

這項研究由 ProbeLab 團隊的 @cortze 和 @yiannisbot 完成,並得到了以太坊基金會和 PeerDAS 社群的反饋。
引言
作為以太坊提高可擴充套件性路線圖的一部分,blob 交易被引入以允許在每個插槽中包含更多資料。因此,可以新增的 blob 越多,鏈上支援的資料就越多,這將使 rollup 和其他擴容方案受益。
因此,人們對增加每個區塊的目標和最大 blob 數量很感興趣。然而,這引發了一些擔憂:
- 雖然機構驗證者可能擁有處理更多 blob 的硬體和頻寬,但許多家庭驗證者並不具備。這可能會造成驗證者參與的潛在不平衡。
- 增加 blob 數量還可能影響某些節點保持同步的能力,尤其是在重組或恢復事件期間,節點需要從較少的對等節點下載大量資料。
目前,我們沒有太多方法來衡量網路如何處理這些情況,除了檢視從其他節點下載區塊或 blob 的速度(請檢視我們的帖子,擴充套件這個想法)。這提供了一些洞察,但不足以完全理解網路在壓力恢復下的行為。
減輕單個驗證者負擔的一種可能方法是透過分散式區塊構建。由於執行層(EL)通常在 blob 交易被包含在區塊之前就已接收到許多 blob 交易,區塊構建者可以透過假設其他節點的本地記憶體池已包含區塊驗證所需的 blob 來減少初始頻寬使用。
本文的工作建立在我們最近的研究基礎上,該研究測量了 blob 側車的理論執行層記憶體池命中率。那項分析表明,在超過 75% 的情況下,執行層已經擁有必要的 blob 資料,然後才提出區塊。然而,那項研究並未檢查執行層是否能及時為共識層(CL)的 engine_getBlobsV1 呼叫提供 blob。
在這個後續研究中,我們著眼於執行層記憶體池中 blob 側車的實證命中率,以更好地理解分散式區塊構建在實踐中的可行性,尤其是在幫助頻寬或資源有限的驗證者方面。
摘要
- 監控共識層和執行層之間的本地
engine_GetBlobsV1呼叫顯示執行層記憶體池的 blob 命中率很高:- 76.6% 的總請求能在 100 毫秒內從本地執行層記憶體池成功檢索以驗證區塊。
- 剩餘的 23.4% 請求是部分響應。然而,在這些部分響應中的大多數(98%)只缺少一個 blob 側車。
- 當前網路狀態顯示,在 gossipsub 網路上重新分發所有側車可能會產生一些冗餘流量,因為目前,在新區塊廣播時,大多數 blob 已經存在於執行層記憶體池中。
| 響應的一部分是否? | 是否在釋出記憶體池中看到? | 邊車數量 |
|---|---|---|
| 是 | 是 | 197156 |
| 否 | 是 | 4571 |
| 否 | 空 | 6392 |
引擎API呼叫和邊車重建時間
因為共識層(CL)不能無限期地等待執行層(EL)的響應,幾個客戶端團隊已經討論是否應該為engine_getBlobsV1請求設定超時,如果是,適當的值是多少。
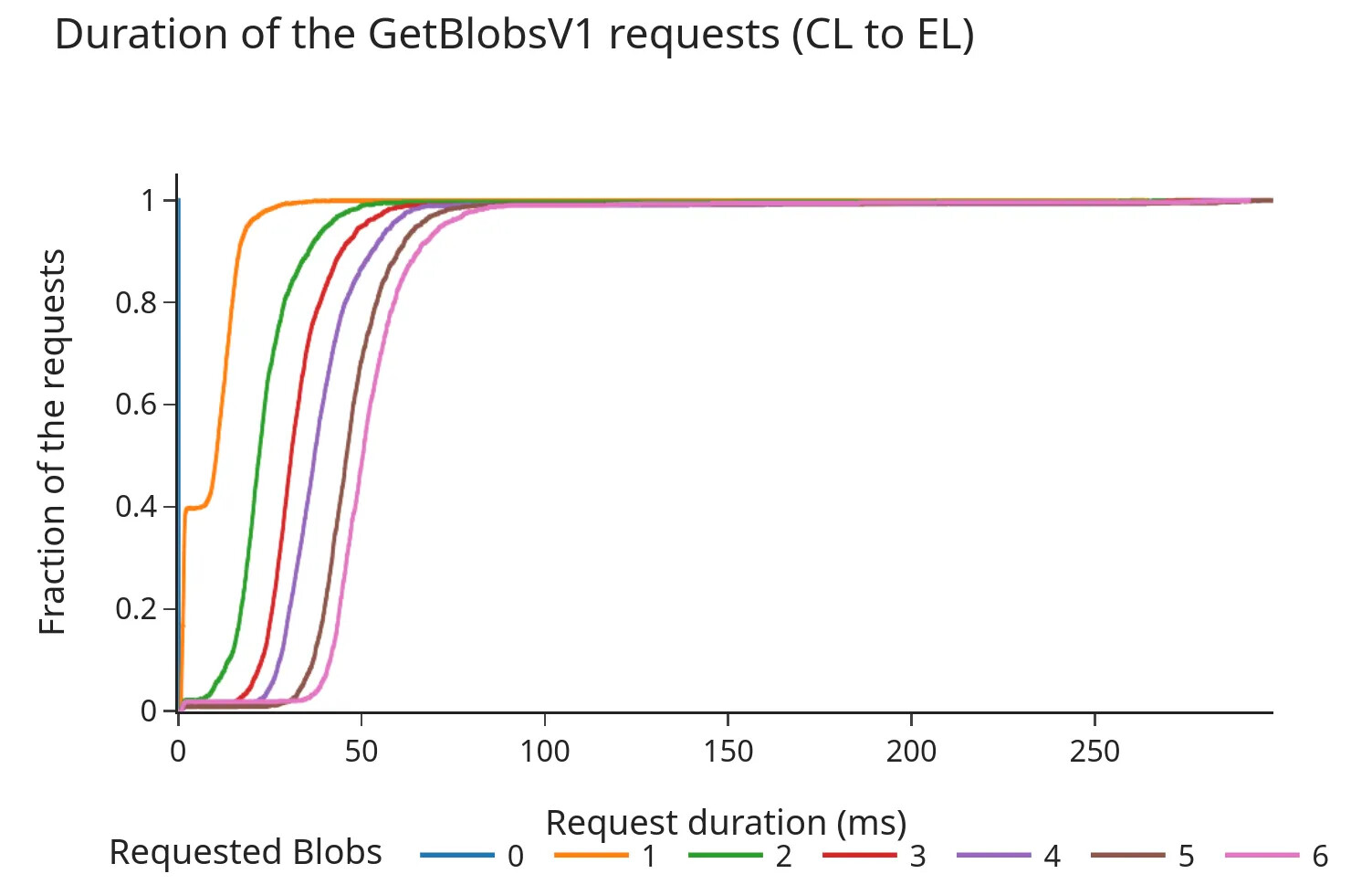
以下圖表顯示了引擎API的請求/響應持續時間(以毫秒為單位)的累積分佈函式(CDF)。
Pectra之前:
Pectra之後:
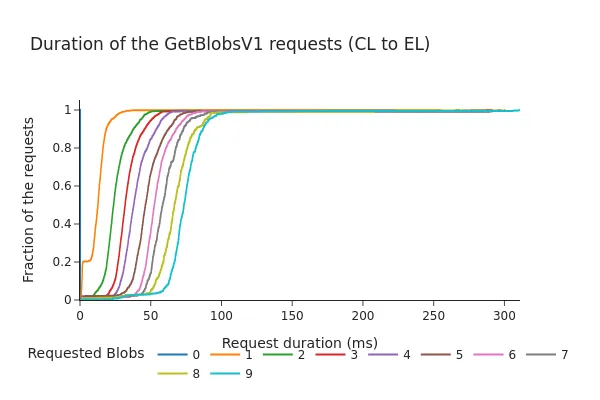
- CDF顯示,即使在Pectra分叉和增加3個額外的邊車後,98%的請求在100毫秒內完成。
- 總持續時間幾乎與請求的邊車數量呈線性增加。儘管這些時間仍在通常被認為的"安全範圍"內(之前的討論建議超時在200-250毫秒左右),但資料表明增加每個插槽的邊車數量可能會導致從EL的邊車記憶體池獲取更長的時間,尤其是在較高負載下。
結論
這項研究和我們之前的研究是與@cskiraly的研究並行進行的,儘管方法不同,但兩項工作得出了相同的結論:
在當前的網路狀態和鏈的使用趨勢下,大多數邊車已經在被包含到信標塊之前就在EL中可用。
儘管這個結論總體上是個好訊息,但它表明當前網路正在使用大量資源在CL邊車主題上傳送冗餘資訊,這為改進留下了充足空間。
一方面,這種冗餘確保所有CL節點都有處理新塊提案所需的資料,成功地提供了彈性。另一方面,它也成為了自身的瓶頸,因為所有邊車都需要在不到4秒的時間內在網路上廣播(假設時間遊戲正在縮短這個視窗)。
建議
為了減少網路開銷和節點負載,值得討論PeerDAS和邊車共享。
在以太坊當前的PeerDAS提案中,我們只在CL層對邊車進行分片,這是對Blob重新分發階段的最佳化。然而,這隻部分解決了問題,因為我們仍然會透過EL記憶體池傳送所有邊車交易,節點將在頻寬允許的情況下不加選擇地下載所有邊車。
即使使用分散式區塊構建,這可能有助於更快地廣播邊車,我們仍然會發送(至少部分)冗餘資訊。
IDONTWANT訊息在這裡有幫助,但我們仍會生成許多重複項,這最終會增加網路開銷和節點負載。
可能的未來
將分片轉移到EL記憶體池有明顯且重大的好處:
在EL層對邊車進行分片可以簡化驗證網路中Blob的種子和一些預計算步驟,這可能成為交易提議者的新職責,即對邊車單元應用糾錯編碼併發起廣播。
可以對邊車的分發應用負載均衡屬性,這消除了CL必須在4秒內廣播邊車的當前時間限制。因為邊車尚未被包含,我們不需要對其傳播強制執行任何截止日期。這進一步意味著較慢的使用者在廣播片段時可以"承受"一些額外的延遲。
EL目前在下載邊車方面比CL更高效:
- 在EL層獲取邊車時沒有時間限制,因此不需要立即下載所有看到的邊車。
- EL決定何時傳送單個拉取邊車請求,避免了GossipSubs在其平均網格對等節點上引起的重複項→預設為
D-2每條訊息的重複項(連結)
這與@cskiraly的提案大體一致:在執行層(EL)而不是共識層(CL)實施分片可能更有效。
這個想法仍處於草案階段,探索如何最佳化網路資源的使用,還有幾個細節需要解決。
作為這可能看起來的示例,我們想重新審視並分享Blob記憶體池DHT提案,這是ProbeLab團隊幾個月前開始起草的。它旨在展示CL和EL如何協同工作以更有效地利用網路頻寬和儲存(將提案細節留待未來的帖子)。一如既往,歡迎所有反饋。






