

從一維和二維角度重新審視安全DAS
作者: Benedikt ( @b-wagn )、 Francesco ( @fradamt )
所有代碼均可在筆記本中找到。
一、引言
隨著Fusaka 升級,以太坊將引入一種名為PeerDAS的數據可用性採樣 (DAS)機制。底層數據單元blob使用 Reed-Solomon 碼進行水平擴展,並排列為矩陣的行。樣本則作為矩陣的列。
列也是網絡上的傳輸單位,目前無法交換小於列的單位。因此,PeerDAS 的初始版本缺少兩個功能:
- 部分重建:僅通過重建和重新播種部分數據(例如,僅一行(或幾行)而不是整個矩陣)即可為重建做出貢獻。
- 完全兼容內存池:交易附帶 blob/行,通常會提前分發到內存池中。然而,任何單個 blob 的缺失都會阻止節點構建列,從而導致所有其他內存池 blob 失效。
為了解決這些限制,單元級消息傳遞已被強烈考慮作為該協議下一輪迭代的候選方案(例如,參見此處)。由於這也是二維 DAS 構建的關鍵組成部分,這引發了一個問題:我們是否應該:
- 通過單元級消息傳遞增強 1D PeerDAS,或
- 過渡到 2D 構造。
或者至少,這種轉變是否會是後續的迭代。在本文中,我們將比較這兩種方法的效率,假設它們都旨在提供相同級別的安全性,同時最大限度地減少帶寬消耗。
免責聲明:我們將完全忽略“加密層”的安全性,即所使用的 KZG 承諾的安全屬性。該層已在此處和此處進行了廣泛的研究。我們的重點是與採樣過程相關的統計安全屬性,並將加密層視為理想化。
背景:數據可用性採樣
讓我們首先抽象地回顧一下數據可用性採樣(DAS)背後的核心思想。
在 DAS 中,提議者持有一段數據,並希望將其分發到整個網絡。客戶端(可能是全節點或驗證者)的目標是驗證該數據確實可用,而無需完整下載。
為了實現此目的,提議者使用糾刪碼擴展數據。然後,每個客戶端嘗試下載結果碼字的k k 個隨機符號,並根據所有客戶端都會下載的簡潔加密承諾進行檢查。在 DAS 中,這些符號也稱為樣本或查詢。只有當所有k k 個查詢都成功驗證後,客戶端才會接受數據(例如,在其分叉選擇中包含相應的區塊)。
DAS 安全性(針對潛在的惡意提議者)背後的高級直覺是:
- 加密承諾保證提議者承諾使用有效的代碼字(請參閱此處的代碼綁定概念);
- 如果有足夠多的客戶端接受,那麼由於擦除碼的屬性,他們的集體查詢允許重建完整的數據。
這篇文章主要討論第二點:重構究竟是如何實現的?多少個客戶端才夠用?參數k又該如何設置?
我們首先解決第一個問題,解釋一下“部分重建”的含義。然後,我們將重點轉向安全性。
背景:部分重建
DAS 的核心問題之一是:誰能重建數據?何時重建?假設我們有一個無所不能的“超級節點”,它能夠從網絡下載足夠多的樣本,重建通過糾刪碼編碼的全部數據。在這種情況下,即使只有少數代碼符號缺失(可能是被惡意提議者隱瞞的),這個超級節點也可以簡單地重新計算缺失的部分,並將其重新引入網絡(即重新播種)。最終,這些符號會被傳播,所有客戶端都會接受。
這種設置引發了對如此強大的超級節點的依賴擔憂,這可能是一箇中心化因素。事實上,即使我們使用具有最小重建閾值的糾刪碼(例如Reed-Solomon等所謂的MDS碼) ,超級節點也需要下載與完整原始數據一樣多的樣本才能重建數據。
這時,部分重建的概念就應運而生了。如果某個代碼能夠使用比完全重建所需的樣本少得多的樣本量來恢復數據中較小的局部部分,我們就稱其支持部分重建。無需超級節點收集幾乎所有數據片段,多個較小的節點就可以獨立地重建部分數據。通過這種方式,部分重建可以將重建任務分散到眾多參與者身上,從而減少對中心化超級節點的依賴。
除了通過減少對更強大節點的依賴來增強網絡的穩健性之外,分散重建的 CPU 負載和重新播種重建數據的帶寬負載也可以被視為性能提升。目前,重建不太可能幫助數據在關鍵路徑上傳播,這或許是採用糾刪碼的另一個好處,因為重建一個包含所有證明的 blob大約需要 100 毫秒。通過將此負載分散到多個節點,每個節點只負責一個或幾個 blob,糾刪碼的作用遠不止於安全保障。
背景:子集健全性
在本文中,我們將比較不同編碼方案(一維和二維)的效率,假設它們都能達到相同的安全級別。為了使比較更有意義,我們首先需要清楚地理解在 DAS 環境中“安全”的含義。
我們考慮的安全概念被稱為子集健全性,並考慮了自適應對手。該概念在《DAS基礎》論文中作為定義2正式引入,它也是PeerDAS安全原理的基礎。
直觀地講,子集健全性模型模擬了一個強大的對手,他會觀察大量n個客戶端/節點的查詢。然後,對手可以自適應地決定顯示哪些符號、隱藏哪些符號,從而有效地構建每個節點看到的視圖。對手還會選擇一小部分節點(例如, \epsilon n \leq n ϵ n ≤ n ,其中\epsilon > 0 ϵ > 0 ),並試圖欺騙這些節點,使其相信數據完全可用。值得注意的是,這種選擇可能取決於節點發出的查詢。然後,我們考慮對手贏得這場遊戲的概率p p ,即
- \epsilon n ϵ n個節點全部接受,並且
- 數據並不完全可用;也就是說:人們無法從查詢中重建數據。
為了達到我們的目的,我們希望p p最多為2^{-30} 2 − 30 (對於任何對手)。下面,我們將根據n n 、 \epsilon ϵ和編碼方案設置每個節點的查詢次數k k ,以保證p \leq 2^{-30} p ≤ 2 − 30 。
\epsilon ϵ的影響和選擇:
上面描述的安全概念由\epsilon \in (0, 1] ϵ ∈ ( 0 , 1 ]參數化,它模擬了對手試圖欺騙的節點比例。從正式定義和簡單的密碼學簡化來看,給定\epsilon ϵ (具有固定的n n )的子集健全性意味著任何更大的\epsilon' \geq \epsilon ϵ ′ ≥ ϵ的子集健全性。換句話說:如果對手無法欺騙\epsilon ϵ比例的節點,那麼它肯定無法欺騙更大比例的\epsilon' ϵ ′ 。但這與整體共識協議有何關係?假設我們知道攻擊者最多隻能欺騙ε ϵ比例的節點。每個被欺騙的節點實際上在共識過程中充當一個額外的惡意節點。因此,當使用數據可用性抽樣時,攻擊者最多可以獲得額外 ε ϵ比例的明顯惡意節點。
例如,如果沒有 DAS 的共識可以容忍最多<{1}/{3} < 1 / 3 個惡意節點,那麼有了 DAS,系統現在只能容忍最多<{1}/{3} - \epsilon < 1 / 3 − ϵ 個惡意節點。
因此,在實際操作中,我們必須選擇較小的\epsilon ϵ ,比如\epsilon = 1\% ϵ = 1 % ,以確保對手的影響可以忽略不計。
二、PeerDAS——一維構造
在本節中,我們將解釋PeerDAS的工作原理,它將包含在Fusaka升級中。我們還將解釋單元級消息傳遞如何實現部分重建。
工作原理
我們描述瞭如何編碼數據以及客戶端如何進行查詢,而忽略了與“加密層”相關的所有內容,例如承諾和開口。
一個blob是由m個單元組成的集合,每個單元包含f個字段元素。在 PeerDAS 當前的參數設置中,每個單元包含f = 64個字段元素,每個 blob 包含m = 64個單元。為了考慮不同的單元大小,我們令fm = 4096為常數(即數據大小固定) ,並在f ∈ { 64,32,16,8 }之間變化,即m = 4096 / f 。
要對單個 blob 進行編碼,需要使用速率為1/2 1/2的Reed -Solomon 碼對其進行擴展,從而得到2m 2 m個單元,或者等效地得到2fm = 8192 2 f m = 8192 個字段元素。在 PeerDAS 中,我們將此編碼過程分別應用於b b 個blob,並將擴展後的 blob 視為b \times 2m b × 2 m個單元矩陣中的行。
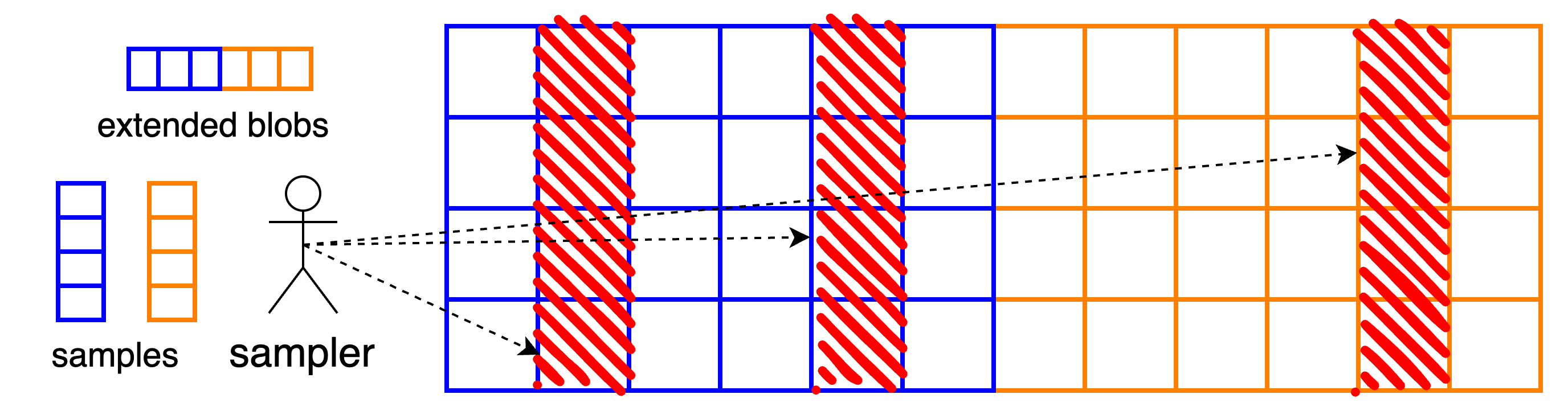
客戶端現在查詢該矩陣的整列,也就是說,它們嘗試一次性下載b個單元。這意味著“符號”或我們的糾刪碼是擴展 blob 矩陣的列。從這些列中的任意m個列,都可以重建整個矩陣,從而重建數據。
支持採樣功能的具體網絡基礎設施是列的 GossipSub 主題,即只有對特定樣本(= 列)感興趣的節點參與的子網絡。
部分重建
正如預期的那樣,當前的PeerDAS設計不支持部分重建。然而,即使是這樣的一維編碼,原則上也可以支持此功能,當它獨立應用於多個blob時,就像在PeerDAS中一樣。事實上,通過使用小於列的垂直單位(例如單元格),當然可以僅重建完整矩陣的部分內容,例如單獨的行或行組。這帶來了兩個挑戰:
- 部分重新播種:當一個節點重建單行時,它不會重建任何完整的樣本(列),但它仍然需要能夠將重建的數據貢獻回網絡。
- 獲取足夠的單元進行重建:當僅對列進行採樣時,重建能力要麼全部,要麼全部不重建,也就是說,一個節點要麼獲得足夠的列來重建整個矩陣,要麼無法重建矩陣的任何部分。換句話說,只有超節點才能參與重建。我們希望節點能夠做到這一點,同時仍然只下載整個數據的一小部分。
有一些眾所周知的方法可以解決這些問題,這些方法可以讓我們進行部分重建:
- 單元級消息傳遞:使節點能夠交換單元而不是整列,以便重建行的節點可以逐個單元地重新播種,至少在它們參與的列主題中是這樣。
- 行主題:有些節點也嘗試通過參與行主題下載部分行,並配備單元級消息傳遞功能。至關重要的是,這並非採樣,獲取多少行並不涉及安全隱患,因此即使只參與一個行主題也足夠了。事實上,在一維結構中,對行進行採樣毫無意義,因為不存在垂直冗餘。行主題的目的僅僅是使列主題中的單元能夠流入其中並實現行向重構,而無需任何超節點。重構後的單元隨後可以從行主題流入所有列主題,同樣無需任何單個節點參與所有列主題。
注意:缺乏垂直冗餘意味著我們需要每個行主題都能成功執行其重建任務。即使只有一個行主題失敗(例如,由於僅限於該主題的網絡級攻擊),整個重建也無法完成。
樣本數量
現在讓我們確定PeerDAS每個客戶端的樣本數量k 。如上所述,我們希望選擇k ,使得攻擊者破壞子集健全性的概率p最多為2^{-30} 2 − 30 。
PeerDAS 的安全性已在這裡和這裡進行了廣泛的分析。後者的工作建立在這裡的安全框架之上,並且可以通過結合引理 1 和引理 3得出子集健全性的具體界限。最終,所有這些得出了相同的子集健全性界限,即:
p \leq \binom{n}{n\epsilon}\cdot \binom{2m}{m-1} \cdot (\frac{m-1}{2m})^{kn\epsilon} \leq \binom{n}{n\epsilon}\cdot \binom{2m}{m-1} \cdot 2^{-kn\epsilon}. p ≤ ( n n ϵ ) ⋅ ( 2米米− 1 ) ⋅ (米− 1 2米) k n ϵ ≤ ( n n ϵ ) ⋅ ( 2米米− 1 ) ⋅ 2 − kn ϵ 。
直觀地講,第一個二項式表示對手自由且自適應地挑選n\epsilon n ϵ個節點來欺騙的能力,第二個二項式表示對手選擇m-1 m − 1 個符號來提供給這些節點,最後一個項是所有樣本最終都出現在編碼的可用部分中的概率。
如果我們希望p \leq 2^{-30} p ≤ 2 − 30且n,m,\epsilon n , m , ϵ已知,我們需要設定
k \geq \frac{1}{n\epsilon} \left( \log_2 \binom{n}{n\epsilon} + \log_2 \binom{2m}{m-1} + 30 \ right ) k≥1nϵ (日誌2 ( n n ϵ ) + log 2 ( 2米− 1 ) + 30 ) 。
以下是計算k k的代碼:
from math import comb, log2, ceil # used later from tabulate import tabulate # used later import numpy as np # used later import matplotlib.pyplot as plt # used later def min_samples_per_node ( n: int , m: int , r: int = 2 , eps: float = 0.01 ): """Finds the smallest integer k such that k samples per nodeachieve security of 30 bits for the 1D construction.Inputs:n: total number of nodesm: number of symbols in original datar: inverse coding rate (total symbols = r*m), default=2eps: fraction of nodes to be fooled (0 < eps <= 1), default=0.01Returns:Smallest integer k satisfying the bound""" neps = int (n * eps)binom_n = comb(n, neps)binom_m = comb(m*r, m- 1 )log2_binom = log2(binom_n) + log2(binom_m)k = -(log2_binom + 30 )/(n*eps*log2( 1 /r)) return ceil(k)列也是網絡上的傳輸單位,目前無法交換小於列的單位。因此,PeerDAS 的初始版本缺少兩個功能:
- 部分重建:僅通過重建和重新播種部分數據(例如,僅一行(或幾行)而不是整個矩陣)即可為重建做出貢獻。
- 完全兼容內存池:交易附帶 blob/行,通常會提前分發到內存池中。然而,任何單個 blob 的缺失都會阻止節點構建列,從而導致所有其他內存池 blob 失效。
為了解決這些限制,單元級消息傳遞已被強烈考慮作為該協議下一輪迭代的候選方案(例如,參見此處)。由於這也是二維 DAS 構建的關鍵組成部分,這引發了一個問題:我們是否應該:
- 通過單元級消息傳遞增強 1D PeerDAS,或
- 過渡到 2D 構造。
或者至少,這種轉變是否會是後續的迭代。在本文中,我們將比較這兩種方法的效率,假設它們都旨在提供相同級別的安全性,同時最大限度地減少帶寬消耗。
免責聲明:我們將完全忽略“加密層”的安全性,即所使用的 KZG 承諾的安全屬性。該層已在此處和此處進行了廣泛的研究。我們的重點是與採樣過程相關的統計安全屬性,並將加密層視為理想化。
背景:數據可用性採樣
讓我們首先抽象地回顧一下數據可用性採樣(DAS)背後的核心思想。
在 DAS 中,提議者持有一段數據,並希望將其分發到整個網絡。客戶端(可能是全節點或驗證者)的目標是驗證該數據確實可用,而無需完整下載。
為了實現此目的,提議者使用糾刪碼擴展數據。然後,每個客戶端嘗試下載結果碼字的k k 個隨機符號,並根據所有客戶端都會下載的簡潔加密承諾進行檢查。在 DAS 中,這些符號也稱為樣本或查詢。只有當所有k k 個查詢都成功驗證後,客戶端才會接受數據(例如,在其分叉選擇中包含相應的區塊)。
DAS 安全性(針對潛在的惡意提議者)背後的高級直覺是:
- 加密承諾保證提議者承諾使用有效的代碼字(請參閱此處的代碼綁定概念);
- 如果有足夠多的客戶端接受,那麼由於擦除碼的屬性,他們的集體查詢允許重建完整的數據。
這篇文章主要討論第二點:重構究竟是如何實現的?多少個客戶端才夠用?參數k又該如何設置?
我們首先解決第一個問題,解釋一下“部分重建”的含義。然後,我們將重點轉向安全性。
背景:部分重建
DAS 的核心問題之一是:誰能重建數據?何時重建?假設我們有一個無所不能的“超級節點”,它能夠從網絡下載足夠多的樣本,重建通過糾刪碼編碼的全部數據。在這種情況下,即使只有少數代碼符號缺失(可能是被惡意提議者隱瞞的),這個超級節點也可以簡單地重新計算缺失的部分,並將其重新引入網絡(即重新播種)。最終,這些符號會被傳播,所有客戶端都會接受。
這種設置引發了對如此強大的超級節點的依賴擔憂,這可能是一箇中心化因素。事實上,即使我們使用具有最小重建閾值的糾刪碼(例如Reed-Solomon等所謂的MDS碼) ,超級節點也需要下載與完整原始數據一樣多的樣本才能重建數據。
這時,部分重建的概念就應運而生了。如果某個代碼能夠使用比完全重建所需的樣本少得多的樣本量來恢復數據中較小的局部部分,我們就稱其支持部分重建。無需超級節點收集幾乎所有數據片段,多個較小的節點就可以獨立地重建部分數據。通過這種方式,部分重建可以將重建任務分散到眾多參與者身上,從而減少對中心化超級節點的依賴。
除了通過減少對更強大節點的依賴來增強網絡的穩健性之外,分散重建的 CPU 負載和重新播種重建數據的帶寬負載也可以被視為性能提升。目前,重建不太可能幫助數據在關鍵路徑上傳播,這或許是採用糾刪碼的另一個好處,因為重建一個包含所有證明的 blob大約需要 100 毫秒。通過將此負載分散到多個節點,每個節點只負責一個或幾個 blob,糾刪碼的作用遠不止於安全保障。
背景:子集健全性
在本文中,我們將比較不同編碼方案(一維和二維)的效率,假設它們都能達到相同的安全級別。為了使比較更有意義,我們首先需要清楚地理解在 DAS 環境中“安全”的含義。
我們考慮的安全概念被稱為子集健全性,並考慮了自適應對手。該概念在《DAS基礎》論文中作為定義2正式引入,它也是PeerDAS安全原理的基礎。
直觀地講,子集健全性模型模擬了一個強大的對手,他會觀察大量n個客戶端/節點的查詢。然後,對手可以自適應地決定顯示哪些符號、隱藏哪些符號,從而有效地構建每個節點看到的視圖。對手還會選擇一小部分節點(例如, \epsilon n \leq n ϵ n ≤ n ,其中\epsilon > 0 ϵ > 0 ),並試圖欺騙這些節點,使其相信數據完全可用。值得注意的是,這種選擇可能取決於節點發出的查詢。然後,我們考慮對手贏得這場遊戲的概率p p ,即
- \epsilon n ϵ n個節點全部接受,並且
- 數據並不完全可用;也就是說:人們無法從查詢中重建數據。
為了達到我們的目的,我們希望p p最多為2^{-30} 2 − 30 (對於任何對手)。下面,我們將根據n n 、 \epsilon ϵ和編碼方案設置每個節點的查詢次數k k ,以保證p \leq 2^{-30} p ≤ 2 − 30 。
\epsilon ϵ的影響和選擇:
上面描述的安全概念由\epsilon \in (0, 1] ϵ ∈ ( 0 , 1 ]參數化,它模擬了對手試圖欺騙的節點比例。從正式定義和簡單的密碼學簡化來看,給定\epsilon ϵ (具有固定的n n )的子集健全性意味著任何更大的\epsilon' \geq \epsilon ϵ ′ ≥ ϵ的子集健全性。換句話說:如果對手無法欺騙\epsilon ϵ比例的節點,那麼它肯定無法欺騙更大比例的\epsilon' ϵ ′ 。但這與整體共識協議有何關係?假設我們知道攻擊者最多隻能欺騙ε ϵ比例的節點。每個被欺騙的節點實際上在共識過程中充當一個額外的惡意節點。因此,當使用數據可用性抽樣時,攻擊者最多可以獲得額外 ε ϵ比例的明顯惡意節點。
例如,如果沒有 DAS 的共識可以容忍最多<{1}/{3} < 1 / 3 個惡意節點,那麼有了 DAS,系統現在只能容忍最多<{1}/{3} - \epsilon < 1 / 3 − ϵ 個惡意節點。
因此,在實際操作中,我們必須選擇較小的\epsilon ϵ ,比如\epsilon = 1\% ϵ = 1 % ,以確保對手的影響可以忽略不計。
二、PeerDAS——一維構造
在本節中,我們將解釋PeerDAS的工作原理,它將包含在Fusaka升級中。我們還將解釋單元級消息傳遞如何實現部分重建。
工作原理
我們描述瞭如何編碼數據以及客戶端如何進行查詢,而忽略了與“加密層”相關的所有內容,例如承諾和開口。
一個blob是由m個單元組成的集合,每個單元包含f個字段元素。在 PeerDAS 當前的參數設置中,每個單元包含f = 64個字段元素,每個 blob 包含m = 64個單元。為了考慮不同的單元大小,我們令fm = 4096為常數(即數據大小固定) ,並在f ∈ { 64,32,16,8 }之間變化,即m = 4096 / f 。
要對單個 blob 進行編碼,需要使用速率為1/2 1/2的Reed -Solomon 碼對其進行擴展,從而得到2m 2 m個單元,或者等效地得到2fm = 8192 2 f m = 8192 個字段元素。在 PeerDAS 中,我們將此編碼過程分別應用於b b 個blob,並將擴展後的 blob 視為b \times 2m b × 2 m個單元矩陣中的行。
客戶端現在查詢該矩陣的整列,也就是說,它們嘗試一次性下載b個單元。這意味著“符號”或我們的糾刪碼是擴展 blob 矩陣的列。從這些列中的任意m個列,都可以重建整個矩陣,從而重建數據。
支持採樣功能的具體網絡基礎設施是列的 GossipSub 主題,即只有對特定樣本(= 列)感興趣的節點參與的子網絡。
部分重建
正如預期的那樣,當前的PeerDAS設計不支持部分重建。然而,即使是這樣的一維編碼,原則上也可以支持此功能,當它獨立應用於多個blob時,就像在PeerDAS中一樣。事實上,通過使用小於列的垂直單位(例如單元格),當然可以僅重建完整矩陣的部分內容,例如單獨的行或行組。這帶來了兩個挑戰:
- 部分重新播種:當一個節點重建單行時,它不會重建任何完整的樣本(列),但它仍然需要能夠將重建的數據貢獻回網絡。
- 獲取足夠的單元進行重建:當僅對列進行採樣時,重建能力要麼全部,要麼全部不重建,也就是說,一個節點要麼獲得足夠的列來重建整個矩陣,要麼無法重建矩陣的任何部分。換句話說,只有超節點才能參與重建。我們希望節點能夠做到這一點,同時仍然只下載整個數據的一小部分。
有一些眾所周知的方法可以解決這些問題,這些方法可以讓我們進行部分重建:
- 單元級消息傳遞:使節點能夠交換單元而不是整列,以便重建行的節點可以逐個單元地重新播種,至少在它們參與的列主題中是這樣。
- 行主題:有些節點也嘗試通過參與行主題下載部分行,並配備單元級消息傳遞功能。至關重要的是,這並非採樣,獲取多少行並不涉及安全隱患,因此即使只參與一個行主題也足夠了。事實上,在一維結構中,對行進行採樣毫無意義,因為不存在垂直冗餘。行主題的目的僅僅是使列主題中的單元能夠流入其中並實現行向重構,而無需任何超節點。重構後的單元隨後可以從行主題流入所有列主題,同樣無需任何單個節點參與所有列主題。
注意:缺乏垂直冗餘意味著我們需要每個行主題都能成功執行其重建任務。即使只有一個行主題失敗(例如,由於僅限於該主題的網絡級攻擊),整個重建也無法完成。
樣本數量
現在讓我們確定PeerDAS每個客戶端的樣本數量k 。如上所述,我們希望選擇k ,使得攻擊者破壞子集健全性的概率p最多為2^{-30} 2 − 30 。
PeerDAS 的安全性已在這裡和這裡進行了廣泛的分析。後者的工作建立在這裡的安全框架之上,並且可以通過結合引理 1 和引理 3得出子集健全性的具體界限。最終,所有這些得出了相同的子集健全性界限,即:
p \leq \binom{n}{n\epsilon}\cdot \binom{2m}{m-1} \cdot (\frac{m-1}{2m})^{kn\epsilon} \leq \binom{n}{n\epsilon}\cdot \binom{2m}{m-1} \cdot 2^{-kn\epsilon}. p ≤ ( n n ϵ ) ⋅ ( 2米米− 1 ) ⋅ (米− 1 2米) k n ϵ ≤ ( n n ϵ ) ⋅ ( 2米米− 1 ) ⋅ 2 − kn ϵ 。
直觀地講,第一個二項式表示對手自由且自適應地挑選n\epsilon n ϵ個節點來欺騙的能力,第二個二項式表示對手選擇m-1 m − 1 個符號來提供給這些節點,最後一個項是所有樣本最終都出現在編碼的可用部分中的概率。
如果我們希望p \leq 2^{-30} p ≤ 2 − 30且n,m,\epsilon n , m , ϵ已知,我們需要設定
k \geq \frac{1}{n\epsilon} \left( \log_2 \binom{n}{n\epsilon} + \log_2 \binom{2m}{m-1} + 30 \ right ) k≥1nϵ (日誌2 ( n n ϵ ) + log 2 ( 2米− 1 ) + 30 ) 。
以下是計算k k的代碼:
from math import comb, log2, ceil # used later from tabulate import tabulate # used later import numpy as np # used later import matplotlib.pyplot as plt # used later def min_samples_per_node ( n: int , m: int , r: int = 2 , eps: float = 0.01 ): """Finds the smallest integer k such that k samples per nodeachieve security of 30 bits for the 1D construction.Inputs:n: total number of nodesm: number of symbols in original datar: inverse coding rate (total symbols = r*m), default=2eps: fraction of nodes to be fooled (0 < eps <= 1), default=0.01Returns:Smallest integer k satisfying the bound""" neps = int (n * eps)binom_n = comb(n, neps)binom_m = comb(m*r, m- 1 )log2_binom = log2(binom_n) + log2(binom_m)k = -(log2_binom + 30 )/(n*eps*log2( 1 /r)) return ceil(k)III. 2D 構造
PeerDAS 的替代方案是二維構造,這已經在(此處、 此處和此處)討論過了。該構造基於 Reed-Solomon 碼的張量編碼,並已在此處第 8 節進行了分析。它支持一種自然形式的部分重建。
工作原理
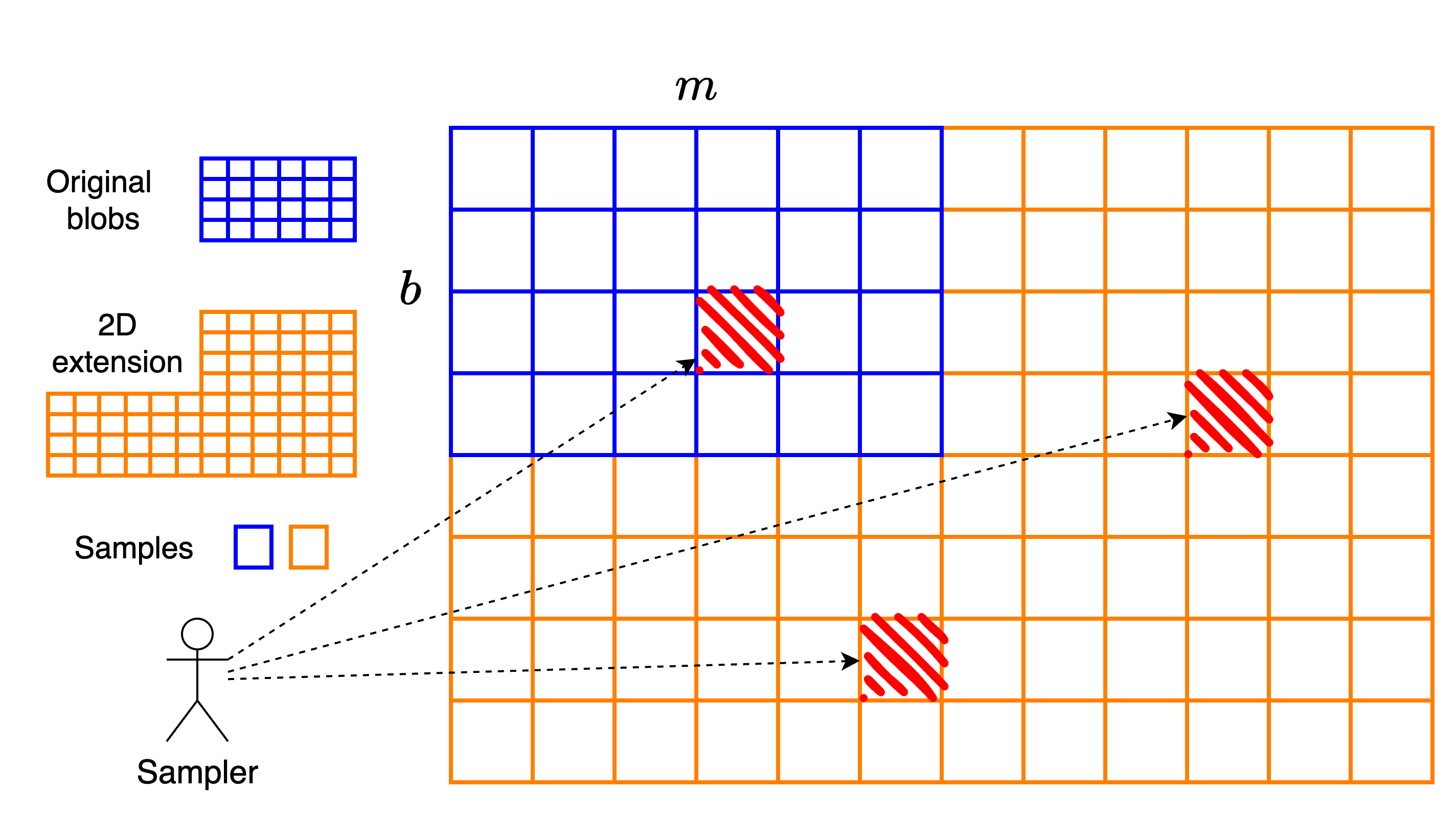
我們可以將 PeerDAS 視為將一個b \times m b × m矩陣( b b 個blob,每個 blob 有m m 個cell)水平擴展為一個b \times 2m b × 2 m 個cell 矩陣。等效地,這是一個由場元素組成的b \times 2mf b × 2 m f矩陣,其中每個 cell 包含f f個場元素。由於擴展僅沿水平軸進行,因此 PeerDAS 被稱為一維結構。
在二維構造中,我們按如下方式進行:從 PeerDAS 中導出的b \times 2mf b × 2 m f矩陣開始,然後使用另一個速率為1/2 1 / 2的 Reed–Solomon 碼垂直擴展每一列。最終得到一個大小為2b \times 2mf 2 b × 2 m f的矩陣,或者等效地,一個由單元組成的2b \times 2m 2 b × 2 m矩陣。
與 PeerDAS 的一個關鍵區別在於,在二維結構中,客戶端採樣的是單個單元格,而不是整列。也就是說,代碼的一個符號是一個單元格,而不是一整列。
部分重建
二維構造中的重建自然是一個涉及幾個子過程的過程:
- 只要同一行中至少有m個單元格可用,就可以完全重建該行。
- 類似地,只要同一列中至少有b個單元格可用,就可以重建該列。
這種局部性意味著不需要一箇中心超級節點來重建整個數據集。相反,只要有足夠多的節點能夠獨立地重建特定的行或列,就能以去中心化的方式實現相同的目標。
樣本數量
同樣,我們希望確定每個客戶端的樣本數量k k ,以實現p \leq 2^{-30} p ≤ 2 − 30形式的安全性。為此,我們需要在二維結構中確定p p的上限。
使用DAS 基礎論文中的工具,我們可以獲得邊界
p \leq \binom{n}{n\epsilon}\cdot \binom{4mb}{4mb - (b+1)(m+1)} \cdot (\frac{4mb - (b+1)(m+1)}{4mb})^{kn\epsilon} = \binom{n}{n\epsilon}\cdot \binom{4mb}{(b+1)(m+1)} \cdot (1-\frac{(b+1)(m+1)}{4mb})^{kn\epsilon}. p ≤ ( n n ϵ ) ⋅ ( 4米b 4米b − ( b + 1 ) (米+ 1 ) ) ⋅ ( 4米b − ( b + 1 ) (米+ 1 ) 4米b ) kn






