

注:本文来自@BlazingKevin_ 推特,MarsBit整理如下:
1/ Arweave 2.6版本已发布,将在3月6号完成硬分叉升级,主题围绕如何降低能源消耗,并提升存储激励。
Arweave上一次重要升级要回溯到21年2月的2.4版本,完成了SPoA到SPoRA的升级,激励矿工提高对数据的访问速度。
在Arweave迎来又一次重大升级之际,本文将回顾此前的历次升级,让大家有更充分的了解
2/ Arweave 1.5(2018年10月 主网上线)
上线时的weave size只有177Mi,这个部分我会介绍Arweave网络中的一些特有名词,这里我们遇到了第一次名词是区块坊(block weave)。
区块坊是Arweave网络的区块结构,和普通区块链一前一后的连接方式不同。
3/ Arweave 的数据结构并不是严格的单链列表而是复杂一点的图结构,结构中每个区块一共与三个区块相关,当前块的前一个和后一个块以及随机的指向一个之前的块称为回忆区块 (recall block/recall chunk),由此构成区块纺(摘自Arweave黄皮书)。
4/ 回忆区块是根据前一个块的哈希和高度确定的,密码学原理保证了回忆区块在选定时既有确定又不可预测。
此时Arweave的性能如下:

5/ 和PoW以及PoS的挖矿机制不同,Arweave的挖矿机制是访问证明(Proof of Access)。 在早期的Arweave中,访问证明是指矿工为了获得打包新区块的权利,必须证明他能够访问历史区块的数据,也就是说矿工必须储存历史数据。
6/ 实际工作中,每当一个新区块产生时,PoA会随机挑选一个历史区块作为回忆区块,并要求矿工将回忆区块放入新区块当中。
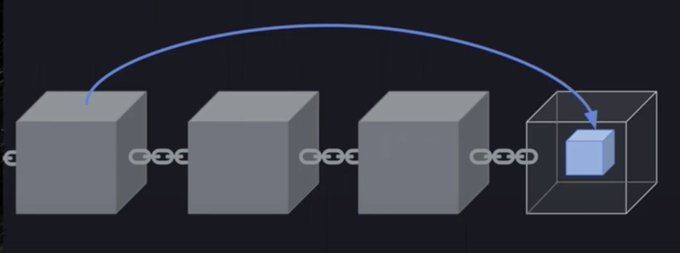
7/ 因此,在 Arweave 网络中不存在存在全节点和轻节点概念,新矿工加入网络后只需要从储存新块和会议区块开始,而不必存储所有的历史区块。矿工之间存储的副本(回忆区块)数量也是不同的。
8/ PoA共识要求矿工必须存储回忆区块,但不要求矿工存储全部历史数据。前文图中,我们看到Arweave的区块时间是2分钟。在这两分钟里,还进行着激烈的PoW竞争,是的,在Arweave中工作量证明被包含在了PoA共识当中。
9/ 两分钟的挖矿过程可以被分为两个部分,第一个部分我们已经了解,就是访问证明。当新区块到来时,在2分钟的时间里,PoA共识会随机选择一个历史区块作为回忆区块,对回忆区块拥有访问路径的矿工才有资格进入第二部分的工作量证明竞争中,如果一个矿工没有储存回忆区块,他可以向附近的矿工发送申请。
10/ 即时存储这个回忆区块并以落后的速度进入工作量证明中。从这里可以看出,矿工同步的历史区块越多,同步的稀有区块越多,通过第一部分要求的可能性就越大,Arweave巧妙地将对历史数据的存储从要求变成了激励。在第一部分中,拥有回忆区块的矿工们会进入工作量证明。
11/ 在1.5版本的Arweave中,工作量证明是纯粹的哈希算力比拼:消耗资源,堆积硬件。矿工们朝着两分钟的终点线疯狂计算,当两分钟时间截止时,计算量最高的矿工获胜。下一个区块的竞争重新开始。
12/ 这种PoA设计出现了一个问题,由于矿工能在第一部分时向附近矿工下载回忆区块,因此很多矿工选择不储存历史区块,而是堆积大量gpu硬件来并行计算。这样一来即使稍微落后进入第二部分,依然能依靠大量算力反败为胜。
13/ 这种策略逐渐变成主流,矿工们放弃对于历史数据的存储,放弃对于副本的快速访问,而选择堆积算力。这种策略导致的结果是,历史数据会逐渐中心化,整个网络的资源消耗会爆发式增长。
最初的Arweave网络设计具有缺陷,没有限制对于gpu的堆砌。在2019年6月,Arweave推出了1.7版本。
14/ Arweave 1.7(2019年6月 Random X)
为了限制矿工疯狂堆积gpu的行为,在1.7版本中,Arweave推出Random X。Random X是一个哈希方程式,特点是很难在gpu或者Asics上运行。矿工无法堆积gpu挖矿后,只能依靠单一cpu来完成工作量证明,减少了能源消耗。
15/ Arweave上没有全节点这个概念,也就是说矿工之间不必维护共识,那么当用户发送一笔交易时,矿工们会互相分享同步吗?答案是会的,试想我是一名矿工,我必定希望挖出新块时能获得最大的收益,当我收到用户交易时,我会选择将交易传播给网络中的其他矿工,如此一来,其他矿工也会将各自收到交易同步
16/ 我们可以将其看作一种激励措施,如果矿工们互相不分享交易,那么获胜矿工打包的区块中交易数量会减少,用户体验下降后,网络陷入死亡螺旋。为了收益,矿工们会积极同步交易。
17/ Arweave是一个存储网络,和普通区块链不同,一笔交易最高有5.8MB。矿工们需要在两分钟的时间内同步所有的交易,并完成工作量证明,这对交易的传输速度提出了要求。
18/ 同时Arweave网络的可拓展性也受到了限制,矿工们需要尽可能确保在第一部分时完成对回忆区块的访问或下载,以及同步用户的新交易,否则在第二部分工作量证明中,矿工们不能处于同一起跑线。Arweave的网络发展遇到交易传输速度的瓶颈(transmission bottlenecks)。
19/ Arweave 1.8(2019年10月 交易最大size翻倍到10MB)
5.8MB的大小对于普通交易绰绰有余,但是对于存储网络来说还是太小,有时甚至无法容纳一张图片,更不用说音频和视频。在2019年10月,Arweave将单笔交易的最大容量提升到10MB。
20/ 但是交易传输的瓶颈还是没有解决,Arweave的终极目标是存储人类历史,成为现代的亚历山大图书馆。为了达到这个终点,Arweave必须解决可拓展性的问题。Arweave是一个分布式网络架构,矿工分散在全球不同地区。客观上,矿工使用的硬件和拥有的网络条件各不相同,无法统一。
21/ Arweave网络的性能实际上取决于所有节点的平均传输速度,增加网络中矿工的数量会增大单位时间内同步数据的传输速度需求,盲目增加矿工或者提高交易和区块大小来拓展网络会导致用户交易丢失,因此在这个阶段,Arweave无法提高可拓展性,网络中历史数据增速在一个较低的速度。
22/ Arweave 2.0(2020年3月 SPoA)
为了打破传输瓶颈,Arweave在2.0版本中,引入两个概念:succinct proof(简洁证明)和format 2 transaction(新型交易格式)。
简洁证明用到了一个常见技术,默克尔树,在矿工打包新区块时,必须证明他们拥有回忆区块的副本/访问,并且在新区块中包含回忆区块。
23/ 这使得未存储该回忆区块的矿工必须先消耗带宽从附近矿工那里下载整个回忆区块,随着单笔交易容量增加,区块大小也在增加,传输回忆区块的带宽要求也在进一步提高。矿工们为了收益最大化,必须尽可能多的等待其他矿工传来的交易,而未存储回忆区块的矿工会在同步回忆区块后才开始分享交易。
24/ 区块大小的增加缩短了矿工们分享交易的时间,部分矿工不得不在未同步全部交易的情况下开始工作量证明。为了解决这个问题,简洁证明让矿工能够将回忆区块按照默克尔树的排序方式打包,最终生成一个root proof,也被成为简洁证明,用来证明矿工能够存储了该历史区块。
25/ 简洁证明代替了回忆区块,可以被矿工同步,也可以被放入新区块中,节省了区块空间和区块传输成本。
format 2 transaction是Arweave引入的新交易格式,帮助其将区块能容纳的交易量无上限增加。旧的交易数据包括header和data,二者不可分开。
26/ format 2当中交易的header和data能够拆分开,为什么拆分交易能够无上限提升区块交易量呢?让我们回到2.0版本的2分钟区块时间内,在第一部分当中,矿工会同步简洁证明,快速建立和回忆区块的连接,与此同时旧版本的交易格式也没有删除。
27/ 在第一部分中,format 1交易依然会完全在矿工之间同步,header和data没有分割。不同的是,用户发出的format 2交易只有header被放入新区块中,也只有header在矿工之间同步。
28/ 简洁证明和format 2交易的引入,极大的减轻了第一部分中矿工之间同步的数据量,提高了Arweave的可拓展性。当新区块产生时,它的区块组成是:对于回忆区块的简洁证明、format 1交易的完整数据和format 2交易的header。
29/ 可以想像此时的区块是一个巨大乐高模型,但是中间很多零件是空白的,这些空白的零件就是format 2交易的data部分。data数据会在下一个区块进行到第二部分时完成同步,因为工作量证明不占据带宽,完全可以在cpu进行哈希计算时,利用带宽同步上一个区块未传输的data数据。
30/ 新区块生成时只有交易header是没有问题的,因为通过header也可以完成验证,但是随后必须补齐数据,因为未来某个时刻会把当前区块作为回忆区块,回忆区块能生存简洁证明,但前提是数据必须完整。
31/ 此刻,Arweave的可拓展性已经被释放,但是新的问题又来了。不同于上文提到的堆砌gpu的策略,SPoA的引入让矿工们又走上另一条歧路。我们知道,简洁证明的引入让矿工能够很快同步回忆区块的信息,矿工们不再存储历史区块而是选择等待其他矿工同步的简洁证明,并将成本偏移到挖矿硬件上。
32/ Arweave 2.4(2021年2月 SPoRA)
PoA 只能保证永久存储,不能保证访问速度。在数据检索方面没有竞争优势的情况下,矿工们可以通过使用远程存储池中获益,而不是维护单独的、去中心化的节点。为了解决矿工们不再存储历史副本的问题,Arweave将SPoA升级到SPoRA(succinct proof of random access)
33/让我们再次回到2分钟到区块时间里,在第一部分中,没有任何变化,矿工们可以通过同步简洁证明来获得进入第二部分的资格,大部分的矿工选择使用远程存储池,通过提升带宽速度,快速同步和访问远程内存,不会选择自己构建存储池。
34/ SPoRA的引入让第二部分变得不同,SPoRA提出的哈希计算会要求矿工针对回忆区块里某一个交易计算哈希值,生成一个轻量的简洁证明,并且进行第二部分时,矿工之间无法传递简洁证明。
35/ 对于没有构建自己存储池的矿工来讲,可以想象成他们被强制退回到第一部分,在远程存储池中找到哈希值,再进入第二部分的工作量计算。可是SPoRA对于回忆区块里哈希计算是随机且不间断的,没有个人存储池的矿工会不断被退回到第一部分。
36/ 这样的设计要求矿工必须维护自己的个人存储池,SPoRA 降低了之前矿工出块概率的权重,加入了对数据访问速度的考量。
37/ SPoRA 通过抑制 CPU 之间的资源池创建了一个更加去中心化和高效的区块编织,让矿工专注于维护本地硬件和节点,实现地理位置多样化以及去中心化,以此来激励矿工更高效、更迅速地复制数据。(摘自Arweave黄皮书)
38/ 新的设计又带来了新的问题,现在我们能确保矿工尽可能多在个人硬盘里存储尽可能多的历史副本。但是,如前文提到的,SPoRA加入对于数据访问速度的考量,矿工如果不能快速的在硬盘中找到SPoRA要求的交易数据,并且不能及时生成轻简洁证明的话就无法获得挖矿奖励。
39/ SPoRA让矿工们追求硬盘读取速度,能够更快检索数据,更快计算哈希值意味着更高的奖励。补充一点,硬盘的价格和读取速度基本是成正比的,70刀的机械硬盘读取速度是750MB/s,而700刀的固态硬盘读取速度是7300MB/s。
40/ 矿工想要更高的收益就需要更高的付出。这是一个合理的机制,但却还有更优解,SPoRA没有考虑到Arweave矿工的入门门槛,变相限制了Arweave的可拓展性。
以上是针对@ArweaveEco @ArweaveNewsCN历次升级的一个回顾,文章有点长,感谢看到这里的各位。下一个
我将从自己的角度来理解Arweave2.6,谢谢





