

作者:Swayam
編譯:深潮TechFlow
人工智能 (AI) 的快速發展,使少數大型科技公司掌握了前所未有的計算能力、數據資源和算法技術。然而,隨著 AI 系統逐漸融入我們的社會,有關可訪問性、透明性和控制權的問題,已成為技術和政策討論的核心議題。在這樣的背景下,區塊鏈技術與 AI 的結合為我們提供了一種值得探索的替代路徑——一種可能重新定義 AI 系統開發、部署、擴展和治理的新方式。
我們並不是要完全顛覆現有的 AI 基礎設施,而是希望通過分析,探討在某些具體用例中,去中心化方法可能帶來的獨特優勢。同時,我們也承認在某些情境下,傳統的中心化系統可能仍然是更實際的選擇。
以下幾個關鍵問題引導了我們的研究:
去中心化系統的核心特性(如透明性、抗審查性)是否能夠與現代 AI 系統的需求(如高效性、可擴展性)相輔相成,還是會產生矛盾?
在 AI 開發的各個環節——從數據收集到模型訓練再到推理——區塊鏈技術能夠在哪些方面提供實質性的改進?
在去中心化 AI 系統的設計中,不同環節會面臨哪些技術和經濟上的權衡?
AI 技術堆棧中的當前限制
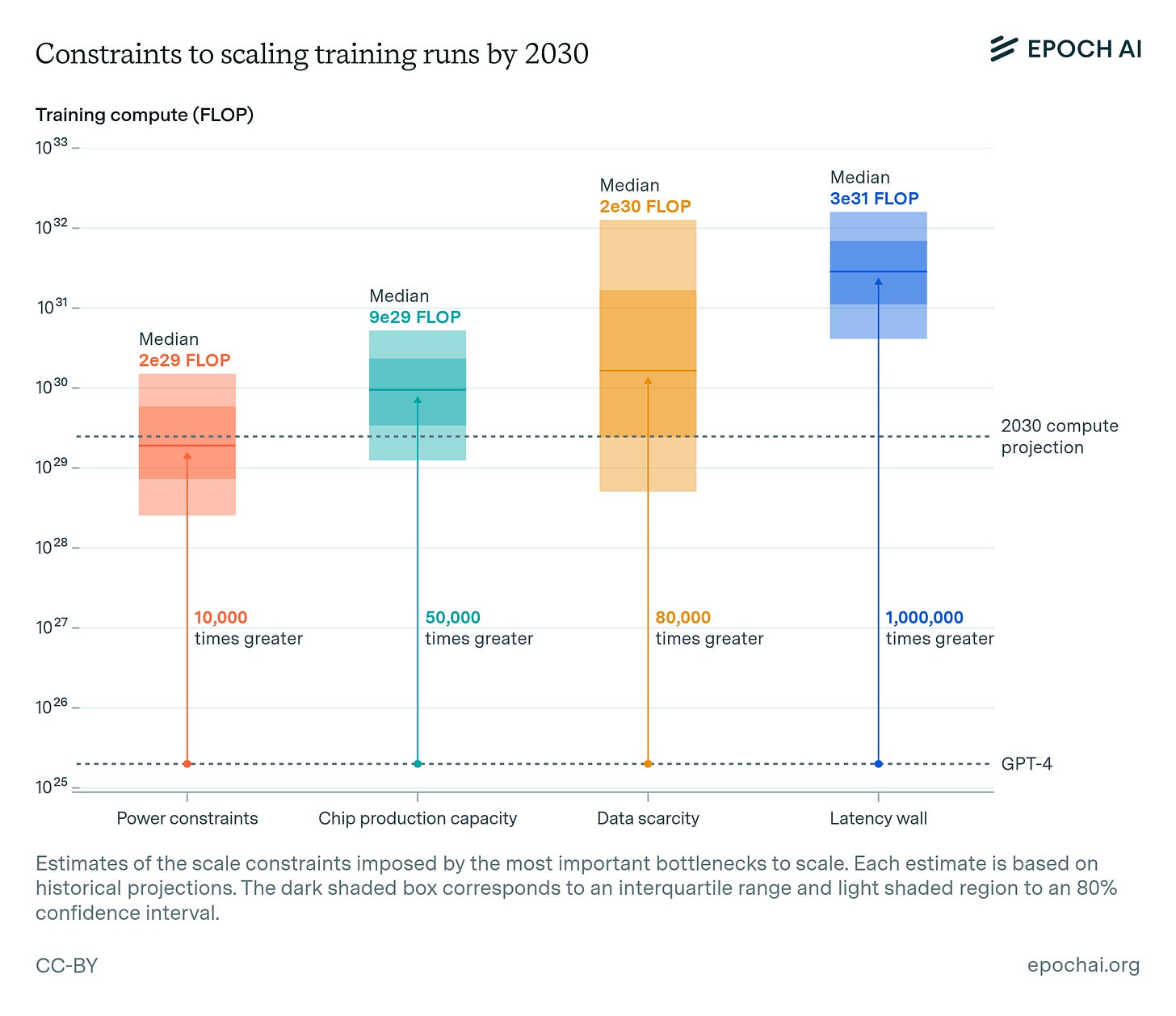
Epoch AI 團隊在分析當前 AI 技術堆棧的限制方面做出了重要貢獻。他們的研究詳細闡述了到 2030 年,AI 訓練計算能力擴展可能面臨的主要瓶頸,並使用每秒浮點運算次數 (Floating Point Operations per Second, FLoPs) 作為衡量計算性能的核心指標。
研究表明,AI 訓練計算的擴展可能受到多種因素的限制,包括電力供應不足、芯片製造技術的瓶頸、數據稀缺性以及網絡延遲問題。這些因素各自為可實現的計算能力設定了不同的上限,其中延遲問題被認為是最難突破的理論極限。
該圖表強調了硬件、能源效率、解鎖邊緣設備上捕獲的數據以及網絡方面的進步的必要性,以支持未來人工智能的增長。
電力限制 (性能):
擴展電力基礎設施的可行性(2030 年預測): 預計到 2030 年,數據中心園區的容量有望達到 1 至 5 吉瓦 (GW)。然而,這一增長需要依賴對電力基礎設施的大規模投資,同時還需克服可能存在的後勤和監管障礙。
受能源供應和電力基礎設施的限制,預計全球計算能力的擴展上限可能達到當前水平的 10,000 倍。
芯片生產能力 (可驗證性):
當前,用於支持高級計算的芯片(如 NVIDIA H100、Google TPU v5)的生產受限於封裝技術(如 TSMC 的 CoWoS 技術)。這種限制直接影響了可驗證計算的可用性和擴展性。
芯片製造和供應鏈的瓶頸是主要障礙,但仍可能實現計算能力高達 50,000 倍的增長。
此外,先進芯片在邊緣設備上啟用安全隔離區或可信執行環境 (Trusted Execution Environments, TEEs) 至關重要。這些技術不僅能夠驗證計算結果,還能在計算過程中保護敏感數據的隱私。
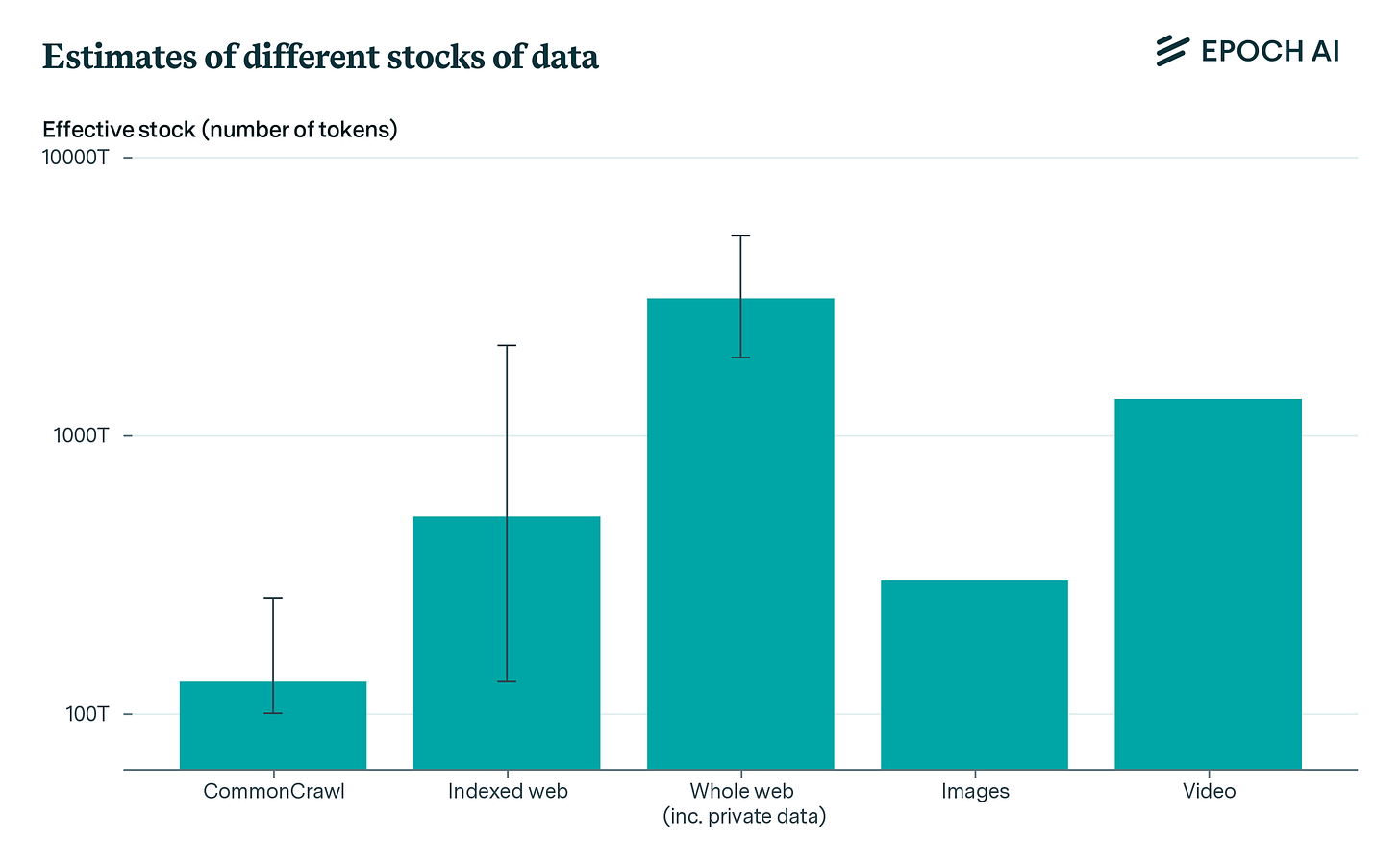
數據稀缺性 (隱私):
延遲壁壘 (性能):
模型訓練中的固有延遲限制: 隨著 AI 模型規模的不斷擴大,由於計算過程的順序性,單次前向傳播和後向傳播所需的時間顯著增加。這種延遲是模型訓練過程中無法繞過的根本限制,直接影響了訓練速度。
擴展批量大小的挑戰: 為了緩解延遲問題,一種常見的方法是增加批量大小,使更多數據能夠並行處理。然而,批量大小的擴展存在實際限制,例如內存容量不足,以及隨著批量增大,模型收斂效果的邊際收益遞減。這些因素使得通過增加批量來抵消延遲變得更加困難。
基礎
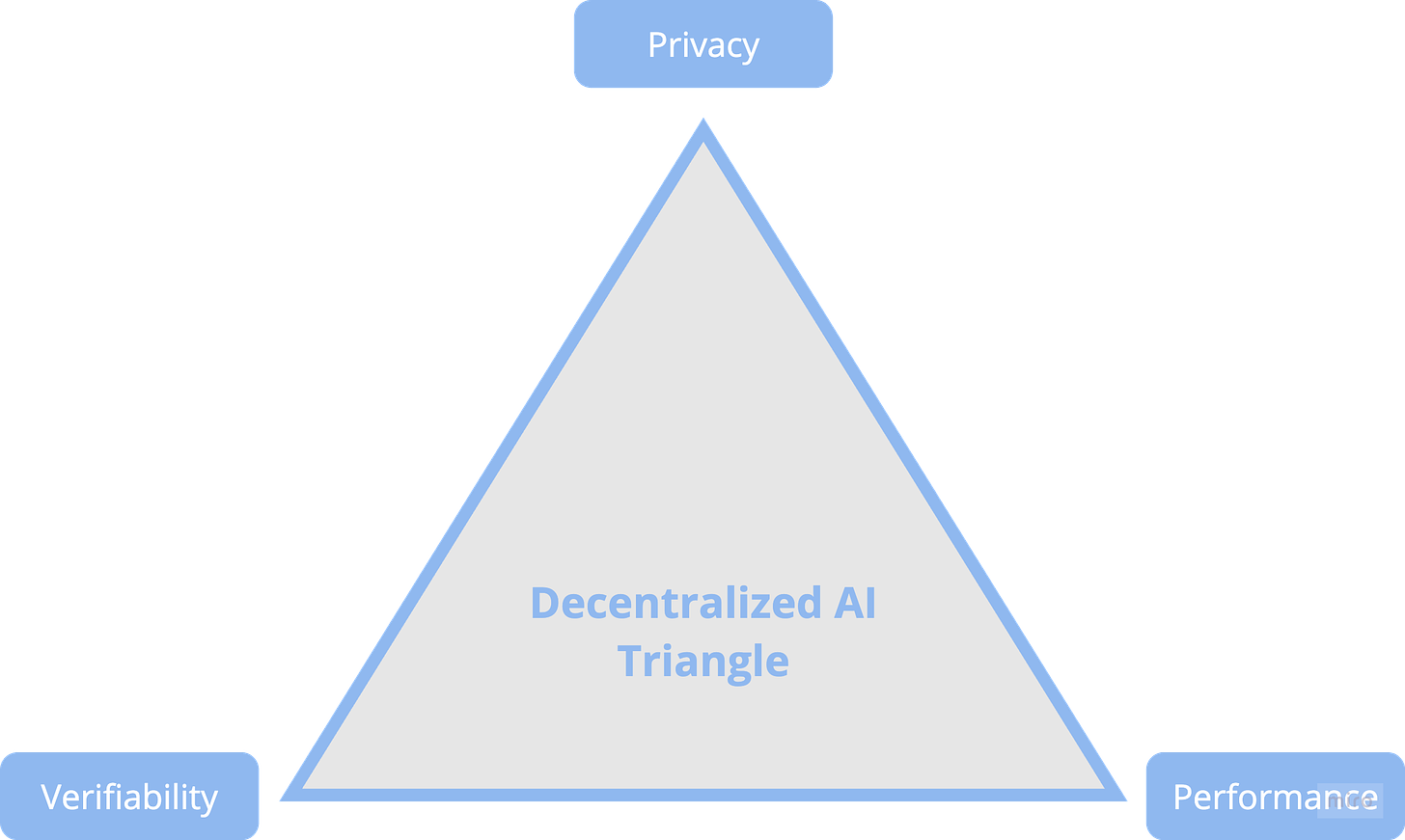
去中心化 AI 三角形
當前 AI 面臨的多種限制(如數據稀缺性、計算能力瓶頸、延遲問題和芯片生產能力)共同構成了“去中心化 AI 三角形”。這一框架試圖在隱私、可驗證性和性能之間實現平衡。這三種屬性是確保去中心化 AI 系統有效性、可信性和可擴展性的核心要素。
以下表格詳細分析了隱私、可驗證性和性能三者之間的關鍵權衡,深入探討了各自的定義、實現技術及其面臨的挑戰:
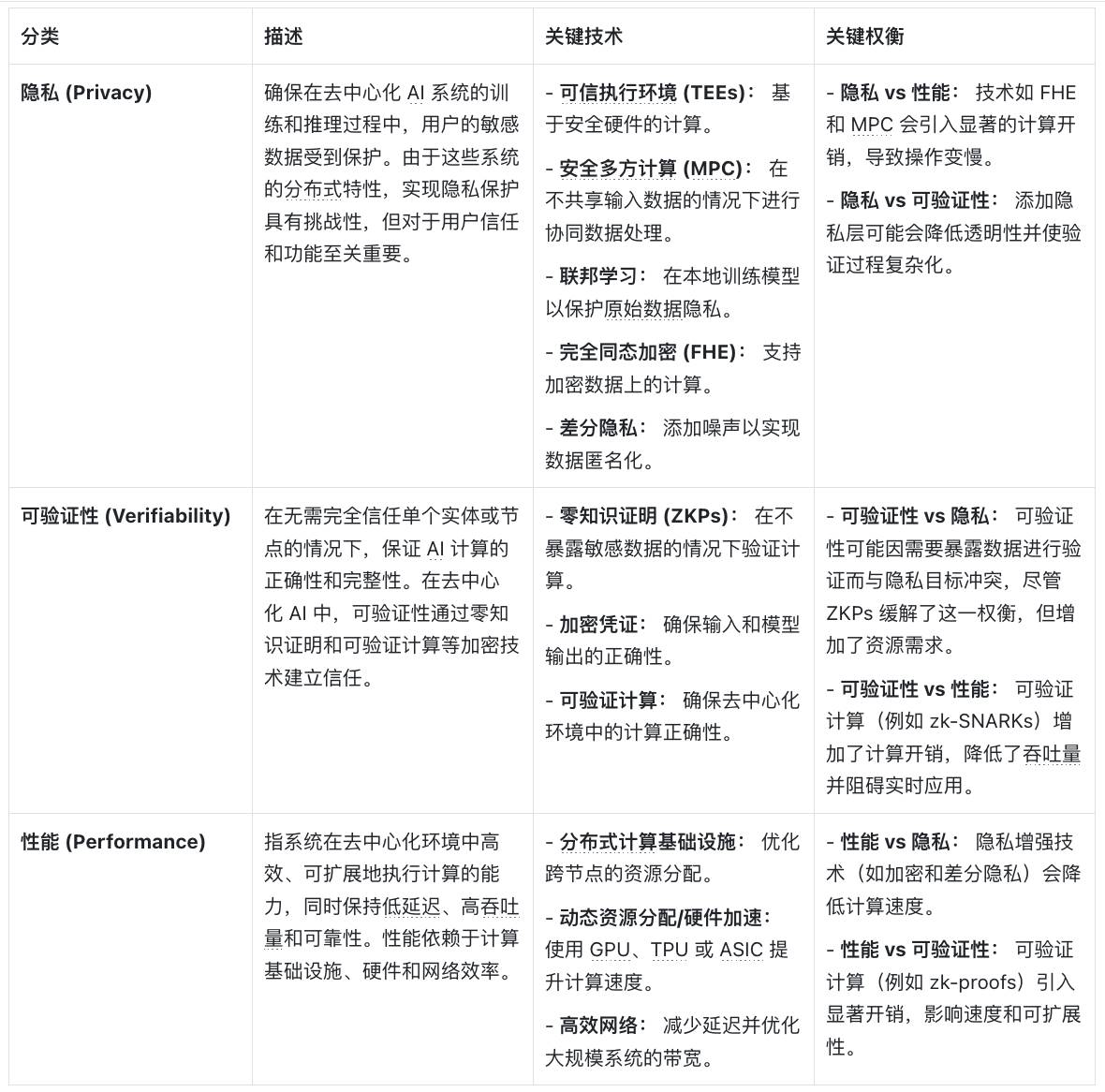
隱私: 在 AI 的訓練和推理過程中,保護敏感數據至關重要。為此,使用了多種關鍵技術,包括可信執行環境 (TEEs)、多方計算 (MPC)、聯邦學習、全同態加密 (FHE) 和差分隱私。這些技術雖然有效,但也帶來了性能開銷、透明度問題影響可驗證性,以及可擴展性受限等挑戰。
可驗證性: 為確保計算的正確性和完整性,採用了零知識證明 (ZKPs)、加密憑證和可驗證計算等技術。然而,在隱私和性能與可驗證性之間取得平衡,往往需要額外的資源和時間,這可能導致計算延遲。
性能: 高效地執行 AI 計算並實現大規模應用,依賴於分佈式計算基礎設施、硬件加速和高效的網絡連接。然而,採用隱私增強技術會導致計算速度變慢,而可驗證計算也會增加額外的開銷。
區塊鏈三難困境:
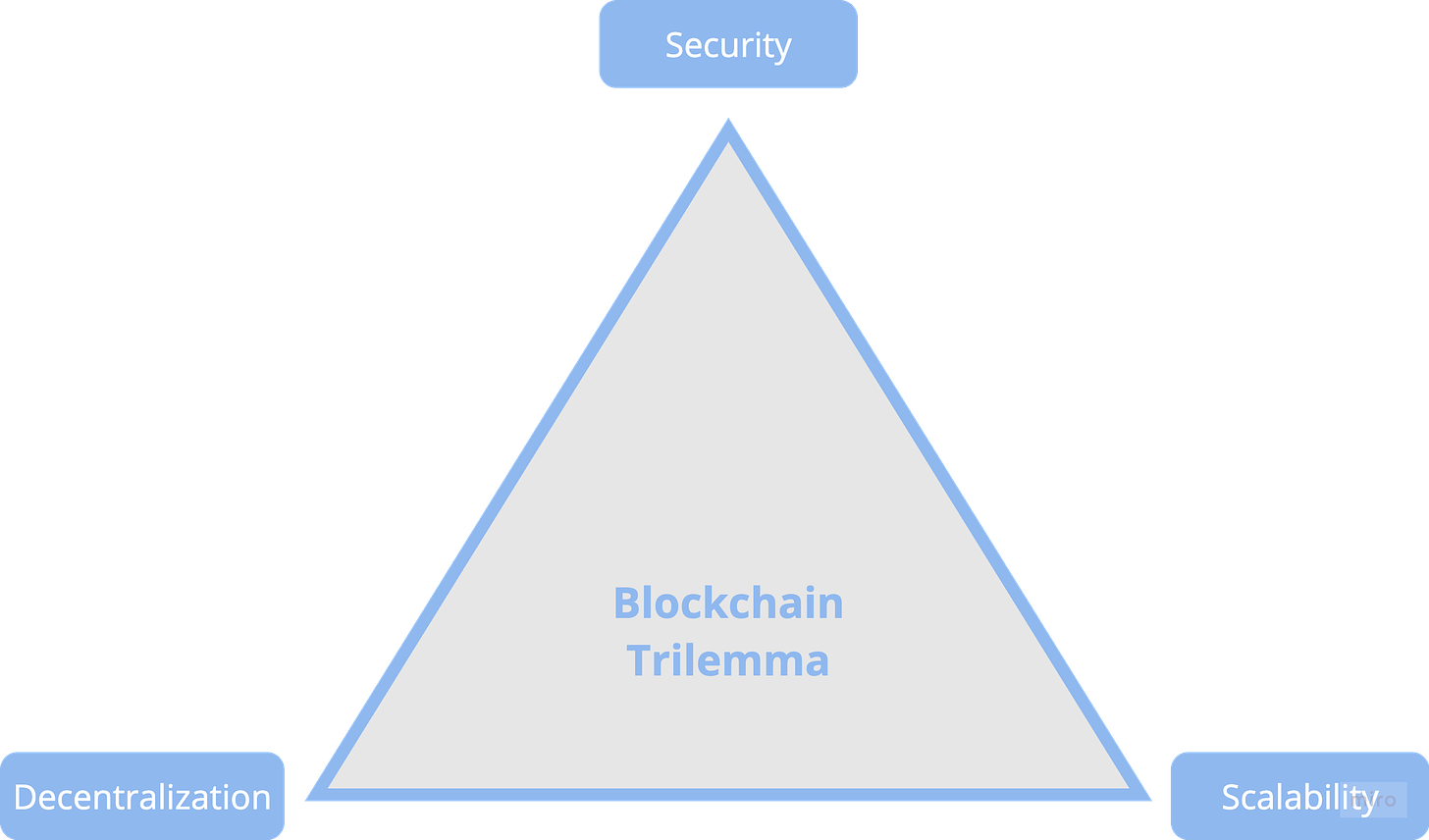
區塊鏈領域面臨的核心挑戰即三難困境,每個區塊鏈系統都必須在以下三者之間進行權衡:
去中心化:通過在多個獨立節點上分佈網絡,防止任何單一實體對系統的控制。
安全性:確保網絡免受攻擊並保持數據完整性,通常需要更多的驗證和共識流程。
可擴展性:快速且經濟地處理大量交易,然而這通常意味著在去中心化(減少節點數量)或安全性(降低驗證強度)上做出妥協。
例如,以太坊優先考慮去中心化和安全性,因此其交易處理速度相對較慢。關於區塊鏈架構中這些權衡的深入理解,可以參考相關文獻。
AI-區塊鏈協同分析矩陣 (3x3)
AI 和區塊鏈的結合是一個複雜的權衡與機遇的過程。這個矩陣展示了這兩種技術在何處可能產生摩擦、找到和諧的契合點,並有時會放大彼此的弱點。
協同矩陣的工作原理
協同強度反映了區塊鏈和 AI 屬性在特定領域中的兼容性和影響力。具體來說,它取決於兩種技術如何共同應對挑戰並提升彼此的功能。例如,在數據隱私方面,區塊鏈的不可篡改性與 AI 的數據處理能力結合,可能帶來新的解決方案。

協同矩陣的工作原理
示例 1:性能 + 去中心化(弱協同)
在去中心化網絡中,例如比特幣或以太坊,性能通常受到多種因素的制約。這些限制包括節點資源的波動性、高通信延遲、交易處理成本和共識機制的複雜性。對於需要低延遲和高吞吐量的 AI 應用(例如實時 AI 推理或大規模模型訓練),這些網絡難以提供足夠的速度和計算可靠性,無法滿足高性能的需求。
示例 2:隱私 + 去中心化(強協同)
隱私保護型 AI 技術(如聯邦學習)能夠充分利用區塊鏈的去中心化特性,在保護用戶數據的同時實現高效協作。例如, SoraChain AI 提供了一種解決方案,通過區塊鏈支持的聯邦學習,確保數據所有權不被剝奪。數據所有者可以在保留隱私的前提下,貢獻高質量的數據用於模型訓練,從而實現隱私與協作的雙贏。
該矩陣的目標是幫助行業清晰地理解 AI 和區塊鏈的交匯點,指導創新者和投資者優先考慮那些切實可行的方向,探索具有潛力的領域,同時避免陷入僅具投機意義的項目中。
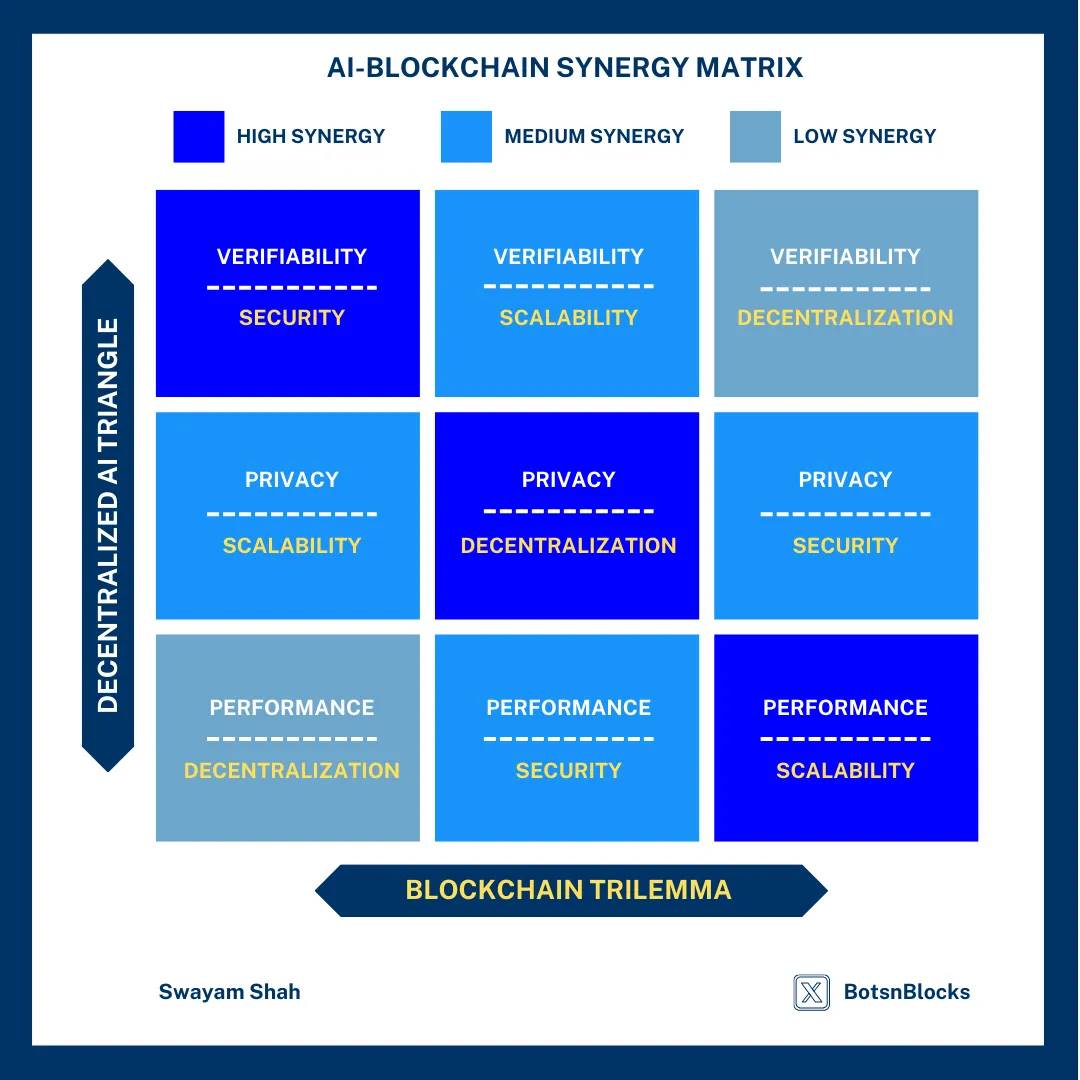
AI-區塊鏈協同矩陣
協同矩陣的兩條軸分別代表不同的屬性:一條軸是去中心化 AI 系統的三大核心特性——可驗證性、隱私和性能;另一條軸是區塊鏈的三難困境——安全性、可擴展性和去中心化。當這些屬性相互交匯時,會形成一系列協同效應,從高度契合到潛在衝突不一而足。
例如,當可驗證性與安全性結合時(高協同),可以構建出強大的系統,用於證明 AI 計算的正確性和完整性。但當性能需求與去中心化發生衝突時(低協同),分佈式系統的高開銷會顯著影響效率。此外,一些組合(如隱私與可擴展性)則處於中間地帶,既有潛力又面臨複雜的技術挑戰。
為什麼這很重要?
戰略指南針: 該矩陣為決策者、研究人員和開發者提供了明確的方向,幫助他們聚焦於高協同領域,例如通過聯邦學習確保數據隱私,或利用去中心化計算實現可擴展的 AI 訓練。
聚焦有影響力的創新與資源分配: 理解協同強度的分佈(如安全性 + 可驗證性、隱私 + 去中心化),有助於利益相關者將資源集中在高價值的領域,避免浪費在弱協同或不切實際的整合上。
引導生態系統的演進: 隨著 AI 和區塊鏈技術的不斷發展,該矩陣可以作為動態工具,用於評估新興項目,確保它們符合實際需求,而不是助長過度炒作的趨勢。
以下表格按協同強度(從強到弱)總結了這些屬性組合,並解釋了它們在去中心化 AI 系統中的實際運作方式。同時,表格還提供了一些創新項目的案例,展示了這些組合在現實中的應用場景。通過該表格,讀者可以更直觀地瞭解區塊鏈與 AI 技術的交匯點,識別出真正有影響力的領域,同時避開那些過度炒作或技術不可行的方向。

AI-區塊鏈協同矩陣:按協同強度分類 AI 和區塊鏈技術的關鍵交匯點
結論
區塊鏈與 AI 的結合蘊含著巨大的變革潛力,但未來的發展需要明確的方向和專注的努力。真正推動創新的項目,正在通過解決數據隱私、可擴展性和信任等關鍵挑戰,塑造去中心化智能的未來。例如,聯邦學習(隱私 + 去中心化)通過保護用戶數據實現協作,分佈式計算與訓練(性能 + 可擴展性)提升了 AI 系統的效率,而 zkML(零知識機器學習,可驗證性 + 安全性)則為 AI 計算的可信性提供了保障。
與此同時,我們也需要以審慎的態度看待這一領域。許多所謂的 AI 智能體實際上只是現有模型的簡單包裝,功能有限,與區塊鏈的結合也缺乏深度。真正的突破將來自那些充分發揮區塊鏈和 AI 各自優勢,並致力於解決實際問題的項目,而非單純追逐市場炒作的產品。
展望未來,AI-區塊鏈協同矩陣將成為評估項目的重要工具,能夠有效幫助決策者區分真正具有影響力的創新與無意義的噪聲。
未來十年,將屬於那些能夠結合區塊鏈的高可靠性與 AI 的變革能力,來解決實際問題的項目。例如,節能型模型訓練將顯著降低 AI 系統的能源消耗;隱私保護型協作將為數據共享提供更安全的環境;而可擴展的 AI 治理將推動更大規模、更高效的智能系統落地。行業需要聚焦這些關鍵領域,才能真正開啟去中心化智能的未來。






