

編譯:深潮 TechFlow
在剛剛過去的週末,我們看到了未來的一些端倪。長期以來,我一直在探討 AI 的兩場重要革命:自主智能體 (Autonomous Agents) 的崛起,以及自 OpenAI 推出 o1 模型以來強大推理系統 (Reasoners) 的發展。這兩條技術路徑如今終於走向融合,催生出了一種令人驚歎的成果——AI 系統不僅能夠以人類專家的深度和細緻程度開展研究,還能以機器般的速度完成。這一融合的代表便是 OpenAI 的 Deep Research,它為我們描繪了未來的圖景。然而,要理解這一切為何重要,我們需要從基礎說起:推理系統與智能體。
推理系統 (Reasoners)
過去幾年中,當你使用聊天機器人時,它的工作方式通常非常簡單:你輸入問題後,系統會逐字(或更準確地說是逐 Token)生成回應。由於 AI 只能在生成這些 Token 的同時“思考”,研究人員開發了許多技巧來提升其推理能力。例如,通過提示 AI “在回答之前逐步推理”,這被稱為鏈式思維提示 (Chain-of-Thought Prompting),顯著提高了 AI 的表現。
推理系統的出現將這一過程自動化。在回答問題之前,系統會先生成“思考 Token”(即推理步驟),然後再給出最終答案。這種方法帶來了兩個重要的突破。
首先,AI 公司可以通過優秀問題解決者的示例訓練推理系統,從而讓 AI 的“思考”過程更加高效。這種訓練方式能夠生成比人類提示更高質量的推理鏈,使推理系統能夠解決更復雜的問題,尤其是在數學和邏輯等傳統聊天機器人表現不佳的領域。
其次,推理系統的一個顯著特點是:它“思考”得越久,答案的質量就越高(儘管隨著時間延長,改進的速度會逐漸減緩)。這一點尤為重要,因為過去提升 AI 性能的唯一方法是訓練更大規模的模型,而這需要大量的數據和資金。而推理系統表明,只需在回答問題時(即推理時計算)讓 AI 生成更多推理步驟,就能顯著提升性能,無需增加模型訓練資源。
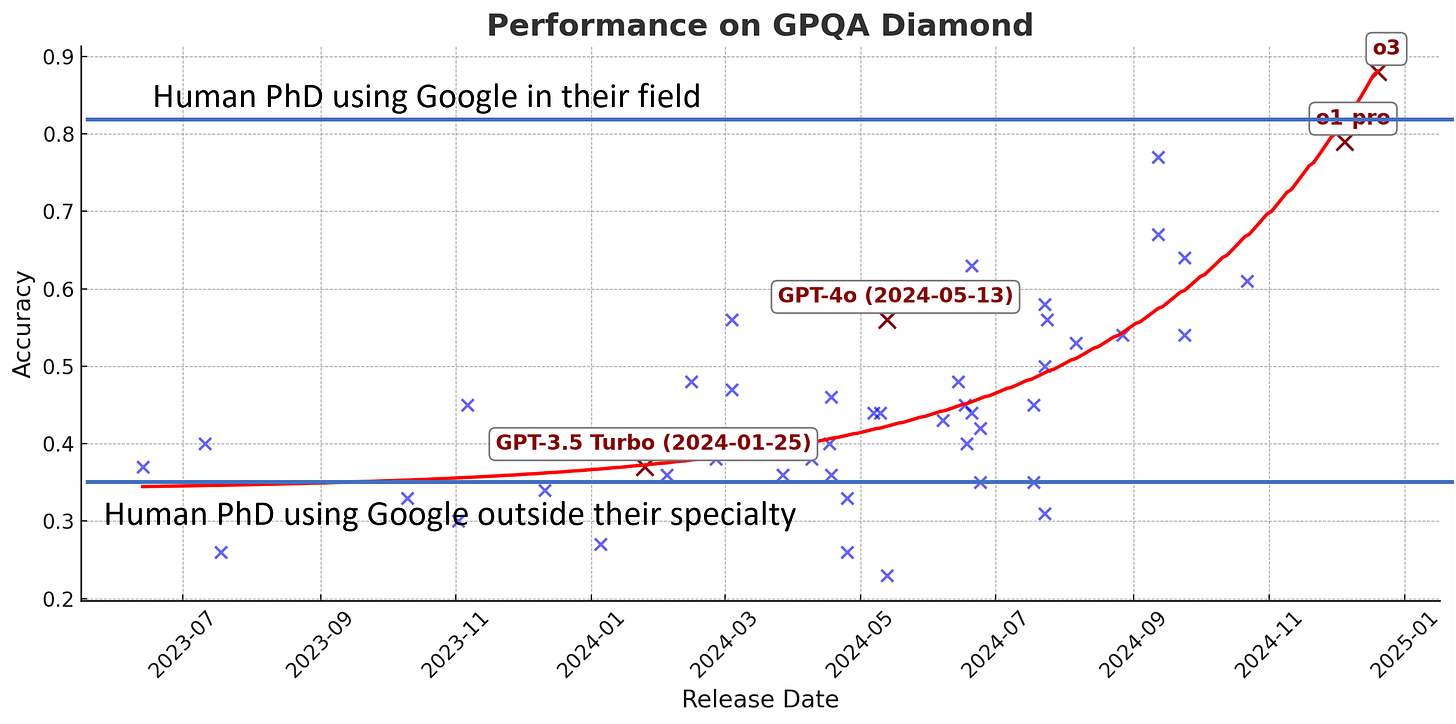
研究生級別的無谷歌問答測試 (GPQA) 是一組多選題,旨在評估 AI 的推理能力。即使是擁有互聯網訪問權限的博士生,在非專業領域的正確率也僅為 34%,而在專業領域則可達到 81%。這一測試展示了推理模型如何加速 AI 能力的提升(數據來源)。
由於推理系統仍是新興技術,其能力正在快速提升。僅在幾個月內,我們就見證了 OpenAI 的 o1 系列向新 o3 模型的顯著躍升。同時,中國的 DeepSeek r1 通過創新方法提升性能並降低成本,而 Google 也推出了其首個推理系統。這僅僅是開始——未來,我們將看到更多強大的推理系統問世,並且可能比預期更快。
智能體 (Agents)
關於 AI 智能體的定義,專家們至今尚未達成一致。不過,我們可以簡單地將其理解為“被賦予目標並能夠自主完成目標的 AI 系統”。目前,各大 AI 實驗室正在激烈競爭,試圖研發出通用型智能體——一種可以應對任何任務的系統。我曾提到過一些早期的例子,比如 Devin 和 Claude,它們具備一定的計算機操作能力。而最近,OpenAI 剛剛推出了 Operator,這或許是迄今為止最完善的通用型智能體。
以下視頻(經過 16 倍速處理)展示了通用型智能體的巨大潛力以及當前的侷限性。我給 Operator 下達了一個任務:閱讀我在 OneUsefulThing 平臺上的最新 Substack 帖子,然後訪問 Google ImageFX,設計一張合適的圖片,下載後交給我發佈。最初,Operator 的表現非常出色——它準確地找到我的網站,閱讀文章,導航到 ImageFX(期間暫停讓我輸入登錄信息),併成功創建了一張圖片。然而,問題接踵而至,主要體現在兩個方面:一是 Operator 被 OpenAI 的安全限制阻止下載文件,二是在任務執行過程中出現了混亂。智能體嘗試了各種解決方法,比如複製到剪貼板、生成直接鏈接,甚至深入到網站的源代碼。然而,這些嘗試無一成功——有些因為 OpenAI 的瀏覽器限制,有些則因為智能體對任務的理解產生了偏差。觀察這一執著卻最終失敗的嘗試過程,不僅揭示了當前系統的侷限性,也引發了關於智能體在現實世界中遇到障礙時將如何應對的思考。
雖然 Operator 暴露了通用型智能體的不足,但這並不意味著智能體毫無價值。目前,專注於特定任務的窄領域智能體已經展現出顯著的經濟價值。這些智能體依託當前的大語言模型 (LLM) 技術,在特定領域內能夠實現令人驚歎的成果。例如,OpenAI 的新產品 Deep Research 就是一個專注型智能體的典範。
深度研究 (Deep Research)
OpenAI 的 Deep Research(需注意,不要與 Google 的 Deep Research 混淆,後續會詳細介紹)是一個專注於研究領域的窄領域智能體。它基於 OpenAI 尚未發佈的 o3 推理系統 (Reasoner),並配備了專用工具和功能。這是我近期見過的最令人印象深刻的 AI 應用之一。
為了展示其能力,我為它設置了一個主題:在初創公司發展過程中,應該在何時停止探索並開始擴展?這是一個在我研究領域內頗具技術性且爭議性的問題。我要求 Deep Research 調查相關的學術研究,重點分析高質量論文和隨機對照試驗 (RCTs),並處理其中可能存在的定義爭議,以及常識與研究結論之間的矛盾。最終,它需要為研究生級別的討論呈現一份詳盡的結果。

在任務開始時,AI 提出了幾個非常有見地的問題,我也進一步明確了我的需求。隨後,OpenAI 的 o3 推理系統 (Reasoner) 開始工作。在整個過程中,你可以清楚地看到它的進展以及“思考”過程。以下展示了幾個關鍵的樣本,值得花點時間仔細看看。你會發現,這個 AI 系統的行為非常接近一位研究人員:它會主動探索發現,深入挖掘那些“引起它興趣”的內容,並嘗試解決問題(例如尋找繞過付費牆文章的方法)。整個過程持續了大約五分鐘。
最終,我收到了一份十三頁、三千七百七十八字的草稿,包含六個引用和一些額外的參考文獻。整體質量令人滿意,儘管引用來源的數量還有提升空間。這篇文章成功地將複雜且矛盾的概念有機地整合在一起,還發現了一些我未曾預料到的新聯繫。它只引用了高質量的學術來源,並且引用中包含了準確的引文內容。儘管我無法完全保證其中的內容都無誤(但我並未發現明顯錯誤),但如果這是一位剛入門的博士生的作品,我會對其表現感到滿意。以下是幾個摘錄片段,足以說明為何我對它的表現如此印象深刻(完整結果參考此處)。

這次 AI 的引用質量標誌著一個顯著的進步。引用不再是常見的 AI“幻覺”或錯誤引用的論文,而是合法的、高質量的學術來源,包括我同事 Saerom (Ronnie) Lee 和 Daniel Kim 的開創性研究。當我點擊引用鏈接時,它們不僅指向相關論文,還經常直接跳轉到具體的高亮引文部分。儘管當前仍存在一些限制——AI 只能訪問它在幾分鐘內能夠找到和閱讀的內容,而付費牆文章仍然無法獲取——但這已經代表了 AI 在處理學術文獻方面的一次根本性飛躍。首次,一個 AI 不僅僅是總結研究,而是以接近人類學術研究的方式主動參與其中。
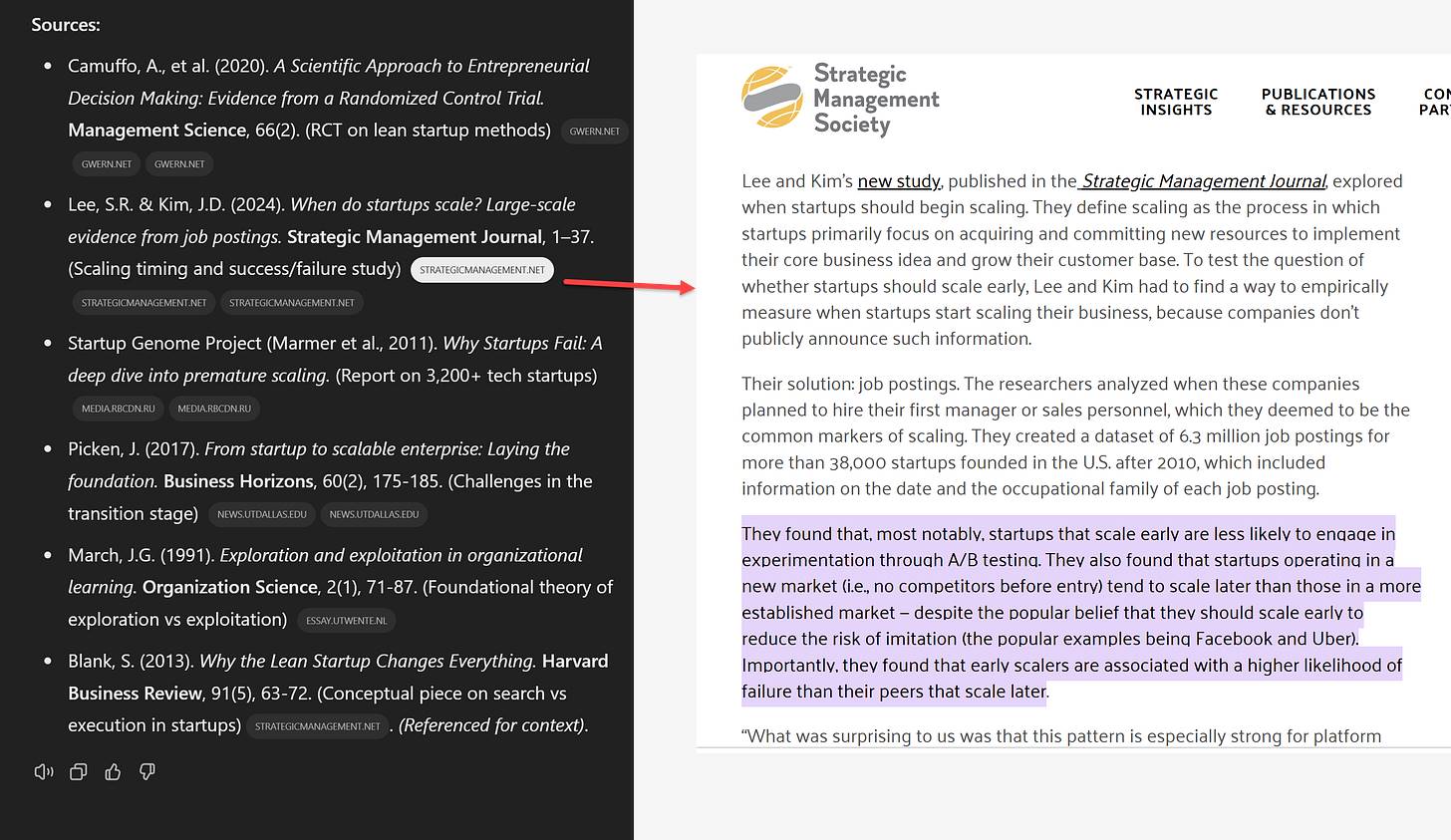
值得注意的是,Google 上個月也推出了一個同名產品 Deep Research(無奈嘆氣)。Google 的系統提供了更多的引用,但引用來源的質量參差不齊,常常是各種網站的混合體(無法訪問付費信息和書籍對所有智能體來說都是一個難題)。與 OpenAI 的研究智能體不同,Google 的系統似乎一次性收集所有文檔,而不是通過探索式發現逐步獲取。此外,由於 Google 的產品目前基於舊版 Gemini 1.5 模型(不具備推理能力),其總結內容更加表面化,儘管整體上仍然紮實且沒有明顯錯誤。可以說,它的表現更像是一個非常優秀的本科生的作品。

為了更直觀地理解這一點:OpenAI 和 Google 的研究智能體都能完成通常需要人類數小時才能完成的工作。區別在於,OpenAI 的系統達到了接近博士研究水平的分析,而 Google 的系統則更像是優秀本科生的作品。在 OpenAI 的官方聲明中,他們提出了一些大膽的主張,並用圖表展示了他們的智能體可以處理 15% 的高經濟價值研究項目以及 9% 的極高價值研究項目。雖然這些數據的具體方法論並未公開,值得保留一定的懷疑態度,但從我的實際使用體驗來看,這些說法並非完全誇大。Deep Research 確實能夠在幾分鐘內完成複雜且有價值的分析,而不是耗費數小時。考慮到技術進步的速度,我相信 Google 不會讓這一差距維持太久。在未來幾個月中,我們可能會看到研究智能體的能力迅速提升。
技術協同發展
從當前的發展趨勢來看,各大 AI 實驗室正在構建的技術不僅是簡單地拼接在一起,而是通過相互作用實現更高的效率。推理系統 (Reasoners) 提供了強大的邏輯分析能力,而智能體系統則賦予了這些推理能力以實際行動的能力。目前,我們正處於窄領域智能體的時代,例如 Deep Research,它們專注於特定任務,因為即使是現階段最先進的推理系統,也尚未達到通用型自主能力的要求。然而,“窄領域”並不意味著受限——這些系統已經能夠完成曾經需要高薪專家團隊或專業諮詢公司才能完成的複雜工作。
當然,這並不意味著專家和諮詢公司會因此被取代。相反,隨著他們從直接執行工作轉向協調和驗證 AI 系統的成果,他們的專業判斷力將變得更加重要。但 AI 實驗室的目標遠不止於此。他們希望通過更強大的模型,破解通用型智能體的難題,使其超越窄領域任務,成為真正的自主數字勞動力。這些智能體不僅能夠自主瀏覽網絡,還可以處理多種形式的數據(如文本、圖像和音頻),並在現實世界中採取有意義的行動。儘管 Operator 的表現表明我們還未完全達到這一目標,但 Deep Research 的成功已經顯示,我們正在朝著這一方向穩步前進。






