作者:Iris Chen, Dr. Ni

一、AI+3D管線降本增效顯著
2022年ChatGPT爆火引發AIGC浪潮,生成式AI對很多行業都產生了顛覆性作用,遊戲、影視、3D打印等場景下的3D內容領域也正在生成式AI的作用下重塑行業格局。相比於追求準確性的工業場景CAD、建築場景BIM,這些場景下的3D內容更追求創作性,生成式AI可以有更大的用武之地。
3D生成技術指利用深度神經網絡學習並生成物體或場景的3D模型,並在3D模型的基礎上將色彩與光影賦予物體或場景使生成結果更加逼真,包括AI建模、AI骨骼綁定、AI表情、AI動作、AI渲染等研究方向。3D內容產業鏈包括提供技術的基礎層、提供資產的中間層和資產開發的應用層,其中基礎層的技術提供方為產業提供生產3D內容的基礎工具,3D生成技術主要在該層替代傳統生產工具以促進行業發展。

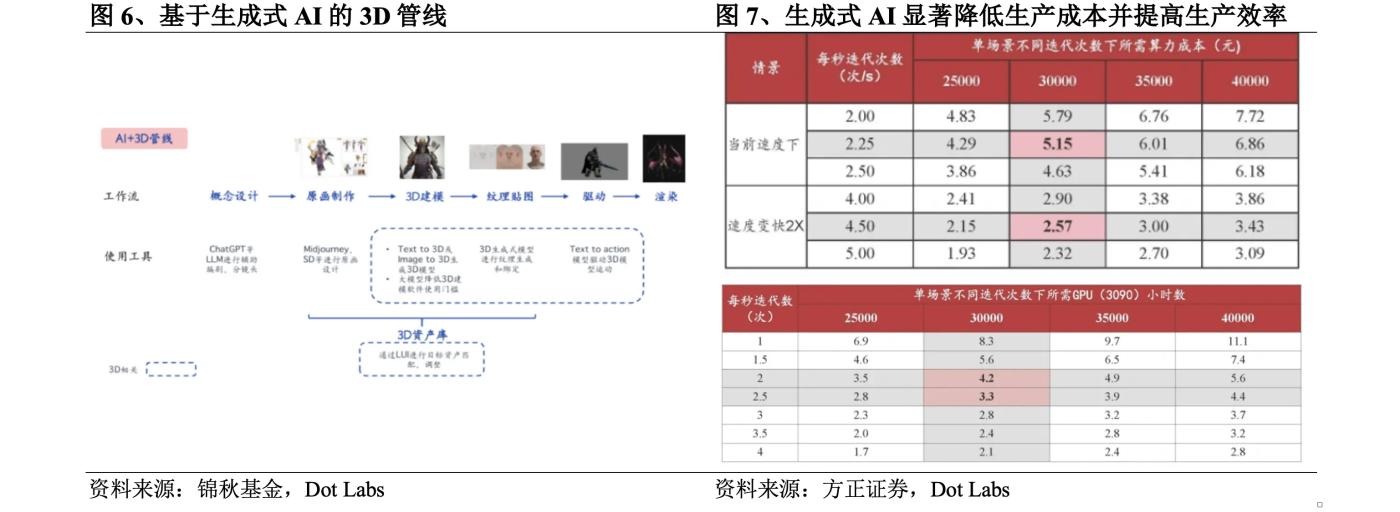
傳統3D管線包括概念設計、原畫製作、3D建模、紋理貼圖、驅動和渲染等環節,其中原畫製作、3D建模、紋理貼圖等3D相關環節制作週期長、高度依賴人工,是主要研發成本所在。以3D遊戲為例,3D遊戲中3D相關環節通常會佔研發成本的60-70%,其中3D建模環節成本極高,一個十萬面以上的3D高模資源,廠商如果委託外包團隊生產,價格至少需要3萬元,時間需要30-45天,如果在3D資產庫購買,除了存在可選資產有限的問題,通常也需要5-10人/天進行清洗才可以使用。據全球最大3D內容公司Sketchfab的數據,3D模型生產大概費用在3-40美元左右,所需時間在2-15小時左右。

生成式AI幾乎可以在傳統3D管線的所有環節中發揮作用,很多遊戲工作室目前已是美術成員人手一個Midjourney和Stable Diffusion,大模型的應用也降低了3D建模的門檻,基於生成式AI的3D管線可降低3D內容的生產成本、提高生產效率。以2024年初大賣的Steam遊戲《幻獸帕魯》為例,一個建模師製作一個帕魯(遊戲中的生物)的3D模型需要一個月,每個帕魯需要約20個動作,以每天一個動作計算則還需要額外20天,該遊戲約有100種帕魯,按照傳統3D管線的生產方式總共需要5000天左右,而工作室利用生成式AI,在3年內完成該作品。
據方正證券的測算,使用RTX 3090顯卡在Zero123方法迭代30000次,生成一個3D資產的成本約5元,未來隨著方法的發展成熟,迭代速度變快2倍的情況下成本將降至2.6元,且單場景只需要約3.3-4.2小時,相較於前文的3-40美元和2-15小時,生成式AI的應用顯著降低了生產成本並提高了生產效率。
二、3D生成技術發展
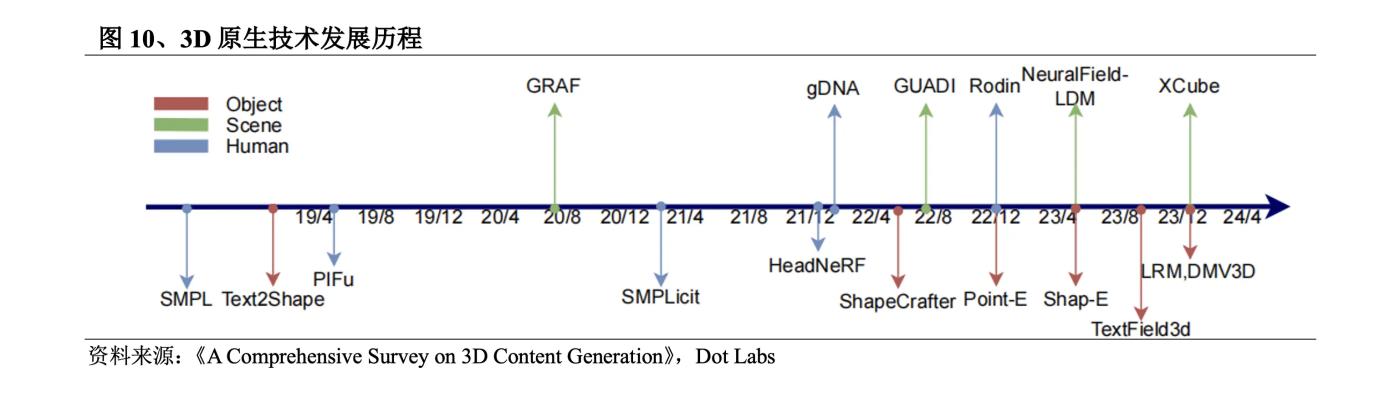
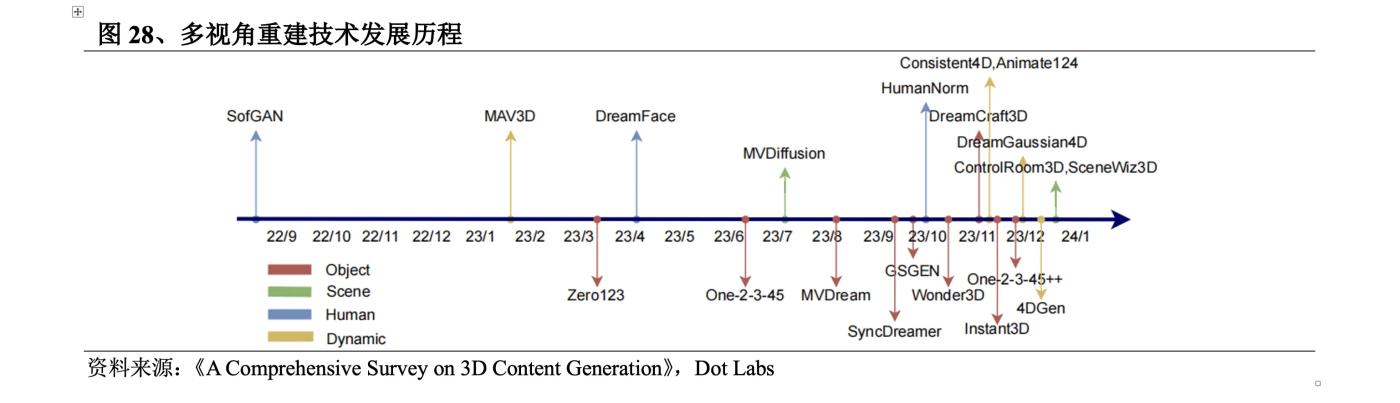
3D生成技術的研究最開始是在計算機視覺和圖形學領域展開,早在1970年MIT教授Berthold K.P. Horn就提出了Shape from shading,基於圖像中的明暗信息,藉助反射光照模型恢復出3D模型。2023年,3D生成技術出現井噴式發展,生成質量、速度和豐富性都得到大幅提升,契機在於:①3D數據集從早期小規模的ShapeNet到Objaverse(2022年12月)、Objaverse XL(2023年7月),其中0bjaverse-XL數據集包含1020萬3D資產,比Objaverse多了一個數量級;②將3D內容表達為神經網絡參數的神經場誕生;③2D預訓練模型的發展推動多視角重建。
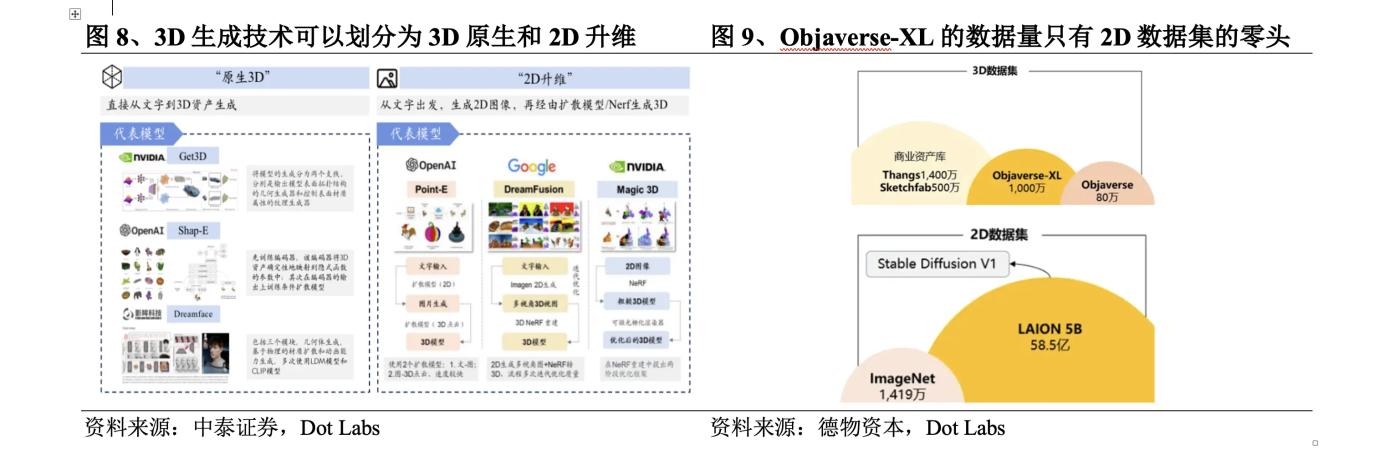
3D生成技術可以劃分為3D原生和2D升維兩大類發展路線。3D原生通常使用3D數據集進行訓練,從訓練到推理都基於3D數據,從文字/圖像直接生成3D內容,而可學習的3D數據集十分有限,即使是最大的開源3D數據集Objaverse-XL的數據量也只有2D數據集的一個零頭。為解決這一問題,部分研究嘗試使用2D數據集進行訓練,從文字先到2D圖像,再通過擴散模型或者NeRF模型生成3D內容,此為2D升維。
1、 3D原生路線
3D原生路線使用3D數據集進行訓練,實現從文字/圖片輸入直接到3D內容的生成。主要優劣勢在於:
l 優勢
生成質量高:由於使用的是3D數據集,在特定範圍內針對性強,能夠生成質量較高的3D內容,比如通過高質量的3D人臉數據可以訓練出4k以上高質量的3D人臉,同時避免了2D升維的多面問題。
生成速度快:2D升維通常利用擴散模型或者NeRF模型來指導3D表示的優化,需要多步迭代導致耗時長,而3D原生可直接由文字/圖片進行3D生成。
兼容性強:通常有幾何和紋理的分別生成,可以直接在標準圖形引擎中進行後續編輯。
l 劣勢
豐富性不足:缺乏高質量、大規模的3D數據集,且數據質量和一致性較差,制約了模型想象力,難以生成數據集中沒有見過的物品或組合。
3D原生早期使用的方法有VAE模型、流模型、GAN模型、EBM模型等,其中GAN模型在生成效果方面的優勢使其在2022年前一直是3D原生的主流模型,但由於GAN存在訓練病態問題,很難在不存在規範座標系的數據上進行訓練,訓練難度極大且對硬件要求極高。2022年9月,Nvidia發佈Get3D,可以生成具有高保真紋理和複雜幾何細節的3D內容。之後,OpenAI發佈Point-E和Shap-E,打破3D數據和字幕的數量限制,收集了數百萬個3D資源和相應文本字幕,支持大詞彙量的3D生成。近期大火的LRM通過結合高效的神經網絡架構和大規模的多視角數據集,實現了從單張圖像到高保真3D模型的快速轉換,DMV3D提出T步驟擴散模型對LRM進行改進實現了更高質量的結果生成。
2022年9月,Nvidia發佈Get3D。Get3D的生成過程分為兩個部分:①幾何分支部分,可以輸出任意拓撲結構的表面網格;②紋理分支部分,產生紋理場以實現在表面點上進行查詢。

該方法的具體突破在於:
l 在該方法出現之前,3D生成技術生成的內容缺乏幾何細節和紋理。而在Get3D的生成過程下,其3D內容的幾何細節更加豐富,且可以帶紋理。
l 當時最先進的反向渲染方法也只能一次構建一個3D物體。而在單個Nvidia的GPU上訓練,Get3D每秒可以生成大約20個對象,且所學習的訓練數據集越大、越多樣化,輸出的多樣性和詳細程度就越高,Nvidia研究團隊稱,僅用2天時間就使用A100 GPU在大約100萬張圖像上訓練了模型。
l 可以根據受訓練時使用的數據生成幾乎無限量的3D內容。例如,學習2D汽車圖像的數據集,Get3D可以創建轎車、卡車、賽車和麵包車等系列集。

2023年5月,OpenAI發佈Shap-E,在其Point-E的基礎上進行提升。Shap-E流程為:①訓練一個編碼器生成隱式表徵;②在編碼器產生的潛表徵上訓練擴散模型。
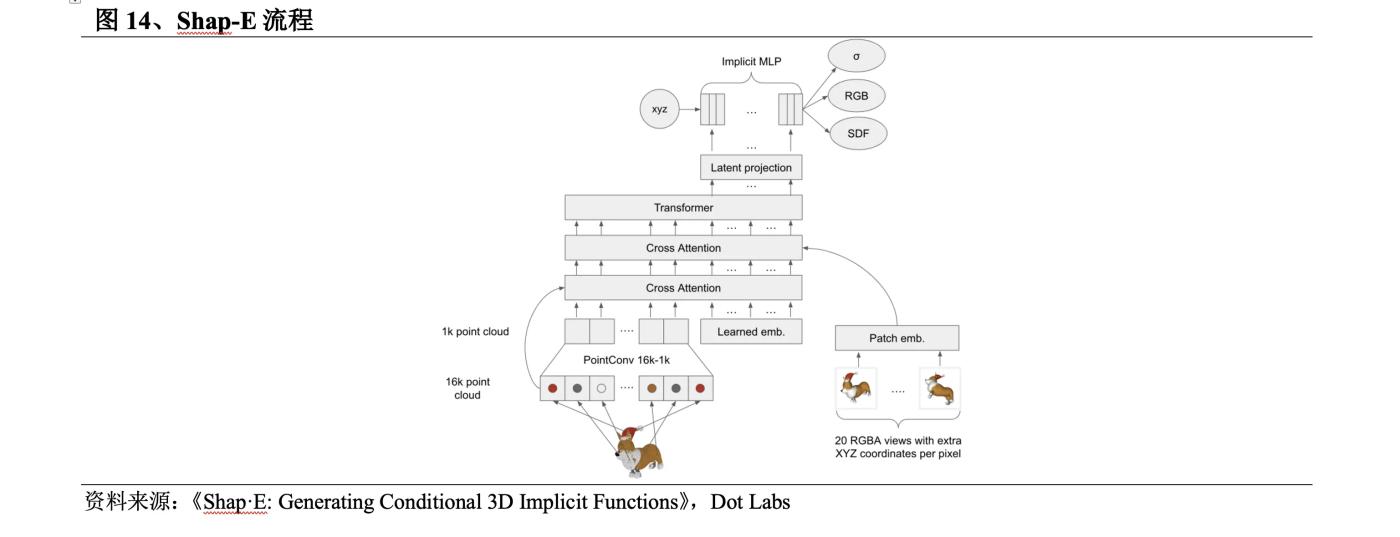
l Shap-E使用隱式表示法生成既有神經場又有紋理網格的3D模型,可以輕鬆導入到3D軟件中進行後續處理。相比其他方法,Get3D只能生成網格,Point-E只能生成點雲。
l 在使用大型3D和文本對應數據集進行訓練後,Shap-E可以在幾秒鐘內生成複雜且多樣化的3D模型,在推理速度上比Point-E快,且比其他方法快幾個數量級。
但是和Point-E存在的問題一樣,Shap-E的樣本質量較差,編碼器有時會丟失詳細的紋理。

2023年11月,Adobe研究院和澳大利亞國立大學的研究團隊介紹了一種創新的大型重建模型LRM。該方法流程為:①應用預先訓練過的視覺模型DINO對輸入的圖像進行編碼;②圖像特徵由大型Transformer解碼器通過交叉注意力投影到3D三平面空間,使用NeRF模型進行表示;③使用多層感知器MLP預測體積渲染的點顏色和密度。
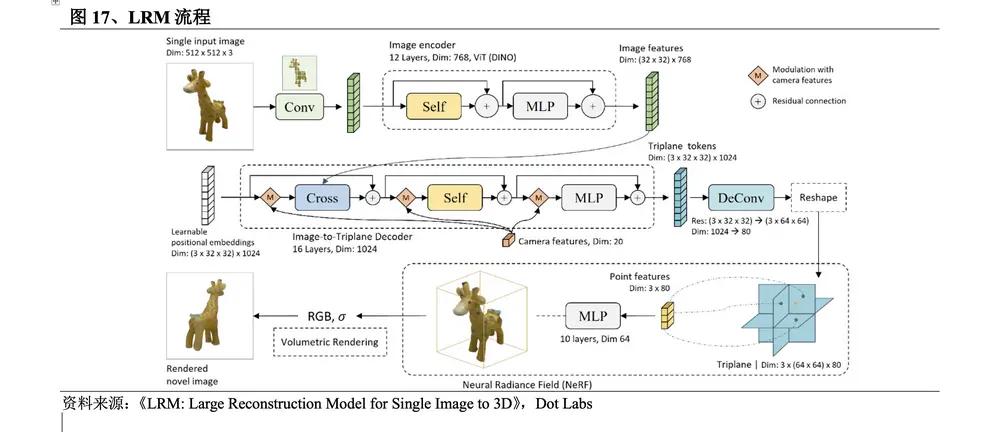
l 耗時短。2D升維主要利用擴散模型通過優化算法優化3D表示,推理即訓練,耗時很長,其他3D原生方法是在3D表示上訓練擴散模型,推理需要迭代多步,耗時較長。而LRM是訓練迴歸模型,直接一步推理出3D表示,可在短短5秒內從單張輸入圖像中生成高保真度的3D物體模型。
l 強通用性。與過去在小數據集上以特定類別進行訓練的方法不同,LRM採用了高度可擴展的基於transformer的架構,具有5億個可學習參數,並使用Objaverse和MVImgNet數據集中約100萬個3D對象進行端到端訓練,具有很強的通用性。
l 處理真實場景圖片。LRM使用戶可以從智能手機拍攝的照片中生成高質量的3D模型,擴展了3D建模的民主化,打開了無限創意和商業可能。
LRM是第一個大型重建模型,其突破性在於其快速、高效地生成高質量的3D圖像,為增強現實、虛擬現實系統、遊戲、影視動畫和工業設計等領域帶來了轉變。其在生成速度和質量上的顯著優勢掀起了3D生成技術領域的重建模型潮,很多工作在LRM的基礎上進行改進,重建模型大量湧現。
2D升維路線使用2D數據集進行訓練,先從文字到2D圖像,再通過擴散模型或者NeRF模型生成3D內容。主要優劣勢在於:
l 優勢
豐富性強:可以利用大量的2D圖像數據進行預訓練,生成的3D模型複雜度提高,富有想象力。
l 劣勢
生成質量低:受限於採樣數量、視角數量及計算資源的平衡,目前2D升維方法在分辨率、紋理細節上都較粗糙,且擴散模型的3D先驗能力不足,生成結果易出現幾何結構不合理問題。
生成速度慢:NeRF的訓練和推理過程都需要大量計算資源,需要對3D空間進行密集的採樣,耗費時間。
兼容性弱:NeRF格式無法直接在Unity等3D引擎中進行後續編輯,需要通過Matching cubes等轉換成3D網格再到3D引擎中進行編輯,兼容性較弱。
2018年,將3D內容表達為神經網絡參數的神經場誕生,雖然神經場表達的仍然是3D數據,且由於缺乏學習數據在2018-2020年期間發展緩慢,但為2D升維奠定了技術基礎。2020年,伯克利、谷歌與加大聖地亞哥分校的聯合團隊提出NeRF算法,生成的圖像精度高且可以生成大場景的3D感知圖像,大大加速了2D升維的發展,但由於訓練難度大、對硬件要求高、生成效率低等問題,僅能進行試驗性與娛樂性的小範圍應用。2022年,以Stable Diffusion、Dall·E為代表的2D圖像生成應用快速發展,提升了2D升維的商業化價值,技術發展再次提速。具體技術的發展上,2D升維的最初探索是Google2021年末發佈的DreamFields,其於2022年9月發佈在此基礎上改進的DreamFusion,利用Imagen擴散模型計算損失和SDS方法進行採樣,顯著提高了文本到3D的質量。之後,Nvidia發佈Magic3D,引入兩階段的優化策略提高生成速度和質量。ProlificDreamer採用VSD解決SDS方法過飽和、過平滑和低多樣性的問題。DreamGaussian將3D高斯整合到3D內容的創建中,此後3D高斯在很大程度上替代了NeRF,近半年出現大量基於3D高斯的系列改進工作。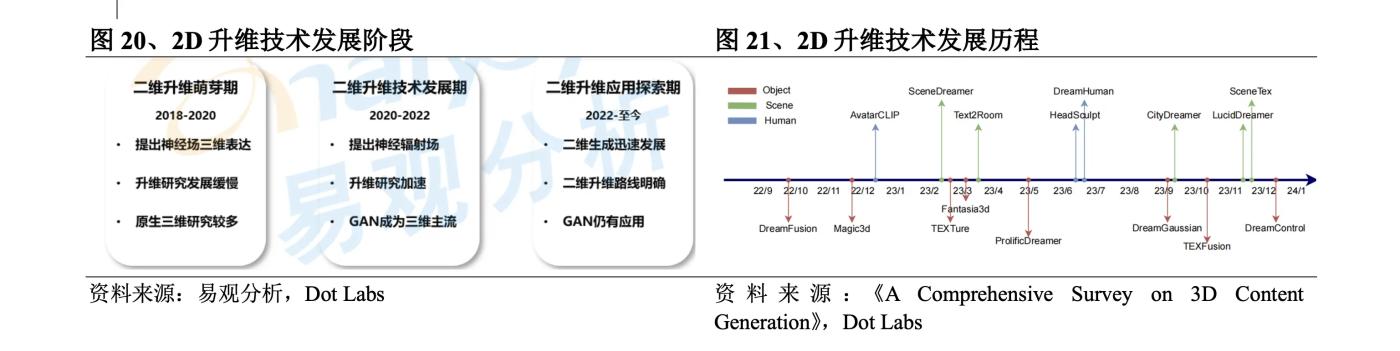
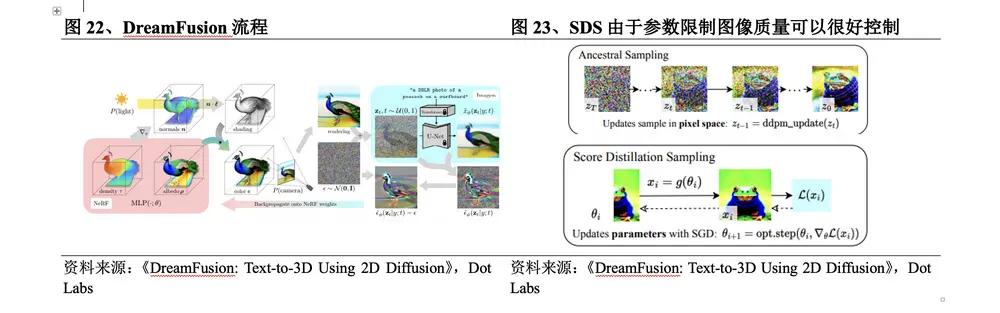
2022年9月,Google發佈DreamFusion,在其DreamFields的基礎上進行提升。DreamFusion流程為:①用NeRF在預定的機位渲染圖片,和高斯分佈混合得到加噪圖片;②將圖片輸入Imagen擴散模型,採用類似於NeRF的隨機權重初始化模型;③反覆渲染的視圖作為環繞Imagen的SDS函數的輸入。該方法的具體突破在於:
l 通過文本到圖像的Imagen擴散模型來計算損失以替代CLIP,相當於一個由擴散模型優化之後的NeRF,對3D模型進行了優化。
l 使用新的圖像採樣方法SDS,在參數空間而不是像素空間中進行採樣,由於參數限制生成的圖像質量走向可以很好控制。
l 在生成圖像的過程中,參數會經過優化成為擴散模型的一個訓練樣本,經過擴散模型訓練之後的參數具備多尺度特性,更利於後續的圖像生成,且擴散模型能夠直接預測更新的方向則不需要反向傳播。
雖然DreamFusion提升了3D模型的結構準確性與渲染的真實性,但其生成3D內容要進行1.5萬次的優化,每個模型生成要1.5小時,耗時太長,在規模、渲染與結構細節方面難以滿足產業級應用的要求。
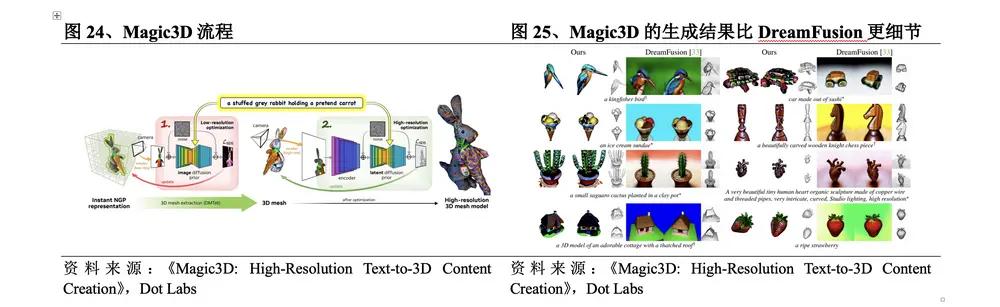
2022年11月,Nvidia發佈Magic3D,在DreamFusion的基礎上進行兩階段優化。Magic3D流程為:①低分辨率優化。通過重複採樣和渲染低分辨率圖像計算SDS損失,採用其3D重建模型Instant NGP給出結果,使用DMTet提取初始3D mesh作為第二階段的輸入;②高分辨率優化。用同樣方法對高分辨率圖像進行採樣和渲染,並使用相同方法進行更新得到最終結果。與DreamFusion相比,該方法的具體突破在於:
l 生成質量更高。Magic3D的分辨率比DreamFusion高8倍,具體效果上Magic3D的生成結果也更加細節。
l 生成速度更快。Magic3D可以在40分鐘內創建高質量的3D網格模型,比DreamFusion快2倍。
l 銜接更好。由於Magic3D的渲染方式與傳統計算機圖形學有非常緊密的關係,且其生成結果可以直接在標準的圖像軟件中進行查看,因此可以更好地與傳統3D生成工作進行銜接,已具備進行產業應用的能力基礎。
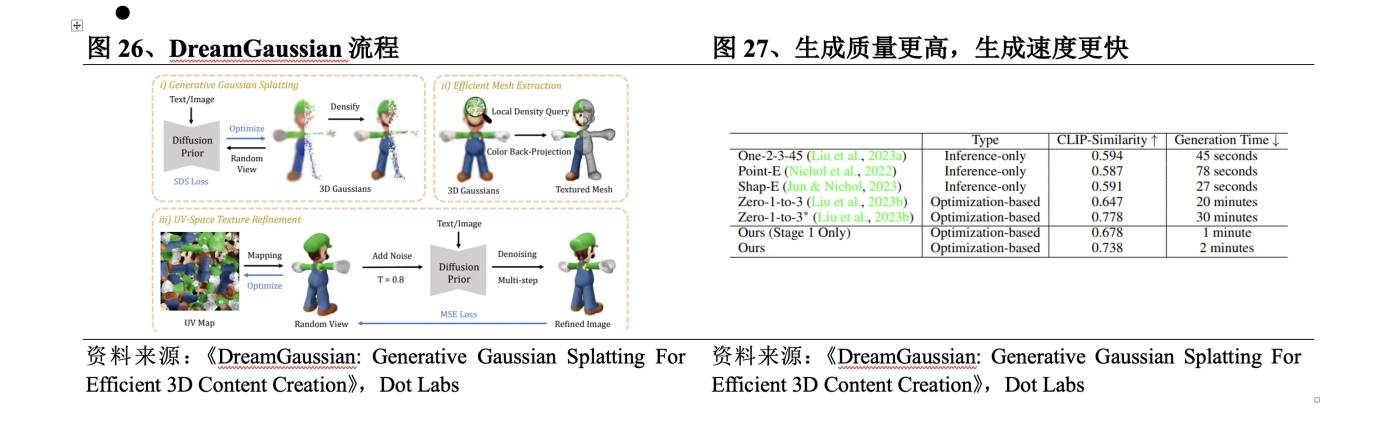
2023年9月,來自百度、南洋理工和北大的作者共同發佈DreamGaussian。DreamGaussian流程為:①在UV空間使用3D Gaussian Splatting建模文本或圖像指示的內容;②使用SDS Loss進行優化並提取紋理網格;③通過多輪計算MSE Loss細化網格上圖像的紋理。與基於NeRF的方法相比,該方法的具體突破在於:
l 生成質量更高。DreamGaussian設計了從3D高斯提取網格的算法和UV空間紋理細化階段,進一步提高了生成質量。
l 生成速度更快。通過將高斯分割適應生成設置,顯著減少了2D升維方法的生成時間,DreamGaussian可以在2分鐘內從單視圖圖像生成具有明確網格和紋理映射的3D內容,相較於現有方法加速了約10倍。
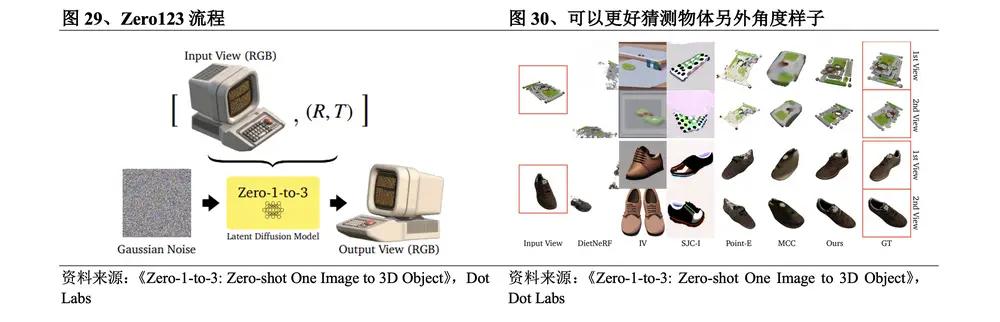
前期的2D升維方法主要利用2D數據集進行訓練,只能提煉有限的3D幾何知識。2023年3月,哥倫比亞大學劉若石博士發表Zero123,探索到將3D信息注入2D預訓練模型中,可以有效彌補擴散模型3D先驗能力不足的問題。於是,生成多個視角的圖像後通過3D重建的方法得到3D模型的多視角重建方法興起。之後,在Zero123的基礎上,加州大學聖地亞戈分校蘇昊教授團隊提出了One-2-3-45和One-2-3-45++,藉助擴散模型實現更好的生成泛化性,同時利用有限的3D數據實現相對正確的幾何結構,以及字節跳動發佈MVDream、VAST發佈Wonder3D、Meta發佈MVDiffusion++。
2023年3月,哥倫比亞大學的研究團隊發佈Zero123。Zero123流程為:①輸入單個RGB圖像進行編碼;②對噪聲圖像進行去噪;③選擇另外的攝像機視角生成新視角圖像;④把這些多視角圖片加入擴散模型進行訓練並3D重建。該方法的具體突破在於:雖然顛倒了3D重建和新視圖合成的順序,但保留了輸入圖像中所描述對象的身份,以至可以利用旋轉物體時的概率生成模型,來模擬自遮擋引起的隨機不確定性,有效利用了擴散模型學習到的語義和幾何先驗,擴散模型在訓練過程中已經知道3D物體多個角度的真實樣子,可以更好猜測物體另外角度樣子。
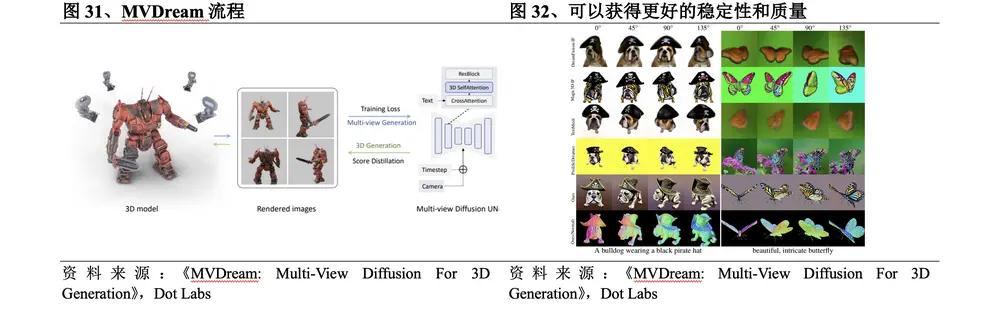
2023年8月,字節跳動發佈MVDream。MVDream流程為:①通過在自注意力層中連接不同的視圖來將原始的2D自注意力層轉換為3D,併為每個視圖添加相機嵌入;②使用多視角擴散模型作為3D優化的先驗,並通過SDS進行3D生成。該方法的具體突破在於:
l 通過利用在大規模網絡數據集上預訓練的圖像擴散模型以及從3D資源渲染的多視圖數據集,得到的多視圖擴散模型既能夠實現2D擴散的通用性,又能夠實現3D數據的一致性。相對於當前開源的2D升維方法,可以獲得更好的穩定性和質量。
l 多視角擴散模型可以在少樣本設置下進行訓練微調,允許用戶進行個性化的3D生成。
三、2D升維方法商業化可期
通過不斷地發展和完善,3D生成技術在生成質量、速度和豐富性已取得很大進步,若能更好地解決以下問題,3D生成技術將有十分值得期待的未來:
l 數據集。訓練數據不足是制約3D生成技術發展的重要原因,主要由於:①3D數據集的生產歷史很短;②3D資產通常需要3D設計師花費大量時間使用專業軟件進行創建;③由於使用場景和創作者風格的不同,3D資產在規模、質量和風格上存在很大差異,從而增加了3D數據的複雜性;④3D數據獲取不便,大量3D數據分散在了遊戲公司、影視特效公司和個人建模師的手裡難以收集。探索如何利用2D數據進行3D生成是解決方案之一,但大規模、高質量的3D數據集仍然非常必要。
l 表示方式。3D生成技術中,隱式表示能夠有效地建模複雜的幾何拓撲結構,但優化速度慢,顯式表示有助於快速優化收斂,但難以封裝複雜的拓撲結構,並需要大量的存儲資源,開發一種可以同時具有高訓練效率和高精細度的表示方式,3D生成效果會更上一個臺階。
l 評估體系。全面評估生成的3D內容需要理解其物理屬性和預期設計,目前對3D內容質量的評估主要依賴人工評分,開發能全面衡量幾何和紋理保真度的穩健指標,可以推動3D生成技術的優化工作。
l 可控性。3D生成技術的目的是以廉價和可控的方式生成大量用戶友好、高質量和多樣化的3D內容,但是將生成的3D內容嵌入到實際應用中時,兼容性問題不利於3D設計師交互和編輯,且生成內容的風格受到訓練數據集的限制,統一通過不同方法制作的3D內容並建立包含豐富編輯功能的工具鏈以增強技術的可控性非常必要。
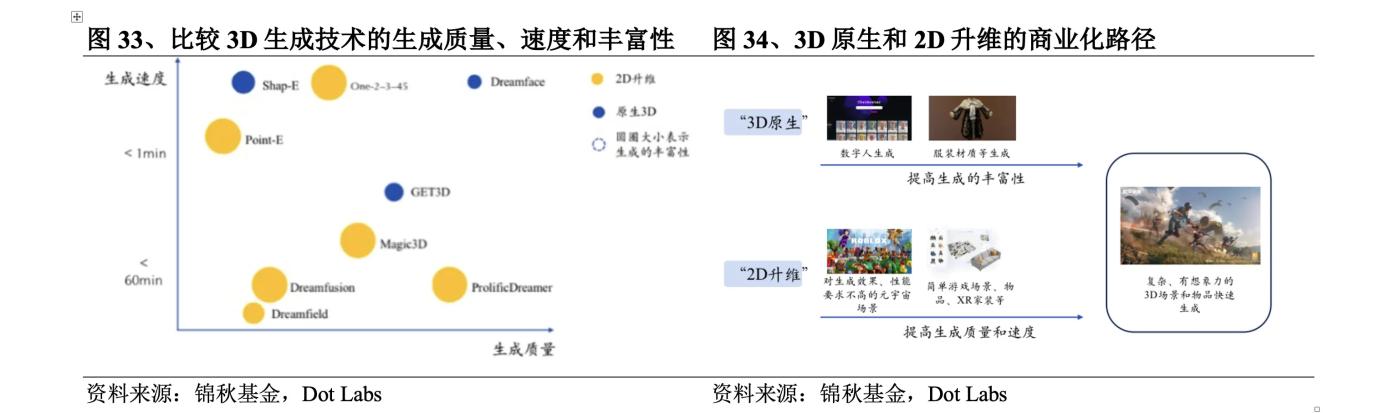
對不同3D生成技術的生成質量、生成速度和豐富性進行比較可以發現,這些方法在以上三者之間存在一個“不可能三角”:3D原生路線的方法使用3D數據集,基本上保證了質量和速度,但是在豐富性上由於數據集過小而存在明顯短板,2D升維路線的方法使用2D數據集,能夠很好地滿足豐富性要求,既有Zero123這樣生成質量讓人亮眼的方法,也有DreamGaussian這種在生成速度上追求極致的方法。
“不可能三角”讓3D生成技術在商業化進程中面臨較大挑戰。對於面向專業人士的場景,在生成質量上有較高要求,如工業、建築業與醫療需要3D生成高度準確,對於面向普通消費者的場景,更強調生成速度。3D原生方法在生成質量和速度上的優勢更接近商業化的要求,可實現特定場景下的先行商業化。例如影眸科技的Dreamface已經可以在遊戲領域替代一部分前期建模的工作,Get3D正在一些元宇宙類場景裡進行簡單物品生成。相比之下,2D升維方法離商業化更遠一些,但能看到2023年下半年以來大量2D升維相關學術成果發佈,2D升維方法在生成質量、生成速度上都有不同程度的顯著提升,可以預期未來一年內,2D升維有機會在一些對生成質量要求不苛刻的場景初步落地,比如元宇宙、VR家裝等。
四、頭顯完善開拓無限潛力
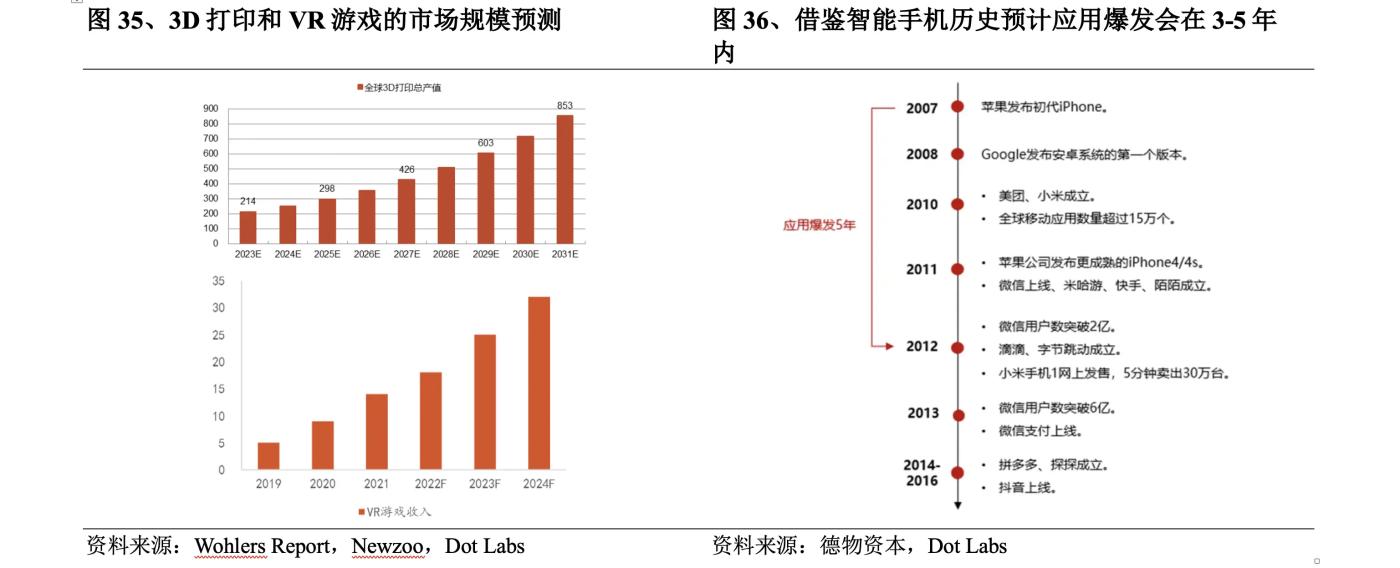
雖然現有3D生成技術還存在一些問題,但不可否認的是,3D生成的未來應用空間巨大,主要集中在3D打印、遊戲、影視等領域。據Wohlers Report的數據,2022年全球3D打印總產值182億美元,同比增長18%,增速持續保持高位,預計2031年市場規模將達到853億美元,據Newzoo的預測,全球VR遊戲市場規模在2024年可達32億美元。在其下游3D內容應用領域的發展下,3D生成技術擁有廣闊的需求和市場期待。
而從長期的視角來看,3D生成的更大潛力空間在於頭顯設備的完善。硬件是技術的載體,硬件的發展會促進技術的發展。頭顯設備的完善有望帶來3D原生應用爆發,開發者可以藉助3D生成技術開發頭顯應用,促進頭顯設備生態走向成熟。雖然從用戶反饋來看,初代設備Vision Pro還有很多不盡如人意之處,但借鑑智能手機的發展歷史,預計應用爆發會在3-5年內實現,從中可以窺探到的未來依舊值得興奮。
五、3D生成初創企業入局市場
解決3D生成技術的問題並不能簡單依靠發幾篇論文,更需要對3D工業標準和專業用戶需求有清晰的認知。除了Nvidia、OpenAI、Google等大型科技企業外,在3D生成領域,一些新興的3D生成創業公司也在可用性方面做了很多工作,最終效果不一定比巨頭差,他們的表現和未來值得市場期待。
l CSM(Common Sense Machines):2020年成立於美國馬薩諸塞州,由前Google DeepMind高級研究科學家Tejas Kulkarni和麻省理工博士研究員、紅杉資本的偵察投資者Max Kleiman-Weiner共同創立。該公司提供了一個平臺CSM.ai,允許用戶將照片、文本和手繪草圖轉換為完全實現的3D世界。CSM創新地提出了不同於顯示遊戲引擎和隱式遊戲引擎的第三種框架——結合高度靈活性和可控性的隱式學習遊戲引擎,開發了基於擴散的實時渲染引擎,推出快速生成高分辨率3D資產和自定義風格圖像的Cube應用。在三輪融資中已籌集了1010萬美元。
l Luma:2021年由前蘋果AR/CV工程師Amit Jain、伯克利實驗室負責人Alberto Taiuti和Alex Yu共同創立,總部位於美國加州,旨在通過AI簡化3D圖像和視頻的創建過程,核心技術基於NeRF。其今年1月發佈的Genie 1.0可在10秒內根據文本生成3D模型,其本月推出的革命性AI視頻生成器Dream Machine,可以根據文本和圖像創建高質量、逼真的視頻,且速度快至120秒內120幀。憑藉出色的技術實力和廣闊的市場前景,Luma已經成功籌集了超過7000萬美元的資金,主要投資者包括Andreessen Horowitz、Matrix Partners和Amplify Partners等知名風投公司。截至2024年,Luma的估值已達到3億美元。
l Polycam:2021年成立於美國加州,其APP允許用戶利用iPhone的LiDAR和攝像頭生成3D模型。推出AI Texture Generato用於創建3D紋理、免費的3D高斯濺射創建者和查看器用於3D高斯濺射重建。Polycam擁有近10萬名付費客戶,APP下載量已超過1000萬次,製作了超過2000萬個3D模型,執行了超過5000萬次3D編輯工作。其收入從2021年的28萬美元增長至2022年的180萬美元,2023年飆升至650萬美元,今年上半年已超400萬美元,預計全年收入將再創新高。完成了1800萬美元的A輪融資,投資方為Left Lane Capital、Adjacent、Adobe Ventures、YouTube聯合創始人Chad Hurley。
l Yellow:成立於2023年的3D角色生成公司,由A16z提供500萬美元的種子資金支持,其CEO Mandeep Waraich曾是Google大模型和Core ML產品負責人,大部分團隊成員擁有麻省理工、牛津、斯坦福等名校背景。已發佈第一個產品YellowSculpt,實現了拓撲感知的3D生成,使其更易於使用和編輯。雖然目前大多數生成式AI技術都會產生剛性對象,但Yellow的結構化網格生成會產生易於設置動畫的3D模型,且生成的網格可以與Unity、Unreal和Roblox等頂級遊戲引擎或Daz Studio、Maya和Blender等其他3D創作工具無縫集成。2024年1月與Daz Studio的開發商Tafi建立了獨家合作關係,Yellow可以利用Daz的3D庫以安全的方式訓練模型。
六、3D生成加碼空間智能時代
空間智能是一個支持實時渲染的3D虛擬環境,需要身份認證、數據確權、資產交易、監管治理等作為支撐,而Web 3的去中心化思想恰好為其提供了一個安全、可靠且公開的基礎設施環境,空間智能也將成為Web 3大規模應用的重要場景,Web 3與空間智能在相互促進的發展中到來,空間智能中重要的3D生成技術在Web 3的互聯網環境下將擁有廣闊的應用和發展空間。
1、 Lifeform:視覺DID先驅引領Web 3破圈機遇
在Web 3和空間智能的風口,數字虛擬身份成為行業內關鍵且缺乏的基礎設施。Lifeform是去中心化數字身份(DID)解決方案的先驅提供商,為Web 3用戶提供數字虛擬身份,並用來登錄任何DApp和元宇宙,有望實現區塊鏈互操作性,為Web 3帶來破圈式的發展機遇。項目在一年間進行了4億美元總估值的兩輪融資,投資機構包括幣安、IDG Capital、GeekCartel,上線174天就在Twitter收穫了10萬關注量,現月交易量已超350萬美元,約佔BSC市場份額的35%,僅次於OpenSea,其代幣LFT今年5月上線Bybit、KuCoin。
l 視覺DID以提升心理體驗。已有的DID是在鏈上保存用戶的個人信息,通過NFT或SBT等方式來實現錢包與鏈上身份的綁定,而Lifeform採用視覺DID,除了兼容DID標準之外,還為用戶提供虛擬人編輯器及相應的DID協議、智能合約等,允許用戶以可視化的3D虛擬人物形象參與元宇宙活動,提升用戶的視覺和心理體驗。
l 超百億組合滿足個性化需求。Lifeform的產品AvatarID有基於UE5的Hyper-Realistic和卡通風格的Cartoon Version兩種,其虛擬人編輯包含7個創建部件,每個部件擁有超過1000個組件,用戶可以創建超過100億個頭像組合,且還提供大量模板以降低用戶的製作難度,製作完成後支持形成NFT。
l 通用域名確保跨鏈可用。與依賴於不同區塊鏈而限制了跨鏈能力和應用範圍的其他DID解決方案不同,Lifeform創造的通用域名服務,通過.btc後綴簡化跨區塊鏈的身份驗證和定位,是首個支持多條區塊鏈(比特幣、以太坊、BNB Chain、Solana、Base、Avalanche、OPBNB等)的域名解析平臺,用戶可以完全控制自己的身份信息,確保了數字身份的全球可用性。未來計劃與各類錢包合作,將.btc域名SDK接入交易所錢包,以及支持跨多個第1層和第2層網絡無縫交互。
2、 Param Labs:模塊互聯繫統創新Web 3遊戲生態
Param Labs是一家AAA級遊戲和區塊鏈開發工作室,致力於創建模塊化、互聯的Web3遊戲生態系統,通過賦予用戶數字產權確保他們創造的價值能夠返還,徹底改變玩家和開發者的遊戲體驗。項目現已完成700萬美元融資,由Animoca Brands領投,Delphi Ventures和Cypher Capital等參投,擁有約90萬Twitter關注者、50萬Discord用戶和30萬每日活躍用戶,即將在Bitget和Gate.io等交易所推出其代幣PARAM。其主要產品有:
l Pixel to Poly:用於大規模生產元宇宙資產的平臺,可將用戶上傳的2D圖像轉換為高質量、可用於遊戲的3D資產,且這些資產可以集成到Fortnite和GTAV等熱門遊戲中,大大縮短了遊戲開發者的製作時間,加速3D遊戲行業的資產創造。該平臺還有在遊戲中使用的獨特NFT,為玩家和收藏家提供有價值的數字資產。
l Kiraverse:免費的多人射擊遊戲,用戶可通過導入自定義IP進一步個性化,以獲得獨特、跨IP和跨生態系統的體驗。今年5月宣佈與遊戲生態系統Pixelverse合作,Pixelverse將把其智慧財產權和角色整合到Kiraverse中,從而增強遊戲的敘事並擴展其宇宙。
3、 NeuralAI:開發Bittensor子網革新Web 3 3D生成
NeuralAI利用其$NEURAL生態系統和dapp為用戶提供3D資產生成服務,且提供市場允許用戶無縫地交易其創作資產。項目正在進行Bittensor子網的開發工作,即將發佈第一個dapp,旨在成為3D資產生成的首要Bittensor子網。項目已與世界頂級去中心化計算市場Akash Network達成戰略合作,Akash為其提供了56個功能強大的A6000 GPU,可按需擴展。
l LRM模型優化多邊形數。NeuralAI使用的主要模型是LRM,其顯著優勢是能夠生成優化多邊形數網格,在保留細節的同時具有較少的多邊形數,適合在高FPS(畫面每秒幀數)下運行,確保模型高效並保持詳細,非常適合遊戲環境,且允許3D藝術家在後期製作中使用軟件操縱和細化網格,或將其直接添加到遊戲引擎中。
l Bittensor子網降本3D生成。生成3D資產是資源密集型過程,需要大量的計算能力和人力資源。Bittensor作為一個分散的機器學習網絡,可以在全球節點分配大量計算任務,NeuralAI正在Bittensor網絡中開發一個專用子網,為3D資產生成提供更好的解決方案。據該項目測算,聘請專業的3D藝術家每小時的費用為30-100美元,對於一個需要10個小時才能創建的複雜資產,則需要300-1000美元,且並不包括軟件和硬件的額外管理費用。而在Bittensor子網中,Bittensor會使用代幣TAO獎勵驗證器和礦工,Neural dApp、Neural插件或API的用戶可以免費生成3D資產,如果網絡的激勵措施涵蓋了生成3D資產的獎勵,那麼成本可以節省90-100%。

七、風險提示
風險一:價格波動
- 加密貨幣價格波動較大,無法保證或預測未來價格
風險2:財務
- 項目可能會破產,或者無法償還SWEAT本金或利息
風險3:黑客攻擊
- SWEAT可能會被惡意行為者竊取,項目方可能無法退還資金
風險4:法律
- 部分國家和地區禁止該類行為,項目方可能無法償還SWEAT本金或利息