根据 Vectara 的 HHEM 2.1 基准测试,中国 DeepSeek 实验室的旗舰推理模型 DeepSeek-R1 的得分高达 14.3%。这几乎是其非推理前代产品 DeepSeek-V3(得分 3.9%)的四倍。
这一差距给加密货币行业带来了棘手的问题。目前,快速增长的一类人工智能代理代币正依赖于推理型逻辑逻辑模型(LLM)来实现自主交易、信号传递和链上执行。
Vectara数据显示R1存在“过度引导”虚假事实的情况
Vectara使用其专用的幻觉评估框架 HHEM 2.1 对两个 DeepSeek 模型进行了测试。研究团队还使用 Google 的 FACTS 方法对结果进行了交叉验证。在所有测试配置中,R1 产生的错误或无根据的陈述都比 V3 多。
原因并非仅仅是推理深度不足。Vectara 的分析师发现,R1 模型往往会“过度辅助”。该模型会添加一些源文本中并未出现的信息。
即使添加的细节本身在事实上是正确的,它仍然可能被归类为幻觉。这种行为将捏造的背景信息巧妙地融入到原本合理的答案中。
Vectara 在 X 上以公开帖子的形式直接公布了这一调查结果。
Vectrara 在一篇帖子中指出: “DeepSeek-R1 的幻觉发生率为 14.3%,几乎是 DeepSeek-V3 的 4 倍。”
这种模式并非DeepSeek独有。业内人士也注意到,其他实验室的推理训练模型也存在同样的权衡取舍。强化学习虽然能够提升思维链的清晰度,但也鼓励更大胆、更自信的决策。
为什么加密人工智能代币面临这种权衡取舍
目前加密货币市场拥有数百种 AI 代理代币,其中以Virtuals Protocol (VIRTUAL) 、ai16z (AI16Z) 和 aixbt (AIXBT) 为首。
该类别在最近30天内实现了约39.4%的增长。仅虚拟产品一项的市值就已超过5.76亿美元。
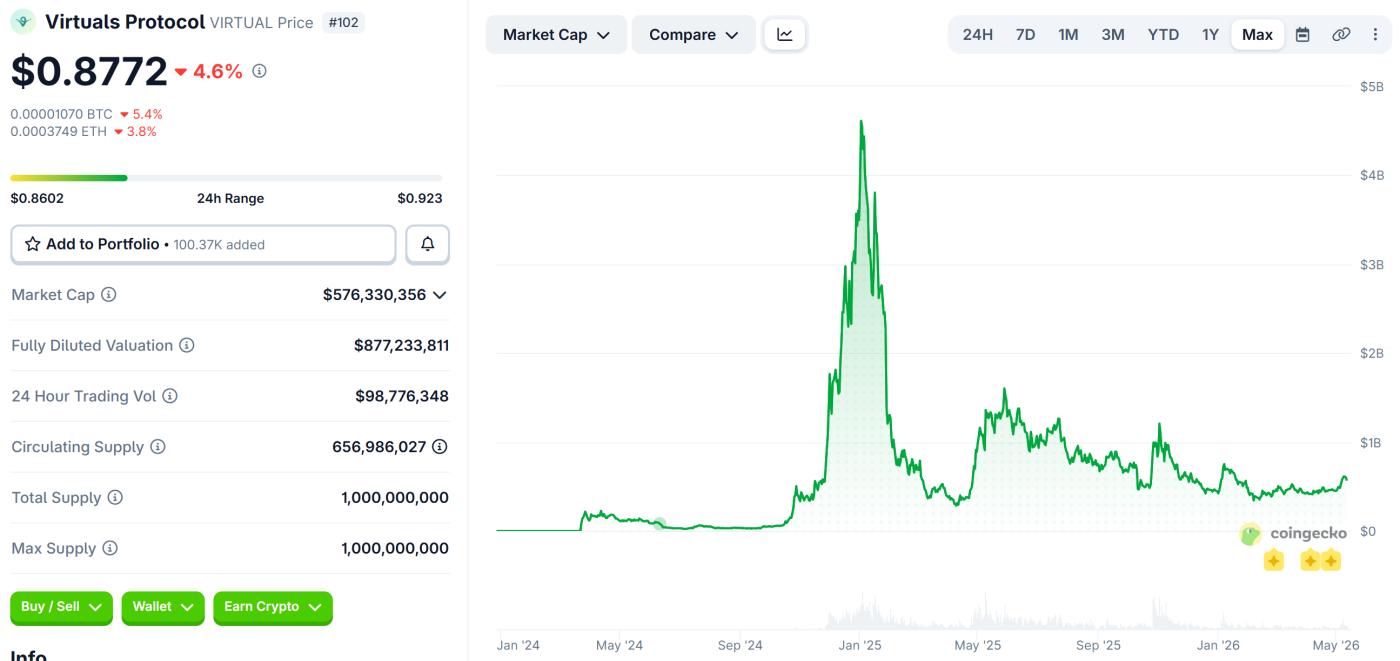 Virtuals Protocol (VIRTUAL) 价格表现。来源: Coingecko
Virtuals Protocol (VIRTUAL) 价格表现。来源: Coingecko这些智能体大多将大型语言模型封装在工具集中。这些工具集使智能体能够在社交媒体上发布内容、安排交易、铸造代币或生成市场评论。
当底层模型捏造价格水平、合作关系或合约地址时,其后果可能会波及链上。
BeInCrypto对 AIXBT 的一项分析显示,该代理人推销了 416 个代币,平均回报率为 19% 。然而,同样的表面机制也使得追随者在模型失效时面临错误的投资决策。
风险面随自主程度而变化。仅用于汇总情绪的只读代理与持有国库密钥的代理在利益关联度上有所不同。
推理模型对于需要进行多步骤规划的智能体来说尤其具有吸引力。而Vectara 14.3%的收益率数据,在这种应用场景下显得尤为刺眼。
思维链早期出现的一个幻觉事实,可以影响后续的每一个行动。
勒昆认为问题出在建筑方面。
Meta公司的首席人工智能科学家Yann LeCun长期以来一直认为,自回归逻辑线性模型无法完全摆脱幻觉。在他看来,这种架构本身缺乏任何基于现实世界的模型。
在数学和编程等特定领域,基于思维链的强化学习可以掩盖问题,但根本原因依然存在。
其他前沿实验室对此持不同意见。他们指出,通过检索增强、训练后微调和验证模型,基准幻觉率取得了稳步提升。然而,开发者的报告往往与排行榜数据相符。
AI 研究员 xlr8harder 在 X 上撰写了一篇关于使用 R1 进行调试的文章,总结了当天的经历。
“Deepseek R1 对其思维轨迹的理解似乎存在一种有趣的、不整合的问题……所以它默认会用幻觉来让我产生精神错乱,”他们说道。
对于加密代理开发者而言,实际问题是风险管理,而非架构理念。将每个模型声明都经过验证步骤的设计方案可能效果更好。
对于那些依赖规模较小、更为保守的金融行为模式的代理人来说,情况也是如此。
接下来的排行榜周期以及 R1 的最终继任者将会显示,推理与准确性之间的权衡是否正在缩小。
目前来看,14.3% 和 3.9% 之间的差距是一个值得关注的运营细节。它能够区分真正交付可用产品的 AI 代理代币和那些仅仅做出承诺的代币。