

人工智能剛剛迎來了自己的“斯普特尼克時刻”。
上週,中國大型語言模型(LLM)初創公司 DeepSeek 在低調運營後正式亮相,令美國市場大感意外。
DeepSeek 比 ChatGPT 等其他 LLM 更快、更智能、資源佔用更少。無論是內容創作還是基礎查詢,它的速度都遠超前代模型。更重要的是,該模型具備“自主思考”能力,因此據稱其訓練成本比之前的模型更低。
聽起來很棒,對吧?但如果你是一家押注於美國 AI 產業的科技公司,那就不一定了。市場在週一對這一進展作出了劇烈反應。科技股集體暴跌,市值蒸發超過 1 萬億美元——相當於比特幣市值的一半。其中,英偉達(Nvidia)股價單日重挫 17%,市值損失 5890 億美元,創下美國股市歷史上最大單日市值損失紀錄。英偉達及其他科技股的下跌拖累納斯達克綜合指數當日下跌 3.1%。
且市場的拋售並未侷限於科技股。能源股同樣遭受重創,自然氣、核能和可再生能源企業 Vistacorp(在德克薩斯州有大規模業務)股價暴跌約 30%,而正在重啟三里島核電站以為微軟數據中心供能的 Constellation Energy 股價也下跌超過 20%。
市場對 DeepSeek 的擔憂很簡單:LLM 計算效率的提升速度遠超預期,其直接後果是市場對 GPU、數據中心及能源的需求減少。而巧合的是,這一模型爆紅的時間點正好與前總統特朗普宣佈 5000 億美元的“星門計劃”(Project Stargate)相隔數日,該計劃旨在加速美國 AI 基礎設施建設。
對於 DeepSeek 的影響,專家們的看法不一。一方面,有人認為這可能是 AI 行業的重大利好,而非災難——就像內燃機效率的提升並未減少汽車需求,反而推動了行業增長。
另一方面,社交媒體上流傳的關於 DeepSeek 訓練成本的數據可能具有誤導性。儘管新模型確實降低了成本,但遠沒有傳言中的那麼誇張。
認識 DeepSeek
DeepSeek 由中國工程師梁文峰(Liang Wenfeng)於 2023 年 5 月創立,並獲得對沖基金 High-Flyer 的投資,該基金也是梁文峰在 2016 年創辦的公司。DeepSeek 於 1 月 20 日開源了首個模型 DeepSeek-R1,並在上週末迅速走紅網絡。
DeepSeek-R1 具備多項獨特功能,使其與其他模型區別開來,包括:
- 語義理解:DeepSeek 具備“讀懂弦外之音”的能力。它採用“語義嵌入”(semantic embeddings)技術,可以推測查詢背後的意圖和更深層的語境,從而提供更細緻入微的回答。
- 跨模態搜索:它能夠解析並交叉分析不同類型的媒體內容,意味著可以同時處理文本、圖片、視頻、音頻等多種數據。
- 自動適應:DeepSeek 具備持續學習和自我訓練的能力——輸入的數據越多,它的適應性就越強。這可能使其在不需要頻繁重新訓練的情況下依然保持可靠性。換句話說,我們可能不再需要像以往那樣定期輸入新數據,因為模型可以在運行過程中自主學習和調整。
- 海量數據處理:據稱,DeepSeek 可處理 PB 級(Petabyte)數據,使其能夠應對其他 LLM 可能難以處理的龐大數據集。
- 更少的參數:DeepSeek-R1 總參數量為 671 億,但每次推理僅需 370 億個參數,而 ChatGPT 每次推理所需的參數量估計在 5000 億到 1 萬億之間(OpenAI 並未公開具體數字)。參數是指模型在訓練過程中用於引導和優化學習的輸入及組件。
除了上述特點外,DeepSeek 最吸引人的地方在於其自我調整和自主學習的能力。這一特性不僅節省時間和資源,還為 AI 代理的發展奠定了基礎,使其能夠應用於機器人、自主駕駛、物流等領域的自治 AI 系統。
Pastel 創始人兼 CEO Jeffrey Emmanuel 在其文章《做空英偉達的理由》(The Short Case for Nvidia Stock)中對此突破做出了精彩總結:
“通過 R1,DeepSeek 基本上攻克了 AI 領域的一座‘聖盃’:讓模型在沒有大規模監督數據集的情況下實現逐步推理。他們的 DeepSeek-R1-Zero 實驗展示了一項驚人的成就:通過純強化學習和精心設計的獎勵函數,他們成功使模型完全自主地發展出複雜的推理能力。這不僅僅是解決問題——模型能夠自然地生成長鏈推理過程,自我驗證其工作,並在處理更困難的問題時分配更多計算資源。”
DeepSeek 讓華爾街恐慌的真正原因
DeepSeek 確實是 ChatGPT 的增強版,但這並不是上週讓金融界震驚的真正原因——真正讓投資者恐慌的是該模型的訓練成本。
DeepSeek 團隊自稱,該模型的訓練成本僅為560 萬美元,但這一數據的可信度存疑。
從 GPU 小時(即每塊 GPU 每小時運行的計算成本)來看,DeepSeek 團隊聲稱,他們使用了 2,048 塊英偉達 H800 GPU,總計 278.8 萬 GPU 小時,完成了預訓練、上下文擴展及後訓練,計算成本約 2 美元 /GPU 小時。
相比之下,OpenAI CEO 山姆·奧特曼(Sam Altman)表示,GPT-4 的訓練成本超過 1 億美元。GPT-4 的訓練週期為 90 至 100 天,使用了 25,000 塊英偉達 A100 GPU,總計 5,400 萬至 6,000 萬 GPU 小時,每小時計算成本約 2.50 至 3.50 美元 /GPU 小時。
因此,DeepSeek 訓練成本的“標價”與 OpenAI 相比,直接引發了市場的恐慌性拋售。投資者紛紛自問:如果 DeepSeek 能以 OpenAI 訓練成本的一小部分打造出更強大的 LLM,那麼我們為何還要在美國斥資數十億美元建設 AI 計算基礎設施?這些所謂的“必要”算力投資,真的有意義嗎?AI/HPC 數據中心的投資回報率(ROI)和盈利模式又將何去何從?
下方的圖表直觀展示了訓練 DeepSeek 與 ChatGPT 所需的數據中心每 GW 收入情況,進一步突出了這一問題。
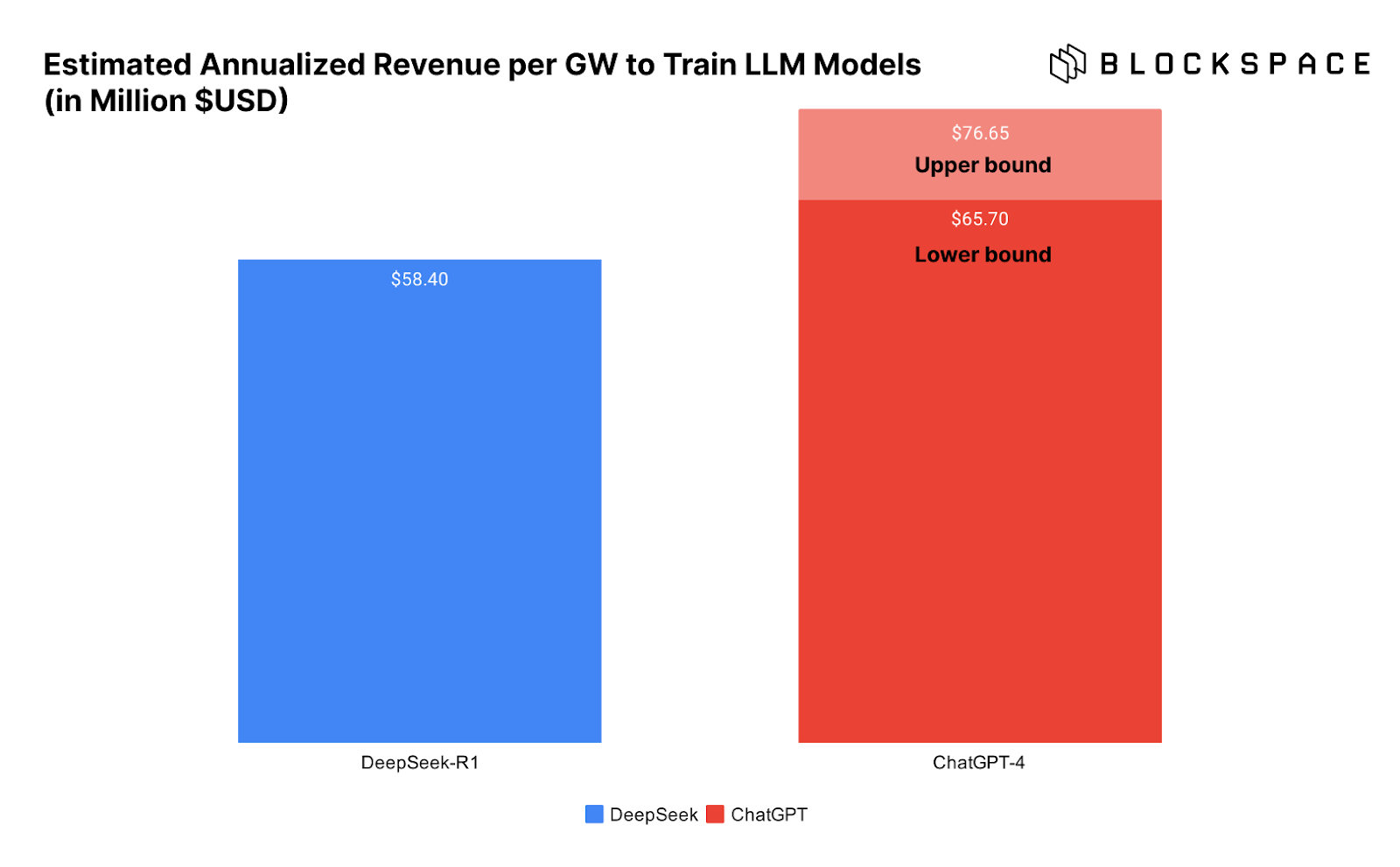
問題在於,我們並不能確定 DeepSeek 真的以如此低的成本完成了模型訓練。
DeepSeek 訓練成本真的如此之低嗎?
然而,DeepSeek 真的只花了 560 萬美元訓練模型嗎?不少業內人士對此表示懷疑,而且理由充分。
首先,在 DeepSeek 的技術白皮書中,團隊明確表示,“所述訓練成本僅涵蓋 DeepSeek-V3 的正式訓練,不包括此前在模型架構、算法或數據上的研究和消融實驗成本。”換句話說,560 萬美元只是最終的訓練成本,而在模型優化過程中,還有更多資金投入。
因此,Atreides Management 首席投資官(CIO)加文·貝克(Gavin Baker)直言,“560 萬美元的成本數據極具誤導性。”
“換句話說,如果一個實驗室已經在前期研究上投入了數億美元,並且擁有更大規模的計算集群,那麼確實可以用 560 萬美元完成最終訓練。但 DeepSeek 顯然不止使用了 2,048 塊 H800 GPU——他們早期的一篇論文就提到了一個由 10,000 塊 A100 組成的集群。因此,一個同樣優秀的團隊如果想要從零開始,僅憑 2,000 塊 GPU 訓練出類似 R1 的模型,根本不可能只花 560 萬美元。”
此外,貝克指出,DeepSeek 採用了一種名為“知識蒸餾”(distillation)的方法,從 ChatGPT 汲取經驗來訓練自己的模型。
“DeepSeek 很可能無法在沒有 GPT-4o 和 GPT-4o1 完全開放訪問的情況下完成訓練。”
DeepSeek、能源消耗與傑文斯悖論
儘管 DeepSeek 訓練成本僅為 560 萬美元的說法存疑,但加文·貝克(Gavin Baker)指出,該模型的多項突破——如自學習、參數更少等——確實使其訓練和推理(即 AI 運行成本,行業術語稱之為“推理”)變得更加低廉。
貝克聲稱,使用 DeepSeek-R1 的成本比 ChatGPT 的 o1 版本低 93%,每次 API 調用的費用大幅下降。儘管 93% 這一具體數字是否準確仍有爭議,但關鍵在於,DeepSeek 的推理成本更低,甚至可以在 Mac Studio Pro 等本地硬件上運行。
這才是 DeepSeek 的真正突破——AI 變得更加經濟可用。正如一位匿名評論者所說,這感覺就像微軟開源了互聯網瀏覽器,從而徹底摧毀了 Netscape 的付費訪問模式。
DeepSeek 徹底打開了 AI 的新模式,使 AI 發展進入了一個全新的競爭階段——“現在的競爭重點已經從 AI 訓練轉向 AI 推理”,借用 Chamath Palihapitiya 的話來說。
AI 驅動的數據中心與電力行業熱潮何去何從?
正如我們在文章前面所提到的,更高效的發動機是否減少了汽油需求,或者對依賴汽車的行業造成了負面影響?
傑文斯悖論(Jevons Paradox)認為,當技術進步提升了資源利用效率時,資源本身的需求反而會上升,因為更低的成本會促使更廣泛的應用。比特幣礦工對此深有體會——儘管 ASIC 礦機的能效逐年提升,但比特幣網絡的算力仍然持續增長。
從目前來看,市場迎來了一個更強大的競爭者,但遊戲規則並未改變。如果 AI 推理和訓練成本下降(而這本就是必然趨勢),那麼它將解鎖更多應用場景,並進一步推動 AI 產業需求增長。





