今日
情报
市场
赚取
设置
账户
主题选择
普通主题
深色主题
语言
English
简体中文
繁體中文
Tiếng Việt
한국어
Followin APP
发掘 Web3 新机会
App Store
Google Play
登录
CaptainZ
1,210个推特粉丝
关注
Prompt Engineer. Focusing on AI, ZKP and Onchain Game. 每周一篇严肃深度长文分析。专注于AI,ZKP,全链游戏,心理学。BS in Physics, MSc in Optics & Finance 可能南方的阳光 照着北方的风 可能时光被吹走 从此无影无踪
动态
CaptainZ
03-19
近期的发展逻辑是:coding agent 引发开发民主化,进而工作效率提升工具大爆发,造成token消耗以几何速度暴增,进而大模型公司赚的盆满钵满,接着数据中心业务大爆发,然后半导体产业(其实就是矿机制造业)继续超高速发展,最后是电力等基础设施受益匪浅,也算是闭环了。 我估计美联储也是看到了同样的情况,所以大幅上调了未来美国gdp增长率
CaptainZ
03-17
sub agent 真是费token啊,几个子代理并行干活,一天时间就把 codex 的plus用量给干完了。 开5个plus账号是 100美金 一个pro是200美金 不知掉哪个划算?
CODEX
0%
CaptainZ
03-12
闭源版龙虾,不管咋说,mac mini 都是要买起来的
Perplexity
@perplexity_ai
03-12
Announcing Personal Computer. Personal Computer is an always on, local merge with Perplexity Computer that works for you 24/7. It's personal, secure, and works across your files, apps, and sessions through a continuously running Mac mini.
龙虾
0.3%
CaptainZ
03-06
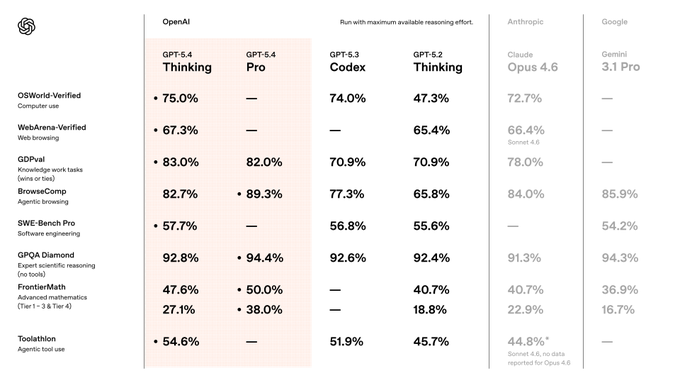
感觉是龙虾原生的大一统LLM模型啊 今天openai发布新模型 GPT-5.4,算是一个“模型能力大一统”成果:OpenAI首次在单一模型中,把推理(Reasoning)、编程(Coding)、计算机原生交互(Computer Use)、深度网页搜索以及百万级Token上下文全部揉碎、重组,焊死在了同一个模型里。 twitter.com/hiCaptainZ/status/...
龙虾
0.3%
CaptainZ
01-13
看来现在的互联网工具都值得再重新做一个针对ai agent 使用的版本 twitter.com/hiCaptainZ/status/...
CaptainZ
12-24
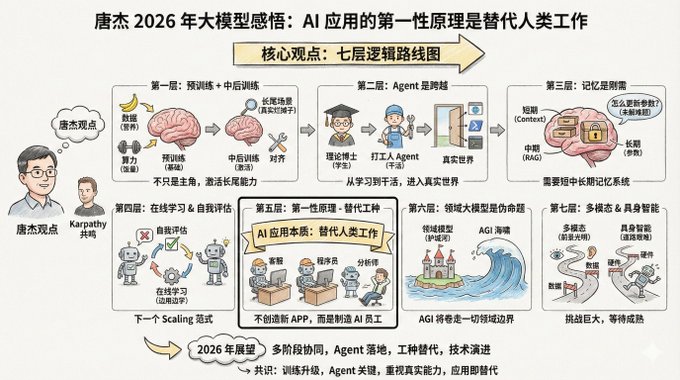
唐杰 @jietang 是清华大学教授、智谱(GLM 系列模型出自他们家)AI 首席科学家,也是国内最懂大模型的人之一。他刚发了长微博(见评论),谈 2025 年对大模型的感悟。 有意思的是,唐杰和 Andrej Karpathy 的观察有不少共鸣,但也有一些不同的侧重点。两个顶级专家的视角放在一起看,能看出更完整的图景。 内容比较长,但有句话我要特别放在前面高亮一下: > AI 模型应用的第一性原理不应该是创造新的 App,它的本质是 AGI 替代人类工作,因此研发替代不同工种的 AI 是应用的关键 如果你是在做 AI 应用开发,应该反复思考一下这句话:AI 应用的第一性原理不是创造新产品,而是替代人类工作。想清楚这一点,很多事情的优先级就清楚了。 唐杰的核心观点有七层逻辑。 --- 第一层:预训练没死,只是不再是唯一主角 预训练仍然是让模型掌握世界知识和基础推理能力的根基。 更多的数据、更大的参数、更饱和的计算,依然是提升模型智商最高效的办法。这就像还在长身体的孩子,饭量(算力)和营养(数据)必须管够,这是物理规律,没法绕弯。 但光有智商不行,现在的模型有个毛病:容易“偏科”。为了刷榜单(Benchmark),很多模型都在针对性地做题,导致在真实复杂的场景下反而不好用。这好比孩子上完九年义务教育(预训练)后,必须把他扔到真实的职场里去实习,去处理那些书本上没有的烂摊子,这才是真本事。 所以接下来的重点是“中后训练”(Mid and Post training)。中后训练这两个阶段负责「激活」模型的能力,尤其是长尾场景的对齐能力。 什么是长尾场景?就是那些不常见但真实存在的需求。比如帮律师整理某类特殊合同、帮医生分析某种罕见病的影像。这些场景在通用测试集里占比很小,但在真实应用中至关重要。 通用 benchmark 一方面评测了模型效果,但也可能让很多模型过拟合。这和 Karpathy 说的「训练在测试集上是一门新艺术」观点一致。大家都在刷榜,但榜单刷了高分不等于能解决真实问题。 --- 第二层:Agent 是从「学生」到「打工人」的跨越 唐杰用了个形象的比喻: > 如果没有 Agent 能力,大模型就是个“理论博士”。一个人书读得再多,读到了博士后,如果不能动手解决问题,那也只是知识的容器,产生不了生产力。 这个比喻精准。预训练是上课,强化学习是刷题,但这些都还在「学习阶段」。Agent 是让模型真正「干活」的关键,是进入真实世界、产生实际价值的门槛。 不同 Agent 环境的泛化和迁移并不容易。你在一个代码环境里训出来的能力,换到浏览器环境就不一定好使。现在最简单的办法,还是不断堆更多环境的数据,针对不同环境做强化学习。 以前我们做 Agent,是给模型外挂各种工具。现在的趋势是,直接把使用工具的数据写进模型的“DNA”里去训练。 这听起来有点笨,但确实是当下最有效的路径。 Karpathy 也把 Agent 列为今年最重要的变化之一,他以 Claude Code 为例,强调 Agent 要能「住在你电脑里」,调用工具、循环执行、解决复杂问题。 --- 第三层:记忆是刚需,但怎么做还没想清楚 唐杰花了不少篇幅讲记忆。他认为,模型要在真实环境中落地,记忆能力是必须的。 他把人类记忆分成四层: - 短期记忆,对应前额叶 - 中期记忆,对应海马体 - 长期记忆,分布在大脑皮层 - 人类历史记忆,对应维基百科和史书 AI 也要模仿这个机制,大模型对应的可能是: - Context 窗口 → 短期记忆 - RAG 检索 → 中期记忆 - 模型参数 → 长期记忆 一个思路是「压缩记忆」,把重要信息精简后存在 context 里。目前的“超长上下文”只是解决了短期记忆,相当于把它能用的“便签纸”变长了。如果未来 context 窗口足够长,短中长期记忆都有可能实现。 但有个更难的问题:怎么更新模型自身的知识?怎么改参数?这还是个未解难题。 --- 第四层:在线学习和自我评估,可能是下一个 Scaling 范式 这一段是唐杰观点里最前瞻的部分。 现在的模型是“离线”的,训练好就不变了。这有几个问题:模型不能真正自我迭代,重新训练浪费资源,还会丢掉很多交互数据。 理想情况是什么?模型能在线学习,边用边学,越用越聪明。 但要实现这一点,有个前置条件:模型要知道自己对不对。这就是「自我评估」。如果模型能判断自己的输出质量,哪怕是概率性地判断,它就知道了优化目标,就能自我改进。 唐杰认为,构建模型的自我评价机制是个难题,但也可能是下一个 scaling 范式的方向。他用了几个词:continual learning、real time learning、online learning。 这和 Karpathy 提到的 RLVR 有一定呼应。RLVR 之所以有效,正是因为有「可验证的奖励」,模型能知道自己对不对。如果这个机制能泛化到更多场景,在线学习就有可能实现。 --- 第五层:AI 应用的第一性原理是「替代工种」 这是对我启发最大的一句话: > AI 模型应用的第一性原理不应该是创造新的 App,它的本质是 AGI 替代人类工作,因此研发替代不同工种的 AI 是应用的关键 AI 的本质不是创造新的 App,而是替代人类工作。 两条路: 1. 把以前需要人参与的软件 AI 化。 2. 创造对齐人类某个工种的 AI 软件,直接替代人类工作。 Chat 已经部分替代了搜索,同时还融合了情感交互,下一步就是替代客服、替代初级程序员、替代数据分析师。 所以,明年 2026 年的爆发点在于“AI 替代不同工种”。 创业者要思考的不是“我要开发个什么软件给用户用”,而是“我要造一个什么样的 AI 员工,去帮老板把某个岗位的人力成本砍掉”。 换句话说,别老想着做一个「AI+X」的新产品,先想想哪些人类工作可以被替代,再倒推产品形态。 这和 Karpathy 关于「Cursor for X」的观察遥相呼应。Cursor 本质上是「程序员这个工种的 AI 化」,那么各行各业都会出现类似的东西。 --- 第六层:领域大模型是个「伪命题」 这个观点可能会让一些人不舒服,但唐杰说得很直接:领域大模型就是个伪命题。都 AGI 了,哪有什么“领域专用(domain-specific)AGI”? 之所以有领域大模型存在,是因为应用企业不愿意在 AI 模型公司面前认输,希望用领域 know-how 构建护城河,把 AI 驯化为工具。 但 AI 的本质是「海啸」,走到哪里都会把一切卷进去。一定会有领域公司主动走出护城河,被卷进 AGI 的世界。领域的数据、流程、Agent 数据,慢慢都会进入主模型。 当然 AGI 还没实现之前,领域模型会长时间存在。但这个时间窗口有多长?不好说,AI 发展实在太快了。 --- 第七层:多模态和具身智能,前景光明但道路艰难 多模态肯定是未来。但当下的问题是:它对提升 AGI 的智能上限帮助有限。 文本、多模态、多模态生成,可能还是分开发展更高效。当然,探索三者结合需要勇气和钱。 具身智能(机器人)更难。难点和 Agent 一样:通用性。你教会机器人在 A 场景干活,换个场景又不行了。怎么办?采数据、合成数据,都不容易,还贵。 怎么办?采数据,或者合成数据。都不容易,都贵。但反过来,一旦数据规模上去了,通用能力出来了,自然就形成门槛。 还有个问题往往被忽略:机器人本身也是个问题。不稳定、故障频繁,这些硬件问题也在限制具身智能的发展。 唐杰预判 2026 年这些都将取得长足进步。 --- 把唐杰这篇文章串起来,其实是一张相当清晰的路线图: 当下,预训练 scaling 依然有效,但要更重视对齐和长尾能力。 近期,Agent 是关键突破口,让模型从"会说"进化到"会做"。 中期,记忆系统和在线学习是必修课,模型要学会自我评估和迭代。 长期,工种替代是应用的本质,领域护城河会被 AGI 冲垮。 远景,多模态和具身各自发展,等待技术和数据的成熟。 --- 把唐杰和 Karpathy 的观点放在一起看,能看出几个共识: 第一,2025 年的核心变化是训练范式的升级,从「预训练为主」变成「多阶段协同」。 第二,Agent 是里程碑,是模型从学习走向干活的关键跨越。 第三,benchmark 刷分和真实能力之间有鸿沟,这个问题越来越被重视。 第四,AI 应用的本质是替代或增强人类工种,不是为了做 App 而做 App。 不同的侧重点也有意思。Karpathy 更关注「AI 是什么形状的智能」这个哲学问题,唐杰更关注「怎么让模型在真实场景落地」的工程问题。一个偏「理解」,一个偏「实现」。 两个视角都需要。理解清楚了,才知道方向对不对;工程跟上了,才能把想法变成现实。 2026 年,会很精彩。 twitter.com/dotey/status/20035...
GLM
2.01%
CaptainZ
12-23
期待 GLM-4.7 在 Claude code里面使用的测评
GLM
2.01%
CaptainZ
12-23
玩 vibe coding 半年了,差不多也是同样的体悟,从 agent coding 变成 上下文管理,最后变成了 文档管理
郭宇 guoyu.eth
@turingou
12-22
今天回东京后继续研究 agentic coding,由于本地项目是从 0 搭建的,需求和文档随着和 codex 和 cc 的沟通越来越明确,文档的复杂程度也逐渐加深。 这让我越来越觉得 agentic coding 本质上是文档管理的艺术,从 vibe coding 发展了一年后,自然语言编程似乎慢慢将软件工程转换为了文档工程。
CaptainZ
12-19
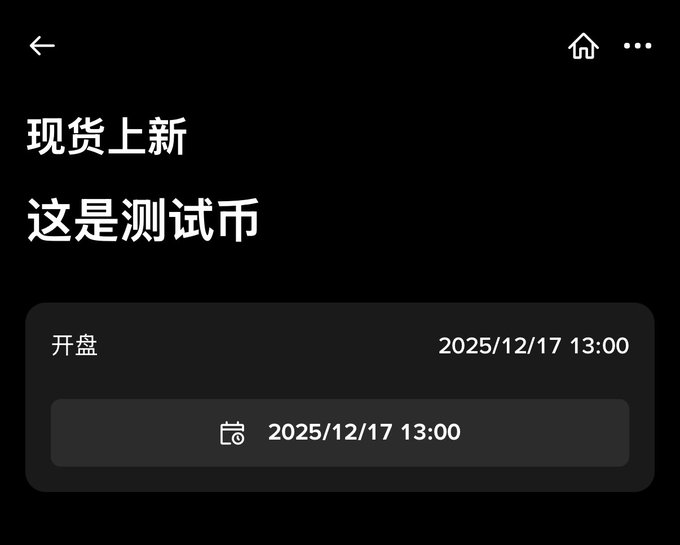
前天这个测试很显然就是为了留给“币安人生”上现货用的,挺确定性的事情,就看啥时候了,最快也许是明天周六? twitter.com/hiCaptainZ/status/...
Loading..