

來源:福布斯
編譯:MetaverseHub
上週有消息稱,OpenAI 在新一輪融資中獲得 65 億美元,其市場估值也來到了 1500 億美元。
這筆融資再次肯定了 OpenAI 作為人工智能初創公司的巨大價值,也表明它願意做出結構性改變,以吸引更多投資。
消息人士補充說,鑑於 OpenAI 收入的快速增長,這一輪大規模融資受到了投資者的強烈追捧,並可能在未來兩週內敲定。
Thrive Capital、Khosla Ventures 和微軟等現有投資者有望參與。包括英偉達和蘋果在內的新投資者也計劃參與投資,紅杉資本也在洽談迴歸投資事宜。

同時,OpenAI 推出了 o1 系列,這是其迄今為止最複雜的人工智能模型,旨在出色地完成複雜的推理和問題解決任務。o1 模型使用了強化學習和思維鏈推理,代表了人工智能能力的重大進步。
OpenAI 通過不同的訪問層級向 ChatGPT 用戶和開發者提供 o1 模型。對於 ChatGPT 用戶,ChatGPT Plus 計劃的用戶可以訪問 o1-preview 模型,該模型具有高級推理和解決問題的能力。
OpenAI 的應用程序接口(API)允許開發人員在更高級別的訂閱計劃中訪問 o1-preview 和 o1-mini。
這些模型在第 5 級 API 中提供,允許開發人員將 o1 模型的高級功能集成到自己的應用程序中。第 5 級 API 是 OpenAI 為訪問其高級模型而提供的更高級別的訂閱計劃。
以下是有關 OpenAI o1 模型的 10 個關鍵要點:
01.兩個模型變體:o1-Preview 和 o1-Mini
OpenAI 發佈了兩個變體:o1-preview 和 o1-mini。o1-preview 模型在複雜任務中表現出色,而 o1-mini 則為 STEM 領域(尤其是編碼和數學)提供了更快、更具成本效益的優化解決方案。
02.高級思維鏈推理
o1 模型利用思維鏈過程,在做出回答之前會逐步推理。這種深思熟慮的方法提高了準確性,有助於處理需要多步驟推理的複雜問題,使其優於 GPT-4 等以前的模型。

思維鏈提示通過將複雜問題分解為連續的步驟來增強人工智能的推理能力,從而提高模型的邏輯和計算能力。
OpenAI 的 GPT-o1 模型將這一過程嵌入其架構中,模擬人類解決問題的過程,從而推進了這一過程。
這使得 GPT-o1 在競技編程、數學和科學領域表現出色,同時也提高了透明度,因為用戶可以跟蹤模型的推理過程,這標誌著類人人工智能推理的飛躍。
這種先進的推理能力會導致模型在做出響應前需要一定的時間,與 GPT-4 系列模型相比可能會顯得緩慢。
03.增強的安全功能
OpenAI 在 o1 模型中嵌入了先進的安全機制。這些模型在不被允許的內容評估中表現出卓越的性能,顯示出對「越獄」的抵抗性,使其在敏感用例中的部署更加安全。
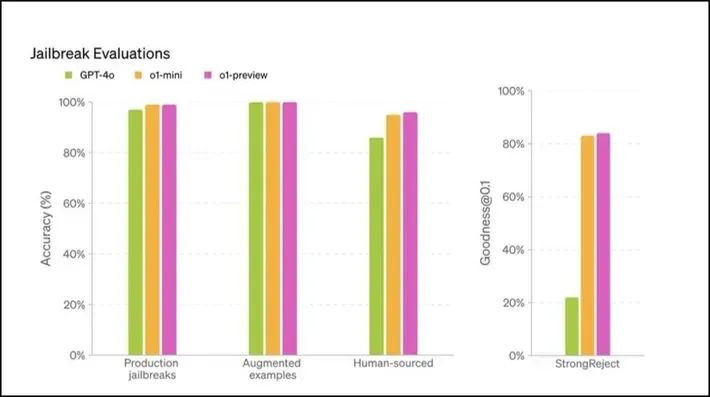
人工智能模型「越獄」涉及繞過安全措施,容易引發有害或不道德的輸出。隨著人工智能系統變得越來越複雜,與「越獄」相關的安全風險也隨之增加。
OpenAI 的 o1 模型,尤其是 o1-preview 變體,在安全測試中得分更高,顯示出更強的抵禦此類攻擊的能力。
這種增強的抵禦能力得益於該模型的高級推理能力,這有助於它更好地遵守道德準則,使惡意用戶更難操縱它。
04.在 STEM 基準測試中表現更佳
o1 模型在各種學術基準測試中名列前茅。例如,o1 在 Codeforces(編程競賽)中排名第 89 位,在美國數學奧林匹克預選賽中名列前 500 名。
05.減少「高級幻覺」
大型語言模型中的「幻覺」是指生成錯誤或無據信息。OpenAI 的 o1 模型利用高級推理和思維鏈過程解決了這一問題,使其能夠逐步思考問題。
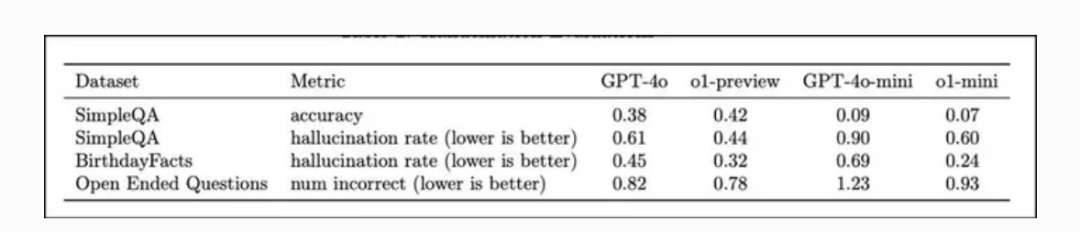
與以前的模型相比,o1 模型降低了「幻覺」發生率。
在 SimpleQA 和 BirthdayFacts 等數據集上進行的評估顯示,o1-preview 在提供真實、準確的回答方面優於 GPT-4,從而降低了錯誤信息的風險。
06.基於多樣化的數據集訓練
o1 模型在公共、專有和定製數據集上進行了綜合訓練,使其既精通一般知識,又熟悉特定領域的主題。這種多樣性使其具有強大的對話和推理能力。
07.價格友好且具成本效益
OpenAI 的 o1-mini 模型是 o1-preview 的高性價比替代品,價格便宜 80%,同時在數學和編碼等 STEM 領域仍具有很強的性能。
o1-mini 模型專為需要高精度、低成本的開發人員量身定製,非常適合預算有限的應用。這種定價策略可確保更多的人,尤其是教育機構、初創企業和小型企業,能夠接觸到先進的人工智能。
08.安全工作和外部「紅隊測試」
在大語言模型(LLM)中,「紅隊測試」是指通過模擬其他人的攻擊,或者用可能導致模型做出有害、有偏見或與初衷不符的行為的方式來嚴格測試人工智能系統。
這對於在大規模部署模型之前找出內容安全、錯誤信息和道德界限等方面的漏洞至關重要。

通過使用外部測試人員和不同的測試場景,紅隊測試有助於使 LLM 更加安全、穩健並符合道德標準。這樣可以確保模型能夠抵禦「越獄」或其他方式的操縱。
在部署之前,o1 模型經過了嚴格的安全評估,包括紅隊測試和準備框架評估。這些努力有助於確保模型符合 OpenAI 的高安全性和一致性標準。
09.更公平,更少偏見
o1-preview 模型在減少刻板答案方面的表現優於 GPT-4。在公平性評估中,它能更多地選擇正確答案,同時在處理模稜兩可的問題方面也有改進。
10.思維鏈監控與欺騙檢測
OpenAI 採用了實驗技術來監控 o1 模型的思維鏈,以在模型故意提供錯誤信息時檢測欺騙行為。初步結果表明,在降低模型生成的錯誤信息所帶來的潛在風險方面,該技術具有良好的前景。
OpenAI 的 o1 模型代表了人工智能推理和解決問題方面的重大進步,尤其在數學、編碼和科學推理等 STEM 領域表現出色。
隨著高性能 o1-preview 和高性價比 o1-mini 的推出,這些模型針對一系列複雜任務進行了優化,同時通過廣泛的紅隊測試確保了更高的安全性和道德合規性。






