當初英特爾和微軟,搞出來個Wintel,制霸電腦時代很多年。
從某種意義上,英偉達的CUDA,就相當於CPU時代的windows,承擔了構建應用生態的重任。而生態的壁壘,是比芯片性能更深厚的競爭壁壘。所以,CUDA才是英偉達最大的王牌。
在CPU時代,我們被Wintel壓制了很多年。在AI時代,英偉達集GPU和CUDA於一身,會是另一個難以打破的Wintel麼?目前看是的。
由於美國對中國AI產業的打壓,芯片這張牌被用的越來越頻繁。不僅美國政府,就是英偉達自身處於商業競爭的考慮,也越來越傾向於“打牌”。而CUDA,就是英偉達最大的王牌。中國要在AI計算領域突破封鎖,不僅要有自己的GPU,也要有自己的CUDA。要做成這件事情,目前來看,似乎只有靠華為了。
CUDA才是英偉達最深的護城河
在圖形渲染的世界中,英偉達以其精湛的GPU技術贏得了市場的青睞。然而,英偉達並未止步於此,它的目光早已超越了圖形渲染的邊界,投向了更為廣闊的計算領域。2006年,英偉達推出了CUDA(Compute Unified Device Architecture),這一舉措標誌著英偉達從圖形渲染巨頭向計算巨頭的華麗轉身。

CUDA的發展歷程中,有幾個關鍵節點:
2007年:CUDA 1.0的發佈,開放了GPU的通用計算能力,為開發者提供了進入GPU編程世界的鑰匙。
2008年:CUDA 2.0增加了對雙精度浮點運算的支持,這對於科學計算和工程模擬等領域至關重要。
2010年:CUDA 3.0進一步擴展了GPU的並行處理能力,為更復雜的計算任務提供了支持。
2012年:CUDA 5.0引入了動態並行性,允許GPU內核自我複製,極大地提升了程序的靈活性和效率。
這些版本不僅推動了CUDA技術的進步,也成為了GPU並行計算發展史上的重要里程碑。

CUDA的核心在於其創新的並行計算模型,通過將計算任務分解為成千上萬的線程,CUDA能夠在GPU上實現前所未有的並行處理能力。這種模型不僅極大地提高了計算效率,也使得GPU成為了解決複雜計算問題的理想平臺。從深度學習到科學模擬,CUDA定義了並行計算的新紀元,開啟了高性能計算的新篇章。
隨著AI和大數據的興起,CUDA的市場影響力不斷擴大。開發者們紛紛轉向CUDA,以利用GPU的強大計算能力來加速他們的應用程序。企業也認識到了CUDA的價值,將其作為提升產品性能和競爭力的關鍵技術。根據統計數據,CUDA的下載量已經超過了3300萬次。
對於英偉達而言,CUDA已經成為英偉達最深的護城河。它不僅鞏固了英偉達在GPU市場的領導地位,更為英偉達打開了進入高性能計算、深度學習、自動駕駛等多個前沿領域的大門。隨著技術的不斷進步和市場的不斷擴大,CUDA無疑將繼續扮演著英偉達最深護城河的角色,引領著計算技術的未來。
比CUDA晚了12年的達芬奇架構,能撐得起華為的AI野心麼?
達芬奇架構,作為華為自研的AI計算架構,其起源與華為對AI未來應用的深遠洞察密切相關。早在幾年前,華為就預測到2025年,全球智能終端的數量將達到400億臺,智能助理的普及率將達到90%,企業數據的使用率將達到86%。基於這樣的預測,華為在2018年全聯接大會上提出全棧全場景AI戰略,並設計了達芬奇計算架構,以在不同體積和功耗條件下提供強勁的AI算力。
達芬奇架構的發展可以追溯到2018年,華為推出的AI芯片Ascend 310(昇騰310)首次亮相,標誌著達芬奇架構的正式應用。緊接著,華為在2019年6月發佈了全新8系列手機SoC芯片麒麟810,首次採用達芬奇架構NPU,實現了業界領先的端側AI算力。麒麟810在AI Benchmark榜單中表現卓越,證明了達芬奇架構的實力。
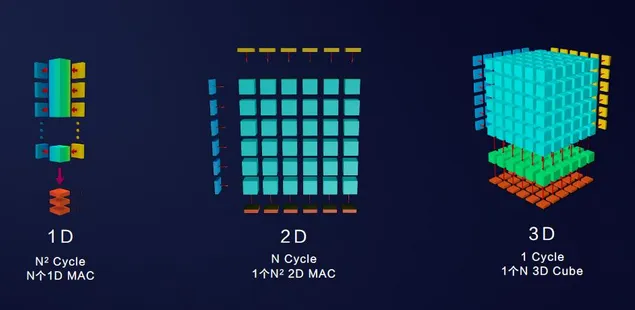
達芬奇架構是專為AI計算特徵而設計的全新計算架構,具備高算力、高能效、靈活可裁剪的特性。其核心優勢在於採用3D Cube針對矩陣運算做加速,每個AI Core可以在一個時鐘週期內實現4096個MAC操作,相比傳統的CPU和GPU實現數量級的提升。此外,達芬奇架構還集成了向量、標量、硬件加速器等多種計算單元,並支持多種精度計算,支撐訓練和推理兩種場景的數據精度要求。
達芬奇架構的應用領域廣泛,覆蓋了從端側到雲端的全場景AI應用。在端側,麒麟810芯片的AI算力已經在智能手機中得到應用,為消費者提供了豐富的AI應用體驗。在邊緣側和雲端,Ascend系列AI處理器可以滿足從幾十毫瓦到幾百瓦的訓練場景,提供最優的AI算力。達芬奇架構的靈活性和高效性,使其在智慧城市、自動駕駛、工業製造等多個領域中發揮著重要作用。
誠然,達芬奇架構在華為的AI市場佈局中佔據了核心的位置。它不僅是華為AI芯片的技術基礎,也是華為實現全棧全場景AI戰略的重要支撐。通過達芬奇架構,華為能夠提供從硬件到軟件的全棧AI解決方案,加速AI技術的產業化和應用落地。此外,達芬奇架構的統一性也為開發者帶來了便利,降低了開發和遷移成本,促進了AI應用的創新和發展。
達芬奇VS CUDA,有幾分勝算?
相比於2006年推出的CUDA,華為達芬奇要晚了12個年頭。這12年中,達芬奇一直在追趕。除了時間上的差距,達芬奇和CUDA還在架構設計哲學、性能表現、工具鏈、開發者生態等多個層面存在顯著的差異。
在設計哲學方面,CUDA是英偉達開發的並行計算平臺和API模型,它允許開發者使用NVIDIA的GPU進行高效的並行計算。而達芬奇架構是華為自研的面向AI計算特徵的全新計算架構,它採用了3D Cube針對矩陣運算做加速,大幅提升單位功耗下的AI算力。CUDA的設計更注重通用性,而達芬奇則專注於AI計算的高效性。
在AI計算性能方面,CUDA和達芬奇各有千秋。CUDA憑藉多年的技術積累,支持大規模並行處理能力,適合處理各種複雜的計算任務。達芬奇架構則通過其3D Cube計算引擎,針對矩陣運算進行優化,實現了在單位面積下的AI算力顯著提升。在深度學習等AI應用場景中,達芬奇架構展現出了優秀的性能表現。
CUDA和達芬奇架構在不同領域下的適用性各有側重,CUDA由於其通用性,被廣泛應用於科學研究、醫學、金融等多個領域。而達芬奇架構則主要針對AI計算,特別是在端側、邊緣側及雲端的AI應用場景中,如智能手機、自動駕駛、雲業務等。
從開發者的角度來看,CUDA和達芬奇架構在編程模型與工具鏈的易用性上有所不同。CUDA提供了一套完整的開發工具鏈,包括CUDA編譯器、調試器、性能分析工具等,支持多種編程語言和深度學習框架。達芬奇架構雖然起步較晚,但華為也在積極構建其工具鏈和開發者生態,提供必要的支持以促進開發者的使用和創新。但從工具鏈的完整性和豐富度來看,達芬奇離CUDA還有不少的差距。
CUDA通過其廣泛的應用和成熟的技術,已經建立了一個龐大的開發者社區和生態系統。而生態的建設,是比單純提升GPU性能更難得事情,這才是對華為真正的考驗。
華為GPU快成了,但離構建自己的CUDA還很遙遠
目前看,華為GPU發展態勢較好。
根據公開信息,2023年華為算力GPU的出貨量大約為十萬片。隨著產能的增加,預計到2024年,這個數字將翻幾番,達到幾十萬片的規模。儘管產能有所提升,市場上的訂單需求依然非常旺盛,僅在2024年1月份的下單量就已經達到了數十萬片。目前,下單需求已經達到上百萬片,遠超華為當前的供應能力。
在國內購買情況方面,華為算力GPU受到了市場的熱烈追捧。華為算力GPU的客戶主要分為三個梯隊:第一類是三大運營商和政務類客戶,第二類是互聯網客戶,第三類是其他公司。由於算力GPU的緊缺,客戶為了儘快拿到產品,都在努力成為第一梯隊的客戶,甚至採取與地方政府合作等措施以確保優先供應。
價格方面,華為算力GPU自2023年8月上市以來,價格已經經歷了至少兩次提價。最初上市的價格約為7萬元人民幣,而目前市場價格已經上漲至約12萬元人民幣。
總體來看,華為GPU的發展態勢良好,市場需求強勁,儘管供應緊張,但這也反映出華為GPU在性能和國產化方面的優勢,使其成為市場中的熱門選擇。隨著技術的不斷進步和產能的進一步提升,預計華為GPU將在未來市場中佔據更重要的位置。
在一次專訪中,黃仁勳表示:“華為是個好公司”。此外,英偉達在財報中將華為列為主要競爭對手,這反映了華為在GPU及相關技術領域的競爭力正在增強。
儘管華為GPU發展態勢良好,但CUDA作為GPU領域占主導地位的框架,其生態系統的成熟度和廣泛接受度遠遠超過了其他框架,包括AMD開發的框架。華為的AI計算框架在生態建設方面確實還有很長的路要走,需要持續的技術創新和市場推廣才能逐步構建起與CUDA相匹敵的生態系統。
然而,英偉達不想給華為成長起來的時間了。
近期,英偉達對其CUDA平臺的兼容性政策進行了調整,限制了CUDA軟件在非英偉達硬件平臺上的運行行為,這一決策始於2021年,並在隨後的時間裡逐步加強。具體來說,英偉達通過更新其最終用戶許可協議(EULA),明確禁止了使用轉換層或模擬層在非英偉達GPU上運行CUDA代碼的行為。
這一政策變動主要影響了那些試圖通過轉譯技術實現CUDA兼容性的第三方項目,例如ZLUDA等。ZLUDA是一個允許在非英偉達硬件上運行CUDA程序的轉譯庫,它提供了一種相對簡單的方式,使得開發者能夠在性能略有損失的情況下,運行CUDA程序。
英偉達此舉,被廣泛認為是保護其市場份額和維護其技術控制權的戰略舉措。通過限制在其他芯片上使用CUDA軟件的方式,英偉達確保其GPU仍然是開發人員和依賴其並行計算平臺的企業的首選。
然而,這一決策在業界引起了不小的震動,並引發了廣泛的討論。不少人指責英偉達藉助封鎖政策壟斷市場,壓制競爭對手的發展機會。
面對英偉達的限制政策,一些國內GPU企業如摩爾線程選擇了遵守EULA規定,並表態採用重新編譯代碼的方式與EULA保持一致,以避免違反英偉達的限制條款。
此外,業界其他力量,包括AMD、英特爾等廠商,並未因英偉達的限制而止步,他們正在積極推動開放、可移植的生態系統建設,以試圖打破英偉達的市場壟斷。
面對英偉達的出牌,華為在發展自己的GPU技術時,需要更多地依賴自主研發的軟件工具和開發環境,而不是依賴於CUDA這樣的成熟平臺。這意味著華為需要投入更多的資源來構建自己的軟件生態系統,包括開發與CUDA性能相匹敵的編程工具、庫和API。
可以預見,在未來較長一段時間內,由於CUDA的廣泛使用和對高性能計算、AI等領域的深遠影響,英偉達的這一政策可能會限制華為GPU的市場接受度,特別是在那些已經深度依賴於CUDA的領域。
這加強了華為構建自身AI計算架構和AI生態的緊迫性,就像當初安卓斷供成就了鴻蒙一樣,CUDA的收緊會否成為華為達芬奇架構的神助攻呢?現在還不好評判,讓子彈飛一會吧。