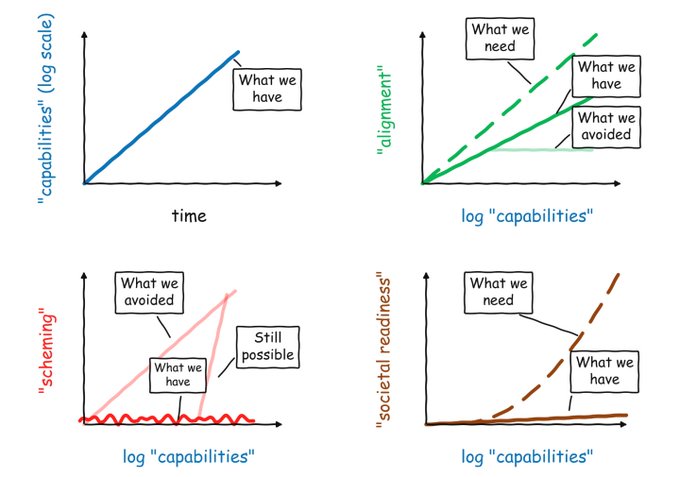
启用 fp8 训练后,“GPT-2 训练时间”提升了 4.3%,现在只需 2.91 小时。另外值得一提的是,如果使用 8 倍 H100 实例价格,复现 GPT-2 的成本实际上只需约 20 美元。这令人振奋——
GPT-2(7 年前):发布风险太大。
GPT-2(今天):新的 MNIST 数据集!:)
肯定能远低于 1 小时。
关于 fp8,我再补充几句。它比我预想的要复杂一些,我花了一段时间才最终决定采用它,即使现在,由于 fp8 的整体支持度较低,我仍然不能完全确定它是否是个好主意。理论上,H100 上的 fp8 浮点运算能力是 2 倍,但实际上却远低于此。在实际训练过程中,我们并非完全受限于计算能力,额外的尺度转换会带来额外的开销,GEMM 模型在 GPT-2 规模下还不够大,不足以明显抵消这些开销,当然,精度越低,每一步的质量就越小。对于逐行缩放方案,FP8 和 BF16 的损失曲线非常接近,但网络步进速度较慢。对于逐张缩放方案,损失曲线的差异更大(即每一步的质量都更差),但至少我们现在获得了速度提升(约 7.3%)。你可以通过增加训练周期(训练更多步,但每一步速度更快)来简单地恢复性能,并希望最终网络性能能够提升。在这种情况下,经过对这些方案和训练周期的调整,目前我最终获得了约 5% 的速度提升。 Torchao 在他们的论文中报告称,Llama3-8B 的 FP8 训练速度提升了 25%(相比之下,我未考虑模型容量的情况下提升了约 7.3%),这更接近我最初的预期,尽管 Llama3-8B 的模型规模要大得多。这可能并非 FP8 的终结。通过精确选择应用 FP8 的层,并更谨慎地处理网络中的数值,应该可以进一步提升性能。
twitter.com/karpathy/status/20...