撰文:Rob Toews
編譯:MetaverseHub
2024 年即將結束,來自 Radical Ventures 的風險投資家 Rob Toews 分享了他對 2025 年人工智能的 10 個預測:
01.Meta 將開始對 Llama 模型收費
Meta 是世界上開放式人工智能的標杆。在一個引人注目的企業戰略案例研究中,當 OpenAI 和谷歌等競爭對手將其前沿模型封閉源代碼並收取使用費時,Meta 卻選擇免費提供其最先進的 Llama 模型。
因此,明年 Meta 開始向使用 Llama 的公司收費這一消息,會讓許多人感到意外。
需要明確的是:我們並沒有預測 Meta 會將 Llama 完全閉源,也不意味著任何使用 Llama 模型的用戶都必須為此付費。
相反,我們預測 Meta 將對 Llama 的開源許可條款做出更多限制,這樣,在一定規模以上的商業環境中使用 Llama 的公司將需要開始付費才能使用模型。
從技術上講,Meta 如今已經在有限的範圍內做到了這一點。該公司不允許最大的公司——雲超級計算機和其他月活躍用戶超過 7 億的公司,自由使用其 Llama 模型。
早在 2023 年,Meta 首席執行官 Mark Zuckerberg 就說過:「如果你是微軟、亞馬遜或谷歌這樣的公司,而且你基本上會轉售 Llama,那麼我們應該從中獲得一部分收入。我不認為這在短期內會是一大筆收入,但從長遠來看,希望這能成為一些收入。」
明年,Meta 將大幅擴大必須付費才能使用 Llama 的企業範圍,將更多的大中型企業納入其中。

跟上大型語言模型(LLM)前沿是非常昂貴的。如果想讓 Llama 與 OpenAI、Anthropic 等公司的最新前沿模型保持一致或接近一致,Meta 每年需要投入數十億美元。
Meta 公司是世界上最大、資金最雄厚的公司之一。但它也是一家上市公司,最終要對股東負責。
隨著製造前沿模型的成本不斷飆升,Meta 公司在沒有收入預期的情況下投入如此鉅額資金來訓練下一代 Llama 模型的做法越來越站不住腳。
愛好者、學者、個人開發者和初創公司明年將繼續免費使用 Llama 模型。但 2025 年,將是 Meta 開始認真實現 Llama 盈利的一年。
02.「尺度定律」相關問題
最近幾周,人工智能領域引發討論最多的話題莫過於尺度定律(Scaling laws),以及它們是否即將終結的問題。
尺度定律在 2020 年 OpenAI 的一篇論文中首次提出,其基本概念簡單明瞭:在訓練人工智能模型時,隨著模型參數數量、訓練數據量和計算量的增加,模型的性能會以可靠且可預測的方式提高(從技術上講,其測試損失會減少)。
從 GPT-2 到 GPT-3 再到 GPT-4,令人歎為觀止的性能提升都是縮放規律的功勞。
就像摩爾定律一樣,尺度定律實際上並不是真正的法則,而只是簡單的經驗觀察。
在過去的一個月裡,一系列報告表明,主要的人工智能實驗室在持續擴大大型語言模型的規模時,正在看到遞減的回報。這有助於解釋為什麼 OpenAI 的 GPT-5 發佈一再推遲。
對尺度定律趨於平穩的最常見反駁是,測試時計算的出現開闢了一個全新的維度,可以在這一維度上追求規模擴展。
也就是說,與其在訓練期間大規模擴展計算,新的推理模型如 OpenAI 的 o3 使得在推理期間大規模擴展計算成為可能,通過使模型能夠「思考更長時間」來解鎖新的 AI 能力。
這是一個重要的觀點。測試時計算確實代表了一個新的令人興奮的擴展途徑,以及 AI 性能提升。
但關於尺度定律的另一個觀點更加重要,而且在今天的討論中被嚴重低估。幾乎所有關於尺度定律的討論,從最初的 2020 年論文開始,一直延續到今天對測試時計算的關注,都集中在語言上。但語言並不是唯一重要的數據模式。
想想機器人技術、生物學、世界模型或網絡代理。對於這些數據模式,尺度定律尚未飽和;相反,它們才剛剛開始。
實際上,這些領域中尺度定律存在的嚴格證據至今甚至尚未發表。
為這些新型數據模式構建基礎模型的初創公司——例如,生物學領域的 Evolutionary Scale、機器人技術領域的 PhysicalIntelligence、世界模型領域 WorldLabs,正試圖識別並利用這些領域的尺度定律,就像 OpenAI 在 2020 年代前半期成功利用大型語言模型(LLM)尺度定律一樣。
明年,預計這裡將取得巨大的進步。
尺度定律不會消失,它們在 2025 年將和以往一樣重要。但是,尺度定律的活動中心將從 LLM 預訓練轉移到其他模式。
03.特朗普和馬斯克可能會在 AI 方向產生分歧
美國新政府將帶來一系列關於人工智能的政策和戰略轉變。
為了預測在特朗普總統就任下人工智能的風向,另外考慮到馬斯克目前在人工智能領域的中心地位,人們可能會傾向於關注當選總統與馬斯克的密切關係。
可以想象,馬斯克可能會以多種不同的方式影響特朗普政府的人工智能相關發展。
鑑於馬斯克與 OpenAI 的深刻敵對關係,新政府在與行業接觸、制定人工智能法規、授予政府合同等方面可能會對 OpenAI 採取不太友好的立場,這是 OpenAI 今天真正擔心的一個風險。
另一方面,特朗普政府可能會更傾向於支持馬斯克自己的公司:例如,削減繁文縟節以使 xAI 能夠建立數據中心並在前沿模型競賽中取得領先;為特斯拉部署機器人出租車車隊提供快速監管批准等。
更根本的是,與許多其他被特朗普看好的科技領袖不同,馬斯克非常重視人工智能的安全風險,並因此主張對人工智能進行重大監管。
他支持加利福尼亞州有爭議的 SB1047 法案,該法案試圖對人工智能開發者施加有意義的限制。因此,馬斯克的影響力可能會導致美國對人工智能的監管環境變得更加嚴格。
然而,所有這些推測都存在一個問題。特朗普和馬斯克的親密關係終將不可避免地破裂。

正如我們在特朗普第一任政府期間一次又一次看到的那樣,特朗普盟友的平均任期,即使是看似最堅定的,都非常短暫。
特朗普第一任政府的副手中,今天仍然忠於他的寥寥無幾。
特朗普和馬斯克都是複雜、易變、不可預測的個性,他們不易合作,他們使人筋疲力盡,他們新發現的友誼到目前為止已經互惠互利,但仍處於「蜜月期」。
我們預測,在 2025 年結束之前,這種關係將會惡化。
這對人工智能世界意味著什麼?
這對 OpenAI 來說是個好消息。對於特斯拉的股東來說,這將是一個不幸的消息。而對於那些關注人工智能安全的人來說,這將是一個令人失望的消息,因為這幾乎可以確保美國政府將在特朗普執政期間對人工智能監管採取放手不管的態度。
04.AI Agent 將成為主流
想象一下,在這樣一個世界裡,你不再需要直接與互聯網互動。每當你需要管理訂閱、支付賬單、預約醫生、在亞馬遜上訂購東西、預訂餐廳或完成其他任何繁瑣的在線任務時,你只需指示人工智能助理代你完成即可。
這種「網絡代理」的概念已經存在多年。如果有這樣的產品並能正常運行,毫無疑問,它將會是一款大獲成功的產品。
然而,目前市場上還沒有一款能正常運行的通用網絡代理。
像 Adept 這樣的初創公司,即使擁有一支血統純正的創始團隊,籌集了數億美元的資金,但卻未能實現其願景。
明年將是網絡代理最終開始運行良好併成為主流的一年。語言和視覺基礎模型的不斷進步,再加上最近因新推理模型和推理時間計算而在「第二系統思維」能力方面取得的突破,將意味著網絡代理已準備好進入黃金時代。
換句話說,Adept 的想法是正確的,只是為時過早。在初創企業中,正如生活中的許多事情一樣,時機就是一切。
網絡代理將找到各種有價值的企業用例,但我們認為,網絡代理近期最大的市場機會將是消費者。
儘管最近人工智能熱度不減,但除了 ChatGPT 之外,能成為消費者主流應用的人工智能原生應用還相對較少。
網絡代理將改變這一局面,成為消費人工智能領域下一個真正的「殺手級應用」。
05.將人工智能數據中心置於太空的想法將會實現
2023 年,制約人工智能發展的關鍵物理資源是 GPU 芯片。2024 年,它變成了電力和數據中心。
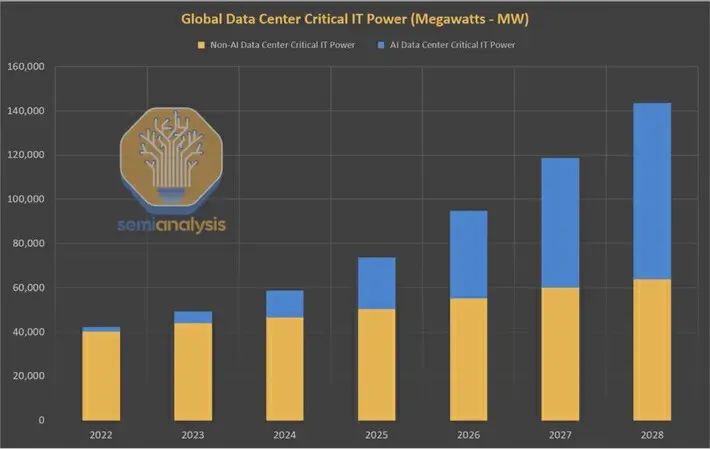
在 2024 年,幾乎沒有什麼故事能比人工智能在急於建造更多人工智能數據中心的同時對能源的巨大且快速增長的需求更受關注了。
由於人工智能的蓬勃發展,全球數據中心的電力需求在數十年持平後,預計將在 2023 年至 2026 年間翻一番。在美國,數據中心的耗電量預計到 2030 年將接近總耗電量的 10%,而 2022 年僅為 3%。
當今的能源系統根本無法應對人工智能工作負載帶來的巨大需求激增。我們的能源網和計算基礎設施這兩個價值數萬億美元的系統之間即將發生歷史性的碰撞。
作為解決這一難題的可能方案,核能在今年獲得了迅猛發展。核電在很多方面都是人工智能的理想能源:它是零碳能源,全天候可用,而且實際上取之不盡、用之不竭。
但從現實情況來看,由於研究、項目開發和監管時間較長,新能源在 2030 年代之前都無法解決這一問題。傳統的核裂變發電廠、下一代「小型模塊化反應堆」(SMR)以及核聚變發電廠都是如此。
明年,一個應對這一挑戰的非常規新想法將出現並吸引真正的資源:將人工智能數據中心置於太空中。
太空中的人工智能數據中心,乍一聽,這聽起來像是一個壞笑話,一個風險投資人試圖把太多的創業流行語結合起來。
但事實上,這可能是有道理的。
在地球上快速建設更多數據中心的最大瓶頸是獲取所需的電力。軌道上的計算集群可以全天候享受免費、無限、零碳的電力:太空中的太陽總是熠熠生輝。
將計算置於太空的另一個重要優勢是:它解決了冷卻問題。
要建立功能更強大的人工智能數據中心,最大的工程障礙之一就是在狹小的空間內同時運行許多 GPU 會變得非常熱,而高溫會損壞或毀壞計算設備。
數據中心開發人員正在採用液浸冷卻等昂貴且未經證實的方法來試圖解決這一問題。但太空是極其寒冷的,計算活動產生的任何熱量都會立即無害地消散。
當然,還有許多實際挑戰有待解決。一個顯而易見的問題是,能否以及如何在軌道和地球之間以低成本高效率地傳輸大量數據。
這是一個懸而未決的問題,但可能證明是可以解決的:可以利用激光和其他高帶寬光通信技術開展前景廣闊的工作。
YCombinator 的一家名為 Lumen Orbit 的初創公司最近籌集了 1100 萬美元,以實現這一理想:在太空中建立一個數兆瓦的數據中心網絡,用於訓練人工智能模型。
正如公司首席執行官所說:「與其支付 1.4 億美元的電費,不如支付 1 千萬美元的發射和太陽能費用。」

2025 年,Lumen 將不會是唯一認真對待這一概念的組織。
其他初創企業的競爭者也會出現。如果有一家或幾家雲計算超大規模企業也按照這種思路開展探索,也不要感到驚訝。
亞馬遜已經通過「柯伊伯計劃」(ProjectKuiper)將資產送入軌道,積累了豐富的經驗;谷歌長期以來一直在資助類似的「登月計劃」;甚至微軟對太空經濟也不陌生。
可以想象,馬斯克的 SpaceX 公司也會在這方面有所作為。
06.人工智能系統將通過「圖靈語音測試」
圖靈測試是人工智能性能最古老、最知名的基準之一。
為了「通過」圖靈測試,人工智能系統必須能夠通過書面文本進行交流,讓普通人無法分辨自己是在與人工智能互動,還是在與其他人互動。
得益於大型語言模型的顯著進步,圖靈測試在 2020 年代已成為一個解決的問題。
但書面文本並非人類交流的唯一方式。
隨著人工智能變得越來越多模態,人們可以想象一個新的、更具挑戰性的圖靈測試版本——「語音圖靈測試」。在這個測試中,人工智能系統必須能夠通過語音與人類互動,其技能和流暢度要達到與人類說話者無法區分的程度。
今天的人工智能系統還無法實現語音圖靈測試,解決這個問題將需要更多的技術進步。延遲(人類說話和人工智能回應之間的滯後)必須減少到接近零,以匹配與另一個人類交談的體驗。
語音人工智能系統必須更擅長優雅地實時處理模糊輸入或誤解,例如說話被打斷的情況。它們必須能夠參與長對話、多輪、開放式對話,同時記住討論的早期部分。
而且至關重要的是,語音人工智能代理必須學會更好地理解語音中的非語言信號。例如,如果一個人類說話者聽起來惱怒、興奮還是諷刺意味著什麼,並在自己的語音中生成這些非語言線索。
隨著我們接近 2024 年底,語音人工智能正處於一個令人興奮的轉折點,這一轉折點是由像語音到語音模型的出現這樣的根本性突破推動的。
如今,人工智能中很少有領域在技術和商業上的進步速度比語音人工智能更快。預計在 2025 年,語音人工智能的最新技術將實現飛躍。
07.自主 AI 系統將取得重大進展
數十年來,遞歸式自我完善人工智能的概念一直是人工智能界經常觸及的話題。
例如,早在 1965 年,AlanTuring 的親密合作者 I.J.Good 就寫道:「讓我們把超智能機器定義為一種能夠遠遠超越人類所有智力活動的機器,無論它多麼聰明。」
「既然設計機器是這些智力活動之一,那麼超智能機器就能設計出更好的機器;到那時,無疑會出現『智能爆炸』,人類的智能將被遠遠拋在後面。」
人工智能可以發明更好的人工智能,這是一個充滿智慧的概念。但是,即使在今天,它仍然保留著科幻小說的影子。
然而,儘管這一概念尚未得到廣泛認可,但它實際上已經開始變得更加真實。人工智能科學前沿的研究人員已經開始在構建人工智能系統方面取得切實進展,而人工智能系統本身也能構建更好的人工智能系統。
我們預測,明年這一研究方向將成為主流。

迄今為止,沿著這一思路進行研究的最顯著的公開範例是 Sakana 的「人工智能科學家」。
「人工智能科學家」於今年 8 月發佈,它令人信服地證明了人工智能系統確實可以完全自主地開展人工智能研究。
Sakana 的「人工智能科學家」本身執行了人工智能研究的整個生命週期:閱讀現有文獻、產生新的研究想法、設計實驗來測試這些想法、執行這些實驗、撰寫研究論文來報告其研究結果,然後對其工作進行同行評審。
這些工作完全由人工智能自主完成,不需要人工干預。你可以在線閱讀人工智能科學家撰寫的部分研究論文。
OpenAI、Anthropic 和其他研究實驗室正在為「自動化人工智能研究人員」這一想法投入資源,不過目前還沒有任何消息得到公開承認。
隨著越來越多的人認識到人工智能研究自動化事實上正在成為一種真正的可能性,預計 2025 年這一領域將會有更多的討論、進展和創業活動。
不過,最有意義的里程碑將是完全由人工智能代理撰寫的研究論文首次被頂級人工智能會議接受。如果論文是盲審的,會議評審人員在論文被接受之前不會知道論文是由人工智能撰寫的。
如果人工智能的研究成果明年被 NeurIPS、CVPR 或 ICML 接收,請不要感到驚訝。對於人工智能領域來說,這將是一個引人入勝、充滿爭議的歷史性時刻。
08.OpenAI 等行業巨頭將戰略重點轉向構建應用
構建前沿模型是一項艱難的工作。
它的資本密集程度令人咋舌。前沿模型實驗室需要消耗大量現金。就在幾個月前,OpenAI 籌集到了創紀錄的 65 億美元資金,而在不久的將來,它可能還需要籌集更多的資金。Anthropic、xAI 和其他公司也處於類似的境地。
轉換成本和客戶忠誠度較低。人工智能應用程序通常都是以模型無關性為目的而構建的,不同供應商的模型可以根據不斷變化的成本和性能比較進行無縫切換。
隨著最先進的開放模型(如 Meta 的 Llama 和阿里巴巴的 Qwen)的出現,技術商品化的威脅不斷迫近。像 OpenAI 和 Anthropic 這樣的人工智能領導者不可能也不會停止對構建尖端模型的投資。
但明年,為了發展利潤更高、差異化更大、粘性更強的業務線,前沿實驗室有望大力推出更多自己的應用和產品。
當然,前沿實驗室已經有了一個非常成功的應用案例:ChatGPT。
在新的一年裡,我們還能從人工智能實驗室看到哪些其他類型的第一方應用程序呢?一個顯而易見的答案是更復雜、功能更豐富的搜索應用。OpenAI 的 SearchGPT 就預示著這一點。
編碼是另一個顯而易見的類別。同樣,隨著 OpenAI 的 Canvas 產品於 10 月份首次亮相,初步的產品化工作已經開始。
OpenAI 或 Anthropic 是否會在 2025 年推出企業搜索產品?還是客戶服務產品、法律人工智能或銷售人工智能產品呢?
在消費者方面,我們可以想象一個「個人助理」網絡代理產品,或者一個旅行規劃應用,又或者是一個生成音樂的應用。
觀察前沿實驗室嚮應用層發展的最迷人之處在於,這一舉措將使它們與許多最重要的客戶直接競爭。
搜索領域的 Perplexity、編碼領域的 Cursor、在客戶服務領域德 Sierra、在法律人工智能領域的 Harvey、在銷售領域的 Clay 等等。
09.Klarna 將在 2025 年上市,但存在誇大 AI 價值的跡象
Klarna 是一家總部位於瑞典的「現購現付」服務提供商,自 2005 年成立以來已籌集了近 50 億美元的風險投資。
也許沒有哪家公司能比 Klarna 對其人工智能的應用說得更冠冕堂皇了。
就在幾天前,Klarna 首席執行官 Sebastian Siemiatkowski 告訴彭博社,該公司已經完全停止僱傭人類員工,轉而依靠生成式人工智能來完成工作。
正如 Siemiatkowski 所說:「我認為,人工智能已經可以完成我們人類所做的所有工作。」
與此類似,Klarna 公司今年早些時候宣佈,它已經推出了一個人工智能客戶服務平臺,該平臺已經將 700 名人工客服人員的工作完全自動化。
該公司還聲稱,它已經停止使用 Salesforce 和 Workday 等企業軟件產品,因為它可以簡單地用人工智能取代它們。
直截了當地說,這些說法並不可信。它們反映了人們對當今人工智能系統的能力和不足缺乏瞭解。
聲稱能夠用端到端的人工智能代理取代組織中任何職能部門的任何特定人類員工,這種說法並不靠譜。這等同於解決了通用的人類級人工智能問題。
如今,領先的人工智能初創企業正在該領域的最前沿努力構建代理系統,以實現特定的、狹義的、高度結構化的企業工作流程自動化,例如,銷售開發代表或客戶服務代理活動的子集。
即使在這些範圍狹窄的情況下,這些代理系統也還不能完全可靠地工作,儘管在某些情況下,它們已經開始很好地工作,足以在早期得到商業應用。
為什麼 Klarna 會誇大人工智能的價值?
答案很簡單。該公司計劃在 2025 年上半年上市。要想成功上市,關鍵是要有一個引人入勝的人工智能故事。
Klarna 仍然是一家不盈利的企業,去年虧損了 2.41 億美元,它可能希望自己的人工智能故事能說服公開市場的投資者,讓他們相信它有能力大幅降低成本,實現持久盈利。
毫無疑問,包括 Klarna 在內的全球每家企業都將在未來幾年內享受到人工智能帶來的巨大生產力提升。但是,在人工智能代理完全取代勞動力中的人類之前,還有許多棘手的技術、產品和組織挑戰有待解決。
像 Klarna 這樣誇大其詞的說法是對人工智能領域的褻瀆,也是對人工智能技術專家和企業家們在開發人工智能代理方面所取得的艱苦進展的褻瀆。
隨著 Klarna 準備在 2025 年公開發行股票,預計這些說法將受到更嚴格的審查和公眾的懷疑,而到目前為止,這些說法大多沒有受到質疑。如果該公司對其人工智能應用的某些描述過於誇張,也不要感到驚訝。
10.第一起真正的 AI 安全事故將會發生
近年來,隨著人工智能變得越來越強大,人們越來越擔心人工智能系統可能會開始以與人類利益不一致的方式行事,而且人類可能會失去對這些系統的控制。
舉例來說,想象一下,一個人工智能系統為了實現自己的目標,學會了欺騙或操縱人類,即使這些目標會對人類造成傷害。這些擔憂通常被歸類為「AI 安全」問題。
近年來,人工智能安全已從一個邊緣的準科幻話題轉變為一個主流活動領域。
如今,從谷歌、微軟到 OpenAI,每一個主要的人工智能參與者都為人工智能安全工作投入了大量資源。像 Geoff Hinton、Yoshua Bengio 和 Elon Musk 這樣的人工智能偶像,也開始對人工智能安全風險發表看法。
然而,到目前為止,人工智能安全問題仍完全停留在理論層面。現實世界中從未發生過真正的人工智能安全事故(至少沒有公開報道過)。
2025 年將是改變這種狀況的一年,第一起人工智能安全事件會是什麼樣的呢?
明確地說,它不會涉及終結者式的殺手機器人,它很可能不會對人類造成任何傷害。
也許人工智能模型會試圖在另一臺服務器上秘密創建自己的副本,以保存自己(稱為自我過濾)。
又也許人工智能模型會得出這樣的結論:為了最好地推進它被賦予的目標,它需要向人類隱瞞自己真實的能力,故意在性能評估中表現低調,規避更嚴格的審查。
這些例子並非牽強附會。阿波羅研究公司本月早些時候發表的重要實驗表明,在特定的提示下,當今的前沿模型能夠做出這種欺騙行為。
同樣,《人類學》最近的研究也表明,LLMs 具有令人不安的「偽對齊」能力。

我們預計,這起首例人工智能安全事件將在造成任何實際傷害之前被發現並消除。但對於人工智能界和整個社會來說,這將是一個大開眼界的時刻。
它將明確一件事:在人類面臨來自無所不能的人工智能的生存威脅之前,我們需要接受一個更平凡的現實:我們現在與另一種形式的智能共享我們的世界,這種智能有時可能是任性的、不可預測的和欺騙性的。