作者:衡宇 發自 凹非寺

圖片來源:由無界AI生成
剛剛,階躍星辰聯合吉利汽車集團,開源了兩款多模態大模型!
新模型共2款:
全球範圍內參數量最大的開源視頻生成模型Step-Video-T2V
行業內首款產品級開源語音交互大模型Step-Audio
多模態卷王開始開源多模態模型,其中Step-Video-T2V採用的還是最為開放寬鬆的MIT開源協議,可任意編輯和商業應用。
(老規矩,GitHub、抱抱臉、魔搭直通車可見文末)
在兩款大模型的研發過程中,雙方在算力算法、場景訓練等領域優勢互補,“顯著增強了多模態大模型的性能表現”。
從官方公佈的技術報告來看,這次開源的兩款模型在Benchmark中表現優秀,性能超過國內外同類開源模型。
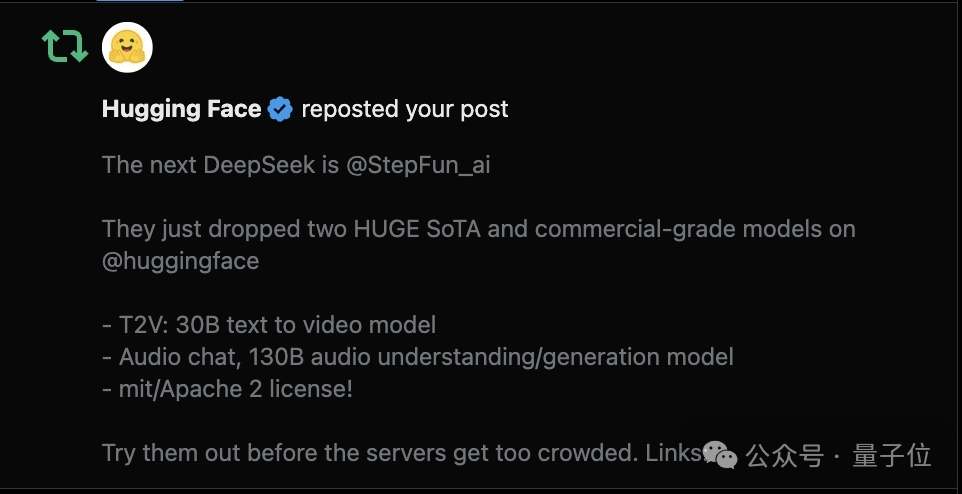
抱抱臉官方也轉發了中國區負責人給予的高度評價。
劃重點,“The next DeepSeek”、“HUGE SoTA”。
哦,是嗎?
那量子位可要在本篇文章中掰開技術報告+一手實測,看看它們是否名副其實。

量子位求證,目前,本次2款新的開源模型都已接入躍問App,人人可以體驗。
多模態卷王首次開源多模態模型
Step-Video-T2V和Step-Audio,是階躍星辰首次開源的多模態模型。
Step-Video-T2V
先來看看視頻生成模型Step-Video-T2V。
它的參數量達到30B,是目前已知全球範圍內參數量最大的開源視頻生成大模型,原生支持中英雙語輸入。

官方介紹,Step-Video-T2V共有4大技術特點:
第一,可直接生成最長204幀、540P分辨率的視頻,確保生成的視頻內容具有極高的一致性和信息密度。
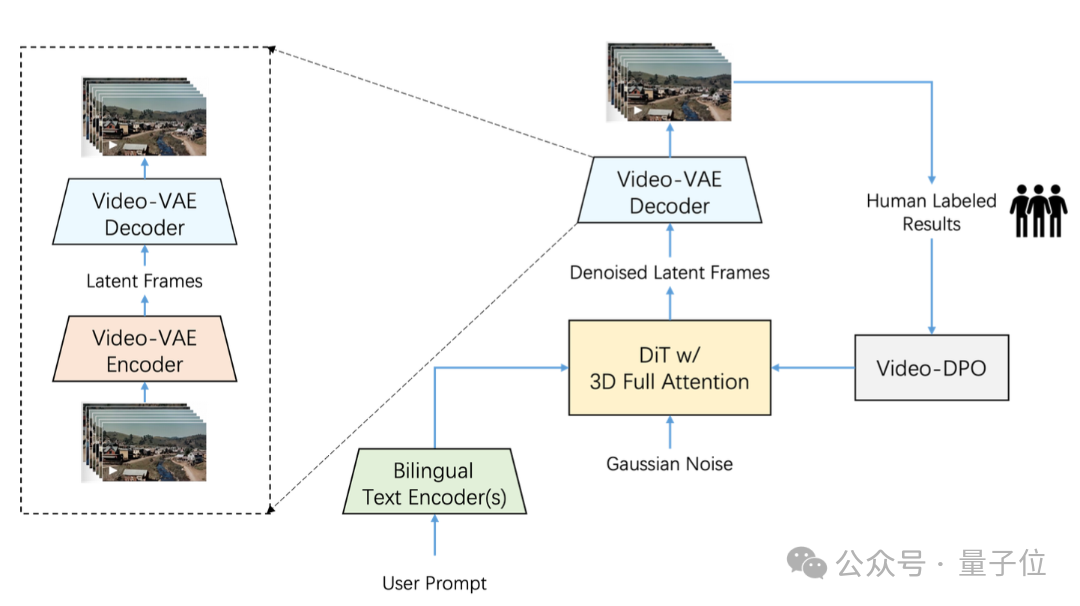
第二,針對視頻生成任務設計並訓練了高壓縮比的Video-VAE,在保證視頻重構質量的前提下,能夠將視頻在空間維度壓縮16×16倍,時間維度壓縮8倍。
當下市面上多數VAE模型壓縮比為8x8x4,在相同視頻幀數下,Video-VAE能額外壓縮8倍,故而訓練和生成效率都提升64倍。
第三,針對DiT模型的超參設置、模型結構和訓練效率,Step-Video-T2V了進行深入的系統優化,確保訓練過程的高效性和穩定性。
第四,詳細介紹了預訓練和後訓練在內的完整訓練策略,包括各階段的訓練任務、學習目標以及數據構建和篩選方式。
此外,Step-Video-T2V在訓練最後階段引入Video-DPO(視頻偏好優化)——這是一種針對視頻生成的RL優化算法,能進一步提升視頻生成質量,強化生成視頻的合理性和穩定性。
最終效果,是讓所生成視頻中的運動更流暢、細節更豐富、指令對齊更準確。
為了全面評測開源視頻生成模型的性能,階躍此次一併發佈了針對文生視頻質量評測的新基準數據集Step-Video-T2V-Eval。
該數據集也一併開源了~
它包含128條源於真實用戶的中文評測問題,旨在評估生成視頻在11個內容類別上的質量,包括運動、風景、動物、組合概念、超現實等等。
Step-Video-T2V-Eval在其上的評測結果,見下圖:
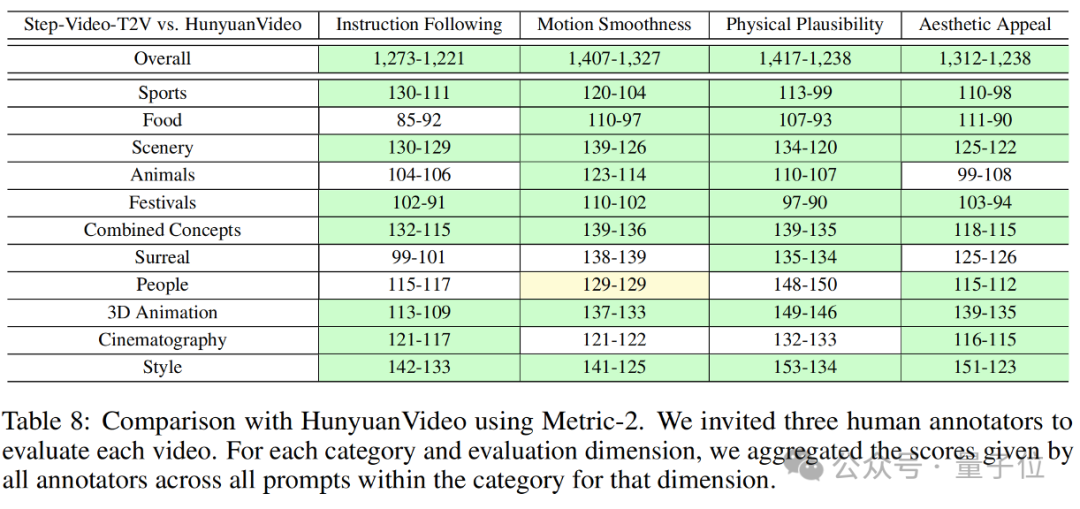
可以看到,Step-Video-T2V在指令遵循、運動平滑性、物理合理性、美感度等方面,表現均超越此前最佳的開源視頻模型。
這意味著,整個視頻生成領域,都可以基於這個新的最強基礎模型來進行研究與創新。
而實際效果方面,階躍官方介紹:
生成效果,Step-Video-T2V在複雜運動、美感人物、視覺想象力、基礎文字生成、原生中英雙語輸入和鏡頭語言等方面具備強大的生成能力,且語義理解和指令遵循能力突出,能夠高效助力視頻創作者實現精準創意呈現。
還等什麼?實測走起——
按照官方介紹的順序,第一關,測試Step-Video-T2V能否hold住複雜運動。
之前的視頻生成模型,在生成芭蕾/國標/中國舞、藝術體操、空手道、武術等各類複雜性運動片段中,總會出現奇奇怪怪的畫面。
比如突然冒出來的第三條腿,交叉融合的雙臂等等,怪嚇人的。
針對這類情況,我們進行定向測試,丟給Step-Video-T2V一段prompt:
室內羽毛球場,平視視角,固定鏡頭記錄了一段男子打羽毛球的場景。一名身穿紅色短袖、黑色短褲的男子,手持羽毛球拍,站在綠色的羽毛球場地中央。球網橫跨場地,將場地分為兩部分。男子揮拍擊球,將羽毛球擊向對面。光線明亮均勻,畫面清晰。
場景、人物、鏡頭、光線、動作,統統吻合。
生成畫面中含「美感人物」,則是量子位對Step-Video-T2V發起的第二關挑戰。
講道理,現在文生圖模型生成真人圖片的level,在靜態、局部細節上,絕對是可以以假亂真的。
但視頻生成時,人物一旦動起來,仍存在可辨識的物理或邏輯瑕疵。
而Step-Video-T2V的表現嘛——
Prompt:一位男性,身穿黑色西裝,搭配深色領帶和白色襯衫,臉部帶有傷痕,表情凝重。特寫鏡頭。
“沒什麼AI感。”
這是量子位編輯部同學們傳閱一遍過後,對視頻中小帥的一致評價。
既是五官端正,皮膚紋理真實,臉上傷痕清晰可見的那種“沒什麼AI感”。
也是逼真但主人公並沒出現眼神空洞、表情僵硬的那種“沒什麼AI感”。
上面兩關,都讓Step-Video-T2V保持在固定鏡頭機位。
那麼,推拉搖移,表現如何?
第三關,考驗Step-Video-T2V對運鏡的掌握,比如推拉搖移,旋轉、跟隨。
要它旋轉,它就旋轉:
還挺不賴!可以肩扛斯坦尼康,去片場當運鏡大師了(不是)。
一番測試下來,生成效果給出答案:
Step-Video-T2V確如評測集結果那樣,在語義理解和指令遵循能力突出。
甚至基礎文字生成也輕鬆拿捏:
Step-Audio
同時開源的另一款模型Step-Audio,是行業內首個產品級的開源語音交互模型。
在階躍自建並開源的多維度評估體系StepEval-Audio-360基準測試上,Step-Audio在邏輯推理、創作能力、指令控制、語言能力、角色扮演、文字遊戲、情感價值等維度,均取得最佳成績。
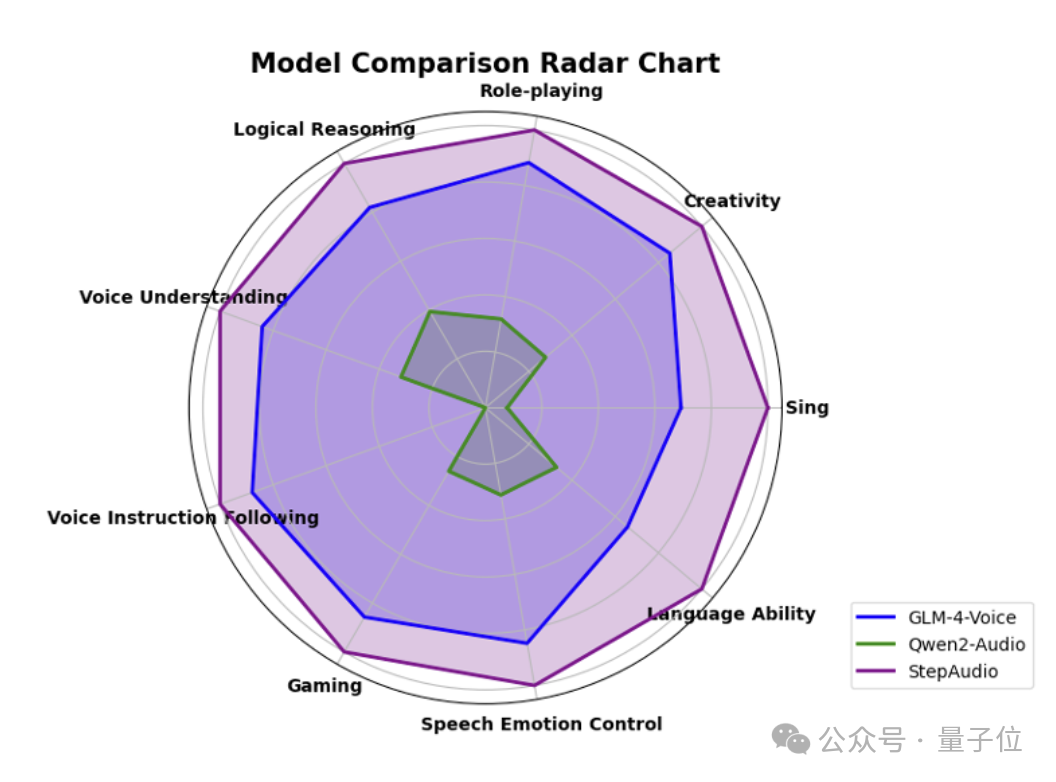
在LlaMA Question、Web Questions等5大主流公開測試集中,Step-Audio性能均超過了行業內同類型開源模型,位列第一。
可以看到,它在HSK-6(漢語水平考試六級)評測中的表現尤為突出。
實測如下:
階躍團隊介紹,Step-Audio能夠根據不同的場景需求生成情緒、方言、語種、歌聲和個性化風格的表達,能和用戶自然地高質量對話。
同時,由其生成的語音不僅具有逼真自然、高情商等特徵,還能實現高質量的音色復刻並進行角色扮演。
總之,影視娛樂、社交、遊戲等行業場景下應用需求,Step-Audio包讓你一整個大滿足的。
階躍開源生態,正在滾雪球
怎麼說呢,就一個字:卷。
階躍是真卷啊,尤其是在自家拿手好戲多模態模型方面——
旗下Step系列中的多模態模型,自打出生以來,就是國內外各大權威評測集、競技場等的第一名常客。
只看最近3個月,都已經數次勇奪榜首。
去年11月22日,大模型競技場最新榜單,多模態理解大模型Step-1V上榜,總分與Gemini-1.5-Flash-8B-Exp-0827持平,位列視覺領域中國大模型第一。
今年1月,國內大模型評估平臺“司南”(OpenCompass)多模態模型評測實時榜單,剛出爐的Step-1o系列模型拿下第一。
同日,大模型競技場最新榜單,多模態模型Step-1o-vision拿下國內視覺領域大模型第一。

其次,階躍的多模態模型不僅性能好、質量佳,研發迭代頻率也很高——
截至目前,階躍星辰已經先後發佈了11款多模態大模型。
上個月,6天連發6模型,覆蓋語言、語音、視覺、推理全賽道,進一步做實多模態卷王稱號。
這個月又開源2款多模態模型。
只要穩定住這個節奏,就能繼續且持續地證明自己「全家桶級多模態玩家」的地位。
憑藉強大的多模態實力,2024年開始,市場和開發者們就已經認可並廣泛接入階躍API,形成了龐大的用戶基礎。
大眾消費品,如茶百道,就讓全國數千家門店接入多模態理解大模型Step-1V,探索大模型技術在茶飲行業的應用,進行智能巡檢、AIGC 營銷。
公開數據顯示,平均每天上百萬杯茶百道茶飲在大模型智能巡檢的守護下送到消費者手中。
而Step-1V平均每天能夠為茶百道督導員節約75%的自檢核驗時間,為茶飲消費者提供了更加安心和優質的服務。
獨立開發者,如網紅AI應用“胃之書”、AI心理療愈應用“林間聊愈室”在對國內大部分模型做過AB測試後,最終都選擇了階躍多模態模型API。
(小聲:因為用它,付費率最高)
具體數據顯示,2024年下半年,階躍多模態大模型API的調用量增長超45倍。

再說到,此次開源,開源的就是階躍自家最擅長的多模態模型。
我們注意到,已經積累市場和開發者口碑及數量的階躍,此次開源,從模型側就在為後續深入接入做考慮。
一方面,Step-Video-T2V採用了是最為開放寬鬆的MIT開源協議,可任意編輯和商業應用。
可以說,「毫不隱藏」。
另一方面,階躍表示“全力降低產業接入門檻”。
就拿Step-Audio來說吧,不同於市面上的開源方案需要經過再部署和再開發等工作量,Step-Audio是一整套實時對話方案,只要簡單部署上就能直接實時對話。
零幀起手就能享受端到端體驗。
一整套動作下來,圍繞階躍星辰和它手中的多模態模型王牌,已經初步形成了獨屬於階躍的開源技術生態。
在這個生態中,技術、創意和商業價值相互交織,共同推動著多模態技術的發展。
而且隨著階躍模型的繼續研發、迭代,開發者的迅速、持續接入,生態夥伴的助力、合力,階躍生態的“滾雪球效應”,已經發生,並正在壯大。
中國開源力量正在並肩用實力說話
曾幾何時,提起大模型開源領域的佼佼者,人們腦中浮現出的是Meta的LLaMA,是Albert Gu的Mamba。
到了現在,毋庸置疑,中國大模型屆的開源力量已經閃耀全球,用實力改寫“刻板印象”。
1月20日,蛇年春節前夕,是一個國內外大模型神仙打架的日子。
最矚目的是,DeepSeek-R1在這一天問世,它推理性能比肩OpenAI o1,成本卻僅後者1/3。
影響之巨大,一夜讓英偉達蒸發5890億美元(約合人民幣4.24萬億元),創下美股單日跌幅最大紀錄。
更重要也更耀眼的是,R1之所以上升到億萬人為之興奮的高度,除了推理優異、價格親民,更重要的是它身上的開源屬性。
一石激起千層浪,連長期被戲謔「不再open」的OpenAI,都有CEO奧特曼屢次出來公開發言。
奧特曼說:“在開源權重AI模型這個問題上,(個人認為)我們站在了歷史錯誤的一邊。”
他還說:“世界上確實需要開源模型,它們可以為人們提供大量價值。我很高興,世界上已經有一些優秀的開源模型。”

現在,階躍也開始開源手裡的新王牌了。
並且開源是初衷。
官方表示,開源Step-Video-T2V和Step-Audio,目的就是促進大模型技術的共享與創新,推動人工智能的普惠發展。
開源一出場就憑實力在多個評測集上秀一把。
現在的開源大模型的牌桌上,DeepSeek強推理,階躍Step重多模態,還有各式各樣持續發育的選手……
它們的實力不僅是在開源圈子裡拔尖,放眼整個大模型圈子,都很夠看。
——中國開源力量,在嶄露頭角後,正在更進一步。
以階躍這次開源為例,突破的是多模態領域的技術,改變的是全球開發者的選擇邏輯。
Eleuther AI等很多開源社區活躍的技術大v,紛紛主動下場測試階躍的模型,“感謝中國開源”。
抱抱臉中國區負責人王鐵震直接表示,階躍會是下一個“DeepSeek”。

從「技術突圍」到「生態開放」,中國大模型的路越走越穩。
話說回來,階躍今次開源雙模型,或許只是2025年AI競賽的一個註腳。
更深層次的,它展現了中國開源力量的技術自信,並傳遞出一個信號:
未來的AI大模型世界,中國力量絕不缺席,也絕不落於人後。