

什麼?AI 界又整新活了?
這次雖然沒像 DeepSeek 、 Manus 們那樣搞得人盡皆知,但可能對 AI 界發展的影響還真不小。
前段時間,有個名不見經傳的小公司 Inception Labs 搞了個大新聞,說是開發出了全球首個商業級擴散大模型( dLLM ) Mercury 。
而這個所謂的擴散大模型,可能要會掀起一股浪潮,徹底顛覆大模型 3 年多來的基礎路線。

人家也實打實放出了數據,在一眾測試裡, Mercury Coder 基本是一路吊打 GPT-4o Mini 和 Claude 3.5 Haiku ,這些大家都快用爛的模型了。
而且,這些同臺競技的模型們,還特地專門為生成速度進行過優化,但 Mercury 還是比他們快了多達 10 倍。

不僅如此, Mercury 還能在 NVIDIA H100 芯片上,實現每秒超過 1000token 的處理速度,而常見的大模型想要實現這個速度,往往都得用上專門定製的 AI 芯片。
要知道,為了實現更高的 token 處理速度,定製化 AI 芯片幾乎成了各個廠商的新戰場。

除了速度超級超級超級快之外,我們也能從 Artificial Analysis 的測試座標系裡看出,Mercury 的生成質量也是槓槓的。
雖然目前還不如頂尖的 Claude3.5 Haiku 等,但考慮到它是一目十行的效率,能保持這個生成質量已經是非常哇塞了。

我們也在官方放出的 Mercury Coder Playground 裡簡單試了幾個例子,一頓測試下來發現生成效果確實不錯,而且速度真的是極快。
提示詞:用HTML5寫一個貪吃蛇遊戲(Implement the game Snake in HTML5.Include a reset button.Make sure the snake doesn't move too fast .)

提示詞:用HTML5 , CSS 和 Javascript 寫一個掃雷遊戲( Write minesweeper in HTML5 , CSS , and Javascript.Include a timer and a banner that declares the end of the game .)

提示詞:用 HTML5 做一個 Pong 遊戲( Create a pong game in HTML5.)

可能不少差友看到這估計決定,這也沒多牛啊,說什麼 AI 界可能要變天了?
Mercury 的厲害的點倒不是它的實際效果有多棒,更重要的是它給 AI 界帶來了一眾新可能:誰說大語言模型就一定要走 Transformer 的路線?
在這個 AI 時代, Transformer 和 Diffusion 大家估計都聽得耳朵起繭子了,一會是 Transformer 單幹,一會是 Diffusion 單飛,又或者是兩者一起合作。

但本質上來說,這兩者其實代表了 AI 的兩個不同進化方向,甚至可以說,Transformer 和 Diffusion 的 “ 思維 ” 機制不同。
Transformer 是“ 典型 ”人類的鏈式思維,它有一個自迴歸的屬性,就是它有個先後的概念,你得先生成了前面的結果,才能想出後面的玩意兒。
所以我們現在看到的 AI 生成,都是逐字逐句,從上從下一點點長出來的。

而 Diffusion ,則是反直覺的,直接從模糊去噪從而到清晰的過程。
就是你問他問題,他不會有整理邏輯,按 1 、 2 、 3 、 4 ……步驟回答你的想法,而是腦子直接想好了所有答案雛形,但這些答案全都是模糊不清的,然後一步步把所有答案一起變清晰,直到生成結果。
用生活裡的一個最常見的例子就是去配眼鏡,當你拿掉眼鏡看東西的時候,一整片都朦朧不清,但你確實都看到了,隨著一片片鏡片加上去,最終你看清了每一個字。
所以 Mercury 生成的結果都是一大片模糊的亂碼,然後一頓 quickly quickly biu biu biu , ber 得一下就全搞定了。

就像這樣
關於這倆的效果對比,我感覺歷史上曾經有一個著名發佈會上,有人曾用過更直觀的對比,可能更形象化幫助大家理解。

CPU 就好比如今的 Transformer

GPU 就好比如今的 Diffusion
其實光從我們這麼簡單的描述看起來,大家也能明白, Transformer 的確是更符合大家邏輯的思維方式,所以在大語言模型剛爆紅的時候,基本就是 Transformer 一個人勇闖天涯。
但逐漸的, Transformer 開始展露自己的不足。
其中最讓人頭疼的就是, Transformer 的注意力機制看起來很優秀的背後,是計算複雜度(計算複雜度公式為 O ( n ² d )( n 為序列長度, d 為特徵維度 ) )指數級別增長。

計算複雜度的爆炸增長帶了多方面的制約,比如模型推理速度顯著下降,在長文本、視頻等領域,生成速度顯然無法滿足實際需求。
進一步的,複雜度不斷升高,所需要的硬件資源也同樣指數級增長,這種硬件需求阻止了 AI 真正走進大家生活。
所以一直以來,業界都在想著法地緩解 Transformer 模型的計算複雜度。
像通過量化、蒸餾、壓縮模型的 DeepSeek 能夠爆火出圈,其實也是建立在這種迫切需求上。

那 Mercury 的出現,似乎也在提醒大家,如果降低 Transformer 的計算複雜度太難的話,要不試試新路子?
而且 Mercury 背後的 Diffusion 路線,大家並不陌生。
比如早期爆紅的 stable Diffusion , Midjournery 、 DALL-E 2 裡,都看到了 Diffusion 模型的應用。
甚至還出現了像是 OpenAI 的 sora 模型,就是利用了 Diffusion Transformer ( DiTs )這種 Transformer 和 Diffusion 混合雙打模型。
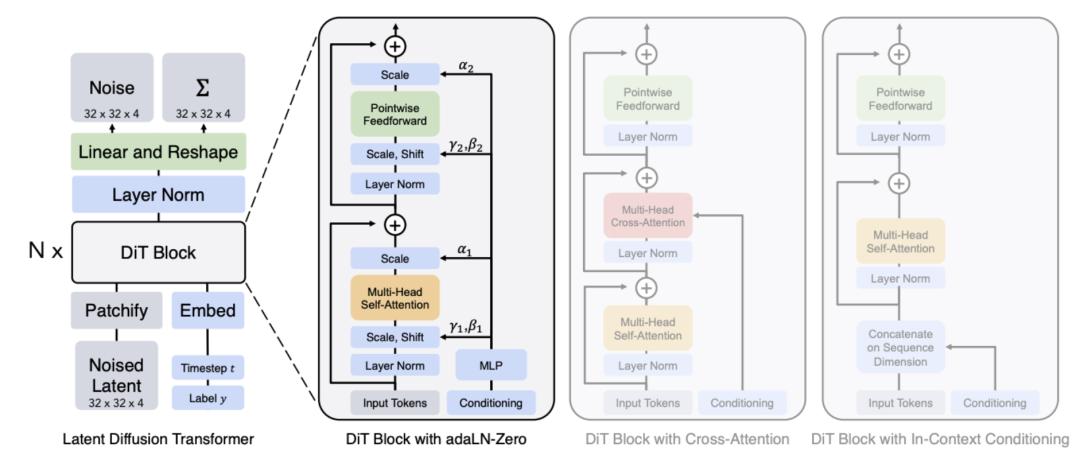
雖然理想很美好,但 Diffusion 此前幾乎都被各路人馬判了死刑,因為他們覺得這貨駕馭不了語言模型。
因為 Diffusion 的特點是沒了自迴歸,不用依賴上下文,從而可以節省資源,加快生成速度。
但這麼一來,生成精度有點難以把握,就像現在文生圖、文生視頻的各種模型,依舊難以控制手部、吃麵條、文字等高精度的生成。

可這次 Mercury 的突破性成果,的確也第一次向大家驗證了, Diffusion 也能幹 Transformer 的活。
不過可惜的是,目前 Mercury 並沒有公開任何技術文檔,我們無法進一步得知它是如何搞定生成內容質量難關的。
但我們從它挑的對手比如 Claude3.5 Haiku 、 GPT4-omini 、 Qwen2.5 coder 7B 、 DeepSeek V2 lite 等等這些袖珍版大模型裡,也能看出來,顯然最強大的 Diffusion 語言模型 Mercury 也還沒法做得特別大。
甚至經過我們測試發現,除了官方推薦的提示詞生成效果比較精準以外,如果用一些自定義提示詞,它的出錯概率就高得有點誇張了。
而且生成的穩定性也相當一般,經常第一次生成效果還不錯,再測試一次結果反而不會了。
提示詞:用 HTML 畫出太陽系的模擬動畫( Use HTML to write an animation of the solar system simulation operation )
但毫無疑問, Mercury 的成果是了不起的,特別在考慮到 Diffusion 在多模態生成上的強勢地位,也讓人不禁想象,如果 Diffusion 的路線才是 AI 大模型更正確的道路( 好像也不是不可能吧 ),未來的聯動進化好像更水到渠成些。
前不久,差評君剛看了一部名為《 降臨 》的電影,裡面的外星人就不是按照人類這樣 1 、 2 、 3 、 4 ……的鏈式思維邏輯,不同的思維方式顯然會帶來更多的可能性。
那問題來了,誰說 AI 就得要像人類一樣思考呢?對他們來說,是不是 Diffusion 的思考方式更符合 “ 硅基生命 ” 的屬性呢?
當然,這些都是差評君的瞎瘠薄扯淡,不過有意思的是, Mercury 既是太陽系的水星,也是羅馬神話中的信使,他們倆的特點就是跑得飛快,而在占星學裡,它又代表著人的思維方式和溝通能力。
我們也不妨期待, Mercury 的出現,能給 AI 帶來新的路子。
圖片、資料來源:
X.com
Mercury官網
OpenAI:Generating videos on Sora
techcrunch:Inception emerges from stealth with a new type of AI model
AimResearch:What Is a Diffusion LLM and Why Does It Matter?
知乎:如何評價Inception Lab的擴散大語言模型Mercury coder?
本文來自微信公眾號“差評”,作者:八戒,編輯:江江 & 面線,36氪經授權發佈。






