文章的核心观点是:金融AI的竞争焦点不在于谁能打造一个更会聊天的“金融版ChatGPT”,而在于谁能深度融入金融从业者的日常工作工具(如Excel、PPT、Word)和核心业务流程(如尽调、审批),并直接输出可被审阅、归档的正式“交付物”。
文章作者:Resonant Ones
文章来源:遂初.AI
金融 AI 的竞争不在"谁会聊天",而在"谁能进入 Excel、PPT 和审批流"。
很多人以为,金融 AI 的竞争,是训练一个更懂金融的大模型。
但 Claude for Financial Services 暴露了真正答案:金融 AI 的核心不是模型,而是工作流。
它不是让 AI 陪用户聊股票,而是让 AI 进入 Excel、PPT、Word、投研、投行、尽调、合规、对账和审批流。
这件事对国内创业者很关键。因为如果你还在做"金融版 ChatGPT",大概率会被大厂、数据终端和办公套件吃掉;但如果你能接管金融机构每天重复生产的 Excel、PPT、Word 和审批包,机会才刚刚开始。
一个真实场景
上个月我和一个做 PE 的朋友聊。他们团队对一家消费公司做尽调,收到的 Data Room 有 17 个文件夹、400 多份文件——合同、审计报告、银行流水、订单明细、访谈纪要、管理层材料。
以前一个 VP 带着两个分析师干两周,才能出一份像样的 IC Memo 初稿。
现在呢?如果有一个人(或者一个 Agent)能在 24 小时内跑完资料梳理、风险标记、缺失项识别和初稿生成——你觉得客户会不会买单?
这不是科幻。Claude for Financial Services 已经在做这件事了。而它开源的不是一个 App,是一套「Agent + Skill + Connector + 交付物 + 人工签核」的产品范式。
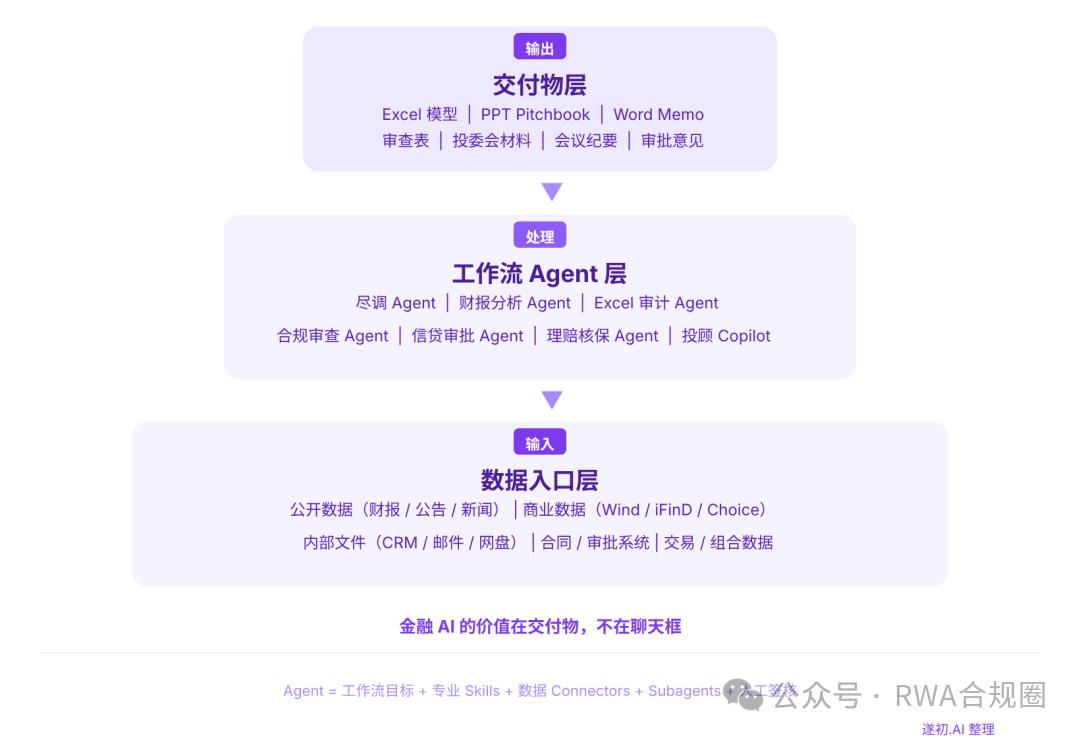
先说第一个发现。Claude for Financial Services 的产品结构其实很简单:Agent 负责端到端任务,Skill 沉淀金融专业流程,Connector 接入金融数据和企业内部系统,Excel、PowerPoint、Word 承接最终交付物,再加上权限、引用、审计、人工复核保证金融机构能用。
过去金融 AI 的形态是你问一个问题,AI 给一个答案。但金融机构真正需要的是:你给我一堆资料,我要一份能被审阅、能被引用、能被归档、能进入业务系统的交付物。这两者差别巨大。金融 AI 的价值在交付物,不在聊天框。
另一个值得关注的变化是,国内金融机构已经不是观望状态了。
2025 到 2026 年,我看到的落地情况大致分三个梯队。银行走得最快,建设银行完成 DeepSeek 私有化部署,覆盖了数百个场景。中信建投基金用 DeepSeek 做 REITs 尽调,5 名员工 70 天的工作量压缩到 1 人 10 天——效率提升了 30 倍。
券商人保财险也跟上了,中信建投证券基于多智能体做投顾服务,人保财险接入 DeepSeek 建专业知识库,平安大模型半年调用 8.18 亿次。
但真正有意思的是第三梯队——PE、资管和财富管理。它们数据多、预算足、交付压力大,但目前大多还在 POC 阶段。这不叫落后,这叫创业公司的窗口期。
说到创业公司切入,很多人第一反应是做金融版 ChatGPT。但这件事风险很大,因为会同时遇到三类强敌。
模型厂商会把通用能力越做越便宜。金融数据终端像 Wind、Choice、iFinD、同花顺,本来就有数据和用户入口,AI 一嵌进去,泛金融问答很难独立收费。大型金融机构更倾向于自建内部 AI 中台,把通用能力放进自己的权限体系里。
创业公司正面打,三线受敌。
但如果你换个角度,不看入口,看操作层,情况就不一样了。什么叫垂直操作层?就是围绕一个具体岗位、一个具体流程、一个具体交付物,把 AI 做深。比如 PE/投行尽调资料结构化、Excel 财务模型审计、信贷审批材料初审、合规审查表自动生成、保险理赔和核保材料辅助审核、客户经理会议纪要自动整理。
这些方向看起来不如"金融大模型"宏大,但更接近客户预算。
什么样的产品值得做
我总结下来,必须同时满足四个条件。
接得住数据
真正高价值的场景,往往要接客户内部文件、CRM、网盘、邮件、合同、审批系统。只处理公开网页,价值很有限。
跑得通流程
金融用户不会为了 AI 改变工作习惯。产品要进入他们已经在用的 Excel、PPT、飞书、企业微信、钉钉、WPS、CRM。
交得出文件
金融机构买单的不是回答,而是材料。能输出审查表、memo、deck、Excel,才有付费意愿。
留得下责任边界
AI 必须支持引用、留痕、权限、审计、人工复核。不做投资建议、不自动交易、不替代最终审批。
这四条缺一条,产品就很难进入真实生产环境。
如果把视角拉远,看未来 24 个月,我觉得最值得关注的细分方向有七个。
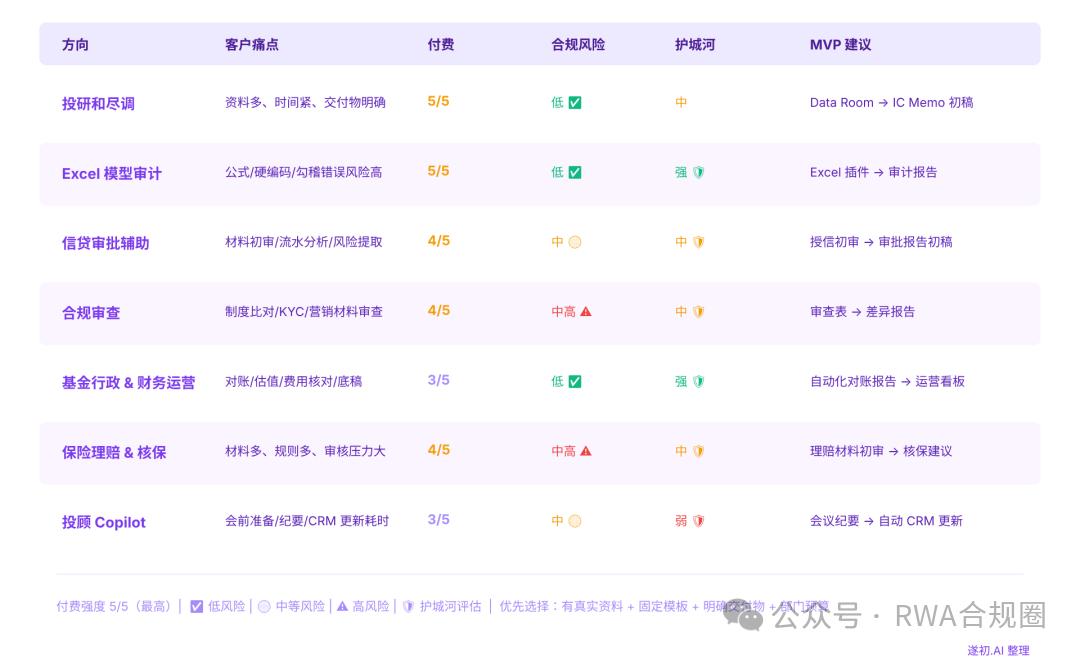
投研和尽调排第一。资料多、时间紧、交付物明确,是最接近 Hebbia 和 Rogo 的方向。
其次是 Excel 模型审计——投行、PE、信贷、资管都有大量 Excel,公式错误、硬编码、假设不一致,AI 辅助空间极大。
信贷审批辅助排第三,银行和非银都需要材料初审、流水分析、风险提取和授信报告生成。合规审查排第四,制度比对、营销材料审查、KYC 检查,都适合做可引用、可留痕的 AI 助手。
基金行政和财务运营对账、估值、费用核对、审计底稿非常流程化且错误成本高。
保险理赔和核保材料多、规则多、审核压力大但必须保留人工确认。
最后是客户经理和投顾 Copilot,不是 AI 直接给投资建议,而是帮顾问做会前准备、产品解释、会议纪要、CRM 更新。
这七个方向有一个共同的前提:产品必须可审计、可引用、可私有化。
金融机构不会接受"AI 大概是这么说的"。数字从哪来?引用在哪里?谁复核过?数据是否出域?这是采购决策的前提条件。所以从一开始就要设计引用溯源、人工签核、数据隔离和操作留痕。这不是合规成本,是产品壁垒。
还有一个更大的趋势。模型能力商品化之后,机会转向 workflow、connector 和治理层。就像当年云计算让 IT 基础设施变成 API,新一代创业者会在上面做 SaaS。今天的大模型也一样——谁能在上面封装行业工作流,谁就有壁垒。
金融行业知识工作信息密度高、格式要求高、责任约束强,这些特性决定了它不是通用 AI 能快速覆盖的。这恰恰是创业公司的安全区。
创业公司怎么切入
不要一开始做平台。
找一个窄场景:有真实资料、有固定模板、有明确交付物、有人工复核、有部门预算、能在 60-90 天内验证 ROI。
不要这样说:
我要做金融机构 AI 平台。
要这样说:
我先帮 PE/FA 团队把 Data Room 资料自动结构化,输出尽调 Q&A、风险清单和 IC Memo 初稿。
越具体,越容易成交。
最大风险被大厂替代?
通用入口会被替代。泛金融问答、普通研报摘要、简单数据查询,很容易被大模型和数据终端覆盖。
但垂直深流程不会。
因为大厂不愿意为每个细分岗位做脏活。真正难的是:接入客户内部系统、理解岗位流程、适配客户模板、陪客户从 POC 跑到生产。
这些不是一个模型 API 能自动解决的。