

引言
硬分叉是重新定義網路能力和效率的關鍵時刻。5月7日,以太坊主網從Deneb升級到Electra分叉,其中包括對協議共識和網路層的幾項關鍵變更和改進。在這篇文章中,我們特別研究了網路如何為分叉做準備,透過分析事件前幾周的網路拓撲、訊息到達時間的變化,以及升級是否實現了一些放寬的頻寬要求。
為此,我們對一些測量工具(如Nebula和Hermes)在硬分叉事件前、期間和之後收集的資料進行了專門分析。這項分析補充了我們關於網路拓撲、區塊到達時間、頻寬使用等的每週更新。我們在一年前對Dencun硬分叉的P2P層進行了深入研究,這為本研究的重點領域提供了一些參考。
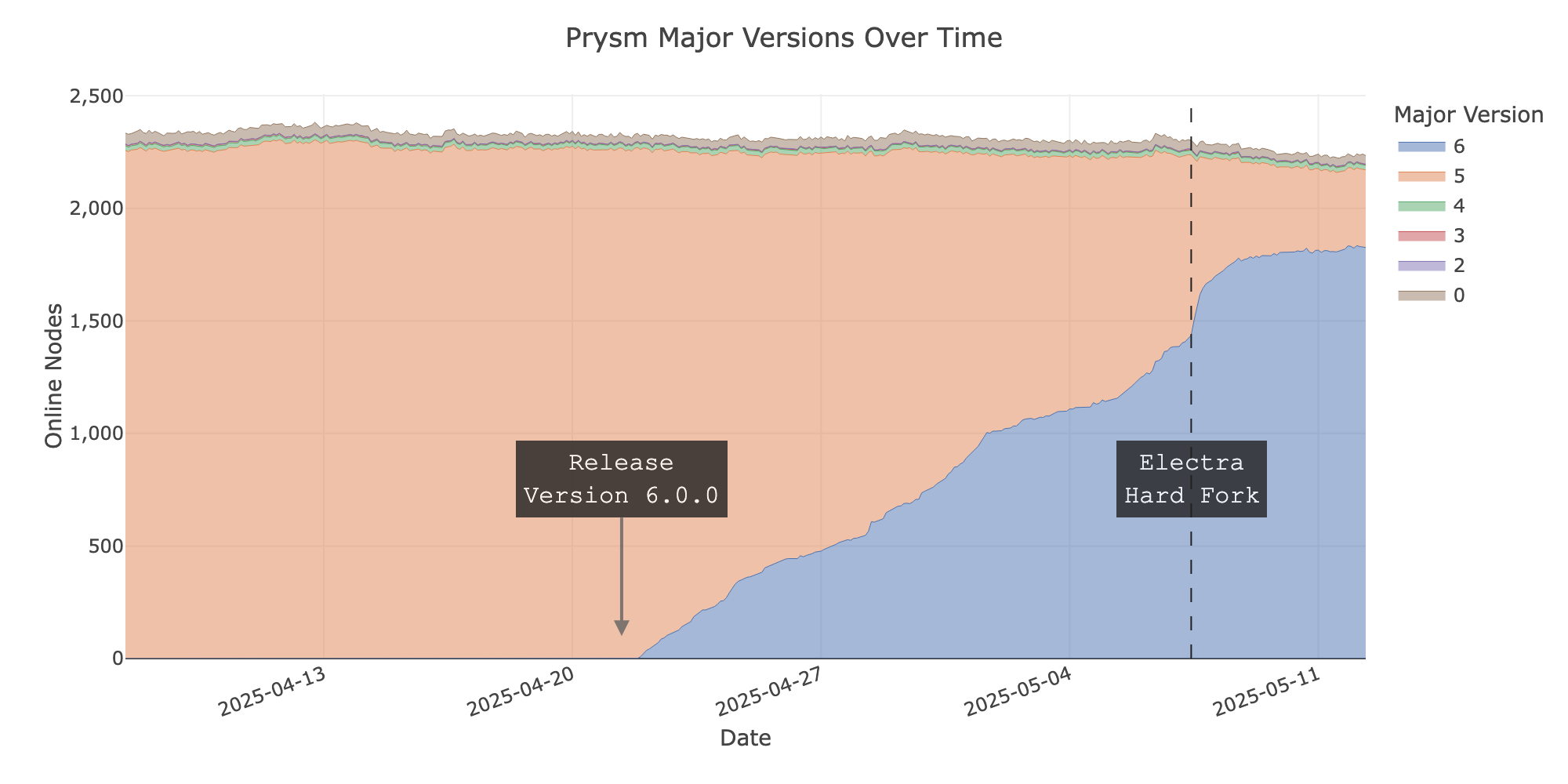
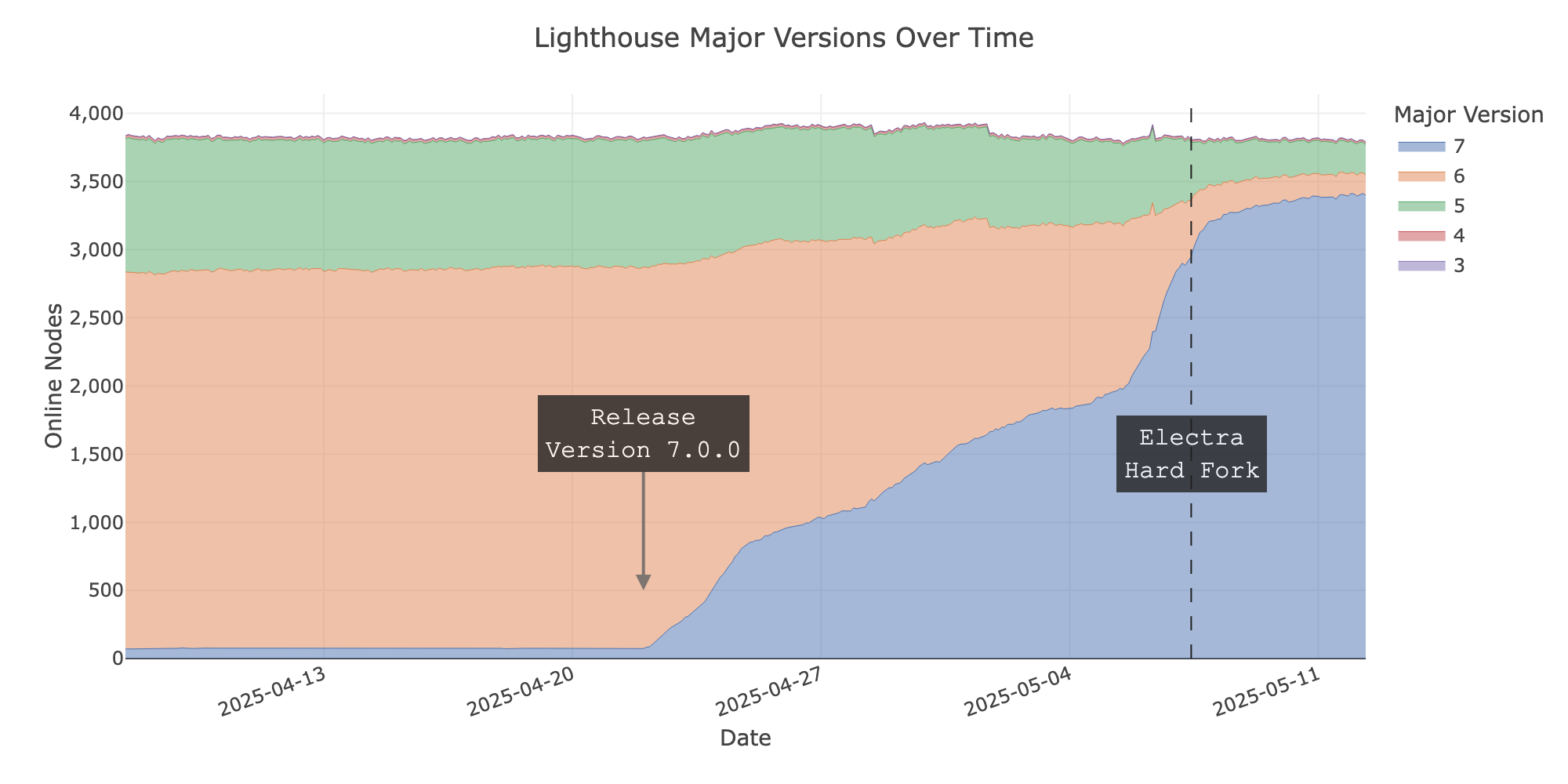
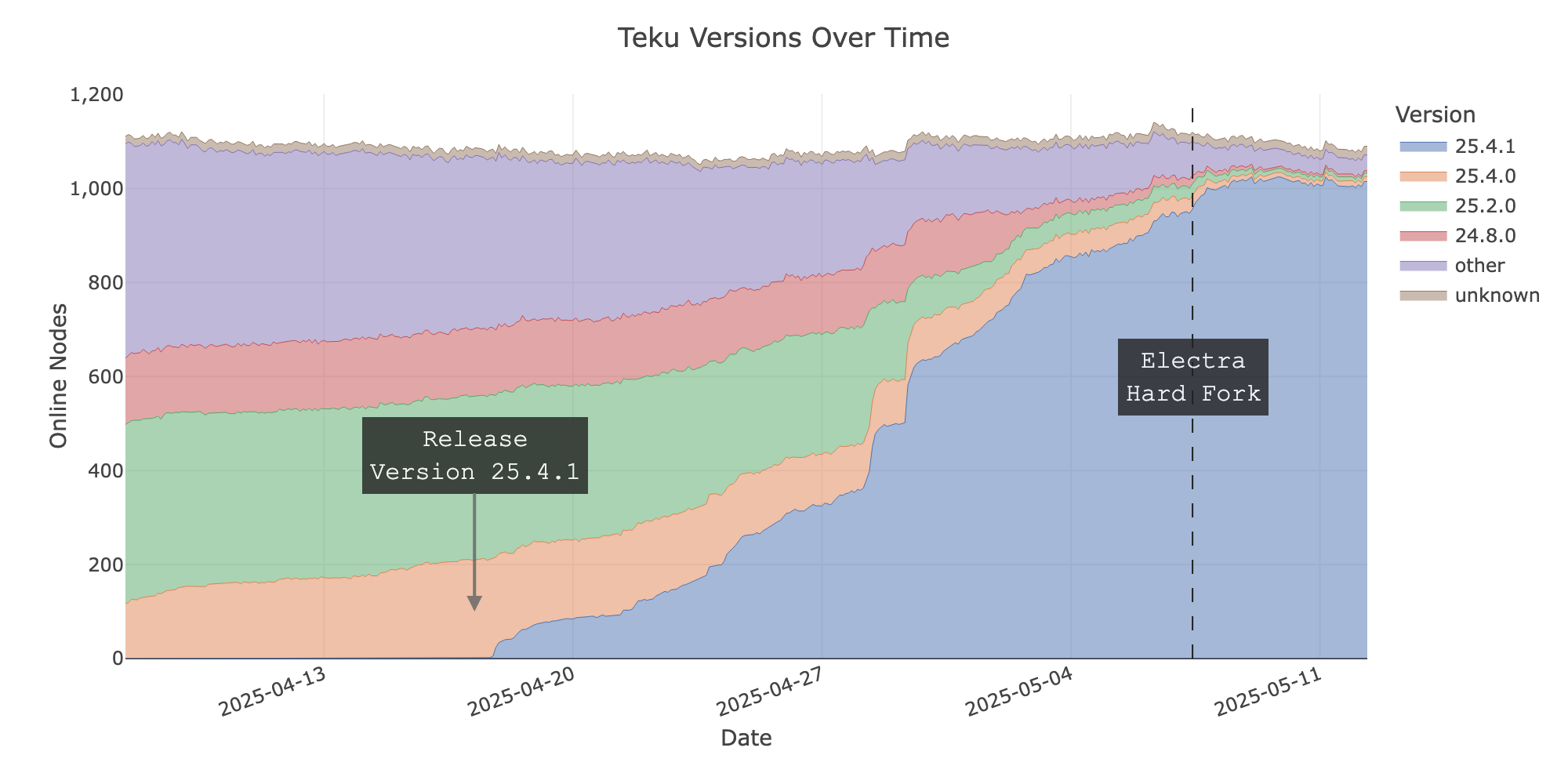
正如預期,在這三種情況下,我們可以看到在官方釋出各自的客戶端後不久,節點運營商就開始升級。在硬分叉前兩天,網路中約53%的節點運行了Electra相容的客戶端實現 - 前一天為60%,前一小時為67%。這些數字沒有考慮Nimbus客戶端,因為它們不公佈版本資訊。Nimbus是網路部署中佔有重要份額的第四個實現,所以Electra就緒節點的數量可能高出幾個個位數百分點。
我們還可以安全地說,節點運營商並沒有利用硬分叉作為切換客戶端實現的機會,如下圖所示。在分叉期間,客戶端實現的分佈幾乎沒有變化。
要點
- 大約70%的線上節點立即跟隨了新的分叉。
- 另外約20%的節點在事件發生一週後跟隨了新的分叉
- 很難說剩餘的節點是否為家庭/業餘部署,因為我們發現它們執行在雲基礎設施上,即不太可能在沒有執行驗證者的情況下啟動節點。
- 相容的客戶端版本在分叉前的幾天裡逐步被採用。
硬分叉對區塊到達時間的影響
Pectra升級的核心新增功能之一是將每個區塊的blob目標值和最大值增加三個額外的blob(請參見EthPandaOps文章,ProbeLab文章)。儘管網路透過這額外的50%臨時空間受益,但這個blob數量的增加也意味著網路需要在每個時段額外傳輸多達348KB的資料。如果節點無法在時段早期分配更多頻寬(區塊傳播時),這最終可能會影響網路的整體訊息廣播能力。
(後續內容省略,保持原有格式和翻譯風格)以下是翻譯結果:下面的圖表顯示了我們認為的四個最相關的資料點隨時間變化:報告的區塊到達時間的最小值、平均值、中位數和第95百分位數。該圖顯示網路上區塊傳播穩定,僅在5月7日凌晨00點硬分叉前12小時出現第95百分位數線突然躍升至4.6秒的情況(硬分叉發生在5月7日上午10點UTC)。這一峰值持續了幾個小時後恢復,並最終將平均和中位數到達時間從之前的2.38秒降低到約2.2秒。
我們將硬分叉時間附近區塊到達的峰值歸因於一些未及時更新的節點,這些節點可能確實干擾了網狀網路的穩定性。
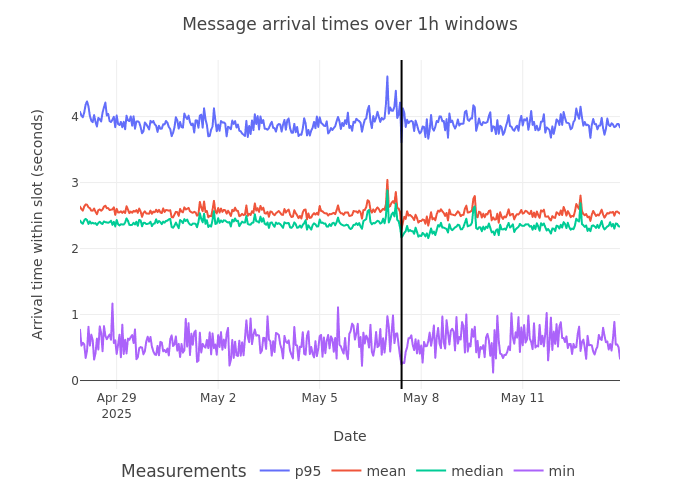
再次觀察到,仍有5%的區塊到達接近或超過4秒標記,這對MEV構建者來說應該是令人警惕的,對於接受投標的個人構建者也是如此。
(後續部分省略,保持原有格式和標籤)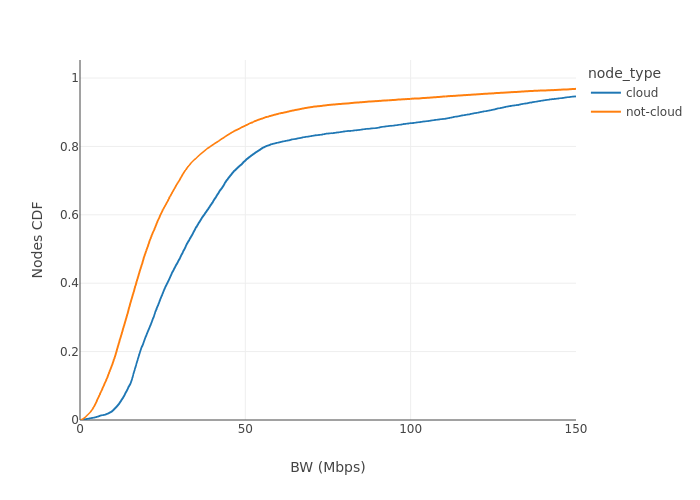
純吞吐量並不是我們唯一關注的內容;至少在以太坊中,時間很重要。由於網路有特定的時間視窗,瞭解吞吐量在時隙內的可用性很重要。以下圖表顯示了按主機型別聚合的平均測量吞吐量和請求信標塊的時隙時間。
模式很清晰,在時隙的第一秒到第四秒之間,雲端和非雲端託管節點都出現了下降。這是網路透過gossipsub廣播信標塊和blob側鏈的視窗。
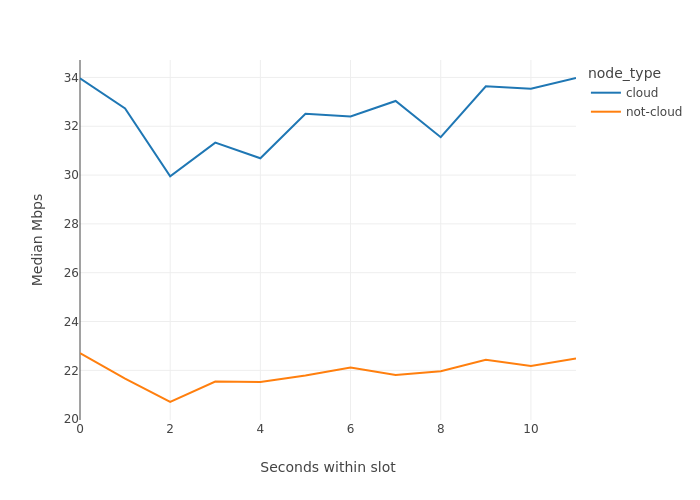
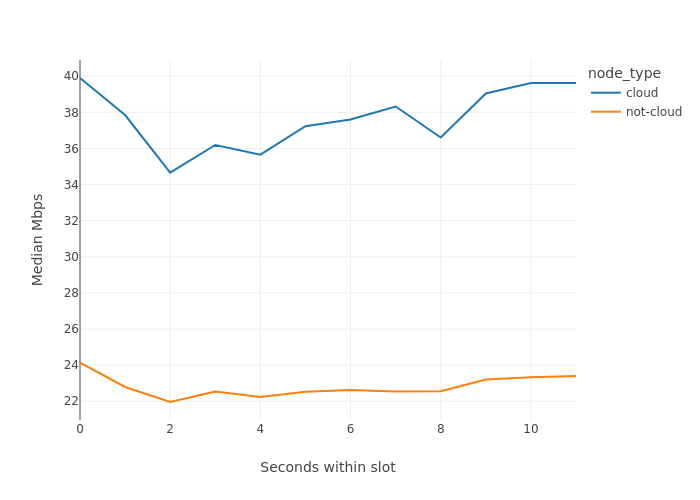
在比較Pectra升級前後的分佈時,我們看到它們在時隙內遵循完全相同的模式。唯一的區別是,雲端節點的平均值增加了5-6 Mbps,非雲端節點增加了2 Mbps。
Pectra升級前:
Pectra升級後:
要點
- 儘管增加了3個額外的blob,網路整體仍處於健康狀態。
- 資源可用性分佈的高階節點似乎比升級前有更多可用頻寬。
- 在網路中資源受限的節點感知到上傳吞吐量略有下降,但這被認為既不顯著也不關鍵。
- 正如這篇文章報告的[連結],由於添加了
IDONTWANT訊息原語,重複訊息數量明顯減少,但其對頻寬可用性的影響在節點資源可用性範圍內並不清晰。
結論
分叉事件突顯了節點運營商傾向於在最後一刻升級。儘管大多數節點準時跟隨新的分叉,但相當大的部分延遲了長達一週。相容的客戶端版本僅逐步在分叉前被採用,表明網路的部分地區仍然缺乏升級緊迫性。
在傳播方面,及時的塊傳遞仍未得到保證。大約5%的塊在控制節點晚到,儘管中位數時間有所改善,但尾部仍然存在問題,這指向資源可用性或網路效能中持續存在的差距。
儘管如此,網路整體在分叉後仍保持穩定和健康狀態。額外的blob沒有造成重大幹擾,IDONTWANT的引入改善了情況,但並不顯著。一些節點似乎有更多頻寬可用性,可能是由於IDONTWANT的新增,或提供了額外的頻寬資源,而效能較弱的節點(可能是家庭質押者)在上傳吞吐量方面略有減少。






