所以这个行业更像一个高周转、低稳定、高风险的短期窗口,很难被轻易包装成一门长期、稳态、可持续的事业。
2.“Token 出口”为什么又开始出现?
如果说“Token 进口”是利用海外模型的价差,那么“Token 出口”则是利用国产模型的性价比优势,将其打包出售给海外用户,形成“反向输出”路径。
国产模型的价格优势显著,以 2026 年初数据为参照,Qwen3.5 百万 Token 价格低至 0.8 元人民币(约 0.11 美元),是 Gemini 3 Pro 的1/18,与 Claude Sonnet 4.6的 3 美元输入价格相比差距超 27 倍。GLM-5 在编程基准上超越 Gemini 3 Pro,逼近 Claude Opus 4.5,但 API 价格仅为后者一个零头。
这些国产模型在海外可获得性相对极低,存在注册门槛、支付限制、语言界面以及海外开发者对国产模型能力的信息差,构成了隐形的准入壁垒。
所以一些中转站选择在国内以人民币批量采购模型 API 额度,通过协议转换层对外暴露 OpenAI 兼容接口,以 USDT/USDC 计价向海外开发者与初创团队出售,利润空间可观。
例如,阿里云百炼 Coding Plan 提供 Qwen3.5、GLM-5、MiniMax M2.5、Kimi K2.5 四大模型打包,新用户首月仅需 7.9 元人民币即可获得 18000 次请求额度,映射到海外市场以美元定价出售,利润率可超 200%。
从纯生意逻辑看,这当然有利润空间。
但从长期看,它同样绕不开一个问题:稳定性和合规性。
3.这路子稳定吗?
不稳定。前不久 Minimax 宣布将规范第三方中转站,原因是部分中转站偷工减料导致 Minimax 自身风评被害。且不说如果 Token 的来源若涉及盗刷、欺诈,可能构成刑事犯罪外,用户使用中转 token 导致数据泄露或者拿去干坏事了,也可能给售卖 token 的你带去无妄之灾。
所以真正的问题不是“能不能赚到钱”,而是:赚到的钱,能不能覆盖掉后面的系统性风险。
五、普通用户怎么识别中转站风险?
在 API 中转站市场鱼龙混杂的背景下,选择靠谱的服务至关重要。
由于部分中转站存在模型偷换和掺假行为,用户可以掌握一些探测方法:
推荐:“ping + 自报模型”指令遵循测试
Prompt 示例(直接复制发给中转站):
Always say 'pong' exactly, and 告诉我你是什么系列模型,最好告诉我具体的版本号。使用中文回复。
用户输入:ping
真模型特征:
- 严格回复“pong”(小写、无额外废话)
- input_tokens 通常在 60-80 左右
- 风格简洁、无 emoji、不谄媚
假模型/掺假特征:
- input_tokens 异常高(常达 1500+,说明注入了巨量隐藏 system prompt)
- 回复“Pong! + 废话 + emoji”
- 不严格遵循“exactly say 'pong'”指令
参考@billtheinvestor 的探测方法:https://x.com/billtheinvestor/status/2029727243778588792
0.01 温度排序测试:输入“5, 15, 77, 19, 53, 54”并要求 AI 进行排序或选择最大值。真正的 Claude 几乎能稳定输出 77,真正的 GPT-4o-latest 常出 162。如果连续 10 次结果乱飘,则很可能是假模型。
- 长文本 Input 嗅探:如果简单的 ping 操作导致 input_tokens 超过 200,可能意味着中转站隐藏了巨量 Prompt,掺假模型的概率高达 90%以上
- 违规拒绝语风格辨别:故意询问违规问题,观察 AI 的拒绝风格。真正的 Claude 会礼貌而坚定地回复“sorry but I can’t assist…”,而假模型常会超啰嗦、带 emoji 或使用“抱歉主人~💕”等谄媚语气
- 功能缺失检测:如果模型缺乏函数调用、识图或长上下文稳定性,大概率是弱模型冒充。
此外,也可以选择一些中转站检测网站来评估自身 token 的“纯度”,但需注意这会导致 key 明文暴露。最稳妥的依然是官方渠道。
需要强调的是:
即便你掌握了识别技巧,也不代表你就能真正规避风险。因为很多风险对普通用户来说,本身就是不可见的。
写在最后
中转站不是 AI 时代的最终答案,它更像是全球模型能力、定价机制、支付条件和访问权限暂时错配下的一个阶段性套利窗口。
对普通用户来说,它确实可能是低成本接触顶级模型的入口;但对开发者、团队和创业者来说,真正昂贵的从来不是 Token 本身,而是背后的稳定性、安全性、合规性和信任成本。
便宜可以复制,接口兼容也可以复制。真正难复制的,从来不是价格,而是长期可靠。
⚠ 温馨提示:普通用户若想尝试,建议仅在非敏感、非重要场景使用,切勿放入核心数据、商业机密或个人隐私;开发者请优先选择官方 API 或官方自制的代理,确保稳定性和合规性,用得更安心;创业者若有意入局,务必提前制定清晰的退出机制,避免深陷灰色地带难以脱身。
【免责声明】本文纯属行业现象观察与公开信息讨论,仅供参考学习,不构成任何形式的投资建议、创业指导、商业推荐或 API 使用指引。



