

作者:imToken Labs
概述
5 月11、12 日连续两天晚上,以太坊共识层短暂异常,imToken 分析该异常主要某几种以太坊共识层客户端节点负载过高,使得Validator 宕机离线,直接导致Epoch 投票无法达到2/3,共识层无法确认最终性,但短时间过后以太坊网络自我恢复正常,imToken 认为这表明以太坊PoS 共识算法具备韧性和自我修复的能力。
事件及背景
通常情况下,以太坊PoS 共识网络状态会在2 个Epoch 被敲定(Finalized),而上周出现了两次Epoch 敲定的延迟。
第一次发生在5 月11 日,Epoch 的敲定被延迟了3 个Epoch,约20 分钟。
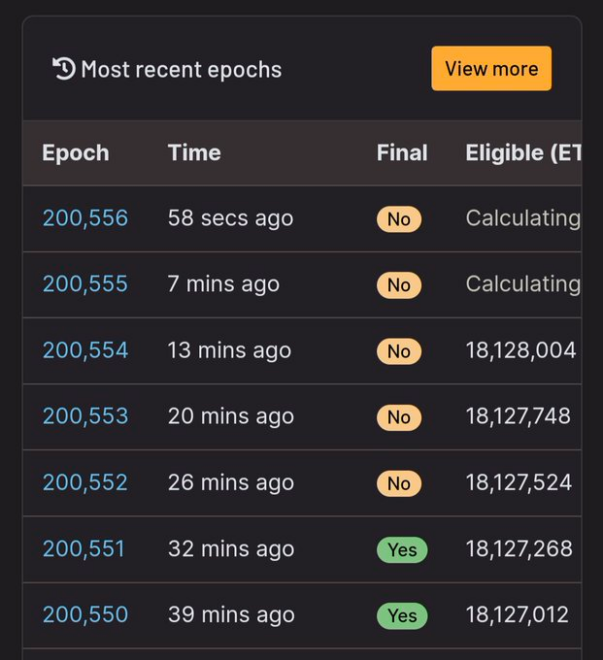
第二次发生在5 月12 日,Epoch 的敲定被延迟了8 个Epoch,约51 分钟。
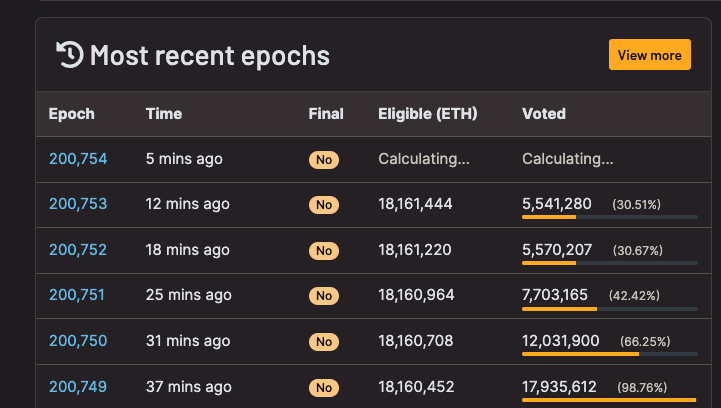
在事件发生期间,以太坊网络仍然持续产生区块并处理交易。然而,由于Validator(验证节点)的投票率不足,Epoch 无法敲定(即Epoch 得到以太坊PoS 网络共识级别安全保证)。 Epoch 未能敲定意味着在绝大多数Validator 作恶并出现分叉的情况下,epcoh 可能被回滚,从而导致交易被回滚。
实际上,在事件发生的期间,以太坊网络并未出现分叉,而Validator 也未进行恶意投票,只因大量Validator 离线导致投票率不足,从而使得Epoch 在期间无法被敲定。
经过观察,离线的Validator 出现CPU 过载的异常情况,被认为是Validator 离线的直接原因。

在第二次事件中,Epoch 敲定被延迟了8 个Epoch,由于敲定延迟大于MIN_EpochS_TO_INACTIVITY_PENALTY (=4) 从而触发了以太坊共识算法Inactivity leak的处理机制。
- 惩罚离线的Validator,削减其质押资金, 罚冇了约28 个ETH 。
- 取消Attestation 的奖励,导致约50 个ETH未被发行。
- 该机制保证在线Validator 最终能掌握以太坊总质押资金的⅔,从而使得网络状态最终能被敲定
imToken 的节点服务也侦测到了此次事件,通过实时监控以太坊共识层Validator 投票的情况,从而在Epoch 未能正常敲定前,提前预警以太坊共识网络的异常。下图是第一次事件发生时的节点状态。
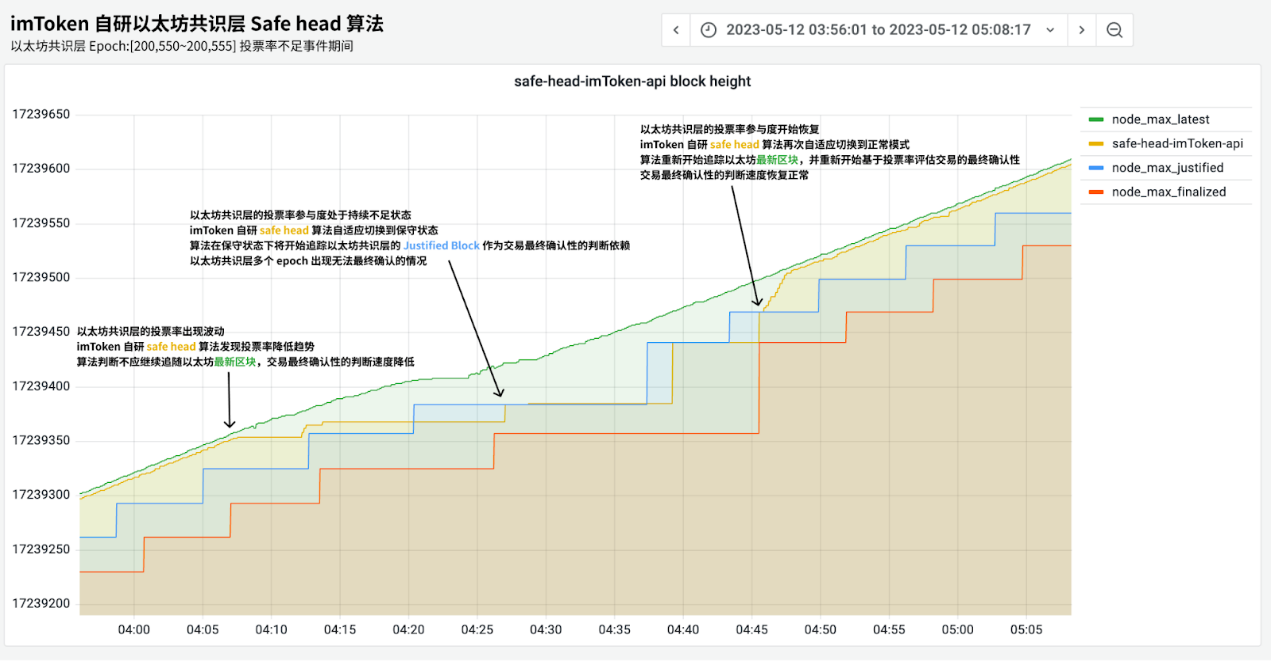
PoW 机制下,交易的成功是认定交易在多少连续区块后大概率不会被回滚,PoS 则是以Safe Head 返回的块高作为交易成功的判定。而目前的规范中则是以Justified Checkpoint 作为Safe Head 的状态认定,因此以前一Epoch 的状态来看,可能存在有6.4 分钟之久的判定延迟,这对用户而言是很糟糕的体验。
imToken 自研的Safe Head 服务会基于实时的以太坊共识层数据,计算出安全的区块用于交易确认,在保证用户交易安全的前提下,缩短交易确认的时长。正常情况下,imToken 的Safe Head 算法返回的块高(如上图黄色),会非常贴近最新的区块高度(绿色),从而提高用户体验。
更多关于Safe Head 机制的资料:
原因分析
造成上述事件的直接原因是某几种以太坊共识层客户端节点负载过高,使得Validator 宕机离线,从而无法正常进行共识投票。经过分析,这些节点负载过高的原因是:
当收到指向陈旧区块的见证( Attestation )时,节点需要重新计算信标链状态以验证这些见证,而该过程需要消耗大量的CPU 以及内存资源。
当同时收到大量指向陈旧区块的见证时,节点的CPU 以及内存资源被耗光,从而导致这些Validator 宕机离线。
本来此类问题可以通过基于见证指向区块的缓存来解决,然而由于Validator 的规模增长以及大量此类attestation 的出现,导致出问题的客户端实现的缓存被击穿,节点不得不消耗大量资源重新计算信标链状态。
共识层客户端Teku 以及Prysm 目前推出了patch 版本以解决该问题。具体而言,patch 版本的客户端实现会过滤掉这些陈旧的见证,即当满足下列条件,忽略该见证:
- 见证指向一个陈旧的Slot
- 见证指向一个节点从未见过的Checkpoint
然而,我们仍需持续观察以太坊主网敲定的情况以确认patch 的有效性。
共识层客户端Teku 以及Prysm 的patch 版本:
- Prysm: v4.0.3-hotfix
- Teku: v23.5.0
以太坊设计优势
在此次事件中,以太坊保证可用性仍持续产生区块并处理交易,而仅推迟Epoch 敲定的关键在于两点:
- 以太坊客户端的多样性
- Gasper 算法的设计
以太坊客户端的多样性
在此次事件中,虽然共识层客户端Teku 以及Prysm 的实现出现了问题,但不影响其他共识层客户端的正常运作。像是Lighthouse 客户端本次并不受影响,由于不同客户端在实现的设计上并不相同,因此仍有Validator 正常在运作。
以太坊客户端的多样性保证了:即使某些客户端出现问题(甚至导致Epoch 不能敲定),也不会影响正常的客户端产生区块并处理交易,使得以太坊的可用性得到保持。
以太坊Gasper 共识算法对可用性的设计
保证以太坊的可用性是以太坊共识算法Gasper 的设计出发点之一,其把以太坊区块生产与敲定分离。因此,即使区块敲定受阻,区块的产生并不会随之终止。考虑到大部分情况下,区块敲定最终会恢复(产生的区块最终仍会被敲定),那么对用户影响其实会很低。对比其他BFT 的共识算法:若区块敲定失败,共识节点会停止产出下个区块。从而,导致期间整个区块链不可用,即俗称的「区块链挂了」。
另外,第二次事件还触发到了Inactivity Leak 的机制,其主要是为了保证以太坊在极端情况(大量Validator 长时间离线)下仍能重新敲定区块。
经验与启示
以太坊多客户端的挑战
当前,以太坊客户端多样性现状如下图所示:
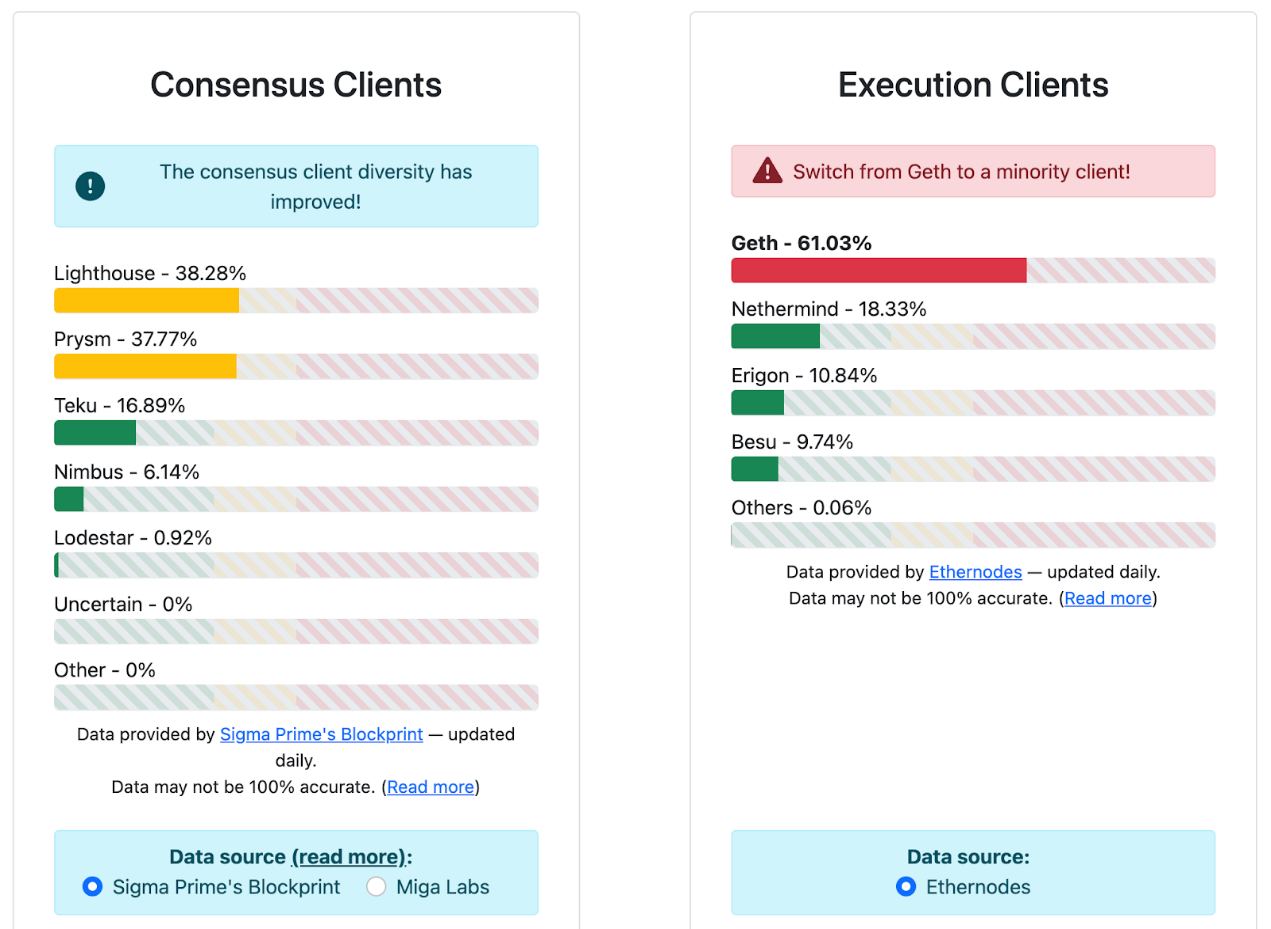
来源: https://clientdiversity.org/#distribution
可以看到,以太坊客户端多样性仍需继续推广和宣传。可以想象,如果客户端实现足够多样,使得Prysm 以及Teku 的占比小于⅓,那么这次事件甚至不会发生(⅔ 客户端正常运作足以敲定Epoch)。另外,当前执行层的客户端集中在Geth,占比高达61%。这实际上存在着潜在风险:如果Geth 运作不当,以太坊会受到很大的影响。
除了以太坊客户端多样性需要进一步努力外,以太坊客户端切换也是此次事件暴露的一个痛点:当某个客户端实现出问题时,Validator 如何切换到正常的客户端实现之上。此过程涉及:
- 把出问题客户端的Validation key 安全地迁移到正常的客户端之上
- 由于以太坊共识有Slash 的规则,需要保证旧客户端与新客户端的行为的一致性而不被Slash。例如:
- 新旧客户端分别对分叉两侧的Checkpoint 进行投票,从而被Slash
- 新旧客户端在同一个Slot 产出不同的区块,从而被Slash
以太坊共识的监控
需要类似Safe Head 类似的服务持续监控以太坊PoS 网络的实时状态,提前发现并预警该类事件,而非等到Epoch 无法按预期敲定才得知网络状态异常。相关的最新研究可见此文章。
以太坊共识算法的科普
这次事件暴露了科普以太坊PoS 共识机制的必要性。在此次事件中,很多用户误以为「以太坊挂了」,从而造成不必要的恐慌。然而,实际上,以太坊网络持续产生区块并处理交易。以太坊共识层和执行层的组合为以太坊交易交易确认带来双重保障,在共识层Epoch 无法敲定的情况下,执行层的区块处理并不受影响,且Epoch 敲定的异常状况也在以太坊共识算法中有相应处理设计。面向用户的区块链知识科普仍然是从业者们需要持续努力的方向。
对以太坊应用的启示
虽然以太坊网络足够健壮,但是偶尔的不稳定会对应用有着一定的影响。同时,应用要正确处理这些不稳定的场景。
- Layer1 -> Layer2 的存款时间会变长。 Layer2 在mint 的时候,一个重要前提是需要保证L1 存款交易不会被回滚。因此,当以太坊网络Epoch 敲定被推迟的情况下,L1->L2 的存款时间也会相应变长。
- 类似的,交易所也需要防止链上充值交易被回滚的情况,因此其充值时间也会相应变长。
- Oracle 链上报价存在被回滚的风险,因此依赖其的高价值服务要适当暂停。
- 在此次事件中,Uniswap 不显示余额、只能买入不可卖出,而dYdX 暂停了存款。
总结
在这次事件中,我们可以看到以太坊PoS 共识算法的韧性与自我修复的能力,也看到客户端很快在发生事故后,即时响应与修正错误。对以太坊整个生态而言,还需在以下方面持续投入:增加客户端多样性,优化对网络状态的实时监控与预警,深度用户教育(不仅面向普通用户,也需面向从业者),生态参与者在网络异常时的紧急预案准备。
参考链接






